Helm 101: 介绍Helm包管理工具
发布时间: 2024-01-03 01:49:21 阅读量: 36 订阅数: 49 
# 第一章:Helm包管理工具简介
## 1.1 什么是Helm?
Helm是一个用于管理Kubernetes应用程序的包管理工具。它允许用户定义、安装和升级Kubernetes的应用程序,以及管理依赖关系。
Helm将应用程序打包为Chart文件,一个Chart可以包含一个或多个Kubernetes资源文件(如部署、服务、配置等)。用户可以使用Helm来轻松地复用、共享和分发自己的应用程序。
## 1.2 Helm的历史和发展
Helm最初由Deis(一个PaaS提供商,现已更名为Azure Kubernetes Service)的工程师发起,于2015年开源。它被设计为一个用于简化Kubernetes应用部署的工具。
随着时间的推移,Helm逐渐成为Kubernetes生态系统中最受欢迎的包管理工具之一。它扩展了Kubernetes的功能,为用户提供了更高效、方便的应用程序部署和管理方式。
## 1.3 Helm在Kubernetes中的应用
在Kubernetes中,应用程序是通过使用Kubernetes资源对象(如Deployment、Service、ConfigMap等)来定义和管理的。然而,对于复杂的应用程序,用户可能需要定义和管理多个相关的资源对象,这可能会变得非常复杂和冗长。
Helm通过使用Chart来解决了这个问题。Chart是一个可重用的应用程序包,它定义了一组相关的Kubernetes资源对象。用户可以使用Helm来安装、升级和卸载这些Chart,从而简化了应用程序的部署和管理过程。此外,Helm还支持依赖关系管理,允许用户轻松地管理多个Chart之间的依赖关系。
总结:该章节介绍了Helm包管理工具的基本概念与作用,以及其在Kubernetes中的应用场景。
## 第二章:安装和配置Helm
### 2.1 安装Helm
在本章节中,我们将介绍如何安装Helm包管理工具。
Helm可以在多个操作系统上进行安装,包括Windows、Mac和Linux。但是,本章节将重点介绍在Linux系统上安装Helm的步骤。
以下是在Linux系统上安装Helm的步骤:
1. 打开终端并运行以下命令以将Helm二进制文件下载到本地:
```bash
$ curl -LO https://get.helm.sh/helm-v3.5.2-linux-amd64.tar.gz
```
2. 解压缩下载的文件,并将Helm可执行文件移动到系统的PATH路径中:
```bash
$ tar -zxvf helm-v3.5.2-linux-amd64.tar.gz
$ sudo mv linux-amd64/helm /usr/local/bin/helm
```
3. 验证Helm是否成功安装,运行以下命令检查Helm版本号:
```bash
$ helm version
```
如果成功安装,将会显示Helm的版本信息。现在,您已成功在Linux系统上安装了Helm。
### 2.2 配置Helm客户端
安装完Helm后,我们需要进行一些基本的配置。
1. 初始化Helm客户端,执行以下命令:
```bash
$ helm init
```
2. 这将在您的Kubernetes集群上安装并配置Tiller(Helm的服务器端组件)。
### 2.3 配置Helm服务器端(Tiller)
在新的Helm版本中,Tiller已被淘汰,我们将介绍如何配置Helm服务器端。
1. 首先,我们需要为Helm安装一个Tiller库:
```bash
$ helm repo add stable https://kubernetes-charts.storage.googleapis.com/
```
2. 然后,我们可以更新库以获取最新的Charts信息:
```bash
$ helm repo update
```
现在,Helm服务器端已经成功配置。
在本章节中,我们学习了如何在Linux系统上安装Helm,并对Helm客户端和服务器端进行了基本的配置。在下一章节中,我们将介绍Helm Charts的基础知识。
### 第三章:Helm Charts基础
Helm Charts是用于定义、安装和升级Kubernetes应用的包。本章将深入探讨Helm Charts的基础知识,包括创建和理解Helm Charts的结构。
#### 3.1 什么是Helm Charts?
Helm Charts是一种预定义Kubernetes应用的打包形式。每个Chart都包含了一组Kubernetes资源的描述,以及定义这些资源的模板。
#### 3.2 创建一个简单的Helm Chart
让我们创建一个简单的Helm Chart来理解其基本结构。首先,使用以下命令创建一个新的Chart:
```shell
$ helm create mychart
```
该命令将创建一个名为`mychart`的新目录,并在其中生成Chart的基本结构。
#### 3.3 理解Helm Chart的结构
一个典型的Helm Chart目录包含以下文件和目录:
- `Chart.yaml`:包含Chart的元数据,如名称、版本和描述。
- `values.yaml`:定义Chart的默认值,可以在模板中使用。
- `templates/`:包含用于生成Kubernetes资源的模板文件。
- `charts/`:用来存放依赖的子Charts。
- `helpers.tpl`:包含用于模板渲染的帮助函数。
通过上述内容,我们了解了Helm Charts的基础知识和结构,为后续学习和使用Helm提供了基础。
## 第四章:Helm包管理
在这一章中,我们将学习如何使用Helm进行包的管理。我们将探讨如何搜索和安装Charts、更新已安装的Charts以及卸载不再需要的Charts。
### 4.1 搜索和安装Charts
Helm提供了一个官方的Chart仓库,其中包含了各种各样的预定义Charts,方便我们使用。我们可以使用`helm search`命令来搜索这个仓库中的Charts。
```shell
$ helm search repo postgresql
```
上述命令将会搜索所有Chart名称包含"postgresql"的Charts。我们可以通过查看搜索结果来选择合适的Chart。
安装一个Chart非常简单,我们只需要使用`helm install`命令即可。
```shell
$ helm install stable/mysql
```
上述命令将会安装一个名为"mysql"的Chart。Helm会自动下载和配置这个Chart,然后在Kubernetes集群中部署一个MySQL实例。
### 4.2 更新已安装的Charts
当一个Chart有新的版本发布时,我们可以使用Helm来更新已经安装的Charts。使用`helm update`命令来更新Charts。
```shell
$ helm update stable/mysql
```
上述命令将会检查是否有新版本的"mysql" Chart可用,并将已安装的Chart更新到最新版本。
### 4.3 卸载Charts
当我们不再需要一个已安装的Chart时,可以使用`helm uninstall`命令将其卸载。
```shell
$ helm uninstall mysql
```
上述命令将会卸载名为"mysql"的Chart,并从Kubernetes集群中移除相关的资源。
这就是使用Helm进行包管理的基本操作。在下一章中,我们将探讨如何自定义Helm Charts,以满足我们特定的需求。
第五章:自定义Helm Charts
### 5.1 参数化和模板化
在之前的章节中,我们已经学习了如何使用Helm Charts来管理和部署应用程序。然而,有时我们需要根据特定场景来自定义Charts的配置。Helm允许我们使用参数和模板来实现这一点。
#### 5.1.1 参数化
参数化是指在Charts中定义一组可配置的值,使用户能够根据自己的需求来设置这些值。这样一来,一个通用的Chart就可以根据不同的配置来生成多个具体的部署。
我们可以在Chart的`values.yaml`文件中定义参数。例如,我们可以定义一个`replicaCount`参数来指定部署的副本数:
```yaml
replicaCount: 3
```
然后,在模板中可以使用`{{ .Values.replicaCount }}`来引用这个参数。这样,当用户部署该Chart时,可以使用`--set`选项来指定具体的值:
```bash
helm install myapp ./mychart --set replicaCount=5
```
这样,部署的副本数就会根据用户的设置而确定。
#### 5.1.2 模板化
除了参数化,我们还可以使用模板来生成动态的配置。模板是一个包含变量、控制结构和函数的文件,它被解析为最终的配置文件。
在Helm中,我们使用Go语言的模板引擎来处理模板。可以在Chart的`templates`目录下创建一个或多个模板文件。例如,我们可以创建一个`deployment.yaml`模板文件来生成Kubernetes部署对象:
```yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: {{ .Release.Name }}-deployment
spec:
replicas: {{ .Values.replicaCount }}
template:
spec:
containers:
- name: myapp
image: {{ .Values.image }}
ports:
- containerPort: {{ .Values.port }}
```
在这个模板中,我们使用了Helm提供的一些变量,例如`.Release.Name`表示当前发布的名称,`.Values.replicaCount`表示用户设置的副本数,`.Values.image`表示用户设置的镜像名称,`.Values.port`表示用户设置的端口号。
通过使用模板,我们可以根据用户的配置生成最终的部署配置。
### 5.2 常用的Chart模板函数
在模板中,Helm还提供了一些常用的函数来处理和操作数据。以下是一些常见的模板函数:
- `toYaml`:将对象转换为YAML格式的字符串。
- `toJson`:将对象转换为JSON格式的字符串。
- `quote`:对字符串添加双引号。
- `tpl`:将字符串作为模板进行渲染。
- `include`:包含其他模板文件的内容。
可以在Helm官方文档中找到更多的模板函数和用法:[https://helm.sh/docs/chart_template_guide/functions_and_pipelines/](https://helm.sh/docs/chart_template_guide/functions_and_pipelines/)
### 5.3 使用条件和循环
除了参数化和模板化,Helm还支持使用条件和循环来根据不同的条件生成不同的配置。
条件语句可以根据特定的条件来决定是否包含某些配置。例如,我们可以根据用户设置的参数值来判断是否包含某个服务:
```yaml
{{- if .Values.enableService }}
apiVersion: v1
kind: Service
metadata:
name: {{ .Release.Name }}-service
spec:
ports:
- name: http
port: {{ .Values.port }}
targetPort: {{ .Values.targetPort }}
selector:
app: {{ .Release.Name }}
{{- end }}
```
在这个例子中,只有当用户设置的`enableService`参数为`true`时,才会生成服务的配置。
循环语句可以根据特定的条件和数据源来重复生成配置。例如,我们可以根据用户设置的副本数来生成多个Pod的配置:
```yaml
{{- range $i, $count := until .Values.replicaCount }}
apiVersion: v1
kind: Pod
metadata:
name: {{ .Release.Name }}-pod-{{ $i }}
{{- end }}
```
在这个例子中,将根据用户设置的副本数生成对应数量的Pod配置。
通过使用条件和循环,我们可以更加灵活地根据不同的场景生成配置。
在本章中,我们学习了如何通过参数化和模板化来定制Helm Charts的配置。我们还介绍了常用的Chart模板函数以及使用条件和循环来生成不同的配置。这些技术可以帮助我们根据具体需求来定制和管理应用程序的部署。
### 第六章:高级Helm特性和最佳实践
在本章中,我们将介绍一些高级的Helm特性和最佳实践,帮助你更好地使用Helm进行应用程序的管理和部署。
#### 6.1 使用Helm Secrets管理敏感信息
在实际应用中,我们经常需要管理一些敏感信息,比如数据库密码、API密钥等。Helm Secrets是一个Helm插件,可以帮助我们安全地管理和传递这些敏感信息。
首先,我们需要安装Helm Secrets插件:
```bash
helm plugin install https://github.com/futuresimple/helm-secrets
```
安装完成后,我们可以通过以下命令创建和编辑加密的敏感信息文件:
```bash
helm secrets create secrets.yaml
helm secrets edit secrets.yaml
```
编辑完成后,我们可以通过以下方式使用加密的敏感信息文件:
```bash
helm secrets upgrade --install myapp ./myapp-chart --values ./secrets.yaml
```
这样,敏感信息将会被解密并传递给应用程序。
#### 6.2 使用Helm Hooks进行预安装和后安装操作
Helm Hooks是一种在Helm部署生命周期中触发操作的机制。它可以让我们在预安装、后安装和卸载过程中执行自定义的操作。
一种常见的用法是在部署之前执行数据库的迁移操作。我们可以在Chart的`templates`目录下创建一个`_hooks.yaml`文件,定义预安装和后安装的Hook:
```yaml
pre-install:
- name: db-migration
job: true
helm.sh/hook: pre-install
helm.sh/hook-delete-policy: hook-succeeded
annotations:
"helm.sh/hook-weight": "0"
"helm.sh/hook-delete-policy": hook-succeeded
template: |
# 在这里编写数据库迁移脚本的代码
# ...
```
定义完成后,我们可以通过以下命令安装Chart,并触发Hooks:
```bash
helm install myapp ./myapp-chart --hooks
```
Hooks将会在相应的生命周期阶段执行,也可以通过`--dry-run`参数进行测试。
#### 6.3 Helm的最佳实践和常见陷阱
在使用Helm过程中,有一些最佳实践可以帮助我们避免常见的陷阱:
- 记得将所需的参数和值存储在Chart的`values.yaml`中,以便我们可以快速修改和管理。
- 在构建Chart时,尽量将应用程序和基础设施的配置分开,以提高可维护性和可复用性。
- 使用版本控制工具来管理Chart的代码,以便我们可以轻松地追踪和回滚变更。
此外,还有一些常见的陷阱需要注意:
- 确保Chart中的参数和模板正确匹配,以免出现意外的错误。
- 注意Chart之间的依赖关系,确保正确的顺序进行安装和卸载。
遵循这些最佳实践,可以帮助我们更好地使用Helm进行应用程序的管理和部署。
本章介绍了Helm Secrets插件的使用、Helm Hooks的使用以及Helm的最佳实践和常见陷阱。希望这些内容能帮助你更好地理解和使用Helm。
在下一章节中,我们将总结全文并给出一些扩展阅读的资源。敬请期待!

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
这个专栏关于Helm,是一个功能强大的Kubernetes包管理工具的详细指南。从介绍Helm的基础知识开始,逐步深入了解Helm的优势、使用场景和模板语法。文章还探讨了Helm的工作原理、架构、Chart Repository的构建与管理,以及Chart的版本控制和依赖管理。此外,专栏还介绍了Helm在Kubernetes集群部署、配置管理、安全最佳实践、持续集成和持续部署等方面的应用。对于想要自定义Kubernetes应用程序的人来说,也提供了关于Helm Chart自定义和高级技巧的指导。同时,还包括了与微服务架构、Istio和常用监控工具如Prometheus和Grafana的集成等主题。无论是初学者还是有经验的用户,这个专栏都将为他们提供实用的技术指南和最佳实践。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
空间统计学新手必看:Geoda与Moran'I指数的绝配应用
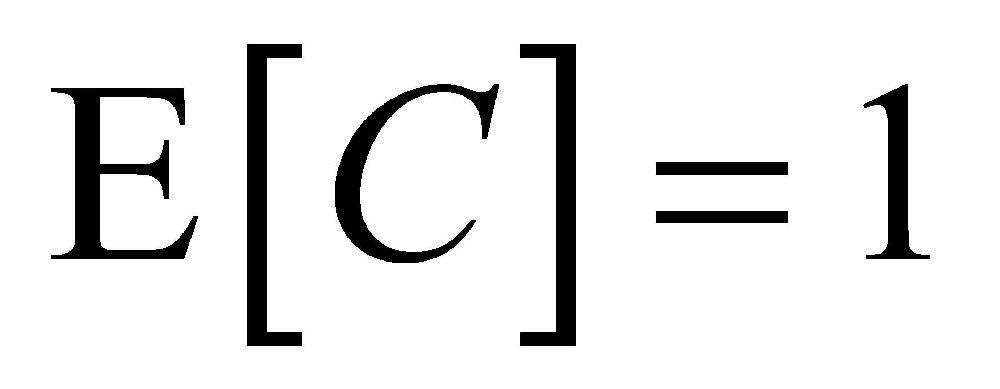
# 摘要
本论文深入探讨了空间统计学在地理数据分析中的应用,特别是运用Geoda软件进行空间数据分析的入门指导和Moran'I指数的理论与实践操作。通过详细阐述Geoda界面布局、数据操作、空间权重矩阵构建以及Moran'I指数的计算和应用,本文旨在为读者提供一个系统的学习路径和实操指南。此外,本文还探讨了如何利用Moran'I指数进行有效的空间数据分析和可视化,包括城市热岛效应的空间分析案例研究。最终,论文展望了空间统计学的未来
【Python数据处理秘籍】:专家教你如何高效清洗和预处理数据

# 摘要
随着数据科学的快速发展,Python作为一门强大的编程语言,在数据处理领域显示出了其独特的便捷性和高效性。本文首先概述了Python在数据处理中的应用,随后深入探讨了数据清洗的理论基础和实践,包括数据质量问题的认识、数据清洗的目标与策略,以及缺失值、异常值和噪声数据的处理方法。接着,文章介绍了Pandas和NumPy等常用Python数据处理库,并具体演示了这些库在实际数
【多物理场仿真:BH曲线的新角色】:探索其在多物理场中的应用
# 摘要
本文系统介绍了多物理场仿真的理论基础,并深入探讨了BH曲线的定义、特性及其在多种材料中的表现。文章详细阐述了BH曲线的数学模型、测量技术以及在电磁场和热力学仿真中的应用。通过对BH曲线在电机、变压器和磁性存储器设计中的应用实例分析,本文揭示了其在工程实践中的重要性。最后,文章展望了BH曲线研究的未来方向,包括多物理场仿真中BH曲线的局限性
【CAM350 Gerber文件导入秘籍】:彻底告别文件不兼容问题
# 摘要
本文全面介绍了CAM350软件中Gerber文件的导入、校验、编辑和集成过程。首先概述了CAM350与Gerber文件导入的基本概念和软件环境设置,随后深入探讨了Gerber文件格式的结构、扩展格式以及版本差异。文章详细阐述了在CAM350中导入Gerber文件的步骤,包括前期
【秒杀时间转换难题】:掌握INT、S5Time、Time转换的终极技巧
# 摘要
时间表示与转换在软件开发、系统工程和日志分析等多个领域中起着至关重要的作用。本文系统地梳理了时间表示的概念框架,深入探讨了INT、S5Time和Time数据类型及其转换方法。通过分析这些数据类型的基本知识、特点、以及它们在不同应用场景中的表现,本文揭示了时间转换在跨系统时间同步、日志分析等实际问题中的应用,并提供了优化时间转换效率的策略和最
【传感器网络搭建实战】:51单片机协同多个MLX90614的挑战

# 摘要
本论文首先介绍了传感器网络的基础知识以及MLX90614红外温度传感器的特点。接着,详细分析了51单片机与MLX90614之间的通信原理,包括51单片机的工作原理、编程环境的搭建,以及传感器的数据输出格式和I2C通信协议。在传感器网络的搭建与编程章节中,探讨了网络架构设计、硬件连接、控制程序编写以及软件实现和调试技巧。进一步
Python 3.9新特性深度解析:2023年必知的编程更新
# 摘要
随着编程语言的不断进化,Python 3.9作为最新版本,引入了多项新特性和改进,旨在提升编程效率和代码的可读性。本文首先概述了Python 3.
金蝶K3凭证接口安全机制详解:保障数据传输安全无忧
# 摘要
金蝶K3凭证接口作为企业资源规划系统中数据交换的关键组件,其安全性能直接影响到整个系统的数据安全和业务连续性。本文系统阐述了金蝶K3凭证接口的安全理论基础,包括安全需求分析、加密技术原理及其在金蝶K3中的应用。通过实战配置和安全验证的实践介绍,本文进一步阐释了接口安全配置的步骤、用户身份验证和审计日志的实施方法。案例分析突出了在安全加固中的具体威胁识别和解决策略,以及安全优化对业务性能的影响。最后
【C++ Builder 6.0 多线程编程】:性能提升的黄金法则
# 摘要
随着计算机技术的进步,多线程编程已成为软件开发中的重要组成部分,尤其是在提高应用程序性能和响应能力方面。C++ Builder 6.0作为开发工具,提供了丰富的多线程编程支持。本文首先概述了多线程编程的基础知识以及C++ Builder 6.0的相关特性,然后深入探讨了该环境下线程的创建、管理、同步机制和异常处理。接着,文章提供了多线程实战技巧,包括数据共享
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )