JUnit在微服务架构中的应用:服务级别测试
发布时间: 2024-09-30 03:28:53 阅读量: 20 订阅数: 37 

ysoserial-master.zip
# 1. JUnit与微服务架构概述
在当今的软件开发领域,微服务架构因其灵活、可扩展的特性而广受欢迎。微服务架构通过将单一应用程序作为一套小服务来开发,每个服务运行在自己的进程中,并且通常使用轻量级的机制通信,如HTTP资源API。与之相伴而生的是测试复杂度的提高,因为它要求开发者需要对每个服务及其交互进行单独的测试。
JUnit作为Java开发者最熟悉和最常用的单元测试框架之一,在微服务架构中扮演着关键角色。JUnit使得开发者能够为每个独立的服务编写单元测试,确保功能正确性,并且在服务集成时进行集成测试,以便验证各个服务间的协同工作能力。
本章将简要介绍JUnit与微服务架构的概念,为读者奠定理解和掌握后续章节内容的基础。接下来的章节将深入探讨JUnit的基础知识,以及如何与微服务架构中的单元测试和集成测试相结合,实现高效且可靠的测试策略。
# 2. JUnit基础与单元测试
### 2.1 JUnit框架的核心概念
JUnit是一个广泛使用的Java单元测试框架,它允许开发者在编码过程中频繁地执行测试用例,从而快速地验证代码的正确性。JUnit的测试用例是独立的,并且以注解的方式组织,使得测试的编写和理解变得直观。
#### 2.1.1 JUnit的主要特性
JUnit提供了丰富的注解来标记测试方法,如`@Test`, `@Before`, `@After`, `@BeforeClass`, 和 `@AfterClass`。此外,JUnit4引入了参数化测试,JUnit5则进一步扩展了这个概念,并提供了更多的功能和灵活性。
##### 表格1. JUnit特性与作用一览
| 特性 | 作用 |
| -------- | ------------------------------------------------------------ |
| `@Test` | 标记一个方法为测试方法 |
| `@Before`| 在每个测试方法执行前调用,常用于初始化操作 |
| `@After` | 在每个测试方法执行后调用,常用于资源清理 |
| `@BeforeClass`| 在测试类中的所有方法执行前调用一次,必须是static方法,常用于初始化静态资源 |
| `@AfterClass` | 在测试类中的所有方法执行后调用一次,必须是static方法,常用于清理静态资源 |
| 参数化测试 | 允许使用不同的参数多次运行同一个测试方法 |
### 2.2 编写基本的JUnit测试用例
#### 2.2.1 使用注解进行测试的组织
在JUnit中,测试方法应以`@Test`注解标记,通过使用`@Before`和`@After`注解,我们可以在测试前进行准备工作,在测试后进行资源的清理工作。
##### 示例代码2.1:基本的JUnit测试结构
```java
import org.junit.*;
import static org.junit.Assert.*;
public class MyTest {
@Before
public void setUp() {
// 初始化操作
}
@Test
public void testSomething() {
// 测试代码
assertTrue("失败描述", true);
}
@After
public void tearDown() {
// 清理操作
}
}
```
#### 2.2.2 断言和测试方法的编写
JUnit的断言方法允许我们验证某个条件是否为真。如果条件为假,则测试失败。常用的断言包括`assertTrue`, `assertEquals`, `assertNotNull`等。
### 2.3 高级测试技术
#### 2.3.1 参数化测试的实现
参数化测试允许测试用例以不同的参数多次运行。JUnit5通过`@ParameterizedTest`注解以及`@ValueSource`、`@CsvSource`等提供参数值的方式,使得参数化测试的实现变得更加灵活和强大。
##### 示例代码2.2:JUnit 5参数化测试
```java
import org.junit.jupiter.params.ParameterizedTest;
import org.junit.jupiter.params.provider.CsvSource;
import static org.junit.jupiter.api.Assertions.assertEquals;
public class ParameterizedTests {
@ParameterizedTest
@CsvSource({
"1, One",
"2, Two",
"3, Three"
})
void testWithCsvSource(int input, String expected) {
assertEquals(expected, convert(input));
}
private String convert(int input) {
// 实际的转换逻辑
return "Number";
}
}
```
#### 2.3.2 嵌套测试和依赖注入
嵌套测试允许多个测试用例共享相同的设置代码,提高测试的效率和可读性。JUnit5的嵌套测试通过`@Nested`注解实现。
##### 示例代码2.3:嵌套测试示例
```java
import org.junit.jupiter.api.Nested;
import org.junit.jupiter.api.Test;
public class NestedTests {
@Nested
class InnerTests {
@Test
void innerTest() {
// 测试代码
}
}
@Nested
class AnotherInnerTests {
@Test
void anotherInnerTest() {
// 另一个测试代码
}
}
}
```
JUnit 5 通过依赖注入,可以为测试类和测试方法提供参数,从而简化测试代码,减少重复的设置代码。
##### 示例代码2.4:使用`@BeforeEach`和`@AfterEach`进行依赖注入
```java
import org.junit.jupiter.api.BeforeEach;
import org.junit.jupiter.api.AfterEach;
import org.junit.jupiter.api.Test;
public class DependencyInjectionTests {
private Dependency dependency;
@BeforeEach
void setup(Dependency dependency) {
this.dependency = dependency;
}
@Test
void testWithDependency(Dependency dependency) {
// 使用依赖进行测试
}
}
```
通过上述章节的介绍,我们可以看出JUnit不仅提供了一系列简便的注解来组织测试用例,也提供了高

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
专栏“JUnit 介绍与使用”全面介绍了 JUnit 框架,从基础教程到高级技巧。它涵盖了单元测试、集成测试、测试用例设计、测试驱动开发 (TDD)、模拟对象、性能测试、持续集成、规则管理、JUnit 5 新特性、大型项目测试策略、数据库集成测试、微服务测试、覆盖率分析、接口测试、Spring Boot 集成和参数化测试等主题。通过深入浅出的讲解和丰富的示例,专栏旨在帮助开发人员掌握 JUnit 的强大功能,编写可维护、可靠且高效的测试代码,从而提高软件质量和开发效率。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
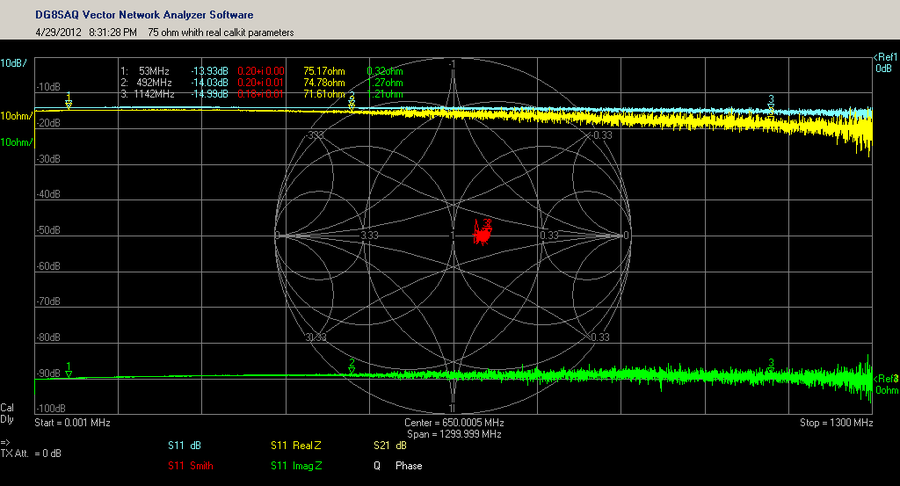
E5071C高级应用技巧大揭秘:深入探索仪器潜能(专家级操作)
# 摘要
本文详细介绍了E5071C矢量网络分析仪的使用概要、校准和测量基础、高级测量功能、在自动化测试中的应用,以及性能优化与维护。章节内容涵盖校准流程、精确测量技巧、脉冲测量与故障诊断、自动化测试系统构建、软件集成编程接口以及仪器性能优化和日常维护。案例研究与最佳实践部分分析了E5071C在实际应用中的表现,并分享了专家级的操作技巧和应用趋势,为用户提供了一套完整的学习和操作指南。
# 关键字
【模糊控制规则的自适应调整】:方法论与故障排除

# 摘要
本文综述了模糊控制规则的基本原理,并深入探讨了自适应模糊控制的理论框架,涵盖了模糊逻辑与控制系统的关系、自适应调整的数学模型以及性能评估方法。通过分析自适应模糊控
DirectExcel开发进阶:如何开发并集成高效插件

# 摘要
DirectExcel作为一种先进的Excel操作框架,为开发者提供了高效操作Excel的解决方案。本文首先介绍DirectExcel开发的基础知识,深入探讨了DirectExcel高效插件的理论基础,包括插件的核心概念、开发环境设置和架构设计。接着,文章通过实际案例详细解析了DirectExcel插件开发实践中的功能实现、调试
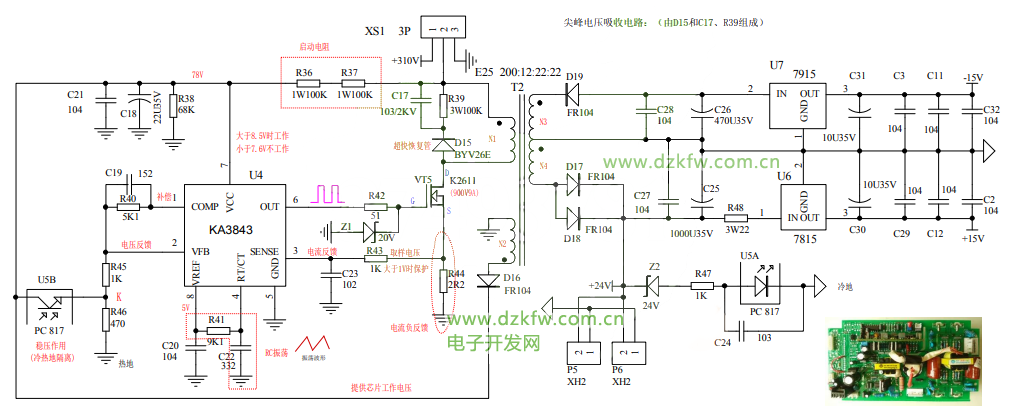
【深入RCD吸收】:优化反激电源性能的电路设计技巧
# 摘要
本文详细探讨了反激电源中RCD吸收电路的理论基础和设计方法。首先介绍了反激电源的基本原理和RCD吸收概述,随后深入分析了RCD吸收的工作模式、工作机制以及关键参数。在设计方面,本文提供了基于理论计算的设计过程和实践考量,并通过设计案例分析对性能进行测试与优化。进一步地,探讨了RCD吸收电路的性能优化策略,包括高效设计技巧、高频应用挑战和与磁性元件的协同设计。此外,本文还涉及了RCD
【进阶宝典】:宝元LNC软件高级功能深度解析与实践应用!

# 摘要
本文全面介绍了宝元LNC软件的综合特性,强调其高级功能,如用户界面的自定义与交互增强、高级数据处理能力、系统集成的灵活性和安全性以及性能优化策略。通过具体案例,分析了软件在不同行业中的应用实践和工作流程优化。同时,探讨了软件的开发环境、编程技巧以及用户体验改进,并对软件的未来发展趋势和长期战略规划进行了展望。本研究旨在为宝元LNC软件的用户和开发者提供深入的理解和指导,以支持其在不
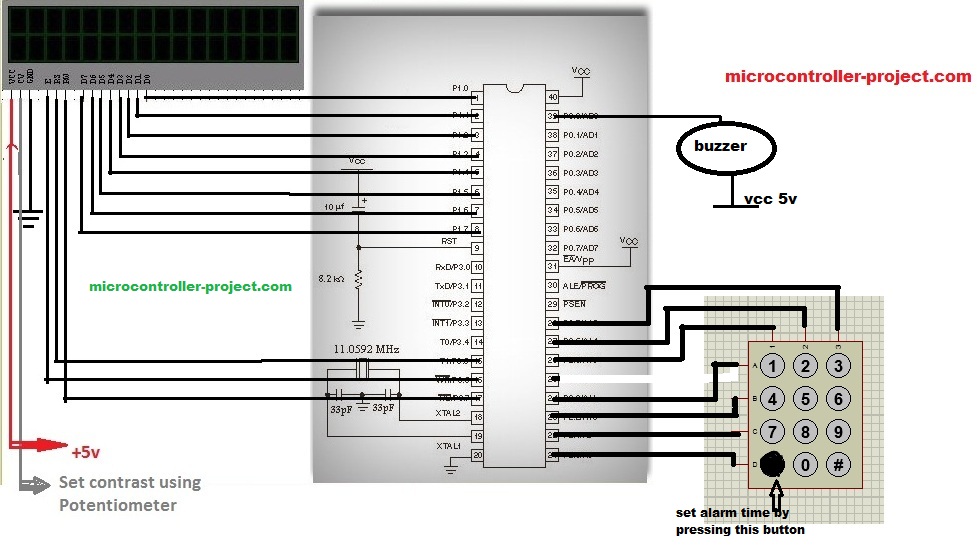
51单片机数字时钟故障排除:系统维护与性能优化
# 摘要
本文全面介绍了51单片机数字时钟系统的设计、故障诊断、维护与修复、性能优化、测试评估以及未来趋势。首先概述了数字时钟系统的工作原理和结构,然后详细分析了故障诊断的理论基础,包括常见故障类型、成因及其诊断工具和技术。接下来,文章探讨了维护和修复的实践方法,包括快速检测、故障定位、组件更换和系统重置,以及典型故障修复案例。在性能优化部分,本文提出了硬件性能提升和软
ISAPI与IIS协同工作:深入探究5大核心策略!
# 摘要
本文深入探讨了ISAPI与IIS协同工作的机制,详细介绍了ISAPI过滤器和扩展程序的高级策略,以及IIS应用程序池的深入管理。文章首先阐述了ISAPI过滤器的基础知识,包括其生命周期、工作原理和与IIS请求处理流程的相互作用。接着,文章探讨了ISAPI扩展程序的开发与部
【APK资源优化】:图片、音频与视频文件的优化最佳实践
# 摘要
随着移动应用的普及,APK资源优化成为提升用户体验和应用性能的关键。本文概述了APK资源优化的重要性,并深入探讨了图片、音频和视频文件的优化技术。文章分析了不同媒体格式的特点,提出了尺寸和分辨率管理的最佳实践,以及压缩和加载策略。此外,本文介绍了高效资源优
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )