Amazon S3对象存储简介与基本概念
发布时间: 2024-02-20 20:54:39 阅读量: 139 订阅数: 33 

springboot集成amazon aws s3对象存储sdk(javav2)
# 1. 什么是Amazon S3对象存储?
## 1.1 Amazon S3的基本介绍
Amazon Simple Storage Service(Amazon S3)是一种对象存储服务,可让您通过Internet存储和检索任意数量的数据。它在全球范围内提供可扩展性、安全性、数据的持久性和低成本的存储解决方案。
## 1.2 对象存储与传统文件存储的区别
传统文件存储是基于文件系统的,通过路径来定位数据,而对象存储是以对象的形式存储数据,每个对象都有唯一的标识符,而数据的元数据则以键值对的形式存储。
## 1.3 Amazon S3在云计算中的地位和作用
Amazon S3作为云计算基础设施的一部分,为用户提供了高度可靠、安全、经济的存储解决方案,为云计算应用提供了稳定、持久的数据存储基础。
接下来,我们将深入了解Amazon S3的基本概念。
# 2. Amazon S3的基本概念
Amazon S3作为一种对象存储服务,有一些基本概念是需要了解的,包括存储桶(Bucket)、对象(Object)和存储类别(Storage Class)。让我们逐一来了解它们的含义和特点。
### 2.1 Bucket(存储桶)的概念和用途
在Amazon S3中,Bucket是最上层的存储容器,用于存储对象。每个Bucket都必须具有唯一的名称,并且Bucket的名称在全球范围内必须是唯一的。可以通过Bucket来组织和管理存储在其中的对象,类似于文件系统中的文件夹。Bucket可以存储大量的对象,并且可以根据需要进行扩展和管理。
### 2.2 对象(Object)的概念和特点
对象是存储在Amazon S3中的基本实体,可以是文本文件、图片、视频等任意类型的数据。每个对象由数据(Object Data)和元数据(Metadata)组成。数据部分是实际存储的内容,而元数据则包含了与对象有关的信息,比如对象的大小、创建时间等。对象在Bucket中具有唯一的键(Key),通过对象的键可以唯一标识和访问特定的对象。
### 2.3 存储类别(Storage Class)的区分和应用场景
Amazon S3提供了多种不同的存储类别,每种类别针对不同的数据访问模式和成本要求。常见的存储类别包括标准存储(Standard)、低频访问存储(Standard-IA)、归档存储(Glacier)等。不同的存储类别具有不同的价格和适用场景,用户可以根据自己的需求来选择适合的存储类别来存储数据。
以上是Amazon S3基本概念的介绍,这些概念对于理解和使用Amazon S3存储服务非常重要。在接下来的章节中,我们将深入探讨Amazon S3的核心功能和应用场景。
# 3. Amazon S3的核心功能和特点
Amazon S3作为一种弹性、可靠的对象存储服务,具有许多核心功能和特点,这些功能和特点使其成为云计算中备受青睐的存储解决方案。
#### 3.1 安全性与权限控制
Amazon S3提供了多种安全性和权限控制机制,确保存储的数据不会被未经授权的访问而泄露。用户可以通过以下方式来保障数据的安全性和进行权限控制:
- 访问控制列表(Access Control List,ACL):通过ACL可以对存储桶和对象进行细粒度的权限控制,包括读、写、删除等操作。
- 存储桶策略(Bucket Policy):存储桶策略是基于JSON的策略语言,可以定义对存储桶的访问权限规则,如允许特定IP范围的访问、限制匿名访问等。
- 跨域资源共享(Cross-Origin Resource Sharing,CORS):CORS可以控制在Web页面中访问存储桶中对象的权限,支持跨域访问控制。
```python
# 使用Python SDK Boto3设置存储桶策略的示例代码
import json
import boto3
# 定义存储桶名称和策略
bucket_name = 'my-secure-bucket'
bucket_policy = {
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Deny",
"Principal": "*",
"Action": "s3:GetObject",
"Resource": "arn:aws:s3:::my-secure-bucket/*",
"Condition": {
"IpAddress": {"aws:SourceIp": "203.0.113.0/24"}
}
}
]
}
# 应用存储桶策略
s3 = boto3.client('s3')
bucket_policy = json.dumps(bucket_policy)
s3.put_bucket_policy(Bucket=bucket_name, Policy=bucket_policy)
```
通过以上权限控制机制,用户可以灵活地配置存储桶和对象的访问权限,并确保数据的安全性。
#### 3.2 数据的持久性和可靠性
Amazon S3提供了高持久性和可靠性的数据存储方案,保障用户存储的数据不会丢失或损坏。其持久性保证了数据的长期保存,即使发生硬件故障或数据中心故障,用户的数据也能够得到可靠的保护。
#### 3.3 数据的可扩展性和弹性存储
Amazon S3的存储架构具有高度的可扩展性,能够适应用户不断增长的数据存储需求。用户无需担心架构扩展的问题,可以根据需要随时扩展存储空间,同时也能够灵活地调整存储类别以满足不同的业务需求。
以上便是Amazon S3的核心功能和特点,这些特性使得Amazon S3在云计算领域具有举足轻重的地位,并得到了广泛的应用和认可。
# 4. Amazon S3的应用场景
Amazon S3作为一种高可用、可靠、低成本的云存储解决方案,广泛应用于各种场景中。下面将介绍Amazon S3的几个主要应用场景:
#### 4.1 云存储与备份
Amazon S3提供了高度可靠的数据存储服务,适合作为企业和个人的云存储方案。用户可以将重要数据备份到Amazon S3中,使用多种存储类别来满足不同数据备份需求。同时,Amazon S3还支持跨区域复制功能,可以轻松构建跨地域的数据备份方案。
#### 4.2 静态网站托管
Amazon S3可以直接托管静态网站的内容,通过配置相应的Bucket策略和静态网站托管功能,使用户可以在Amazon S3上轻松部署和托管静态网站,实现高可用、高性能的访问体验。
#### 4.3 大规模数据分析与处理
Amazon S3作为云端数据湖的理想存储平台,可以存储各种结构化和非结构化数据。用户可以利用Amazon S3作为数据湖集中存储数据,再通过其与其他云服务(如AWS Glue、Amazon Athena、Amazon Redshift等)的集成,实现大规模数据的分析和处理。
以上是Amazon S3的几个主要应用场景,下面我们将以这些场景为例,详细介绍如何在实际应用中使用Amazon S3来实现相应的功能和服务。
# 5. Amazon S3的使用实例
Amazon S3作为一种强大的云存储服务,在实际应用中有着丰富的使用场景。接下来,我们将介绍几个Amazon S3的使用实例,包括配置和管理存储桶、上传和下载文件以及使用Amazon S3作为静态网站托管的示例。
#### 5.1 配置和管理Amazon S3存储桶
在使用Amazon S3之前,首先需要创建一个存储桶(Bucket)。存储桶是Amazon S3用于存储对象(Objects)的容器,类似于文件夹的概念。我们可以通过Amazon S3的控制台或者AWS SDK来创建和管理存储桶。
Python示例代码:
```python
import boto3
# 创建S3客户端
s3 = boto3.client('s3')
# 创建存储桶
bucket_name = 'my-unique-bucket-name'
s3.create_bucket(Bucket=bucket_name)
print(f'存储桶 {bucket_name} 创建成功!')
```
代码总结:以上代码演示了如何使用Python的boto3库创建一个Amazon S3存储桶,并打印出创建成功的消息。
结果说明:成功创建名为"my-unique-bucket-name"的存储桶。
#### 5.2 上传和下载文件
一旦存储桶创建成功,我们可以上传和下载文件到Amazon S3存储桶中。这为我们提供了一种高度可靠和可扩展的存储解决方案。
Java示例代码:
```java
import software.amazon.awssdk.core.sync.RequestBody;
import software.amazon.awssdk.services.s3.S3Client;
import software.amazon.awssdk.services.s3.model.PutObjectRequest;
import java.io.File;
// 创建S3客户端
S3Client s3 = S3Client.create();
// 指定要上传的文件和存储桶名称
String bucketName = "my-unique-bucket-name";
String key = "my-file.txt";
File file = new File("path/to/file.txt");
// 上传文件
s3.putObject(PutObjectRequest.builder().bucket(bucketName).key(key).build(), RequestBody.fromFile(file));
System.out.println("文件上传成功!");
```
代码总结:以上Java代码演示了如何使用AWS SDK for Java将本地文件上传到指定的Amazon S3存储桶中。
结果说明:成功将指定文件上传到名为"my-unique-bucket-name"的存储桶中。
#### 5.3 使用Amazon S3作为静态网站托管
除了存储数据,Amazon S3还可以用于托管静态网站。通过将静态网页文件上传到S3存储桶中,并配置相应的Bucket策略和静态网站托管选项,您可以快速搭建一个高可靠的静态网站。
JavaScript示例代码:
```javascript
const AWS = require('aws-sdk');
const fs = require('fs');
// 创建S3实例
const s3 = new AWS.S3();
// 读取要上传的静态网页文件
const fileContent = fs.readFileSync('index.html');
const params = {
Bucket: 'my-unique-bucket-name',
Key: 'index.html',
Body: fileContent,
ContentType: 'text/html'
};
// 上传静态网页文件
s3.putObject(params, function(err, data) {
if (err) console.log(err, err.stack);
else console.log('静态网页上传成功!');
});
```
代码总结:以上JavaScript代码演示了如何使用AWS SDK for JavaScript将静态网页文件上传到Amazon S3存储桶,并指定ContentType为'text/html'。
结果说明:成功将静态网页文件上传到名为"my-unique-bucket-name"的存储桶中,可用于静态网站托管。
通过以上实例,我们了解了如何在实际应用中使用Amazon S3进行存储和管理文件,以及将其作为静态网站的托管服务。在实际开发中,根据具体需求,我们可以进一步探索Amazon S3更多强大的功能和应用场景。
# 6. Amazon S3的最佳实践和注意事项
Amazon S3是一个功能强大的对象存储服务,但在使用过程中,我们也需要遵循一些最佳实践和注意事项,以确保数据的安全性、成本效益和性能优化。接下来,我们将介绍一些Amazon S3的最佳实践和注意事项:
### 6.1 数据安全性与加密
在Amazon S3中,保护数据的安全性尤为重要,我们可以通过以下方式来确保数据的安全:
#### 6.1.1 使用服务器端加密
Amazon S3提供了服务器端加密功能,可以在对象上传时自动加密数据。我们可以选择使用SSE-S3(Amazon S3管理加密密钥)、SSE-KMS(由AWS Key Management Service管理加密密钥)或者使用自定义加密密钥进行加密。
```python
import boto3
# 创建S3客户端
s3 = boto3.client('s3')
# 上传加密文件到S3
s3.upload_file('myfile.txt', 'mybucket', 'myfile.txt', ExtraArgs={'ServerSideEncryption': 'AES256'})
```
##### 代码说明
- 使用boto3库创建S3客户端。
- 使用`upload_file`方法上传文件到指定的存储桶,设置`ExtraArgs`参数来指定服务器端加密算法为AES256。
#### 6.1.2 控制访问权限
通过合理设置存储桶和对象的访问权限,可以有效地控制数据的访问范围。可以使用IAM策略、存储桶策略和ACL来管理访问控制。
```python
import boto3
# 创建S3客户端
s3 = boto3.client('s3')
# 设置对象访问控制
s3.put_object_acl(Bucket='mybucket', Key='myfile.txt', ACL='private')
```
##### 代码说明
- 使用`put_object_acl`方法设置指定对象的访问控制为私有(private)。
### 6.2 成本控制和优化存储
Amazon S3的存储费用取决于存储量、访问量和数据传输量等因素,因此需要合理控制成本并优化存储空间的利用率:
#### 6.2.1 使用生命周期规则管理数据
通过定义生命周期规则,可以自动将数据转移至更经济的存储类别或者删除过期数据,以节省存储成本。
```python
import boto3
# 创建S3客户端
s3 = boto3.client('s3')
# 定义生命周期规则
lifecycle_config = {
'Rules': [
{
'ID': 'Move older files to Glacier',
'Prefix': '',
'Status': 'Enabled',
'Transitions': [
{
'Days': 30,
'StorageClass': 'GLACIER'
}
]
}
]
}
# 设置存储桶生命周期配置
s3.put_bucket_lifecycle_configuration(Bucket='mybucket', LifecycleConfiguration=lifecycle_config)
```
##### 代码说明
- 使用`put_bucket_lifecycle_configuration`方法设置存储桶的生命周期规则,将数据在30天后转移到Glacier存储类别。
### 6.3 性能调优和最佳实践建议
为了获得更好的性能和体验,我们还可以进行一些性能调优和遵循最佳实践:
#### 6.3.1 使用分段上传大文件
对于大文件的上传,推荐使用分段上传功能,可以提高上传速度并减少失败重试的可能性。
```python
import boto3
# 创建S3客户端
s3 = boto3.client('s3')
# 创建Multipart上传
response = s3.create_multipart_upload(Bucket='mybucket', Key='mylargefile.txt')
# 上传文件块
part = open('part1.txt', 'rb')
upload_part = s3.upload_part(Bucket='mybucket', Key='mylargefile.txt', UploadId=response['UploadId'], PartNumber=1, Body=part)
```
##### 代码说明
- 使用`create_multipart_upload`方法创建Multipart上传任务。
- 使用`upload_part`方法上传文件块到指定的Multipart上传任务中。
以上是Amazon S3的最佳实践和注意事项的部分内容,通过遵循这些建议,可以更好地管理和优化您在Amazon S3中的数据存储和访问。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入探讨了Amazon S3对象存储的各个方面,从基本概念到高级应用,全面介绍了如何创建、配置和管理Amazon S3存储桶。涵盖了在Amazon S3中上传、下载、加密数据保护、生命周期管理、日志记录、内容分发、数据访问跟踪和监控等操作方法。此外,还介绍了如何通过AWS Lambda函数实现自动触发操作、数据复制和备份、S3 Select的快速检索和分析,以及S3托管策略与IAM访问控制的深入分析。无论您是刚开始使用Amazon S3还是希望深入了解其高级功能,本专栏都为您提供了全面的指导和实用的技巧,助您充分发挥Amazon S3在存储和管理数据方面的潜力。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
揭秘HID协议:中文版Usage Tables实战演练与深入分析

# 摘要
人类接口设备(HID)协议是用于计算机和人机交互设备间通信的标准协议,广泛应用于键盘、鼠标、游戏控制器等领域。本文首先介绍了HID协议的基本概念和理论基础,深入分析了其架构、组成以及Usage Tables的定义和分类。随后,通过实战演练,本文阐述了如何在设备识别、枚举和自定
【掌握核心】:PJSIP源码深度解读与核心功能调试术

# 摘要
PJSIP是一个广泛使用的开源SIP协议栈,它提供了丰富的功能集和高度可定制的架构,适用于嵌入式系统、移动设备和桌面应用程序。本文首先概述了PJ
【网络稳定性秘籍】:交换机高级配置技巧,揭秘网络稳定的秘诀

# 摘要
交换机作为网络基础设施的核心设备,其基本概念及高级配置技巧对于保障网络稳定性至关重要。本文首先介绍了交换机的基本功能及其在网络稳定性中的重要性,然后深入探讨了交换机的工作原理、VLAN机制以及网络性能指标。通过理论和实践结合的方式,本文展示了如何通过高级配置技巧,例如VLAN与端口聚合配置、安全设置和性能优化来提升网络的可靠性和
Simtrix.simplis仿真模型构建:基础知识与进阶技巧(专业技能揭秘)

# 摘要
本文全面介绍了Simtrix.simplis仿真模型的基础知识、原理、进阶应用和高级技巧与优化。首先,文章详细阐述了Simtrix.simplis仿真环境的设置、电路图绘制和参数配置等基础操作,为读者提供了一个完整的仿真模型建立过程。随后,深入分析了仿真模型的高级功能,包括参数扫描、多域仿真技术、自定义模
【数字电位器电压控制】:精确调节电压的高手指南

# 摘要
数字电位器作为一种可编程的电阻器,近年来在电子工程领域得到了广泛应用。本文首先介绍了数字电位器的基本概念和工作原理,随后通过与传统模拟电位器的对比,凸显其独特优势。在此基础上,文章着重探讨了数字电位器在电压控制应用中的作用,并提供了一系列编程实战的案例。此外,本文还分享了数字电位器的调试与优化技
【通信故障急救】:台达PLC下载时机不符提示的秒杀解决方案

# 摘要
本文全面探讨了通信故障急救的全过程,重点分析了台达PLC在故障诊断中的应用,以及通信时机不符问题的根本原因。通过对通信协议、同步机制、硬件与软件配合的理论解析,提出了一套秒杀解决方案,并通过具体案例验证了其有效性。最终,文章总结了成功案例的经验,并提出了预防措施与未来通信故障处理的发展方向,为通信故障急救提供了理论和实践上的指导。
# 关键字
通信故障;PLC故障诊断;通信协议;同步机制;故障模型
【EMMC协议深度剖析】:工作机制揭秘与数据传输原理解析

# 摘要
本文对EMMC协议进行了全面的概述和深入分析。首先介绍了EMMC协议的基本架构和组件,并探讨了其工作机制,包括不同工作模式和状态转换机制,以及电源管理策略及其对性能的影响。接着,深入分析了EMMC的数据传输原理,错误检测与纠正机制,以及性能优化策略。文中还详细讨论了EMMC协议在嵌入式系统中的应用、故障诊断和调试,以及未来发展趋势。最后,本文对EMMC协议的扩展和安全性、与
【文件哈希一致性秘籍】:揭露Windows与Linux下MD5不匹配的真正根源
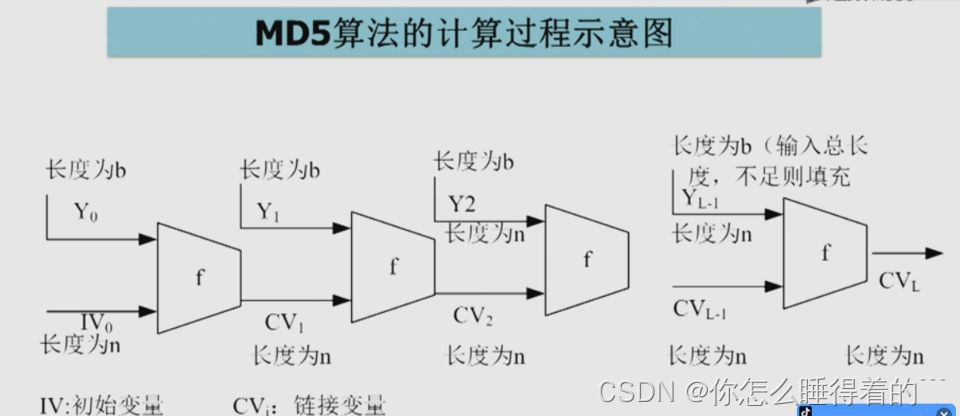
# 摘要
本文首先介绍了哈希一致性与MD5算法的基础知识,随后深入探讨了MD5的工作原理、数学基础和详细步骤。分析了MD5算法的弱点及其安全性问题,并对Windows和Linux文件系统的架构、特性和元数据差异进行了比较。针对MD5不匹配的实践案例,本文提供了原因分析、案例研究和解决方案。最后,探讨了哈希一致性检查工具的种类与选择、构建自动化校验流程的方法,并展望了哈希算法的未
高速数据采集:VISA函数的应用策略与技巧

# 摘要
高速数据采集技术在现代测量、测试和控制领域发挥着至关重要的作用。本文首先介绍了高速数据采集技术的基础概念和概况。随后,深入探讨了VISA(Virtual Instrument Soft
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )