自然语言处理技术与实践
发布时间: 2024-01-02 19:41:01 阅读量: 32 订阅数: 41 

自然语言处理技术在金融资管领域的落地实践(49页).pdf
# 1. 导论
## 1.1 什么是自然语言处理技术
自然语言处理(Natural Language Processing, NLP)是人工智能领域的一个重要分支,旨在让计算机能够理解、解释和处理人类语言的技术。NLP的核心目标是实现计算机对自然语言的真正理解,使计算机能够像人类一样理解语言,并能够通过语言与人类进行有效的交流。
NLP技术可以帮助计算机理解并处理人们使用的自然语言,而自然语言通常是不规则的、多义的,因此NLP技术的研究和应用充满了挑战。
## 1.2 自然语言处理技术的应用领域
自然语言处理技术在许多领域都有着广泛的应用,包括但不限于:
- 人机交互:智能语音助手、聊天机器人等
- 信息检索与文本挖掘:搜索引擎、情感分析、舆情监控等
- 机器翻译:各类语言翻译、语言理解
- 自然语言生成:自动摘要、文本生成、写作助手
- 语音识别与合成:语音识别、合成对话、读写辅助等
## 1.3 自然语言处理技术的历史发展
自然语言处理技术源远流长,可以追溯至20世纪50年代。早期的NLP主要集中在语言分析和信息抽取上,但随着机器学习和深度学习等技术的发展,自然语言处理技术取得了长足的进步。近年来,随着大数据、云计算和强大的硬件设施的发展,NLP技术得到了迅速的发展并在各个领域得到了广泛的应用。
# 2. 基本概念与原理
自然语言处理技术涉及了许多基本概念与原理,下面我们将逐一介绍其中的几个关键概念。
#### 2.1 语言模型
在自然语言处理中,语言模型是指对语言的概率分布进行建模的过程。一个好的语言模型能够很好地捕捉到语言的结构和规律,从而有助于词语、句子的生成和理解。常见的语言模型包括n-gram模型和基于神经网络的语言模型。
```python
# Python示例代码
import nltk
from nltk.util import ngrams
from collections import Counter
# 构建3-gram语言模型
text = "This is a simple example for demonstrating n-gram language model"
tokens = nltk.word_tokenize(text)
three_grams = list(ngrams(tokens, 3))
# 统计频率
ngram_counts = Counter(three_grams)
print(ngram_counts)
```
解释:以上代码使用nltk库构建了一个3-gram语言模型,并统计了给定文本中的3-gram的频率。
#### 2.2 词法分析
词法分析是自然语言处理中的重要步骤,它涉及对文本进行分词、词性标注等操作。词法分析的准确性对后续步骤的影响非常大。
```java
// Java示例代码
import opennlp.tools.tokenize.SimpleTokenizer;
import opennlp.tools.postag.POSTaggerME;
import opennlp.tools.postag.POSModel;
import java.io.FileInputStream;
import java.io.IOException;
public class LexicalAnalysis {
public static void main(String[] args) throws IOException {
// 加载词性标注模型
FileInputStream modelIn = new FileInputStream("en-pos-maxent.bin");
POSModel posModel = new POSModel(modelIn);
POSTaggerME posTagger = new POSTaggerME(posModel);
// 分词
SimpleTokenizer tokenizer = SimpleTokenizer.INSTANCE;
String sentence = "Part of speech tagging is an important task in lexical analysis.";
String[] tokens = tokenizer.tokenize(sentence);
// 词性标注
String[] tags = posTagger.tag(tokens);
for (int i = 0; i < tokens.length; i++) {
System.out.println(tokens[i] + "_" + tags[i]);
}
}
}
```
解释:以上代码使用OpenNLP库进行词性标注,对给定的句子进行了分词和词性标注操作。
#### 2.3 句法分析
句法分析是自然语言处理中的一个重要技术,它涉及分析句子的结构和成分之间的关系。常见的句法分析方法包括基于规则的分析和基于统计的分析。
```go
// Go示例代码
package main
import (
"fmt"
"github.com/slanglab/nlp"
)
func main() {
// 进行句法分析
text := "The cat sat on the mat."
doc, _ := nlp.NewDocument(text)
sentences := doc.Sentences()
for _, sentence := range sentences {
relations := sentence.SyntaxDependencies()
fmt.Println(relations)
}
}
```
解释:以上代码使用SlangLab的NLP库进行了句法分析,输出了句子中的语法依存关系。
#### 2.4 语义分析
语义分析是指对文本进行意思理解和推断的过程,它涉及到词义消歧、指代消解等任务。
```javascript
// JavaScript示例代码
const natural = require('natural');
const tokenizer = new natural.WordTokenizer();
const metaphone = natural.Metaphone;
// 词义消歧
console.log(metaphone.process('write')); // 输出:RT
// 指代消解
const text = "John is a doctor. He is a specialist in cardiology.";
const pronounResolution = natural.PronounResolution();
console.log(pronounResolution.resolve(text)); // 输出:John is a doctor. John is a specialist
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
"llm"专栏囊括了涵盖数据科学、人工智能、云计算、自然语言处理、Web开发等多个热门领域的精华内容。从"初识深度学习"到"机器计算实践","React Hooks完全指南"到"Docker容器化技术实战指南",以及"RESTful API设计与实践"到"人工智能辅助决策系统设计与应用"等主题均得到了涵盖。这个专栏以丰富的知识体系,完整的实践教程吸引着广大技术爱好者和专业人士。不仅如此,该专栏还提供了对于Python、Node.js、AWS云计算平台、JavaScript函数式编程、C并发编程等工具和技术的深入指导。无论你是初学者还是资深从业者,"llm"专栏都将会为你提供最前沿、最全面、最实用的专业知识,助你在技术领域更上一层楼。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
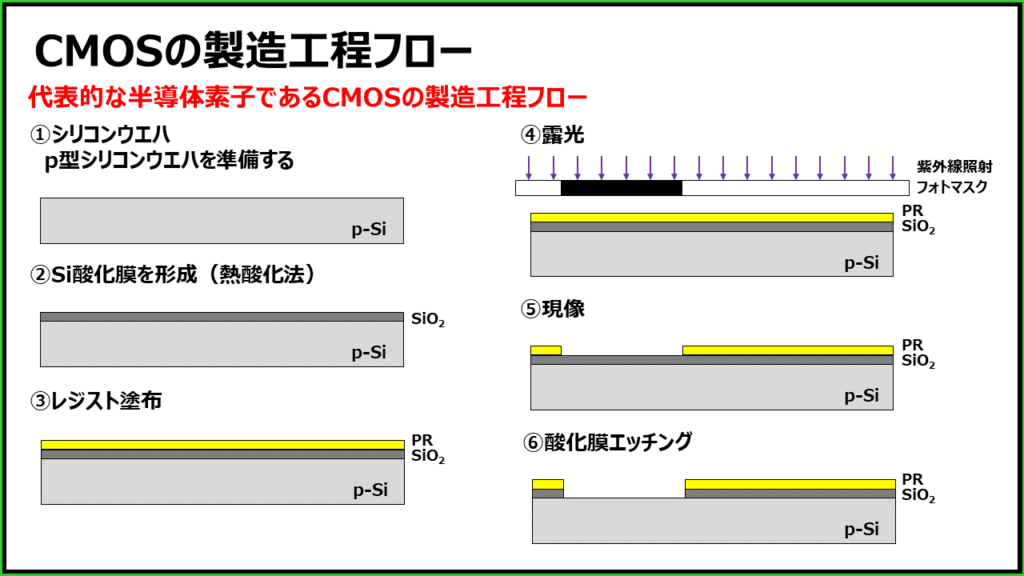
【CMOS集成电路设计实战解码】:从基础到高级的习题详解,理论与实践的完美融合
# 摘要
CMOS集成电路设计是现代电子系统中不可或缺的一环,本文全面概述了CMOS集成电路设计的关键理论和实践操作。首先,介绍了CMOS技术的基础理论,包括晶体管工作机制、逻辑门设计基础、制造流程和仿真分析。接着,深入探讨了CMOS集成电路的设计实践,涵盖了反相器与逻辑门设计、放大器与模拟电路设计,以及时序电路设计。此外,本文还
CCS高效项目管理:掌握生成和维护LIB文件的黄金步骤

# 摘要
本文深入探讨了CCS项目管理和LIB文件的综合应用,涵盖了项目设置、文件生成、维护优化以及实践应用的各个方面。文中首先介绍了CCS项目的创建与配置、编译器和链接器的设置,然后详细阐述了LIB文件的生成原理、版本控制和依赖管理。第三章重点讨论了LIB文件的代码维护、性能优化和自动化构建。第四章通过案例分析了LIB文件在多项目共享、嵌入式系统应用以及国际化与本地化处理中的实际应
【深入剖析Visual C++ 2010 x86运行库】:架构组件精讲

# 摘要
Visual C++ 2010 x86运行库是支持开发的关键组件,涵盖运行库架构核心组件、高级特性与实现,以及优化与调试等多个方面。本文首先对运行库的基本结构、核心组件的功能划分及其交互机制进行概述。接着,深入探讨运行时类型信息(RTTI)与异常处理的工作原理和优化策略,以及标准C++内存管理接口和内存分配与释放策略。本文还阐述了运行库的并发与多线程支持、模板与泛型编程支持,
从零开始掌握ACD_ChemSketch:功能全面深入解读
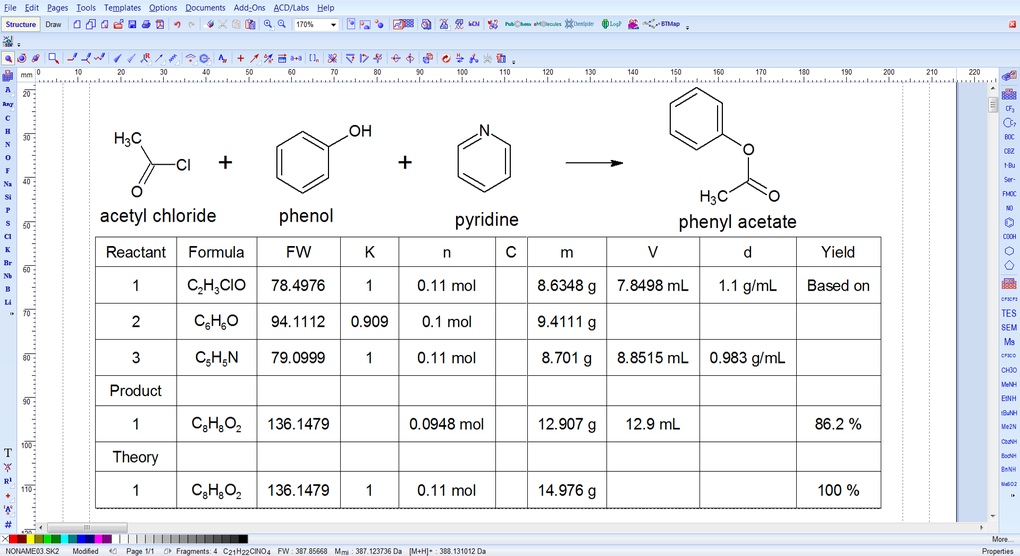
# 摘要
ACD_ChemSketch是一款广泛应用于化学领域的绘图软件,本文概述了其基础和高级功能,并探讨了在科学研究中的应用。通过介绍界面布局、基础绘图工具、文件管理以及协作功能,本文为用户提供了掌握软件操作的基础知识。进阶部分着重讲述了结构优化、立体化学分析、高
蓝牙5.4新特性实战指南:工业4.0的无线革新

# 摘要
蓝牙技术是工业4.0不可或缺的组成部分,它通过蓝牙5.4标准实现了新的通信特性和安全机制。本文详细概述了蓝牙5.4的理论基础,包括其新增功能、技术规格,以及与前代技术的对比分析。此外,探讨了蓝牙5.4在工业环境中网络拓扑和设备角色的应用,并对安全机制进行了评估。本文还分析了蓝牙5.4技术的实际部署,包
【Linux二进制文件执行错误深度剖析】:一次性解决执行权限、依赖、环境配置问题(全面检查必备指南)
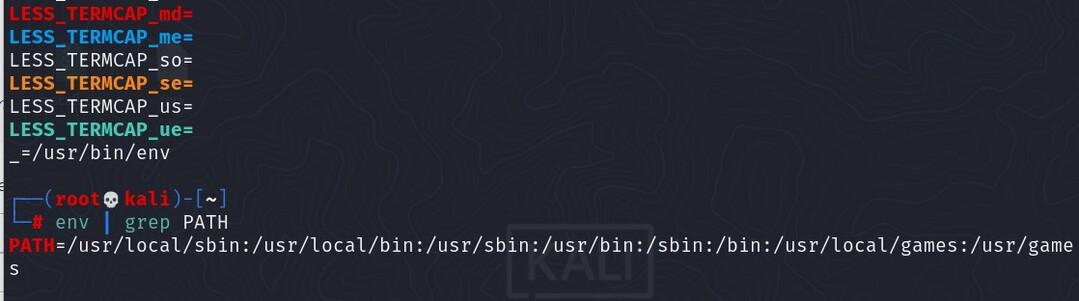
# 摘要
本文详细探讨了二进制文件执行过程中遇到的常见错误,并提出了一系列理论与实践上的解决策略。首先,针对执行权限问题,文章从权限基础理论出发,分析了权限设置不当所导致的错误,并探讨了修复权限的工具和方法。接着,文章讨论了依赖问题,包括依赖管理基础、缺失错误分析以及修复实践,并对比了动态与静态依赖。环境配置问题作为另一主要焦点,涵盖了
差分输入ADC滤波器设计要点:实现高效信号处理
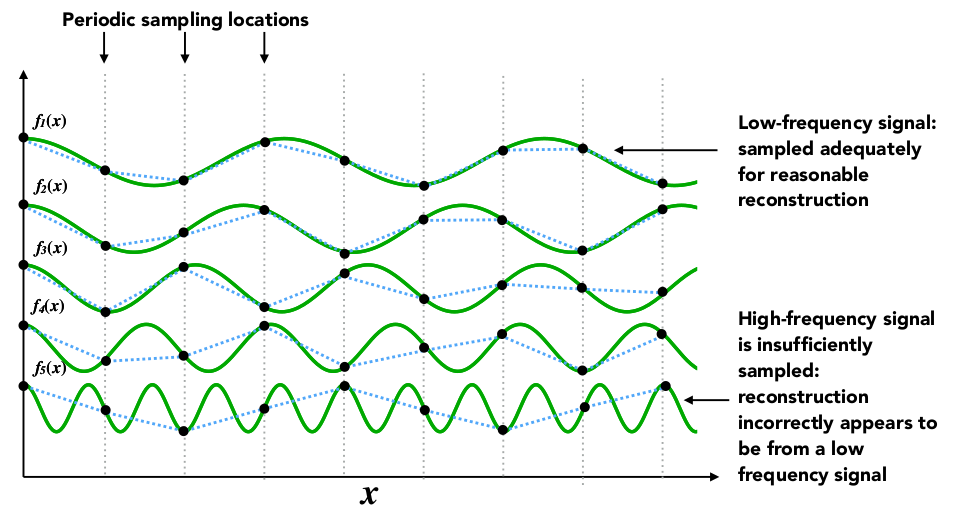
# 摘要
本论文详细介绍了差分输入模数转换器(ADC)滤波器的设计与实践应用。首先概述了差分输入ADC滤波器的理论基础,包括差分信号处理原理、ADC的工作原理及其类型,以及滤波器设计的基本理论。随后,本研究深入探讨了滤波器设计的实践过程,从确定设计规格、选择元器件到电路图绘制、仿真、PCB布局,以及性能测试与验证的方法。最后,论文分析了提高差分输入ADC滤波器性能的优化策略,包括提升精
【HPE Smart Storage性能提升指南】:20个技巧,优化存储效率

# 摘要
本文深入探讨了HPE Smart Storage在性能管理方面的方法与策略。从基础性能优化技巧入手,涵盖了磁盘配置、系统参数调优以及常规维护和监控等方面,进而探讨高级性能提升策略,如缓存管理、数据管理优化和负载平衡。在自动化和虚拟化环境下,本文分析了如何利用精简配置、快照技术以及集成监控解决方案来进一步提升存储性能,并在最后章节中讨论了灾难恢复与备份策略的设计与实施。通过案
【毫米波雷达性能提升】:信号处理算法优化实战指南
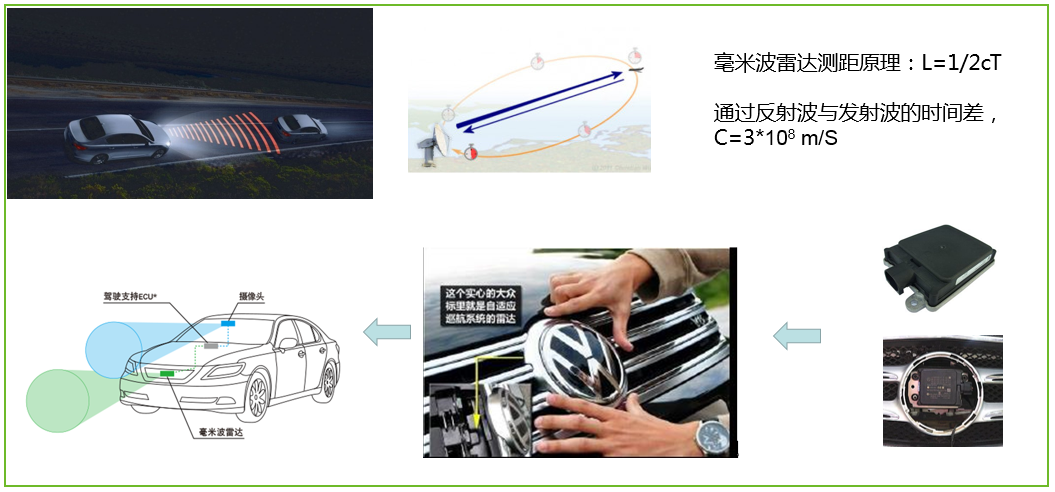
# 摘要
毫米波雷达信号处理是一个涉及复杂数学理论和先进技术的领域,对于提高雷达系统的性能至关重要。本文首先概述了毫米波雷达信号处理的基本理论,包括傅里叶变换和信号特性分析,然后深入探讨了信号处理中的关键技术和算法优化策略。通过案例分析,评估了现有算法性能,并介绍了信号处理软件实践和代码优化技巧。文章还探讨了雷达系统的集成、测试及性能评估方法,并展望了未来毫米波雷达性能提升的技术趋
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )