Spark编程基础:Scala语言基础知识深入剖析
发布时间: 2024-01-27 13:24:07 阅读量: 44 订阅数: 46 
# 1. Scala语言简介
## 1.1 Scala的起源和发展
Scala是一门多范式编程语言,由Martin Odersky和他的团队于2003年开发而成,最初发布于2004年。Scala最初被设计成要运行在Java虚拟机上,并集成了面向对象编程和函数式编程的特性。Scala的发展得到了良好的支持和反响,逐渐成为了一种流行的编程语言,被广泛应用于大数据领域(如Apache Spark)和分布式系统开发中。
## 1.2 Scala的特点和优势
Scala拥有许多特点和优势,包括但不限于:
- **兼具面向对象和函数式编程**:Scala支持面向对象编程的同时,也能够进行函数式编程,使得程序员可以更灵活地进行编程。
- **静态类型系统**:Scala的静态类型系统有助于捕捉更多的编程错误,在代码编写阶段提供更好的错误检查。
- **高阶函数和不可变性**:Scala提供了丰富的高阶函数和对不可变数据的严格支持,这有助于编写更加健壮和可复用的代码。
- **并发编程支持**:Scala内建了并发编程的特性,通过Actor模型和Future/Promise等机制,提供了简单、可靠的并发编程方式。
## 1.3 Scala与Java的关系
由于Scala可以编译成Java字节码并运行在JVM上,因此Scala和Java可以很好地进行互操作。Scala能够无缝调用Java的类和库,并且可以通过Java的框架进行大规模的软件开发。此外,Scala还借鉴了许多Java的语法和特性,使得Java程序员可以更快速地学习和掌握Scala语言。
接下来,我们将继续介绍Scala的基础语法。
# 2. Scala基础语法
在本章中,我们将介绍Scala语言的基础语法知识,包括变量和数据类型、控制流语句、集合类和函数式编程、以及模式匹配和样例类。让我们逐一深入了解。
### 2.1 变量和数据类型
Scala中的变量定义使用关键字`var`和`val`,`var`用于定义可变变量,而`val`用于定义不可变变量。Scala具有丰富的数据类型,包括整型、浮点型、布尔型、字符型,以及字符串等。示例如下:
```scala
var x: Int = 10 // 定义可变变量x,初始值为10
val y: String = "Hello" // 定义不可变变量y,初始值为"Hello"
```
### 2.2 控制流语句
Scala支持常见的控制流语句,包括if-else表达式、while循环、for循环以及match表达式。示例如下:
```scala
val age: Int = 20
if (age >= 18) {
println("成年人")
} else {
println("未成年人")
}
var i: Int = 0
while (i < 5) {
println(i)
i += 1
}
for (i <- 1 to 5) {
println(i)
}
val result = age match {
case 18 => "成年"
case _ => "未成年"
}
println(result)
```
### 2.3 集合类和函数式编程
Scala提供丰富的集合类,包括列表(List)、数组(Array)、映射(Map)等,同时也支持函数式编程风格的操作,如map、filter、reduce等。示例如下:
```scala
val list = List(1, 2, 3, 4, 5)
val doubled = list.map(_ * 2)
println(doubled) // 输出List(2, 4, 6, 8, 10)
val even = list.filter(_ % 2 == 0)
println(even) // 输出List(2, 4)
val sum = list.reduce(_ + _)
println(sum) // 输出15
```
### 2.4 模式匹配和样例类
模式匹配是Scala强大的特性之一,它可以用于匹配各种数据类型和结构,并且与样例类结合应用时尤为有效。示例如下:
```scala
case class Person(name: String, age: Int)
val alice = Person("Alice", 25)
val bob = Person("Bob", 30)
def greeting(p: Person): String = p match {
case Person("Alice", 25) => "Hi, Alice"
case Person("Bob", 30) => "Hello, Bob"
case Person(name, age) => s"Nice to meet you, $name"
}
println(greeting(alice)) // 输出"Hi, Alice"
println(greeting(bob)) // 输出"Hello, Bob"
```
通过本章的学习,我们对Scala基础语法有了初步的了解,包括变量和数据类型、控制流语句、集合类和函数式编程,以及模式匹配和样例类的应用。在接下来的章节中,我们将深入学习Scala的面向对象编程、函数式编程、并发编程,以及Spark编程基础。
# 3. Scala面向对象编程
Scala是一门支持面向对象编程(Object-Oriented Programming)的语言,也是一门函数式编程(Functional Programming)的语言。在这一章节中,我们将详细介绍Scala的面向对象编程的相关内容。
#### 3.1 类和对象的基本概念
在Scala中,类是对象的基本构建单元。类描述了对象的属性(字段)和行为(方法)。下面是一个简单的类的定义和对象的创建示例:
```scala
class Person(name: String, age: Int) {
def sayHello(): Unit = {
println(s"Hello, my name is ${name}. I am ${age} years old.")
}
}
val john = new Person("John", 30)
john.sayHello()
```
以上代码定义了一个名为`Person`的类,该类有一个构造函数,接受两个参数:`name`和`age`。类中的`sayHello`方法用于输出一条问候的信息。通过`new`关键字,我们可以创建一个`Person`类的实例,然后调用该实例的方法。
#### 3.2 继承和多态
在Scala中,我们可以通过继承的方式来扩展已有的类。子类可以继承父类的属性和方法,并在此基础上添加新的属性和方法。下面是一个继承示例:
```scala
class Student(name: String, age: Int, major: String) extends Person(name, age) {
def study(): Unit = {
println(s"I am studying ${major}.")
}
}
val alice = new Student("Alice", 20, "Computer Science")
alice.sayHello()
alice.study()
```
以上代码定义了一个名为`Student`的类,该类继承自`Person`类,并添加了新的属性`major`和方法`study`。我们可以创建一个`Student`类的实例,并调用继承自父类的方法以及自身新增的方法。
#### 3.3 特质和混入
在Scala中,特质(Trait)是一种用于定义可复用的方法和字段的机制。类可以混入(Mix-in)一个或多个特质,以获得特质中定义的方法和字段。下面是一个特质和混入示例:
```scala
trait Speaker {
def speak(): Unit
}
class Dog extends Speaker {
override def speak(): Unit = {
println("Woof")
}
}
class Cat extends Speaker {
override def speak(): Unit = {
println("Meow")
}
}
val dog = new Dog()
dog.speak()
val cat = new Cat()
cat.speak()
```
以上代码定义了一个名为`Speaker`的特质,该特质中有一个抽象方法` speak`。然后我们分别创建了`Dog`和`Cat`两个类,并将`Speaker`特质混入这两个类中。最后我们可以调用这两个类的`speak`方法。
#### 3.4 类型参数化和上下文界定
在Scala中,我们可以使用类型参数化(Type Parameterization)来创建泛型类和方法。使用类型参数化,可以使得类或方法更加灵活、可复用。下面是一个类型参数化的示例:
```scala
class Stack[A] {
private var elements: List[A] = Nil
def push(element: A): Unit = {
elements = element :: elements
}
def pop(): A = {
val top = elements.head
elements = elements.tail
top
}
}
val stack = new Stack[Int]()
stack.push(1)
stack.push(2)
println(stack.pop())
```
以上代码定义了一个名为`Stack`的类,并使用类型参数`A`来表示栈中的元素类型。我们可以创建一个`Stack`类

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
《Spark编程基础》是一本打造大数据技术掌握者的专栏,它深入探索了Spark编程的基础知识和技巧。专栏的第一篇文章《Spark编程基础:大数据技术综述》为读者提供了关于大数据技术的全面概述,从而为后续的学习打下坚实的基础。专栏的其他文章涵盖了Spark编程的各个方面,包括Spark的安装与配置、Spark的核心概念与架构、RDD的操作与转换、Spark SQL的使用、Spark Streaming和机器学习等。每篇文章都以简明扼要的方式解释了概念和原理,并提供了丰富的实例和案例,帮助读者理解和应用Spark编程。无论是初学者还是有一定经验的开发者,都能从本专栏中获得有关Spark编程的宝贵知识和技巧。无论是用于数据分析、机器学习还是实时处理,Spark编程基础专栏都是您迈向大数据技术领域的必备指南。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【硬件实现】:如何构建性能卓越的PRBS生成器

# 摘要
本文全面探讨了伪随机二进制序列(PRBS)生成器的设计、实现与性能优化。首先,介绍了PRBS生成器的基本概念和理论基础,重点讲解了其工作原理以及相关的关键参数,如序列长度、生成多项式和统计特性。接着,分析了PRBS生成器的硬件实现基础,包括数字逻辑设计、FPGA与ASIC实现方法及其各自的优缺点。第四章详细讨论了基于FPGA和ASIC的PRBS设计与实现过程,包括设计方法和验
NUMECA并行计算核心解码:掌握多节点协同工作原理
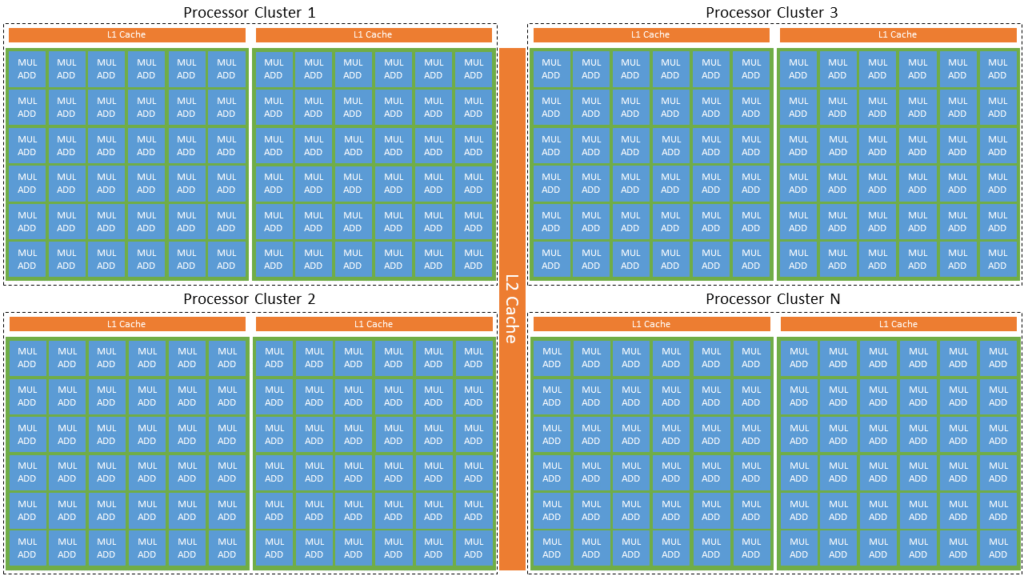
# 摘要
NUMECA并行计算是处理复杂计算问题的高效技术,本文首先概述了其基础概念及并行计算的理论基础,随后深入探讨了多节点协同工作原理,包括节点间通信模式以及负载平衡策略。通过详细说明并行计算环境搭建和核心解码的实践步骤,本文进一步分析了性能评估与优化的重要性。文章还介绍了高级并行计算技巧,并通过案例研究展示了NUMECA并行计算的应用。最后,本文展望了并行计
提升逆变器性能监控:华为SUN2000 MODBUS数据优化策略

# 摘要
逆变器作为可再生能源系统中的关键设备,其性能监控对于确保系统稳定运行至关重要。本文首先强调了逆变器性能监控的重要性,并对MODBUS协议进行了基础介绍。随后,详细解析了华为SUN2000逆变器的MODBUS数据结构,阐述了数据包基础、逆变器的注册地址以及数据的解析与处理方法。文章进一步探讨了性能数据的采集与分析优化策略,包括采集频率设定、异常处理和高级分析技术。
小红书企业号认证必看:15个常见问题的解决方案

# 摘要
本文系统地介绍了小红书企业号的认证流程、准备工作、认证过程中的常见问题及其解决方案,以及认证后的运营和维护策略。通过对认证前准备工作的详细探讨,包括企业资质确认和认证材料
FANUC面板按键深度解析:揭秘操作效率提升的关键操作
# 摘要
FANUC面板按键作为工业控制中常见的输入设备,其功能的概述与设计原理对于提高操作效率、确保系统可靠性及用户体验至关重要。本文系统地介绍了FANUC面板按键的设计原理,包括按键布局的人机工程学应用、触觉反馈机制以及电气与机械结构设计。同时,本文也探讨了按键操作技巧、自定义功能设置以及错误处理和维护策略。在应用层面,文章分析了面板按键在教育培训、自动化集成和特殊行业中的优化策略。最后,本文展望了按键未来发展趋势,如人工智能、机器学习、可穿戴技术及远程操作的整合,以及通过案例研究和实战演练来提升实际操作效率和性能调优。
# 关键字
FANUC面板按键;人机工程学;触觉反馈;电气机械结构
【UML类图与图书馆管理系统】:掌握面向对象设计的核心技巧
# 摘要
本文旨在探讨面向对象设计中UML类图的应用,并通过图书馆管理系统的需求分析、设计、实现与测试,深入理解UML类图的构建方法和实践。文章首先介绍了UML类图基础,包括类图元素、关系类型以及符号规范,并详细讨论了高级特性如接口、依赖、泛化以及关联等。随后,文章通过图书馆管理系统的案例,展示了如何将UML类图应用于需求分析、系统设计和代码实现。在此过程中,本文强调了面向对象设计原则,评价了UML类图在设计阶段
【虚拟化环境中的SPC-5】:迎接虚拟存储的新挑战与机遇
# 摘要
本文旨在全面介绍虚拟化环境与SPC-5标准,深入探讨虚拟化存储的基础理论、存储协议与技术、实践应用案例,以及SPC-5标准在虚拟化环境中的应用挑战。文章首先概述了虚拟化技术的分类、作用和优势,并分析了不同架构模式及SPC-5标准的发展背景。随后
硬件设计验证中的OBDD:故障模拟与测试的7大突破
# 摘要
OBDD(有序二元决策图)技术在故障模拟、测试生成策略、故障覆盖率分析、硬件设计验证以及未来发展方面展现出了强大的优势和潜力。本文首先概述了OBDD技术的基础知识,然后深入探讨了其在数字逻辑故障模型分析和故障检测中的应用。进一步地,本文详细介绍了基于OBDD的测试方法,并分析了提高故障覆盖率的策略。在硬件设计验证章节中,本文通过案例分析,展示了OBDD的构建过程、优化技巧及在工业级验证中的应用。最后,本文展望了OBDD技术与机器学习等先进技术的融合,以及OBDD工具和资源的未来发展趋势,强调了OBDD在AI硬件验证中的应用前景。
# 关键字
OBDD技术;故障模拟;自动测试图案生成
海康威视VisionMaster SDK故障排除:8大常见问题及解决方案速查
# 摘要
本文全面介绍了海康威视VisionMaster SDK的使用和故障排查。首先概述了SDK的特点和系统需求,接着详细探讨了
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )