【Python Requests库高级应用】:构建专业的HTTP请求解决方案
发布时间: 2024-10-16 10:11:58 阅读量: 31 订阅数: 50 

《COMSOL顺层钻孔瓦斯抽采实践案例分析与技术探讨》,COMSOL模拟技术在顺层钻孔瓦斯抽采案例中的应用研究与实践,comsol顺层钻孔瓦斯抽采案例 ,comsol;顺层钻孔;瓦斯抽采;案例,COM
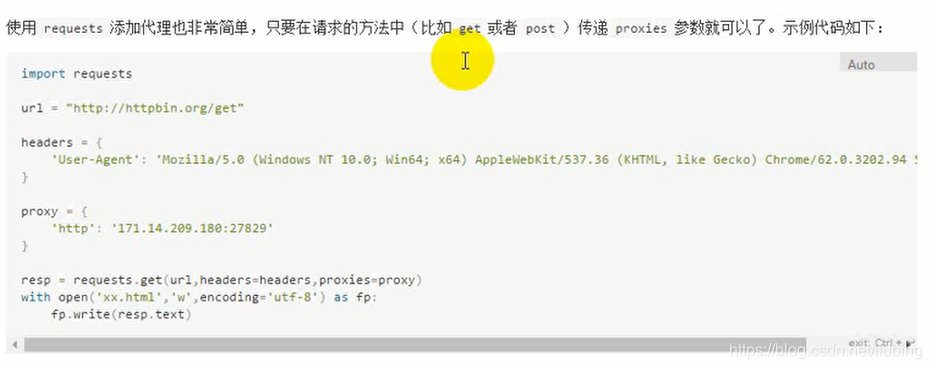
# 1. Python Requests库概述
## 1.1 Requests库的简介
Python Requests库是一个强大的HTTP库,专为人类设计。它的主要优点在于简单易用、表达能力强,并且能够直接与复杂的Web服务和API进行交互。Requests库在Python标准库的基础上进行了优化,使得HTTP请求变得更加简单,同时也提供了额外的功能来满足复杂的网络请求需求。
```python
import requests
# 发送GET请求
response = requests.get('***')
# 发送POST请求
response = requests.post('***', data={'key':'value'})
```
## 1.2 Requests库的安装
安装Requests库非常简单,只需要使用pip即可完成安装:
```bash
pip install requests
```
## 1.3 Requests库的简单使用
Requests库的基本使用非常直观。例如,发送一个GET请求只需要一行代码:
```python
response = requests.get('***')
print(response.text)
```
发送一个POST请求也很简单,只需要传递必要的参数即可:
```python
data = {'key': 'value'}
response = requests.post('***', data=data)
print(response.text)
```
通过这些简单的例子,我们可以看到Requests库如何使HTTP请求变得简单而直观。在接下来的章节中,我们将深入探讨Requests库的HTTP基础和进阶特性。
# 2. Requests库的HTTP基础
## 2.1 Requests库的核心概念
### 2.1.1 发送HTTP请求的流程
在本章节中,我们将深入探讨Requests库的核心概念,首先从发送HTTP请求的基本流程开始。Requests库的设计目标是让HTTP请求变得尽可能简单。它抽象了底层的socket通信,让我们只需要关注于HTTP请求的细节。
在Python中,使用Requests库发送一个HTTP请求的基本步骤如下:
1. 导入Requests库。
2. 使用`requests.get()`或`requests.post()`等方法发起请求。
3. 传递URL和必要的参数。
4. 获取响应对象。
5. 处理响应数据。
```python
import requests
# 发起一个GET请求
response = requests.get('***')
# 发起一个POST请求
data = {'key': 'value'}
response = requests.post('***', data=data)
```
在上述代码中,我们首先导入了Requests库,然后分别使用`get`和`post`方法发起请求。`requests.get`用于获取资源,而`requests.post`用于提交数据。每个方法都会返回一个响应对象,我们可以从中获取请求的状态码、响应头、响应体等信息。
### 2.1.2 请求和响应的结构
在HTTP请求中,通常包含以下几个部分:
- 请求行:包含请求方法、URL和HTTP版本。
- 请求头:包含一系列的键值对,用于传递请求的元数据。
- 空行:请求头和请求体之间的空行。
- 请求体:通常是请求的数据,例如POST请求中提交的表单数据。
HTTP响应的结构则包含:
- 状态行:包含HTTP版本、状态码和状态消息。
- 响应头:包含响应的元数据,例如内容类型、内容长度等。
- 空行:响应头和响应体之间的空行。
- 响应体:服务器返回的数据内容。
Requests库通过响应对象来封装了这些结构,我们可以通过访问响应对象的属性来获取这些信息。
```python
# 获取响应的状态码
status_code = response.status_code
# 获取响应头
headers = response.headers
# 获取响应体(作为字符串)
response_body = response.text
```
通过上述代码,我们可以轻松地获取到HTTP响应的各个部分。
接下来,我们将深入探讨HTTP请求方法的不同使用方式,以及如何处理响应内容。
## 2.2 HTTP请求方法详解
### 2.2.1 GET请求的使用
在本章节中,我们将详细介绍如何在Requests库中使用GET请求。GET请求是最常用的HTTP方法之一,主要用于请求服务器发送资源。
使用Requests库发送GET请求的基本语法如下:
```python
response = requests.get(url, params=None, **kwargs)
```
- `url`:要请求的URL地址。
- `params`:一个字典或字符串会被转换为字典,作为URL的查询字符串附加到URL。
- `**kwargs`:可选参数,可以传递`headers`、`cookies`、`auth`等。
例如,如果我们想要向一个API发送GET请求,并且带有查询参数:
```python
params = {'key1': 'value1', 'key2': 'value2'}
response = requests.get('***', params=params)
```
在这个例子中,我们通过`params`参数传递了一个字典,其中包含了我们希望作为查询字符串附加到URL的参数。`requests`库会自动将这个字典转换为查询字符串,并附加到URL后。
### 2.2.2 POST请求的使用
POST请求通常用于向服务器提交数据。在Requests库中,发送POST请求的语法如下:
```python
response = requests.post(url, data=None, json=None, **kwargs)
```
- `url`:要请求的URL地址。
- `data`:要发送的数据,可以是字典、字符串或字节流。
- `json`:如果设置了`json`参数,会自动将字典转换为JSON格式,并设置正确的`Content-Type`头部。
- `**kwargs`:其他可选参数。
例如,我们向一个API提交JSON格式的数据:
```python
data = {'key1': 'value1', 'key2': 'value2'}
response = requests.post('***', json=data)
```
在这个例子中,我们将一个字典作为`json`参数传递给`post`方法。Requests库会自动将这个字典转换为JSON字符串,并设置`Content-Type`头部为`application/json`。
### 2.2.3 其他HTTP方法的实践
除了GET和POST请求,HTTP协议还定义了其他一些请求方法,如PUT、DELETE、HEAD、OPTIONS等。在Requests库中,这些方法的使用与GET和POST类似,只是方法名称不同。
例如,使用PUT请求更新资源:
```python
response = requests.put('***', data={'key': 'value'})
```
使用DELETE请求删除资源:
```python
response = requests.delete('***')
```
在实际应用中,你可能需要根据API的设计来选择合适的HTTP方法。以下是一个简单的表格,总结了常用HTTP方法及其用途:
| HTTP方法 | 描述 | 使用场景 |
|----------|------------|----------------------------------------------|
| GET | 获取资源 | 读取数据 |
| POST | 提交数据 | 创建新资源 |
| PUT | 更新资源 | 替换或创建资源 |
| DELETE | 删除资源 | 删除资源 |
| HEAD | 获取头部 | 获取资源的头部信息,不获取资源本身 |
| OPTIONS | 获取支持 | 获取服务器支持的方法和资源的其他信息 |
## 2.3 响应内容处理
### 2.3.1 响应文本的获取
在本章节中,我们将讨论如何从HTTP响应中获取文本内容。当你发起一个HTTP请求并接收到响应时,通常你会想查看响应的文本内容。
在Requests库中,可以通过响应对象的`text`属性来获取响应的文本内容。例如:
```python
response = requests.get('***')
response_text = response.text
```
默认情况下,`text`属性会使用`charset`编码解析响应内容。如果你知道响应内容的编码,可以通过`encoding`参数指定:
```python
response = requests.get('***', encoding='utf-8')
response_text = response.text
```
### 2.3.2 响应数据的序列化处理
除了获取文本内容,有时候我们需要将响应内容序列化为Python对象,比如JSON格式的响应体。Requests库提供了`json()`方法来处理JSON响应:
```python
response = requests.get('***')
response_json = response.json()
```
`json()`方法会自动解析JSON响应内容,并将其转换为Python字典。如果响应内容不是有效的JSON,它会抛出一个异常。
### 2.3.3 文件上传和下载的处理
在实际应用中,我们可能需要上传或下载文件。Requests库提供了简单的方法来处理这些操作。
#### 文件上传
文件上传通常使用POST方法,并且需要在请求中包含文件数据。可以使用`files`参数来指定要上传的文件:
```python
files = {'file': open('example.txt', 'rb')}
response = requests.post('***', files=files)
```
在上述代码中,我们使用了`files`参数,并将文件以二进制读取模式打开。`requests`库会自动处理文件上传。
#### 文件下载
文件下载可以通过GET请求实现,并使用`stream=True`参数来分块下载文件:
```python
response = requests.get('***', stream=True)
with open('example.txt', 'wb') as f:
for chunk in response.iter_content(chunk_size=1024):
f.write(chunk)
```
在这个例子中,我们使用`stream=True`来分块下载文件,并通过迭代`response.iter_content()`方法来写入文件。`chunk_size`参数指定了每个块的大小。
通过上述代码,我们可以处理文件的上传和下载。接下来,我们将深入探讨Requests库的进阶特性。
# 3. Requests库的进阶特性
在本章节中,我们将深入探讨Requests库的一些进阶特性,这些特性能够帮助开发者构建更加复杂和高效的HTTP通信。我们将从自定义HTTP头部、身份验证和会话管理、错误处理和重试机制等方面进行详细介绍。
## 3.1 自定义HTTP头部
### 3.1.1 如何设置请求头部
HTTP头部是客户端发送请求时附带的一系列键值对,它包含了诸如用户代理、接受的内容类型等信息。在Requests库中,我们可以通过`headers`参数来设置自定义的HTTP头部。
```python
import requests
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8',
'Accept-Language': 'en-US,en;q=0.5'
}
response = requests.get('***', headers=headers)
print(response.text)
```
在上面的代码示例中,我们设置了一个包含`User-Agent`、`Accept`和`Accept-Language`头部的GET请求。这些头部信息通常用于让服务器识别请求的来源和期望的响应类型。
### 3.1.2 常见的HTTP头部字段
在HTTP请求中,有一些常见的头部字段,它们各自有特定的作用和用途。以下是一些常用的HTTP头部字段及其说明:
| 头部字段 | 说明 |
| --- | --- |
| User-Agent | 识别发起请求的浏览器或其他客户端 |
| Accept | 指定客户端能够接收的内容类型 |
| Accept-Language | 指定客户端接受的自然语言 |
| Authorization | 包含了用于验证用户代理的凭证 |
| Content-Type | 指定请求体的MIME类型 |
| Content-Length | 指定请求体的长度(以字节为单位) |
表格中列出的是一些常用的HTTP头部字段及其用途,它们在实际开发中扮演着重要的角色。
## 3.2 身份验证和会话管理
### 3.2.1 基本身份验证
基本身份验证是一种HTTP认证方式,通过在请求头中添加`Authorization`字段来传递用户名和密码信息。
```python
from requests.auth import HTTPBasicAuth
auth = HTTPBasicAuth('user', 'pass')
response = requests.get('***', auth=auth)
print(response.json())
```
在这个例子中,我们使用了`HTTPBasicAuth`来提供用户名和密码,并将其作为`auth`参数传递给`requests.get`方法。服务器验证这些凭据后,将返回包含身份验证信息的JSON响应。
### 3.2.2 OAuth认证
OAuth是一种开放标准的授权协议,允许用户提供一定权限给第三方应用访问他们的信息,而无需共享密码。Requests库通过`requests-oauthlib`库来支持OAuth认证。
```python
from requests_oauthlib import OAuth1
auth = OAuth1('client_key', 'client_secret', 'resource_owner_key', 'resource_owner_secret')
response = requests.get('***', auth=auth)
print(response.json())
```
在上面的代码示例中,我们使用了`OAuth1`来设置OAuth认证所需的参数。这种方式常用于访问那些需要用户授权的API。
### 3.2.3 使用会话保持连接状态
在多个请求需要保持同一会话状态时,我们可以使用`requests.Session`对象。会话对象允许我们保持某些参数,例如cookies,跨多个请求。
```python
session = requests.Session()
session.auth = ('user', 'pass')
session.headers.update({'Accept': 'application/json'})
response = session.get('***')
print(response.json())
```
在这个例子中,我们创建了一个会话对象,并为它设置了身份验证和头部信息。这意味着后续的请求将自动包含这些信息。
## 3.3 错误处理和重试机制
### 3.3.1 错误处理策略
在HTTP通信中,错误处理是非常重要的一环。Requests库提供了一些内置的方法来处理常见的HTTP错误。
```python
try:
response = requests.get('***')
except requests.exceptions.HTTPError as errh:
print("Http Error:", errh)
except requests.exceptions.ConnectionError as errc:
print("Error Connecting:", errc)
except requests.exceptions.Timeout as errt:
print("Timeout Error:", errt)
except requests.exceptions.RequestException as err:
print("OOps: Something Else", err)
```
在上面的代码示例中,我们使用了`try-except`块来捕获和处理可能发生的HTTP错误。这种错误处理策略有助于增强程序的健壮性。
### 3.3.2 自动重试机制的实现
Requests库提供了`HTTPAdapter`,它允许我们通过自定义逻辑来实现自动重试机制。
```python
from requests.adapters import HTTPAdapter
from requests.packages.urllib3.util.retry import Retry
retry = Retry(connect=3, backoff_factor=0.5)
adapter = HTTPAdapter(max_retries=retry)
session = requests.Session()
session.mount('***', adapter)
session.mount('***', adapter)
response = session.get('***')
print(response.text)
```
在这个例子中,我们创建了一个`Retry`对象,并将其传递给`HTTPAdapter`。这将使得会话对象在遇到连接错误时自动重试,直到达到最大重试次数。
在本章节中,我们详细介绍了Requests库的一些进阶特性,包括自定义HTTP头部、身份验证和会话管理、错误处理和重试机制。这些特性能够帮助开发者构建更加复杂和高效的HTTP通信。在下一章节中,我们将探讨如何使用Requests库构建RESTful API客户端。
# 4. Requests库在实际项目中的应用
在本章节中,我们将探讨如何使用Python的Requests库来解决实际项目中的常见问题。我们将通过构建RESTful API客户端、开发网络爬虫以及实现自动化测试三个方面来深入理解Requests库的应用。
## 4.1 构建RESTful API客户端
### 4.1.1 RESTful API简介
RESTful API是一种基于HTTP协议的软件架构风格,它定义了一组约束条件和原则,用于在客户端和服务器之间进行通信。RESTful API通过使用不同的HTTP方法(如GET、POST、PUT、DELETE等)来实现对资源的增删改查操作。
RESTful API的优点包括:
- **无状态**:服务器不保存客户端的状态,每个请求都是独立的。
- **可缓存**:HTTP协议定义了哪些响应可以被缓存,这有助于提高性能。
- **客户端-服务器分离**:允许两者独立演化,服务器不需要知道客户端的实现细节。
- **统一接口**:统一的接口简化了系统架构,同时使得整个系统更易于理解和实现。
### 4.1.2 使用Requests库调用RESTful API
要使用Requests库调用RESTful API,我们首先需要了解API的基本结构和请求方法。以下是一个简单的示例,展示了如何使用Requests库调用RESTful API进行GET和POST请求。
```python
import requests
# GET请求示例
response_get = requests.get('***')
if response_get.status_code == 200:
data = response_get.json()
print(data)
# POST请求示例
payload = {'key1': 'value1', 'key2': 'value2'}
response_post = requests.post('***', data=payload)
if response_post.status_code == 201:
print('Data submitted successfully')
```
在这个示例中,我们首先导入了`requests`模块,然后使用`get`方法向API发送了一个GET请求,并检查响应状态码是否为200(成功)。如果成功,我们使用`json`方法解析响应的JSON数据。对于POST请求,我们创建了一个包含数据的字典,然后使用`post`方法发送请求,并检查状态码是否为201(已创建)。
#### 代码逻辑解读:
- `requests.get`:发起一个HTTP GET请求。
- `requests.post`:发起一个HTTP POST请求。
- `response.status_code`:获取HTTP响应的状态码。
- `response.json()`:将JSON格式的响应内容转换为Python对象。
### 4.2 网络爬虫的开发
#### 4.2.1 网页内容抓取
网络爬虫是自动化地从网站上抓取信息的程序。Requests库可以非常方便地获取网页内容。以下是一个简单的爬虫示例,它使用Requests获取一个网页的HTML内容,并打印出来。
```python
import requests
def fetch_page(url):
response = requests.get(url)
if response.status_code == 200:
return response.text
else:
return None
def extract_links(html):
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, 'html.parser')
links = []
for link in soup.find_all('a'):
href = link.get('href')
if href:
links.append(href)
return links
url = '***'
html_content = fetch_page(url)
if html_content:
links = extract_links(html_content)
for link in links:
print(link)
```
在这个示例中,`fetch_page`函数使用Requests库获取指定URL的页面内容。如果响应状态码为200,它将返回HTML内容;否则返回None。`extract_links`函数使用BeautifulSoup库解析HTML内容,并提取所有的链接。
#### 代码逻辑解读:
- `requests.get`:发起一个HTTP GET请求。
- `BeautifulSoup`:解析HTML内容。
- `soup.find_all('a')`:查找所有的`<a>`标签。
- `link.get('href')`:获取`<a>`标签的`href`属性值,即链接地址。
#### 4.2.2 数据解析和存储
在获取网页内容后,我们通常需要从中提取有用的数据并进行存储。以下是一个示例,展示了如何使用Requests和BeautifulSoup库提取网页中的标题,并将其存储到CSV文件中。
```python
import requests
from bs4 import BeautifulSoup
import csv
def fetch_page(url):
response = requests.get(url)
if response.status_code == 200:
return response.text
else:
return None
def extract_titles(html):
soup = BeautifulSoup(html, 'html.parser')
titles = []
for title in soup.find_all('h1', class_='title-class'):
title_text = title.get_text()
titles.append(title_text)
return titles
def store_titles(titles, filename):
with open(filename, 'w', newline='') as csv***
***
***['Title'])
for title in titles:
writer.writerow([title])
url = '***'
html_content = fetch_page(url)
if html_content:
titles = extract_titles(html_content)
store_titles(titles, 'titles.csv')
```
在这个示例中,`extract_titles`函数提取了所有`<h1>`标签中含有`class='title-class'`的标题,并返回标题列表。`store_titles`函数将这些标题存储到CSV文件中。
#### 代码逻辑解读:
- `requests.get`:发起一个HTTP GET请求。
- `BeautifulSoup`:解析HTML内容。
- `soup.find_all('h1', class_='title-class')`:查找所有的`<h1>`标签,且`class`属性为`title-class`。
- `title.get_text()`:获取标题的文本内容。
- `csv.writer`:创建一个CSV文件写入器。
- `writer.writerow`:写入标题到CSV文件。
### 4.3 自动化测试
#### 4.3.1 测试HTTP API接口
自动化测试是软件开发中的一个重要环节,它可以确保代码的质量和API的稳定性。Requests库可以用来测试HTTP API接口。以下是一个使用Requests库进行API接口测试的示例。
```python
import requests
import unittest
class APITestCase(unittest.TestCase):
def setUp(self):
self.api_url = '***'
self.headers = {'Content-Type': 'application/json'}
def test_get_request(self):
response = requests.get(self.api_url, headers=self.headers)
self.assertEqual(response.status_code, 200)
def test_post_request(self):
payload = {'key': 'value'}
response = requests.post(self.api_url, json=payload, headers=self.headers)
self.assertEqual(response.status_code, 201)
if __name__ == '__main__':
unittest.main()
```
在这个示例中,我们定义了一个`APITestCase`类,它继承自`unittest.TestCase`。我们创建了两个测试方法:`test_get_request`和`test_post_request`,分别测试GET和POST请求。
#### 代码逻辑解读:
- `unittest.TestCase`:定义了一个测试用例。
- `setUp`:设置测试前的准备工作。
- `requests.get`:发起一个HTTP GET请求。
- `requests.post`:发起一个HTTP POST请求。
- `self.assertEqual(response.status_code, 200)`:断言响应状态码是否为200。
#### 4.3.2 测试Web应用的前端交互
除了测试HTTP API接口,Requests库还可以用来模拟用户与Web应用的前端交互。例如,我们可以模拟登录过程,确保用户认证功能的正确性。
```python
import requests
import unittest
class FrontendTest(unittest.TestCase):
def setUp(self):
self.login_url = '***'
self.username = 'testuser'
self.password = 'testpass'
def test_login(self):
login_data = {'username': self.username, 'password': self.password}
session = requests.Session()
response = session.post(self.login_url, data=login_data)
self.assertEqual(response.status_code, 200)
# 进行后续的测试,例如检查登录后的页面内容
if __name__ == '__main__':
unittest.main()
```
在这个示例中,我们定义了一个`FrontendTest`类,它也继承自`unittest.TestCase`。我们创建了一个测试方法`test_login`,它使用Requests库模拟登录过程,并验证响应状态码是否为200。
#### 代码逻辑解读:
- `requests.Session`:创建一个会话对象,用于持久化登录状态。
- `session.post`:发起一个HTTP POST请求,模拟登录操作。
通过本章节的介绍,我们可以看到Requests库在实际项目中有着广泛的应用,无论是构建RESTful API客户端、开发网络爬虫还是实现自动化测试,Requests库都能够提供强大的支持。在下一节中,我们将继续探索Requests库的高级技巧和最佳实践。
# 5. Requests库的高级技巧和最佳实践
## 5.1 中间件和钩子
### 5.1.1 使用中间件拦截请求和响应
在使用Requests库进行网络请求时,中间件是一种强大的工具,可以让我们在请求发送之前和响应接收之后进行拦截,以便进行日志记录、请求修改或者响应处理。中间件的应用类似于中间件模式在Web框架中的使用,比如Django或Flask。
#### 实现步骤
1. 创建一个中间件函数,该函数接受三个参数:`request`、`functions`和`hooks`。其中`request`是当前的请求对象,`functions`是一个包含所有钩子函数的字典,`hooks`是一个列表,用于存放中间件函数。
```python
def middleware(request, functions, hooks):
# 在请求发送之前执行
for hook in hooks:
response = hook(request, None)
if response is not None:
return response
# 发送请求
response = functions['send'](request)
# 在响应接收之后执行
for hook in hooks:
response = hook(request, response)
return response
```
2. 定义钩子函数,这些函数会在中间件中被调用。钩子函数可以修改请求或响应。
```python
def before_send(request):
# 在请求发送前的钩子函数
print("Before sending request to:", request.url)
return None
def after_receive(request, response):
# 在响应接收后的钩子函数
print("Received response:", response.status_code)
return response
```
3. 使用中间件
```python
from requests import Session, hooks
session = Session()
session.hooks = {'before_send': [before_send], 'after_receive': [after_receive]}
session.mount('***', hooks.Middleware(middleware))
```
#### 代码逻辑分析
- `middleware`函数首先检查是否存在`before_send`钩子函数,如果有,则在请求发送之前调用它们。
- 发送请求,并将响应对象传递给`after_receive`钩子函数,以便在响应接收后进行处理。
- 如果在钩子函数中返回了一个响应对象,则会停止发送请求,并直接返回该响应。
### 5.1.2 钩子函数的高级应用
钩子函数不仅可以用于日志记录和处理,还可以用于动态修改请求和响应,或者进行请求重试等高级操作。
#### 实现步骤
1. 定义更复杂的钩子函数,例如,进行请求重试的钩子函数。
```python
import requests
from time import sleep
def retry_hook(request, response):
retries = 3
delay = 2
if request.attempt < retries:
print("Request failed, retrying... attempt:", request.attempt)
sleep(delay)
return requests.send(request)
else:
print("Max retries reached, returning last response.")
return response
```
2. 使用钩子函数
```python
session = Session()
session.hooks = {'before_send': [], 'after_receive': [retry_hook]}
session.mount('***', hooks.Middleware(middleware))
```
#### 代码逻辑分析
- `retry_hook`函数检查当前尝试次数,如果小于最大重试次数,则暂停一段时间后重试请求。
- 如果达到最大重试次数,则返回最后一次获取的响应对象。
### 5.1.3 中间件和钩子的结合使用
通过结合中间件和钩子,我们可以创建一个强大的请求和响应处理系统,这可以极大地提高代码的可重用性和维护性。
#### 实现步骤
1. 创建一个中间件类,包含钩子列表和中间件逻辑。
```python
class Middleware:
def __init__(self, func):
self.func = func
def __call__(self, request, functions, hooks):
for hook in hooks:
response = hook(request, None)
if response is not None:
return response
response = self.func(request, functions, hooks)
for hook in hooks:
response = hook(request, response)
return response
```
2. 使用中间件类
```python
from requests import Session, hooks
session = Session()
session.hooks = {'before_send': [before_send], 'after_receive': [after_receive]}
session.mount('***', Middleware(middleware))
```
#### 代码逻辑分析
- `Middleware`类将钩子和中间件逻辑封装在一起,使得中间件的使用更加灵活和强大。
- 通过创建中间件实例并传递给`Session.mount()`方法,我们可以将中间件逻辑应用于所有请求。
## 5.2 性能优化
### 5.2.1 并发请求的处理
在处理大量网络请求时,性能优化是至关重要的。使用并发请求可以显著提高效率,特别是在进行网络爬虫或大规模API调用时。
#### 实现步骤
1. 使用`concurrent.futures`模块中的`ThreadPoolExecutor`或`ProcessPoolExecutor`来创建并发执行器。
```python
from concurrent.futures import ThreadPoolExecutor
import requests
def fetch_url(url):
return requests.get(url).text
urls = ['***'] * 10 # 示例URL列表
```
2. 使用`ThreadPoolExecutor`发送并发请求。
```python
with ThreadPoolExecutor(max_workers=5) as executor:
results = list(executor.map(fetch_url, urls))
```
#### 代码逻辑分析
- `ThreadPoolExecutor`创建一个线程池,可以并行地发送网络请求。
- `executor.map()`函数将`fetch_url`函数映射到每个URL上,返回一个迭代器,该迭代器生成请求的结果。
### 5.2.2 连接池的使用和优化
连接池是一种缓存和重用TCP连接的技术,它可以减少创建新连接时的开销,提高请求的处理速度。
#### 实现步骤
1. 使用Requests库的`Session`对象,它自动使用连接池。
```python
from requests import Session
session = Session()
response = session.get('***')
```
2. 自定义连接池的大小。
```python
from requests.adapters import HTTPAdapter
class PoolAdapter(HTTPAdapter):
def __init__(self, pool_size=5, **kwargs):
self.pool_size = pool_size
super().__init__(**kwargs)
def init_poolmanager(self, *args, **kwargs):
kwargs['maxsize'] = self.pool_size
return super().init_poolmanager(*args, **kwargs)
session = Session()
session.mount('***', PoolAdapter(pool_size=10))
```
#### 代码逻辑分析
- `Session`对象使用连接池来缓存和重用HTTP连接。
- 通过继承`HTTPAdapter`类并重写`init_poolmanager`方法,可以自定义连接池的大小。
## 5.3 安全性增强
### 5.3.1 HTTPS通信的加密
在进行网络通信时,安全性是非常重要的。使用HTTPS可以确保数据在传输过程中的安全。
#### 实现步骤
1. 使用Requests库发送HTTPS请求,默认情况下,Requests会尝试使用HTTPS。
```python
response = requests.get('***')
```
2. 使用SSL证书进行更安全的通信。
```python
from requests.packages.urllib3.poolmanager import PoolManager
class SSLAdapter(HTTPAdapter):
def init_poolmanager(self, *args, **kwargs):
context = ssl.SSLContext(ssl.PROTOCOL_TLS)
context.verify_mode = ssl.CERT_REQUIRED
context.load_cert_chain('/path/to/certfile.pem')
kwargs['ssl_context'] = context
return super().init_poolmanager(*args, **kwargs)
session = Session()
session.mount('***', SSLAdapter())
response = session.get('***')
```
#### 代码逻辑分析
- `SSLAdapter`类继承自`HTTPAdapter`,并重写了`init_poolmanager`方法,以便为HTTPS连接加载SSL证书。
- 使用`Session.mount()`方法将自定义适配器挂载到HTTPS URL。
### 5.3.2 防止中间人攻击的策略
为了防止中间人攻击,可以使用证书验证,或者使用某些加密库来加强请求的安全性。
#### 实现步骤
1. 使用证书验证来确保服务器的身份。
```python
session = Session()
session.verify = '/path/to/certfile.pem'
response = session.get('***')
```
2. 使用加密库对敏感数据进行加密。
```python
from cryptography.hazmat.primitives import serialization
from cryptography.hazmat.primitives.asymmetric import padding
from cryptography.hazmat.backends import default_backend
private_key = serialization.load_pem_private_key(
b'-----BEGIN PRIVATE KEY-----\n...\n-----END PRIVATE KEY-----\n',
password=None,
backend=default_backend()
)
data = b'Very sensitive data'
encrypted_data = private_key.sign(
data,
padding.PSS(
mgf=padding.MGF1(hashes.SHA256()),
salt_length=padding.PSS.MAX_LENGTH
),
hashes.SHA256()
)
```
#### 代码逻辑分析
- 在发送HTTPS请求时,通过设置`Session.verify`参数来指定证书文件路径,可以验证服务器的身份。
- 使用加密库`cryptography`对数据进行加密,确保数据在传输过程中的安全性。
通过本章节的介绍,我们可以看到Requests库提供了丰富的高级技巧和最佳实践,帮助我们构建更加安全、高效和可维护的网络应用。中间件和钩子的使用可以使请求和响应处理更加灵活,而性能优化和安全性增强则是提升应用质量和用户体验的关键。
# 6. Requests库的故障排除与调试
## 6.1 日志记录和监控
在使用Requests库进行网络请求时,日志记录和监控是不可或缺的环节。它们可以帮助开发者了解请求的详细流程,包括请求发送的时间、请求的具体内容、响应的状态码以及响应的数据等信息。这对于故障排查和性能分析至关重要。
### 6.1.1 配置日志记录
Requests库支持集成Python的`logging`模块来配置日志记录。以下是一个配置日志记录的示例:
```python
import requests
import logging
# 配置日志
logging.basicConfig(level=logging.DEBUG)
# 创建一个会话对象
session = requests.Session()
# 发送请求
response = session.get('***')
# 日志输出
logging.debug('Request sent to %s', response.url)
logging.debug('Response received with status code %s', response.status_code)
```
在这个示例中,我们将日志级别设置为`DEBUG`,这意味着所有级别的日志信息都会被记录。然后,我们通过`logging.debug`输出了请求的URL和响应的状态码。
### 6.1.2 监控HTTP请求性能
监控HTTP请求的性能可以帮助我们了解请求的响应时间,这对于评估API的性能和定位慢请求非常有用。Requests库本身不提供内置的性能监控工具,但可以通过`time`模块来手动计算请求的时间。
```python
import requests
import logging
import time
# 配置日志
logging.basicConfig(level=***)
# 记录请求开始时间
start_time = time.time()
# 发送请求
response = requests.get('***')
# 记录请求结束时间
end_time = time.time()
# 计算响应时间
duration = end_time - start_time
# 日志输出
***('Request sent to %s', response.url)
***('Response received with status code %s', response.status_code)
***('Request took %f seconds', duration)
```
在这个示例中,我们使用`time.time()`记录了请求发送前的时间戳和请求完成后的时间戳,然后计算两者之间的差值,即请求的响应时间。
## 6.2 常见问题诊断与解决
在使用Requests库时,可能会遇到各种问题,例如HTTP错误状态码、网络连接问题、超时等。通过适当的错误处理和问题诊断,我们可以有效地解决这些问题。
### 6.2.1 HTTP状态码的解读
HTTP状态码是服务器对客户端请求的响应,它们可以告诉我们请求是否成功,或者失败的原因是什么。以下是一些常见的HTTP状态码及其含义:
| 状态码 | 描述 |
|--------|------|
| 200 | 请求成功 |
| 404 | 未找到资源 |
| 500 | 服务器内部错误 |
| 401 | 未授权 |
| 403 | 禁止访问 |
### 6.2.2 响应异常的处理
在使用Requests库时,如果遇到异常响应,我们可以捕获这些异常并进行相应的处理。例如:
```python
import requests
try:
response = requests.get('***', timeout=5)
response.raise_for_status()
except requests.exceptions.HTTPError as errh:
print ("Http Error:",errh)
except requests.exceptions.ConnectionError as errc:
print ("Error Connecting:",errc)
except requests.exceptions.Timeout as errt:
print ("Timeout Error:",errt)
except requests.exceptions.RequestException as err:
print ("OOps: Something Else",err)
```
在这个示例中,我们使用`try-except`块捕获了可能发生的异常,并根据不同的异常类型输出了相应的错误信息。
## 6.3 调试工具和技巧
在开发和维护使用Requests库的应用程序时,使用调试工具可以帮助我们更有效地定位问题。
### 6.3.1 使用调试工具进行问题定位
Python的调试库`pdb`是一个非常有用的工具,它允许我们在代码中设置断点,然后逐步执行代码,查看变量的值,以及执行其他调试操作。以下是如何使用`pdb`进行调试的示例:
```python
import requests
import pdb
# 设置断点
pdb.set_trace()
# 发送请求
response = requests.get('***')
# 输出响应
print(response.text)
```
在这个示例中,我们在发送请求之前设置了一个断点。当代码运行到这里时,它会暂停,允许我们检查当前的环境和变量的状态。
### 6.3.2 调试过程中的性能优化
在调试过程中,我们可能需要多次发送相同的请求。为了避免重复输入相同的代码,我们可以使用函数来封装请求逻辑。以下是一个封装请求的示例:
```python
import requests
def send_request(url):
response = requests.get(url)
return response
# 使用函数发送请求
response = send_request('***')
print(response.text)
```
在这个示例中,我们将发送请求的代码封装在了一个名为`send_request`的函数中。这样,我们只需要调用这个函数并传入URL即可,这使得调试过程更加高效。
通过以上内容,我们介绍了Requests库在故障排除与调试方面的应用,包括日志记录和监控、常见问题诊断与解决以及调试工具和技巧。这些技能对于高效地使用Requests库至关重要。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入探讨了 Python 中 HTTP 库文件的方方面面,从基础使用技巧到高级应用和性能优化。它涵盖了广泛的主题,包括:
* HTTP 库文件的入门和精通
* Requests 库的高效 HTTP 请求
* 专业 HTTP 请求解决方案的构建
* HTTP 请求性能的提升
* Webhooks 的轻松处理
* 会话管理和 Cookies 处理
* 大文件上传和下载的流式处理
* HTTP 请求错误的优雅处理
* HTTP 认证机制的深入剖析
* 数据传输安全的 HTTPS 使用
* 字符编码问题的解决
* HTTP 头部的自定义
* HTTP 请求日志的记录和分析
* HTTP 请求缓存机制的实现
* HTTP 重定向的自动处理
* HTTP 请求和响应压缩的应用
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
SIP栈工作原理大揭秘:消息流程与实现机制详解

# 摘要
SIP协议作为VoIP技术中重要的控制协议,它的理解和应用对于构建可靠高效的通信系统至关重要。本文首先对SIP协议进行了概述,阐述了其基本原理、消息类型及其架构组件。随后,详细解析了SIP协议的消息流程,包括注册、会话建立、管理以及消息的处理和状态管理。文中还探讨了SIP的实现机制,涉及协议栈架构、消息处理过程和安全机制,特
【Stata数据管理】:合并、重塑和转换的专家级方法
# 摘要
本文全面介绍了Stata在数据管理中的应用,涵盖了数据合并、连接、重塑和变量转换等高级技巧。首先,文章概述了Stata数据管理的基本概念和重要性,然后深入探讨了数据集合并与连接的技术细节和实际案例,包括一对一和多对一连接的策略及其对数据结构的影响。接着,文章详细阐述了长宽格式转换的方法及其在Stata中的实现,以及如何使用split和merge命令进行多变量数据的重塑。在数据转换与变量生成策略部分,文章讨论了变量转换、缺失值处理及数据清洗等关键技术,并提供了实际操作案例。最后,文章展示了从数据准备到分析的综合应用流程,强调了在大型数据集管理中的策略和数据质量检查的重要性。本文旨在为S
【Canal+消息队列】:构建高效率数据变更分发系统的秘诀

# 摘要
本文全面介绍消息队列与Canal的原理、配置、优化及应用实践。首先概述消息队列与Canal,然后详细阐述Canal的工作机制、安装部署与配置优化。接着深入构建高效的数据变更分发系统,包括数据变更捕获技术、数据一致性保证以及系统高可用与扩展性设计。文章还探讨了Canal在实时数据同步、微服务架构和大数据平台的数据处理实践应用。最后,讨论故障诊断与系
Jupyter环境模块导入故障全攻略:从错误代码到终极解决方案的完美演绎

# 摘要
本文针对Jupyter环境下的模块导入问题进行了系统性的探讨和分析。文章首先概述了Jupyter环境和模块导入的基础知识,然后深入分析了模块导入错误的类型及其背后的理论原理,结合实践案例进行了详尽的剖析。针对模块导入故障,本文提出了一系列诊断和解决方法,并提供了预防故障的策略与最佳实践技巧。最后,文章探讨了Jupyter环境中
Raptor流程图:决策与循环逻辑构建与优化的终极指南
# 摘要
Raptor流程图作为一种图形化编程工具,广泛应用于算法逻辑设计和程序流程的可视化。本文首先概述了Raptor流程图的基本概念与结构,接着深入探讨了其构建基础,包括流程图的元素、决策逻辑、循环结构等。在高级构建技巧章节中,文章详细阐述了嵌套循环、多条件逻辑处理以及子流程与模块化设计的有效方法。通过案例分析,文章展示了流程图在算法设计和实际问题解决中的具体应用。最后,本文
【MY1690-16S开发实战攻略】:打造个性化语音提示系统

# 摘要
本论文详细介绍了MY1690-16S开发平台的系统设计、编程基础以及语音提示系统的开发实践。首先概述了开发平台的特点及其系统架构,随后深入探讨了编程环境的搭建和语音提示系统设计的基本原理。在语音提示系统的开发实践中,本文阐述了语音数据的采集、处理、合成与播放技术,并探讨了交互设计与用户界面实现。高级功能开发章节中,我们分析了
【VB编程新手必备】:掌握基础与实例应用的7个步骤
# 摘要
本文旨在为VB编程初学者提供一个全面的入门指南,并为有经验的开发者介绍高级编程技巧。文章从VB编程的基础知识开始,逐步深入到语言的核心概念,包括数据类型、变量、控制结构、错误处理、过程与函数的使用。接着,探讨了界面设计的重要性,详细说明了窗体和控件的应用、事件驱动编程以及用户界面的响应性设计。文章进一步深入探讨了文件操作、数据管理、数据结构与算法,以及如何高效使用动态链接库和API。最后,通过实战案例分
【Pix4Dmapper数据管理高效术】:数据共享与合作的最佳实践

# 摘要
Pix4Dmapper是一款先进的摄影测量软件,广泛应用于数据管理和团队合作。本文首先介绍了Pix4Dmapper的基本功能及其数据管理基础,随后深入探讨了数据共享的策略与实施,强调了其在提高工作效率和促进团队合作方面的重要性。此外,本文还分析了Pix4Dmapper中的团队合作机制,包括项目管理和实时沟通工具的有效运用。随着大数据
iPhone 6 Plus升级攻略:如何利用原理图纸优化硬件性能

# 摘要
本文详细探讨了iPhone 6 Plus硬件升级的各个方面,包括对原理图纸的解读、硬件性能分析、性能优化实践、进阶硬件定制与改造,以及维护与故障排除的策略。通过分析iPhone 6
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )