文件操作与输入输出:Python中的数据处理技巧
发布时间: 2024-04-09 07:23:34 阅读量: 54 订阅数: 21 

数据分析+python处理技巧
# 1. Python中的文件操作基础
在Python中,文件操作是进行数据处理不可或缺的一部分,能够帮助我们读取、写入数据,进行文件的打开和关闭操作,以及对文件路径进行操作。在本章节中,我们将深入探讨Python中文件操作的基础知识和技巧。
## 1.1 文件读取与写入
文件读取和写入是文件操作中的核心操作之一。通过Python提供的内置函数和方法,我们可以轻松地读取文本文件中的内容,并将数据写入到文件中。
```python
# 读取文件内容
with open("example.txt", "r") as file:
data = file.read()
print(data)
# 写入文件内容
with open("output.txt", "w") as file:
file.write("Hello, world!")
```
**代码总结:** 通过`open()`函数以只读模式("r")或写入模式("w")打开文件,并使用`read()`方法读取文件内容,或使用`write()`方法向文件中写入数据。
**结果说明:** 以上代码展示了如何读取一个文本文件的内容,并将数据写入另一个文件中。
## 1.2 文件打开与关闭操作
在文件操作过程中,打开文件是必不可少的。确保在文件操作结束后进行文件的关闭操作,这样可以释放资源并防止出现意外的文件写入问题。
```python
# 打开文件
file = open("example.txt", "r")
data = file.read()
print(data)
# 关闭文件
file.close()
```
**代码总结:** 通过`open()`函数打开文件,并在文件操作结束后使用`close()`方法关闭文件。
## 1.3 文件路径操作技巧
在处理文件路径时,经常需要进行文件路径的拼接、获取文件名等操作。Python的`os`模块提供了丰富的方法来操作文件路径。
```python
import os
# 获取当前工作目录
current_dir = os.getcwd()
print("Current Directory:", current_dir)
# 拼接文件路径
file_path = os.path.join(current_dir, "example.txt")
print("File Path:", file_path)
# 获取文件名
file_name = os.path.basename(file_path)
print("File Name:", file_name)
```
**代码总结:** 使用`os`模块中的函数来获取当前工作目录、拼接文件路径和获取文件名等操作。
通过本章节的学习,我们掌握了Python中文件操作的基础知识,包括文件读取与写入、文件打开与关闭操作,以及文件路径操作技巧。这些知识将为我们后续的数据处理和分析提供强大的支持。
# 2. 数据输入输出方法综述
数据的输入输出是数据处理中至关重要的一环,在Python中有多种方法可以实现数据的输入输出。本章将综述Python中常见的数据输入输出方法,包括标准输入输出、文件输入输出以及字符串输入输出。让我们一起来了解吧!
### 2.1 标准输入输出
在Python中,可以通过`input()`函数实现标准输入,通过`print()`函数实现标准输出。下面是一个简单的示例:
```python
# 标准输入
name = input("请输入您的姓名:")
print("您好,", name)
# 标准输出
age = 25
print("您的年龄是:", age)
```
**代码说明:** 上述代码中,通过`input()`函数获取用户输入的姓名,通过`print()`函数输出问候语。同时输出固定的年龄信息。
### 2.2 文件输入输出
Python中通过`open()`函数来打开文件,并使用`read()`、`write()`等方法实现文件的读取与写入操作。下面是一个文件读取和写入的示例:
```python
# 文件读取
with open("data.txt", "r") as file:
data = file.read()
print(data)
# 文件写入
with open("output.txt", "w") as file:
file.write("这是要写入到文件中的内容")
```
**代码说明:** 上述代码中,通过`open()`函数打开名为"data.txt"的文件进行读取操作,然后通过`write()`方法将内容写入名为"output.txt"的文件中。
### 2.3 字符串输入输出
字符串的输入输出操作也是数据处理中常见的操作之一。可以通过格式化符号或者其他字符串处理方法实现字符串的拼接、截取等操作。示例如下:
```python
# 字符串拼接
str1 = "Hello"
str2 = "World"
result = str1 + " " + str2
print(result)
# 字符串截取
text = "Python Programming"
substring = text[7:]
print(substring)
```
**代码说明:** 上述代码中,通过`+`号实现字符串的拼接,通过索引实现字符串的截取。
通过以上示例,我们了解了Python中数据输入输出的常见方法,包括标准输入输出、文件输入输出以及字符串输入输出。在实际数据处理中,根据需求选择合适的输入输出方法是十分重要的。
# 3. 数据处理工具介绍
数据处理在Python中是一项非常重要的任务,而有一些强大的工具可以帮助我们高效地进行数据处理。在本章节中,我们将介绍一些常用的数据处理工具,包括Pandas库、NumPy库和Matplotlib库。
#### 3.1 Pandas库数据处理
Pandas是一个强大的数据分析库,提供了许多用于数据处理和分析的数据结构和函数。以下是一个简单示例,展示如何使用Pandas加载一个CSV文件并进行简单的数据处理:
```python
import pandas as pd
# 加载CSV文件
data = pd.read_csv('data.csv')
# 显示数据前5行
print(data.head())
```
通过Pandas库,我们可以轻松地加载数据、进行数据清洗、筛选、排序等操作,极大地提高了数据处理的效率。
#### 3.2 NumPy库数据处理
NumPy是Python中用于科学计算的核心库,提供了高性能的多维数组对象以及各种函数。下面是一个使用NumPy库进行数组运算的示例:
```python
import numpy as np
# 创建一个数组
arr = np.array([1, 2, 3, 4, 5])
# 计算数组的平均值
mean_value = np.mean(arr)
print("Mean Value:", mean_value)
```
NumPy库的强大之处在于可以高效地进行数组运算,适用于处理大规模数据集。
#### 3.3 Matplotlib库数据可视化
Matplotlib是Python中常用的绘图库,可以创建各种高质量的图表,从简单的折线图到复杂的热力图。以下是一个简单的示例,展示如何使用Matplotlib绘制折线图:
```python
import matplotlib.pyplot as plt
# 数据
x = [1, 2, 3, 4, 5]
y = [5, 4, 3, 2, 1]
# 绘制折线图
plt.plot(x, y)
plt.xlabel('X-axis')
plt.ylabel('Y-axis')
plt.title('Simple Line Plot')
plt.show()
```
Matplotlib库可以帮助我们直观地展示数据,从而更好地理解数据的特征和趋势。
通过Pandas库、NumPy库和Matplotlib库,我们可以对数据进行高效处理、分析和可视化,提高工作效率并做出更加准确的决策。
# 4. 数据清洗与预处理
在数据处理过程中,数据清洗与预处理是至关重要的步骤。本章将介绍一些常用的数据清洗与预处理技巧,包括如何处理缺失值、去重与重复值处理、数据类型转换与格式化等。
#### 4.1 缺失值处理
缺失值是指数据中的某些字段没有数值或数值为NaN。在实际数据处理中,我们需要考虑如何处理这些缺失值,以确保数据分析的准确性。
```python
# 示例:使用 Pandas 库处理缺失值
import pandas as pd
# 创建含有缺失值的 DataFrame
data = {'A': [1, 2, None, 4],
'B': ['apple', 'banana', 'cherry', None]}
df = pd.DataFrame(data)
# 查看含有缺失值的数据
print("含有缺失值的数据:")
print(df)
# 填充缺失值为特定值(如 0)
df_filled = df.fillna(0)
print("\n缺失值填充后的数据:")
print(df_filled)
# 删除含有缺失值的行
df_dropped = df.dropna()
print("\n删除含有缺失值的行后的数据:")
print(df_dropped)
```
**代码总结:** 上述代码演示了如何使用 Pandas 库处理含有缺失值的数据,通过填充特定值或删除含有缺失值的行来处理缺失值。
**结果说明:**
- 填充缺失值后的数据会将缺失值替换为指定值;
- 删除含有缺失值的行后,数据框中不再包含缺失值所在的行。
#### 4.2 数据去重与重复值处理
在数据处理过程中,经常会遇到重复值的情况,需要对数据进行去重操作。
```python
# 示例:去除重复值
import pandas as pd
# 创建含有重复值的 DataFrame
data = {'A': [1, 2, 2, 3, 4],
'B': ['apple', 'banana', 'banana', 'cherry', None]}
df = pd.DataFrame(data)
# 查看含有重复值的数据
print("含有重复值的数据:")
print(df)
# 去除重复值
df_deduped = df.drop_duplicates()
print("\n去除重复值后的数据:")
print(df_deduped)
```
**代码总结:** 以上代码展示了使用 Pandas 库去除重复值的过程,通过`drop_duplicates()`方法实现去重操作。
**结果说明:**
- 去除重复值后,数据框中不再包含重复的行。
#### 4.3 数据类型转换与格式化
在数据处理过程中,有时需要将数据从一种类型转换为另一种类型,或对数据进行特定格式的调整。
```python
# 示例:数据类型转换与格式化
import pandas as pd
# 创建含有不同数据类型的 Series
data = {'A': ['1', '2', '3'],
'B': ['10.5', '20.6', '30.7']}
df = pd.DataFrame(data)
# 查看数据类型
print("数据类型:")
print(df.dtypes)
# 将字符串转换为整数类型
df['A'] = df['A'].astype(int)
# 将字符串转换为浮点数类型
df['B'] = df['B'].astype(float)
print("\n转换后的数据类型:")
print(df.dtypes)
```
**代码总结:** 以上代码展示了如何使用 Pandas 库进行数据类型转换,通过`astype()`方法将字符串转换为整数或浮点数类型。
**结果说明:**
- 转换后,数据框中的数据类型已经从字符串转换为对应的整数或浮点数类型。
通过以上内容,我们可以更加灵活地处理数据中的缺失值、重复值以及进行数据类型转换与格式化,为后续的数据分析与统计工作打下良好的基础。
# 5. 数据分析与统计
数据分析与统计是数据处理过程中至关重要的一部分,它帮助我们从海量的数据中提取有用信息,并进行有效的决策和预测。在Python中,有许多强大的工具和库可以帮助我们实现数据分析与统计任务。接下来将介绍一些常用的数据分析与统计技巧。
**5.1 数据聚合与分组**
在数据处理过程中,经常需要对数据进行聚合操作,比如对数据进行分组计算、求和、平均值等操作。Pandas库提供了一个强大的功能`groupby`,可以轻松实现数据聚合。
```python
import pandas as pd
# 创建示例数据
data = {'Name': ['Alice', 'Bob', 'Alice', 'Bob', 'Alice'],
'Score': [85, 90, 88, 92, 87]}
df = pd.DataFrame(data)
# 按照姓名分组,计算平均成绩
grouped = df.groupby('Name').mean()
print(grouped)
```
**代码说明:**
- 首先导入`pandas`库。
- 创建一个包含姓名和成绩的示例数据。
- 使用`groupby`方法按照姓名分组,然后计算每组的平均成绩。
- 最后输出每个人的平均成绩。
**结果说明:**
输出结果是按照姓名分组后的平均成绩:
```
Score
Name
Alice 86.67
Bob 91.00
```
**5.2 数据筛选与排序**
数据筛选与排序是数据分析过程中常用的操作,可以帮助我们找到特定条件下的数据或者对数据进行排序。在Pandas库中,可以通过逻辑运算和`sort_values`方法实现数据筛选和排序。
```python
# 筛选出成绩大于90分的数据
high_score = df[df['Score'] > 90]
print(high_score)
# 按照成绩降序排序
sorted_df = df.sort_values(by='Score', ascending=False)
print(sorted_df)
```
**代码说明:**
- 对数据框筛选出成绩大于90分的数据。
- 对数据框按照成绩降序排序。
- 输出筛选后的数据和排序后的数据。
**结果说明:**
第一个打印语句输出成绩大于90分的数据:
```
Name Score
3 Bob 92
```
第二个打印语句输出按照成绩降序排序后的数据:
```
Name Score
3 Bob 92
2 Alice 88
4 Alice 87
1 Bob 90
0 Alice 85
```
**5.3 数据统计与描述性分析**
数据统计和描述性分析是了解数据整体情况和特征的重要步骤,常用的统计指标包括平均值、中位数、标准差等。Pandas库提供了`describe`方法可以一次性输出所有这些统计指标。
```python
# 对数据进行描述性统计分析
statistics = df.describe()
print(statistics)
```
**代码说明:**
- 使用`describe`方法对数据进行描述性统计分析。
- 输出包括平均值、标准差、最大值、最小值等统计指标。
**结果说明:**
输出的统计分析结果如下:
```
Score
count 5.000000
mean 88.400000
std 2.880972
min 85.000000
25% 87.000000
50% 88.000000
75% 90.000000
max 92.000000
```
通过以上方法,可以实现数据分析与统计过程中常用的聚合、筛选、排序和描述性分析等操作。这些技巧可以帮助我们更好地理解数据,并从中获取有用信息。
# 6. 案例分析与实战演练
在本章节中,我们将通过实际案例分析和实战演练来展示Python中的数据处理技巧。我们将结合各种数据处理工具和方法,为您呈现一个完整的数据处理实例。让我们一起来看看吧!
#### 6.1 实际数据处理案例分析
在这个部分,我们将展示一个实际的数据处理案例,通过Python代码逐步实现数据清洗、分析和可视化过程。我们将使用Pandas、NumPy和Matplotlib等库来完成这一案例。让我们开始吧!
```python
# 导入所需库
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
# 读取数据文件
data = pd.read_csv('data.csv')
# 查看数据结构
print(data.head())
# 数据清洗与处理
# 处理缺失值
data.dropna(inplace=True)
# 数据分析与统计
# 统计描述性信息
print(data.describe())
# 数据可视化
plt.figure(figsize=(10, 6))
plt.scatter(data['x'], data['y'])
plt.title('Scatter Plot of x vs. y')
plt.xlabel('x')
plt.ylabel('y')
plt.show()
```
通过上述代码,我们展示了一个简单的数据处理案例,包括数据读取、清洗、分析和可视化的全过程。这将帮助您更好地理解Python中的数据处理技巧。
#### 6.2 基于Python的数据处理实战项目
在这个部分,我们将介绍一个基于Python的数据处理实战项目,让您通过实际项目实战来提升数据处理技能。项目涵盖数据收集、清洗、分析和展示等全部步骤,帮助您更好地应用所学知识。
#### 6.3 数据处理技巧与注意事项总结
在最后一部分,我们将总结数据处理过程中的一些技巧和注意事项,帮助您在实际项目中更加高效地处理数据。这些技巧包括数据清洗的常见问题、数据分析的注意事项等,让您能够更加游刃有余地进行数据处理工作。
希望这些案例分析和实战演练能够帮助您更好地理解和应用Python中的数据处理技巧!

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏是 Python 官方网站提供的全面学习资源,涵盖了从基础入门到高级应用的各个方面。专栏通过一系列深入的文章,带领读者从 Hello World 开始,逐步探索 Python 的数据类型、条件语句、循环结构、函数、数据结构、面向对象编程、异常处理、文件操作、正则表达式、模块和包管理、高级函数、并发编程、网络编程、爬虫、数据处理、数据可视化、机器学习、深度学习、自然语言处理和图像处理等重要概念。专栏旨在帮助读者全面掌握 Python 编程语言,并将其应用于实际项目中。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【VS2022升级全攻略】:全面破解.NET 4.0包依赖难题
# 摘要
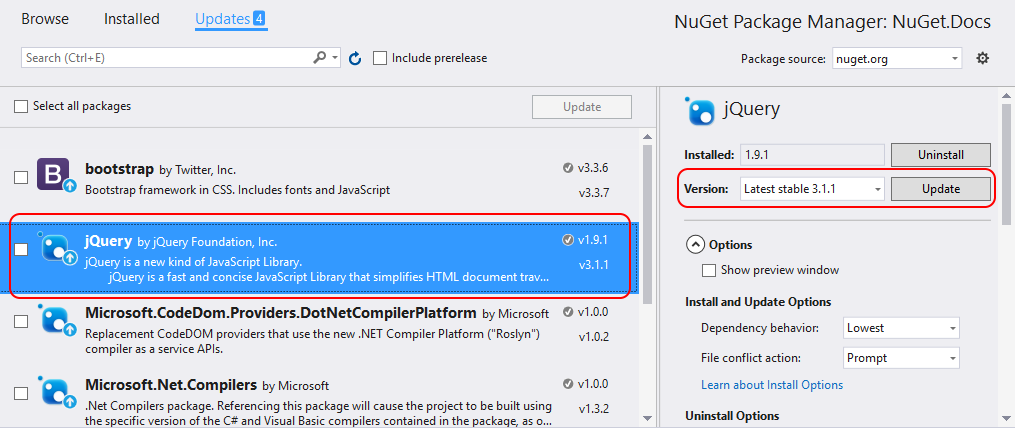
本文对.NET 4.0包依赖问题进行了全面概述,并探讨了.NET框架升级的核心要素,包括框架的历史发展和包依赖问题的影响。文章详细分析了升级到VS2022的必要性,并提供了详细的升级步骤和注意事项。在升级后,本文着重讨论了VS2022中的包依赖管理新工具和方法,以及如何解决升级中遇到的问题,并对升级效果进行了评估。最后,本文展望了.NET框架的未来发
【ALU设计实战】:32位算术逻辑单元构建与优化技巧

# 摘要
算术逻辑单元(ALU)作为中央处理单元(CPU)的核心组成部分,在数字电路设计中起着至关重要的作用。本文首先概述了ALU的基本原理与功能,接着详细介绍32位ALU的设计基础,包括逻辑运算与算术运算单元的设计考量及其实现。文中还深入探讨了32位ALU的设计实践,如硬件描述语言(HDL)的实现、仿真验证、综合与优化等关
【网络效率提升实战】:TST性能优化实用指南

# 摘要
本文全面综述了TST性能优化的理论与实践,首先介绍了性能优化的重要性及基础理论,随后深入探讨了TST技术的工作原理和核心性能影响因素,包括数据传输速率、网络延迟、带宽限制和数据包处理流程。接着,文章重点讲解了TST性能优化的实际技巧,如流量管理、编码与压缩技术应用,以及TST配置与调优指南。通过案例分析,本文展示了TST在企业级网络效率优化中的实际应用和性能提升措施,并针对实战
【智能电网中的秘密武器】:揭秘输电线路模型的高级应用

# 摘要
本文详细介绍了智能电网中输电线路模型的重要性和基础理论,以及如何通过高级计算和实战演练来提升输电线路的性能和可靠性。文章首先概述了智能电网的基本概念,并强调了输电线路模型的重要性。接着,深入探讨了输电线路的物理构成、电气特性、数学表达和模拟仿真技术。文章进一步阐述了稳态和动态分析的计算方法,以及优化算法在输电线路模型中的应用。在实际应用方面,本文分析了实时监控、预测模型构建和维护管理策略。此外,探讨了当前技术面临的挑战和未来发展趋势,包括人
【扩展开发实战】:无名杀Windows版素材压缩包分析
# 摘要
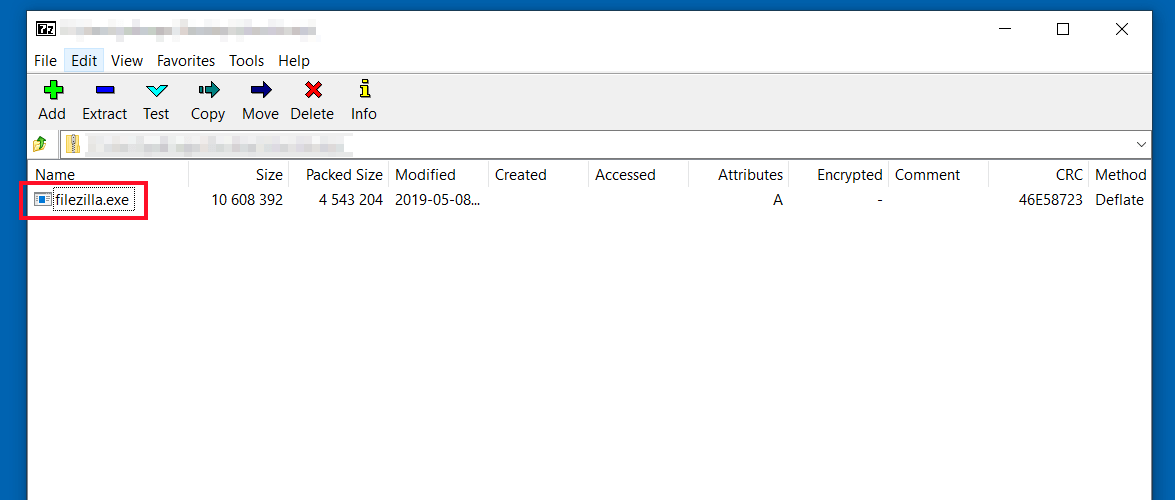
本论文对无名杀Windows版素材压缩包进行了全面的概述和分析,涵盖了素材压缩包的结构、格式、数据提取技术、资源管理优化、安全性版权问题以及拓展开发与应用实例。研究指出,素材压缩包是游戏运行不可或缺的组件,其结构和格式的合理性直接影响到游戏性能和用户体验。文中详细分析了压缩算法的类型、标准规范以及文件编码的兼容性。此外,本文还探讨了高效的数据提取技
【软件测试终极指南】:10个上机练习题揭秘测试技术精髓
# 摘要
软件测试作为确保软件质量和性能的重要环节,在现代软件工程中占有核心地位。本文旨在探讨软件测试的基础知识、不同类型和方法论,以及测试用例的设计、执行和管理策略。文章从静态测试、动态测试、黑盒测试、白盒测试、自动化测试和手动测试等多个维度深入分析,强调了测试用例设计原则和测试数据准备的重要性。同时,本文也关注了软件测试的高级技术,如性能测试、安全测试以及移动
【NModbus库快速入门】:掌握基础通信与数据交换
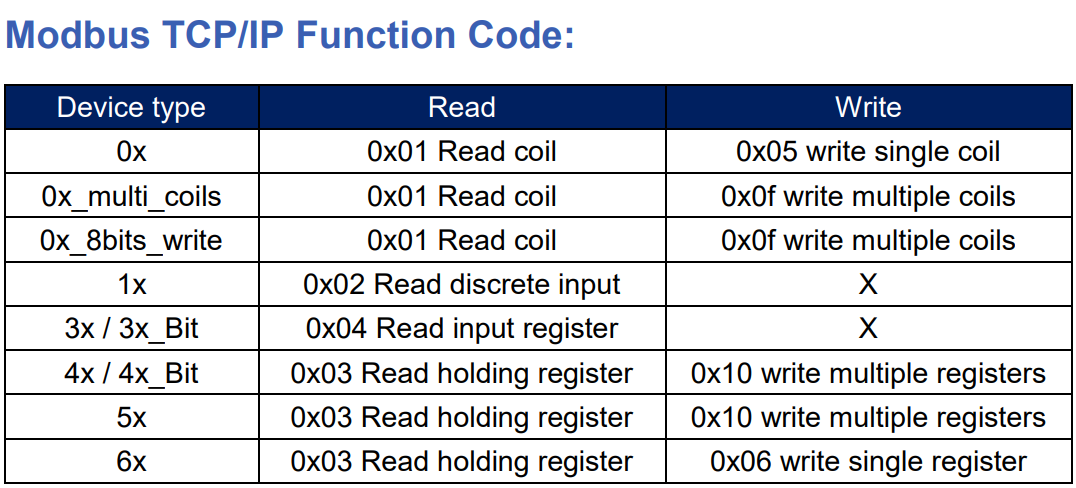
# 摘要
本文全面介绍了NModbus库的特性和应用,旨在为开发者提供一个功能强大且易于使用的Modbus通信解决方案。首先,概述了NModbus库的基本概念及安装配置方法,接着详细解释了Modbus协议的基础知识以及如何利用NModbus库进行基础的读写操作。文章还深入探讨了在多设备环境中的通信管理,特殊数据类型处理以及如何定
单片机C51深度解读:10个案例深入理解程序设计
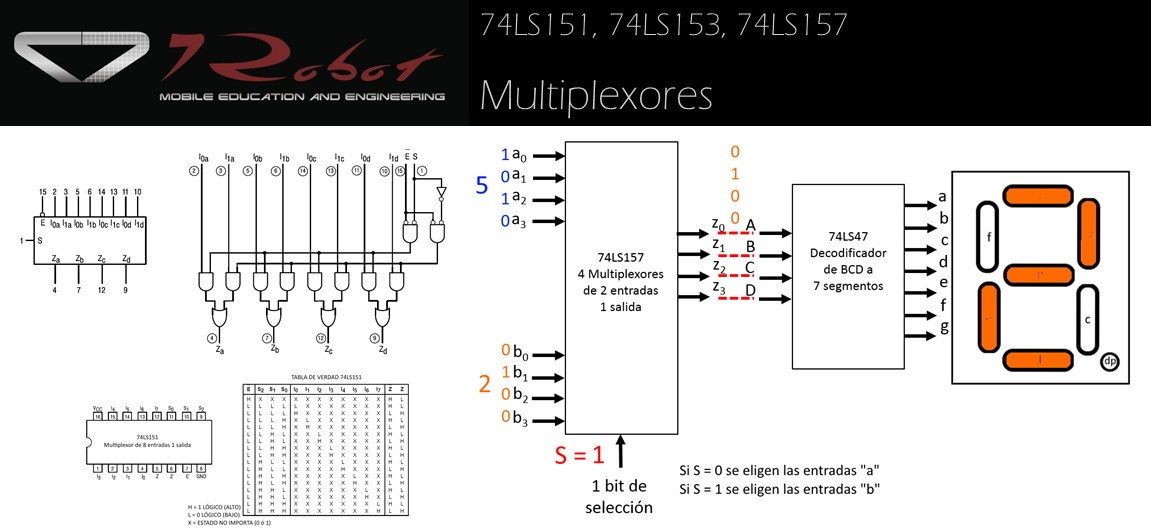
# 摘要
本文系统地介绍了基于C51单片机的编程及外围设备控制技术。首先概述了C51单片机的基础知识,然后详细阐述了C51编程的基础理论,包括语言基础、高级编程特性和内存管理。随后,文章深入探讨了单片机硬件接口操作,涵盖输入/输出端口编程、定时器/计数器编程和中断系统设计。在单片机外围设备控制方面,本文讲解了串行通信、ADC/DAC接口控制及显示设备与键盘接口的实现。最后,通过综合案例分
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )