【Linux内核编译与模块开发】:定制化操作系统打造,从源码到模块
发布时间: 2024-09-26 14:33:55 阅读量: 177 订阅数: 75 

基础实验:linux内核的编译与内核模块.doc
# 1. Linux内核编译的基础知识
Linux内核是操作系统的核心部分,控制着计算机硬件资源的管理与使用。了解Linux内核编译的基础知识对于深入研究Linux系统运作至关重要。本章将为读者提供Linux内核编译的初步认识,帮助读者建立后续章节的基础。
首先,内核编译过程涉及到对源代码进行编译和链接,生成可执行的内核映像。这不仅要求读者具备一定的Linux系统操作技能,还需要了解编译工具链如GCC(GNU Compiler Collection)的使用。在源代码编译过程中,会使用到Makefile脚本来自动化编译过程,而配置选项则通过内核配置系统来设定。
此外,内核编译通常伴随着编译优化选项的使用,旨在提高系统性能或减少资源消耗。了解这些基础知识,有助于读者在后续章节深入探索内核源码结构,以及如何进行定制化编译实践。在接下来的章节中,我们将进一步讨论内核源码结构和定制化编译的具体步骤。
# 2. 深入Linux内核源码结构
## 2.1 Linux内核的层次结构
Linux内核是一个复杂的软件系统,它负责管理系统资源和硬件设备。内核的层次结构可以让我们更好地理解其组件是如何协同工作的。理解这些层次有助于开发者进行故障诊断、性能优化以及安全加固。
### 2.1.1 系统启动与初始化
在系统启动时,内核会经历几个重要的阶段。从引导加载程序开始,内核映像被加载到内存中,然后开始解压缩并执行实际的内核代码。在初始化阶段,内核会进行硬件检测、内存测试、驱动加载等一系列复杂的操作。
**引导过程的典型步骤包括:**
1. BIOS自检。
2. 引导加载程序(如GRUB)的加载。
3. 内核映像的加载和解压缩。
4. 内核初始化硬件设备和驱动。
5. 用户空间的初始化和进程1(通常是init或systemd)的启动。
初始化过程中,内核会经历一系列的阶段,从`start_kernel()`函数开始,逐步初始化各个子系统,最终达到运行级别,启动用户空间进程。
### 2.1.2 内核与硬件的交互
内核与硬件的交互是通过一组精心设计的硬件抽象层实现的。这使得操作系统可以适应不同的硬件平台,同时向用户空间提供统一的接口。
硬件抽象层涉及到多个组件:
- **中断控制器**:管理硬件设备的中断信号。
- **I/O体系结构**:处理内存和设备之间的数据传输。
- **时钟管理**:确保系统的时序准确性。
- **电源管理**:管理设备和系统的能源使用。
这些组件通过内核中的设备驱动程序进行交互。驱动程序是一种特殊的内核模块,它们知道如何与特定的硬件设备通信。
## 2.2 Linux内核配置系统
Linux内核具有很高的可定制性。其配置系统允许用户选择启用或禁用特定的内核特性,以满足特定的系统需求或优化内核大小。
### 2.2.1 配置选项与编译时的依赖关系
配置选项决定了哪些内核功能被包括进最终的内核镜像。这些选项是基于模块化设计的,用户可以通过`make menuconfig`、`make xconfig`或`make config`等工具来选择。
在配置内核时,需注意依赖关系,某些功能可能依赖于其他组件的存在。例如,如果启用了一个特定的文件系统,那么可能需要启用支持该文件系统的模块。编译系统会通过依赖关系来确保所有必要的组件都被正确编译。
### 2.2.2 使用make menuconfig进行配置
`make menuconfig`提供了一个基于文本的用户界面,用于选择和配置内核的各个选项。使用它,用户可以:
- 选择或取消选择特性。
- 查看每个配置选项的详细描述。
- 调整编译选项,如优化级别。
`make menuconfig`使用基于ncurses的图形界面,使得用户能够更容易地进行内核配置。在内核源码树的根目录执行`make menuconfig`会启动配置界面,用户可以在这里进行各种自定义。
## 2.3 内核模块的构建与管理
内核模块是内核中的可加载组件,它们可以动态地插入和移除,而无需重新编译整个内核。模块化设计使得内核保持了灵活性和可扩展性。
### 2.3.1 内核模块的加载与卸载机制
内核模块的加载是通过`insmod`、`modprobe`等命令来实现的。加载模块时,内核会调用模块的初始化函数,并将该模块加入到内核模块列表中。卸载模块时,则调用清理函数,并从内核模块列表中移除。
内核模块通常会有以下几种状态:
- **已安装**:模块已加载到内存中,但可能未被使用。
- **已使用**:至少有一个内核组件正在使用该模块。
- **未安装**:模块不在内存中。
### 2.3.2 模块间的依赖关系处理
内核模块之间可能存在依赖关系。例如,一个文件系统模块可能依赖于特定的块设备驱动模块。内核在加载模块时会自动处理这些依赖。
处理依赖关系的工具之一是`depmod`,它会创建一个模块依赖关系的列表文件,供`modprobe`使用以自动加载所有需要的依赖模块。
# 第三章:Linux内核定制化编译实践
## 3.1 交叉编译环境的搭建
为了在不同架构的硬件上编译Linux内核,我们需要设置一个交叉编译环境。这使得开发者可以在一个架构上构建适用于另一个架构的内核。
### 3.1.1 选择合适的交叉编译工具链
选择正确的交叉编译工具链对于成功构建内核至关重要。工具链应与目标硬件架构兼容,并且需要包括编译器、链接器以及相关的库。
一个流行的工具链是`arm-linux-gnueabi`,它可以用于为基于ARM架构的硬件编译内核。其他的工具链还包括`i686-linux-gnu`、`aarch64-linux-gnu`等。
### 3.1.2 配置交叉编译环境
配置交叉编译环境包括设置环境变量,如`CC`、`CXX`、`LD`和`AR`,以指向交叉编译器。这可以通过在shell配置文件中添加如下行来实现:
```sh
export CROSS_COMPILE=arm-linux-gnueabi-
export ARCH=arm
```
之后,你可以使用`make help`命令来检查是否正确设置了交叉编译器。
## 3.2 源码编译步骤详解
获取Linux内核源码之后,下一步就是执行编译命令以生成内核镜像。这个过程涉及了多个步骤,每个步骤都有其作用和重要性。
### 3.2.1 获取Linux内核源码
通常,内核源码可以从官方的Linux内核仓库下载,使用`git`可以快速克隆代码:
```sh
git clone ***
```
下载完成后,你可以使用`git tag`来查看所有可用的稳定版本标签。
### 3.2.2 运行make命令与内核编译
编译内核的第一步是配置内核选项。这可以通过运行如下命令之一来完成:
```sh
make menuconfig
make nconfig
make xconfig
```
配置完成后,使用以下命令开始编译过程:
```sh
make -j$(nproc)
```
这将在所有可用的处理器核心上并行编译内核,大大加快编译速度。
## 3.3 编译优化与性能调整
在编译内核时,开发者可以选择多种优化选项来调整内核的性能和行为。性能分析工具可以在编译后帮助识别和优化瓶颈。
### 3.3.1 内核编译优化选项
编译优化选项在`make`命令中以`-O`标志给出。例如:
```sh
make -j$(nproc) O=build ARCH=arm CROSS_COMPILE=arm-linux-gn
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
Linux 专栏是一个全面的指南,涵盖 Linux 操作系统从基础入门到高级应用的各个方面。它提供了新手必备的入门知识,以及用于提高效率的命令行指南。专栏深入探讨了 Linux 系统架构,揭示了内核和文件系统的奥秘。它还提供了脚本编程、系统管理、网络配置、安全加固和服务器搭建的实用指南。此外,专栏还介绍了 Linux 虚拟化技术、高可用集群架构、数据库管理、Web 服务器配置、监控工具、文件共享、版本控制和自动化部署工具。最后,它提供了性能调优、内核编译、故障诊断和云服务方面的深入见解。通过阅读这个专栏,读者可以全面掌握 Linux 操作系统,并提升他们在系统管理、开发和运维方面的技能。
专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
从零开始学Arduino:中文手册中的初学者30天速成指南

参考资源链接:[Arduino中文入门指南:从基础到高级教程](https://wenku.csdn.net/doc/6470036fd12cbe7ec3f619d6?spm=1055.2635.3001.10343)
# 1. Arduino基础入门
## 1.1 Arduino简介与应用场景
Arduino是一种简单易用的开源电子原型平台,旨在为艺术家、设计师、爱好者和任何
【进纸系统无忧维护】:施乐C5575打印流畅性保证秘籍
参考资源链接:[施乐C5575系列维修手册:版本1.0技术指南](https://wenku.csdn.net/doc/6412b768be7fbd1778d4a312?spm=1055.2635.3001.10343)
# 1. 施乐C5575打印机概述
## 1.1 设备定位与使用场景
施乐C5575打印机是施乐公司推出的彩色激光打印机,主要面向中高端商业打印需求。它以其高速打印、高质量输出和稳定性能在众多用户中赢得了良好的口碑。它适用于需要大量文档输出的办公室环境,能够满足日常工作中的打印、复印、扫描以及传真等多种功能需求。
## 1.2 设备特性概述
C5575搭载了先进的打印技术
六轴传感器ICM40607工作原理深度解读:关键知识点全覆盖
.png)
参考资源链接:[ICM40607六轴传感器中文资料翻译:无人机应用与特性详解](https://wenku.csdn.net/doc/6412b73ebe7fbd1778d499ae?spm=1055.2635.3001.10343)
# 1. 六轴传感器ICM40607概览
在现代的智能设备中,传感器扮演着至关重要的角色。六轴传感器ICM40607作为一款高精度、低功耗
【易语言爬虫进阶攻略】:网页数据处理,从抓取到清洗的全攻略

参考资源链接:[易语言爬取网页内容方法](https://wenku.csdn.net/doc/6412b6e7be7fbd1778
【C#统计学精髓】:标准偏差STDEV计算速成大法
参考资源链接:[C#计算标准偏差STDEV与CPK实战指南](https://wenku.csdn.net/doc/6412b70dbe7fbd1778d48ea1?spm=1055.2635.3001.10343)
# 1. C#中的统计学基础
在当今世界,无论是数据分析、机器学习还是人工智能,统计学的方法论始终贯穿其应用的核心。C#作为一种高级编程语言,不仅能够执行复杂的逻辑运算,还可以用来实现统计学的各种方法。理解C#中的统计学基础,是构建更高级数据处理和分析应用的前提。本章将先带你回顾统计学的一些基本原则,并解释在C#中如何应用这些原则。
## 1.1 统计学概念的C#实现
C#提
【CK803S处理器全方位攻略】:提升效率、性能与安全性的终极指南
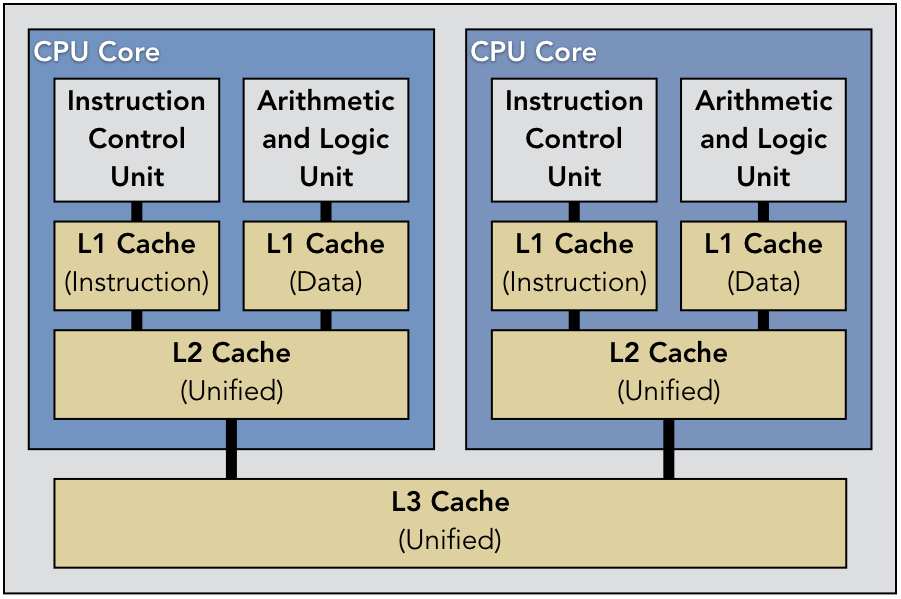
参考资源链接:[CK803S处理器用户手册:CPU架构与特性详解](https://wenku.csdn.net/doc/6uk2wn2huj?spm=1055.2635.3001.10343)
# 1. CK803S处理器概述
CK803S处理器是市场上备受瞩目的高性能解决方案,它结合了先进的工艺技术和创新的架构设计理念,旨在满足日益增长的计算需求。本章
STM32F407内存管理秘籍:内存映射与配置的终极指南

参考资源链接:[STM32F407 Cortex-M4 MCU 数据手册:高性能、低功耗特性](https://wenku.csdn.net/doc/64604c48543f8444888dcfb2?spm=1055.2635.3001.10343)
# 1. STM32F407微控制器简介与内存架构
STM32F407微控制器是ST公司生产的高性能ARM Cortex-M4核心系列之一,广泛应用
【性能调优的秘诀】:VPULSE参数如何决定你的系统表现?
参考资源链接:[Cadence IC5.1.41入门教程:vpulse参数解析](https://wenku.csdn.net/doc/220duveobq?spm=1055.2635.3001.10343)
# 1. VPULSE参数概述
VPULSE参数是影响系统性能的关键因素,它在IT和计算机科学领域扮演着重要角色。理解VPULSE的基本概念是进行系统优化、
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )