Kubernetes集群管理实战:掌握容器编排和管理技巧
发布时间: 2024-06-21 16:35:20 阅读量: 76 订阅数: 24 

kubernetes容器编排

# 1. Kubernetes集群管理概述
Kubernetes是一个开源的容器编排系统,用于自动化容器的部署、管理和扩展。它提供了一套完整的工具和API,使开发人员和运维人员能够轻松地管理大型容器化应用程序。
Kubernetes集群由一组节点组成,这些节点运行着Kubernetes组件,包括API Server、Controller Manager、Scheduler和Kubelet。API Server是集群的中央控制点,负责接收和处理来自客户端的请求。Controller Manager负责维护集群的状态,包括管理Pod、ReplicaSet和Deployment等资源。Scheduler负责将Pod调度到集群中的节点上。Kubelet是运行在每个节点上的代理,负责管理Pod的生命周期和与API Server的通信。
# 2. Kubernetes集群架构和组件
### 2.1 Kubernetes集群的架构和角色
Kubernetes集群是一个分布式系统,由多个组件组成,这些组件共同协作以管理容器化应用程序。Kubernetes集群的架构遵循主从模型,其中一个或多个主节点(master nodes)负责控制和管理集群,而工作节点(worker nodes)则负责运行容器化应用程序。
**主节点(master nodes)**
* **etcd:** 存储集群状态的分布式键值数据库。
* **API Server:** 集群的入口点,负责处理来自客户端的请求并与其他组件通信。
* **Controller Manager:** 运行一组控制器,这些控制器监视集群状态并执行所需的更改。
* **Scheduler:** 负责将 Pod 分配到集群中的工作节点上。
**工作节点(worker nodes)**
* **Kubelet:** 在每个工作节点上运行的代理,负责管理 Pod 的生命周期。
* **Kube-proxy:** 在每个工作节点上运行的代理,负责管理网络代理和负载均衡。
### 2.2 Kubernetes组件详解
#### 2.2.1 etcd
etcd 是一个分布式键值数据库,用于存储 Kubernetes 集群的状态。它存储有关 Pod、服务、节点和其他集群对象的元数据。etcd 是一个高可用组件,这意味着它可以在节点故障的情况下继续运行。
**代码示例:**
```go
import (
"context"
"fmt"
"log"
clientv3 "go.etcd.io/etcd/client/v3"
)
func main() {
// 创建一个 etcd 客户端
client, err := clientv3.New(clientv3.Config{
Endpoints: []string{"localhost:2379"},
})
if err != nil {
log.Fatal(err)
}
defer client.Close()
// 从 etcd 中获取一个键的值
resp, err := client.Get(context.Background(), "/foo")
if err != nil {
log.Fatal(err)
}
// 打印键的值
fmt.Println(string(resp.Kvs[0].Value))
}
```
**逻辑分析:**
此代码示例演示了如何使用 etcd 客户端从 etcd 中获取键的值。首先,它创建了一个 etcd 客户端,然后使用 `Get()` 方法从 `/foo` 键中获取值。最后,它打印键的值。
#### 2.2.2 API Server
API Server 是 Kubernetes 集群的入口点。它处理来自客户端的请求,并与其他组件通信以执行请求。API Server 是一个无状态组件,这意味着它可以在任何节点上运行。
**代码示例:**
```go
import (
"context"
"fmt"
"log"
metav1 "k8s.io/apimachinery/pkg/apis/meta/v1"
"k8s.io/client-go/kubernetes"
"k8s.io/client-go/rest"
)
func main() {
// 创建一个 Kubernetes 客户端
config, err := rest.InClusterConfig()
if err != nil {
log.Fatal(err)
}
client, err := kubernetes.NewForConfig(config)
if err != nil {
log.Fatal(err)
}
// 获取所有 Pod 的列表
pods, err := client.CoreV1().Pods("").List(context.Background(), metav1.ListOptions{})
if err != nil {
log.Fatal(err)
}
// 打印 Pod 的名称
for _, pod := range pods.Items {
fmt.Println(pod.Name)
}
}
```
**逻辑分析:**
此代码示例演示了如何使用 Kubernetes 客户端从 API Server 中获取所有 Pod 的列表。首先,它创建了一个 Kubernetes 客户端,然后使用 `List()` 方法从 `/pods` 路径中获取 Pod 的列表。最后,它打印 Pod 的名称。
#### 2.2.3 Controller Manager
Controller Manager 运行一组控制器,这些控制器监视集群状态并执行所需的更改。这些控制器包括:
* **Node Controller:** 监视节点的状态并确保它们正常运行。
* **Replication Controller:** 确保 Pod 的副本数与期望值相匹配。
* **Endpoint Controller:** 维护 Service 的端点列表。
* **Service Account Controller:** 创建和管理服务帐户。
#### 2.2.4 Scheduler
Scheduler 负责将 Pod 分配到集群中的工作节点上。它考虑各种因素,例如节点的可用资源、Pod 的亲和性和反亲和性约束。
**代码示例:**
```go
import (
"context"
"fmt"
"log"
"k8s.io/api/core/v1"
metav1 "k8s.io/apimachinery/pkg/apis/meta/v1"
"
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏是涵盖广泛技术主题的宝库,旨在为技术人员提供全面的指南和深入的见解。从安装 Python 3 到解决 MySQL 死锁问题,再到优化 Linux 服务器性能,本专栏提供了逐步的说明和深入的分析,帮助读者掌握复杂的技术概念和解决常见问题。此外,本专栏还探讨了 Docker 容器技术、Kubernetes 集群管理、Git 版本控制和网络安全威胁等关键主题,为读者提供全面而实用的技术知识。无论您是经验丰富的专业人士还是技术新手,本专栏都将成为您宝贵的资源,帮助您提高技能并解决技术难题。
专栏目录

文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
TSPL2高级打印技巧揭秘:个性化格式与样式定制指南

# 摘要
TSPL2打印语言作为工业打印领域的重要技术标准,具备强大的编程能力和灵活的控制指令,广泛应用于各类打印设备。本文首先对TSPL2打印语言进行概述,详细介绍其基本语法结构、变量与数据类型、控制语句等基础知识。接着,探讨了TSPL2在高级打印技巧方面的应用,包括个性化打印格式设置、样
JFFS2文件系统设计思想:源代码背后的故事
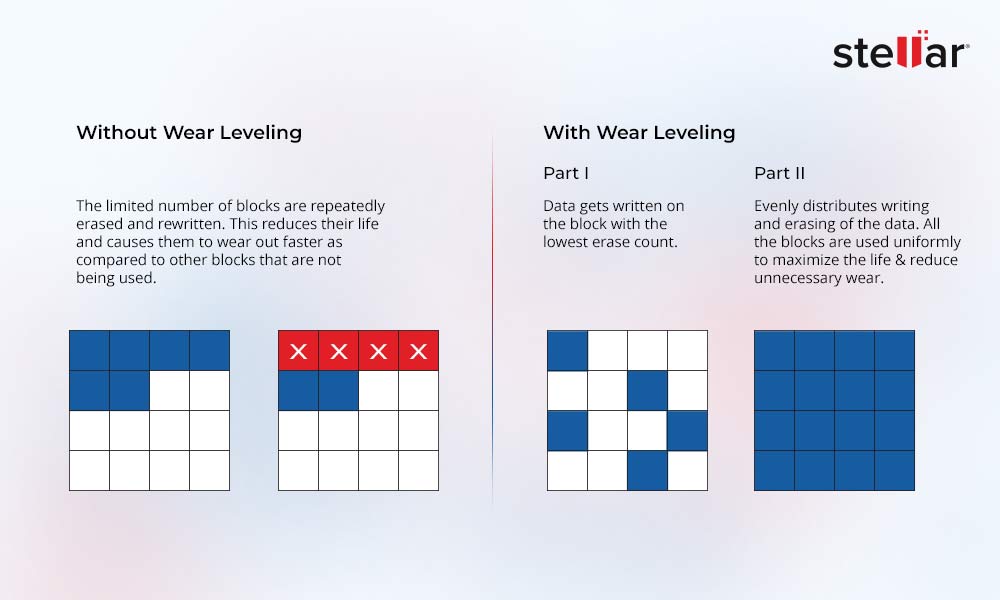
# 摘要
本文对JFFS2文件系统进行了全面的概述和深入的分析。首先介绍了JFFS2文件系统的基本理论,包括文件系统的基础概念和设计理念,以及其核心机制,如红黑树的应用和垃圾回收机制。接着,文章深入剖析了JFFS2的源代码,解释了其结构和挂载过程,以及读写操作的实现原理。此外,针对JFFS2的性能优化进行了探讨,分析了性能瓶颈并提出了优化策略。在此基础上,本文还研究了J
EVCC协议版本兼容性挑战:Gridwiz更新维护攻略

# 摘要
本文对EVCC协议进行了全面的概述,并探讨了其版本间的兼容性问题,这对于电动车充电器与电网之间的有效通信至关重要。文章分析了Gridwiz软件在解决EVCC兼容性问题中的关键作用,并从理论和实践两个角度深入探讨了Gridwiz的更新维护策略。本研究通过具体案例分析了不同EVCC版本下Gridwiz的应用,并提出了高级维护与升级技巧。本文旨在为相关领域的工程师和开发者提供有关EVCC协议及其兼容性维护
计算机组成原理课后答案解析:张功萱版本深入理解

# 摘要
计算机组成原理是理解计算机系统运作的基础。本文首先概述了计算机组成原理的基本概念,接着深入探讨了中央处理器(CPU)的工作原理,包括其基本结构和功能、指令执行过程以及性能指标。然后,本文转向存储系统的工作机制,涵盖了主存与缓存的结构、存储器的扩展与管理,以及高速缓存的优化策略。随后,文章讨论了输入输出系统与总线的技术,阐述了I/O系统的
CMOS传输门故障排查:专家教你识别与快速解决故障
# 摘要
CMOS传输门故障是集成电路设计中的关键问题,影响电子设备的可靠性和性能。本文首先概述了CMOS传输门故障的普遍现象和基本理论,然后详细介绍了故障诊断技术和解决方法,包括硬件更换和软件校正等策略。通过对故障表现、成因和诊断流程的分析,本文旨在提供一套完整的故障排除工具和预防措施。最后,文章展望了CMOS传输门技术的未来挑战和发展方向,特别是在新技术趋势下如何面对小型化、集成化挑战,以及智能故障诊断系统和自愈合技术的发展潜力。
# 关键字
CMOS传输门;故障诊断;故障解决;信号跟踪;预防措施;小型化集成化
参考资源链接:[cmos传输门工作原理及作用_真值表](https://w
KEPServerEX秘籍全集:掌握服务器配置与高级设置(最新版2018特性深度解析)
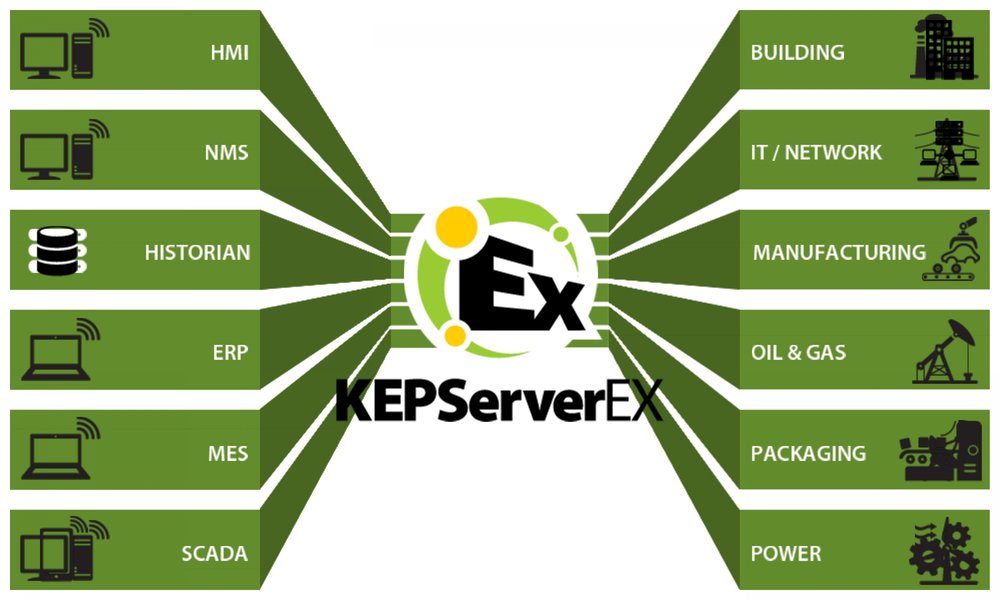
# 摘要
KEPServerEX作为一种广泛使用的工业通信服务器软件,为不同工业设备和应用程序之间的数据交换提供了强大的支持。本文从基础概述入手,详细介绍了KEPServerEX的安装流程和核心特性,包括实时数据采集与同步,以及对通讯协议和设备驱动的支持。接着,文章深入探讨了服务器的基本配置,安全性和性能优化的高级设
【域控制新手起步】:一步步掌握组策略的基本操作与应用
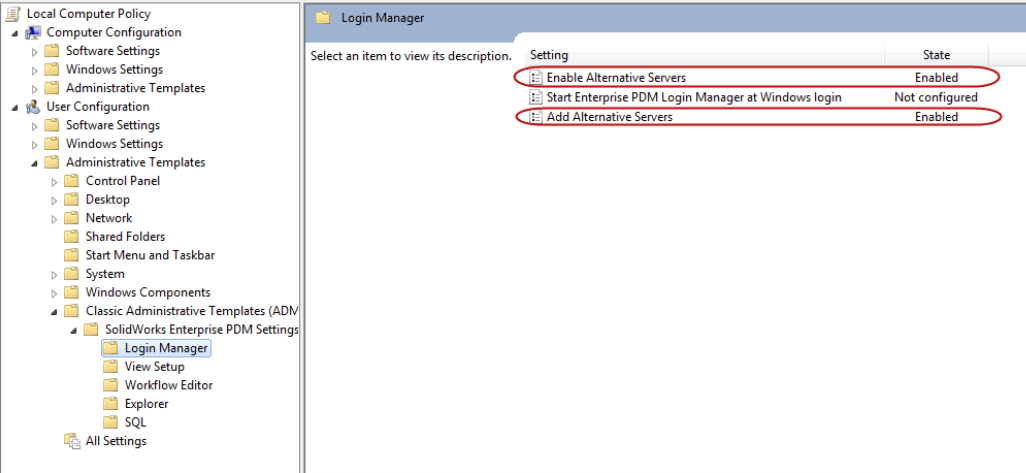
# 摘要
组策略是域控制器中用于配置和管理网络环境的重要工具。本文首先概述了组策略的基本概念和组成部分,并详细解释了其作用域与优先级规则,以及存储与刷新机制。接着,文章介绍了组策略的基本操作,包括通过管理控制台GPEDIT.MSC的使用、组策略对象(GPO)的管理,以及部署和管理技巧。在实践应用方面,本文探讨了用户环境管理、安全策略配置以及系统配置与优化。此
【SolidWorks自动化工具】:提升重复任务效率的最佳实践

# 摘要
本文全面探讨了SolidWorks自动化工具的开发和应用。首先介绍了自动化工具的基本概念和SolidWorks API的基础知识,然后深入讲解了编写基础自动化脚本的技巧,包括模型操作、文件处理和视图管理等。接着,本文阐述了自动化工具的高级应用
Android USB音频设备通信:实现音频流的无缝传输
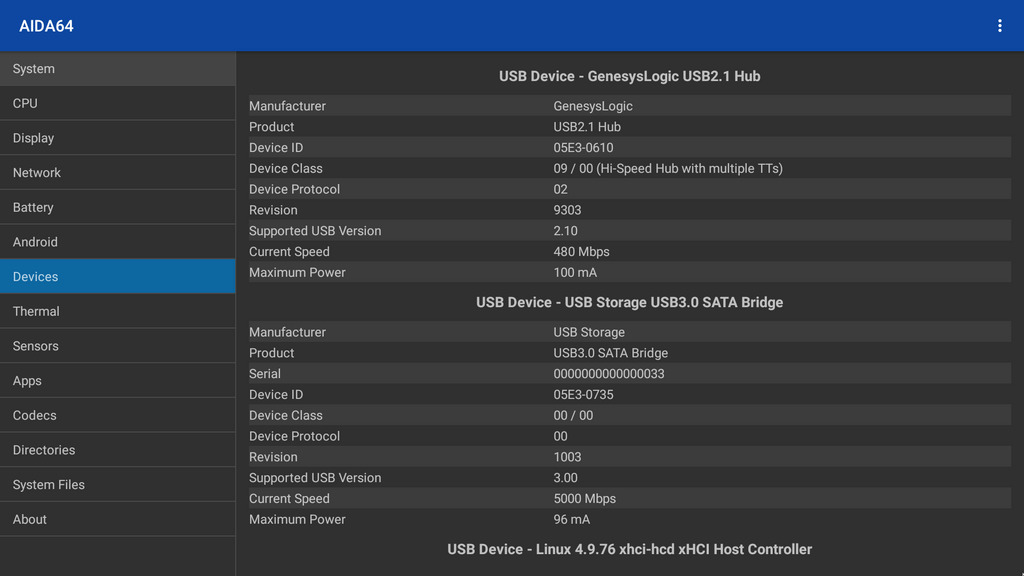
# 摘要
随着移动设备的普及,Android平台上的USB音频设备通信已成为重要话题。本文从基础理论入手,探讨了USB音频设备工作原理及音频通信协议标准,深入分析了Android平台音频架构和数据传输流程。随后,实践操作章节指导读者了解如何设置开发环境,编写与测试USB音频通信程序。文章深入讨论了优化音频同步与延迟,加密传输音频数据
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )