Textile文本内容分析:从文本中提取信息的8大技巧
发布时间: 2024-10-14 14:04:16 阅读量: 38 订阅数: 28 
# 1. Textile文本内容分析概述
文本分析,作为数据科学的重要分支,对于理解和挖掘文本中的信息具有至关重要的作用。Textile文本分析旨在从原始文本数据中提取有价值的信息,支持决策制定和知识发现。本章将概述文本分析的基本概念和重要性。
## 文本分析的重要性
文本分析不仅是数据处理的一部分,它还涉及到自然语言处理(NLP)的技术和方法。通过对文本内容的分析,我们可以实现对大量非结构化数据的有效管理,从而获得深刻的洞察力。
## 文本分析的应用场景
文本分析技术广泛应用于多个领域,包括但不限于社交媒体监控、客户服务自动化、市场分析、情报分析、学术研究等。在社交媒体上,文本分析可以帮助企业了解公众对其品牌的态度和情感倾向。在客户服务中,它可以自动识别和分类客户查询,提高响应效率。
## 文本分析的挑战
尽管文本分析具有巨大潜力,但它也面临许多挑战,如语言的多样性和复杂性、文本中的非结构化特性以及语义理解的难题。这些挑战要求分析师和研究人员不断探索更先进的算法和技术,以提高分析的准确性和效率。
# 2. 文本预处理技巧
文本预处理是文本分析中的关键步骤,它直接影响到后续分析的质量和准确性。本章节将详细介绍文本预处理中的三个重要环节:文本清洗、分词与词性标注、正则表达式在文本处理中的应用。
## 2.1 文本清洗
文本清洗是预处理的第一步,它包括去除无关字符、标准化文本格式等操作,以确保文本数据的质量。
### 2.1.1 去除无关字符
在文本数据中,常常会夹杂着一些无关字符,如标点符号、特殊字符等。这些字符不仅会增加数据的复杂性,还会影响分析结果。因此,我们需要对文本进行清洗,去除这些无关字符。
#### 示例代码
```python
import re
# 原始文本
text = "Hello, World! This is a sample text with some special characters: !@#$%^&*."
# 使用正则表达式去除标点符号
cleaned_text = re.sub(r'[^\w\s]', '', text)
print(cleaned_text)
```
#### 代码逻辑解读分析
- `import re`:导入Python的正则表达式库。
- `text`:原始文本字符串。
- `re.sub(r'[^\w\s]', '', text)`:使用正则表达式`[^\w\s]`匹配所有非字母数字和非空格字符,并将它们替换为空,即删除这些字符。
- `print(cleaned_text)`:打印清洗后的文本。
#### 参数说明
- `r'[^\w\s]'`:正则表达式,匹配所有非字母数字和非空格字符。
- `''`:替换为字符串,即删除匹配到的字符。
### 2.1.2 标准化文本格式
标准化文本格式通常包括统一大小写、移除停用词等操作。这有助于减少文本的冗余度,提高分析效率。
#### 示例代码
```python
# 原始文本
text = "Textile文本内容分析是一个重要的领域,在文本分析中占据着核心地位。"
# 转换为小写
text_lower = text.lower()
# 移除停用词(此处仅为示例,实际操作需要完整的停用词列表)
stopwords = set(["的", "是", "一个", "在", "中", "占据着", "着"])
words = text_lower.split()
filtered_words = [word for word in words if word not in stopwords]
cleaned_text = " ".join(filtered_words)
print(cleaned_text)
```
#### 代码逻辑解读分析
- `text_lower = text.lower()`:将文本转换为小写,以统一大小写。
- `words = text_lower.split()`:将文本分割为单词列表。
- `filtered_words = [word for word in words if word not in stopwords]`:移除停用词。
- `cleaned_text = " ".join(filtered_words)`:将清洗后的单词列表重新组合成文本。
#### 参数说明
- `text.lower()`:将文本转换为小写。
- `text_lower.split()`:按空格分割文本为单词列表。
- `stopwords`:停用词列表,包含需要被移除的常见单词。
## 2.2 分词与词性标注
分词与词性标注是中文文本处理中的重要步骤,它们将文本分解为更小的单元,并赋予它们相应的语法属性。
### 2.2.1 使用分词工具进行文本分割
中文文本分词是将连续的文本切分为有意义的词汇单元。常用的分词工具包括jieba、HanLP等。
#### 示例代码
```python
import jieba
# 原始文本
text = "Textile文本内容分析是一个重要的领域。"
# 使用jieba进行分词
words = jieba.lcut(text)
print(words)
```
#### 代码逻辑解读分析
- `import jieba`:导入jieba分词库。
- `jieba.lcut(text)`:使用jieba进行精确分词。
- `print(words)`:打印分词结果。
#### 参数说明
- `text`:待分词的原始文本。
- `jieba.lcut`:jieba提供的分词函数,`lcut`表示直接返回一个列表。
### 2.2.2 词性标注的原理与应用
词性标注是为文本中的每个词汇赋予语法属性,如名词、动词等。这对于理解文本结构和语义非常重要。
#### 示例代码
```python
import jieba.posseg as pseg
# 原始文本
text = "Textile文本内容分析是一个重要的领域。"
# 使用jieba进行分词并进行词性标注
words = pseg.cut(text)
for word, flag in words:
print(f"{word}/{flag}")
```
#### 代码逻辑解读分析
- `import jieba.posseg as pseg`:导入jieba提供的词性标注模块。
- `pseg.cut(text)`:进行分词并同时进行词性标注。
- `for word, flag in words`:遍历分词结果,`word`为词汇,`flag`为词性。
#### 参数说明
- `jieba.posseg.cut`:进行分词的同时进行词性标注。
## 2.3 正则表达式在文本处理中的应用
正则表达式是一种强大的文本匹配工具,它可以在文本中快速查找和替换特定模式的字符串。
### 2.3.1 正则表达式的构建与使用
正则表达式由特殊字符和文本字符组成,用于描述匹配模式。
#### 示例代码
```python
# 原始文本
text = "Textile文本内容分析(Textile)是一个重要的领域。"
# 使用正则表达式查找括号内的内容
pattern = r"\((.*?)\)"
matches = re.findall(pattern, text)
print(matches)
```
#### 代码逻辑解读分析
- `pattern = r"\((.*?)\)"`:构建正则表达式模式,匹配括号内的任意字符。
- `re.findall(pattern, text)`:在文本中查找所有匹配的子串。
- `print(matches)`:打印匹配结果。
#### 参数说明
- `pattern`:正则表达式模式。
- `re.findall`:在文本中查找所有匹配的子串。
### 2.3.2 案例分析:信息提取实例
正则表达式在信息提取方面有着广泛的应用,例如从文本中提取电话号码、邮箱地址等。
#### 示例代码
```python
# 原始文本
text = "联系邮箱:***,联系电话:123-456-7890。"
# 使用正则表达式提取邮箱和电话
email_pattern = r"\b\w+@\w+\.\w+\b"
phone_pattern = r"\b\d{3}-\d{3}-\d{4}\b"
emails = re.findall(email_pattern, text)
phones = re.findall(phone_pattern, text)
print(f"Emails: {emails}")
print(f"Phones: {phones}")
```
#### 代码逻辑解读分析
- `email_pattern`:构建匹配邮箱地址的正则表达式模式。
- `phone_pattern`:构建匹配电话号码的正则表达式模式。
- `re.findall(email_pattern, text)`:提取文本中的邮箱地址。
- `re.findall(phone_pattern, text)`:提取文本中的电话号码。
#### 参数说明
- `email_pattern`:用于匹配邮箱地址的正则表达式模式。
- `phone_pattern`:用于匹配电话号码的正则表达式模式。
通过本章节的介绍,我们可以看到文本预处理的重要性,以及如何使用Python进行基本的文本清洗、分词与词性标注、正则表达式在文本处理中的应用。这些技能是进行深入文本分析的基石,为后续章节中的信息抽取技术和高级应用打下了坚实的基础。
# 3. 信息抽取技术
信息抽取技术是文本分析中的重要组成部分,它能够从非结构化的文本数据中提取出结构化信息,例如人名、地点、组织、数字、时间等实体,以及它们之间的关系和事实信息。本章节将详细介绍信息抽取技术的核心组成部分:命名实体识别、关系抽取和事实抽取,并通过案例分析,展示如何从文本中提取这些有价值的信息。
## 3.1 命名实体识别(NER)
### 3.1.1 NER的基本概念
命名实体识别(Named Entity Recognition,NER)是自然语

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入探讨了 Textile 库,一个用于 Python 文本处理的强大工具。从初学者指南到高级技巧,它涵盖了 Textile 的各个方面,包括文本格式化、HTML 转换、链接处理、列表和表格创建、样式控制、国际化、安全实践、搜索优化、内容分析、性能优化、内容校验、PDF 输出、缓存策略、分页处理、正则表达式应用、内容拼接和分割,以及压缩和解压缩。通过深入的教程和实用示例,本专栏旨在帮助开发者掌握 Textile 的功能,从而创建互动、可读且高效的文本处理应用程序。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【RCS-2000 V3.1.3系统性能提升秘籍】:有效策略加速调度效率

# 摘要
RCS-2000 V3.1.3系统作为研究对象,本文首先概述了其系统架构与特性。接着,本文深入探讨了系统性能评估的理论基础,包括关键性能指标、性能瓶颈的诊断方法以及性能测试和基准比较的策略。在系统性能优化策略部分,文章详细介绍了系统配置、资源管理、负载均衡以及缓存与存储优化的方法。此外,本文还记录了
C#操作INI文件的20个常见问题解决与优化策略
# 摘要
本文详细探讨了在C#编程环境下操作INI文件的方法,涵盖了从基础概念到高级应用与优化,再到安全性和兼容性处理的全过程。文章首先介绍了INI文件的基本操作,包括文件的创建、初始化、读取、修改及更新,并提供了错误处理和异常管理的策略。随后,本文探讨了使用第三方库和多线程操作来实现性能优化的进阶技术,并针对安全性问题和跨平台兼容性问题提供了具体的解决方案。最后,结合实战案例,文章总结了最佳实践和代码规范,旨在为开发者提供C#操作INI文件的全面指导和参考。
# 关键字
C#编程;INI文件;文件操作;多线程;性能优化;安全性;兼容性
参考资源链接:[C#全方位详解:INI文件操作(写入
【Arima模型高级应用】:SPSS专家揭秘:精通时间序列分析

# 摘要
时间序列分析在理解和预测数据变化模式中扮演着关键角色,而ARIMA模型作为其重要工具,在众多领域得到广泛应用。本文首先介绍了时间序列分析的基础知识及ARIMA模型的基本概念。接着,详细探讨了ARIMA模型的理论基础,包括时间序列数据的特征分析、模型的数学原理、参数估计、以及模型的诊断和评估方法。第三章通过实例演示了ARIMA模型在SPSS软件中的操作流程,包括数据处理、模型构建和
【散热技术详解】:如何在Boost LED背光电路中应用散热技术,提高热管理效果

# 摘要
散热技术对于维护电子设备的性能和寿命至关重要。本文从散热技术的基础知识出发,详细探讨了Boost LED背光电路的热源产生及其传播机制,包括LED的工作原理和Boost电路中的热量来源。文章进一步分析了散热材料的选择标准和散热器设计原则,以及散热技术在LED背光电路中的实际应用。同
CTM安装必读:新手指南与系统兼容性全解析

# 摘要
CTM系统的安装与维护是确保其高效稳定运行的关键环节。本文全面介绍了CTM系统的安装流程,包括对系统兼容性、软件环境和用户权限的细致分析。文章深入探讨了CTM系统兼容性问题的诊断及解决策略,并提供了详细的安装前准备、安装步骤以及后续的配置与优化指导。此外,本文还强调了日常维护与系统升级的重要性,并提供了有效的故障恢复与备份措施,以保障CTM系统运行的连续性和安全性。
# 关键字
CTM系统;兼容性分析;安装流
【EC200A模组MQTT协议全解】:提升物联网通信效率的7大技巧
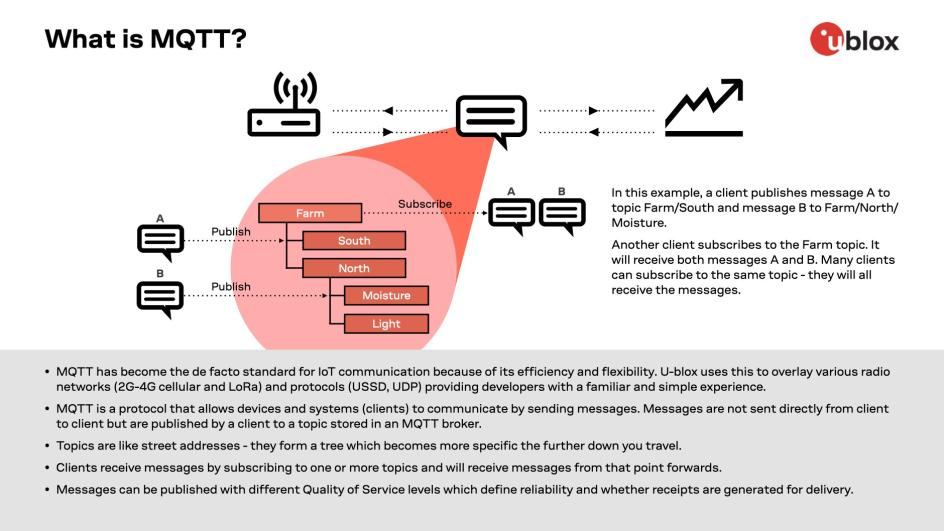
# 摘要
本文旨在探讨EC200A模组与MQTT协议在物联网通信中的应用。首先介绍了EC200A模组的基础和MQTT协议的理论架构,包括其起源、优势、消息模式、QoS等级及安全机制。随后,通过具体实例演示了EC200A模组的设置、MQTT通信的实现及性能优化。文章进一步提出了优化MQTT连接和消息处理的技巧,并强调了安全通信的重要性。最
SDH信号故障排查秘籍:帧结构问题快速定位与解决方案,让你的网络无懈可击!

# 摘要
SDH(同步数字体系)作为电信传输的重要技术,其帧结构的稳定性和可靠性对于数据通信至关重要。本文首先介绍了SDH信号及其帧结构的基础知识,详细阐述了帧结构的组成部分和数据传输机制。接着,通过理论分析,识别并解释了帧结构中常见的问题类型,例如同步信号丢失、帧偏移与错位,以及数据通道的缺陷。为了解决这些问题,本文探讨了利用专业工具进行故障检测和案例分析的策略,提出了快速解
【Android Studio与Gradle:终极版本管理指南】:2023年最新工具同步策略与性能优化
# 摘要
本文综合概述了Android Studio和Gradle在移动应用开发中的应用,深入探讨了版本控制理论与实践以及Gradle构建系统的高级特性。文章首先介绍了版本控制系统的重要性及其在Android项目中的应用,并讨论了代码分支管理策
2路组相联Cache性能提升:优化策略与案例分析
# 摘要
本文深入探讨了2路组相联Cache的基本概念、性能影响因素、优化策略以及实践案例。首先介绍了2路组相联Cache的结构特点及其基本操作原理,随后分析了影响Cache性能的关键因素,如访问时间、命中率和替换策略。基于这些理论基础,文中进一步探讨了多种优化策略,包括Cache结构的调整和管理效率的提升,以及硬件与软件的协同优化。通过具体的实践案例,展示了如何通过分析和诊断来实施优化措施,并通过性能测试来评估效果。最后,展望了Cache优化领域面临的新兴技术和未来研究方向,包括人工智能和多级Cache结构的应用前景。
# 关键字
2路组相联Cache;性能影响因素;优化策略;命中率;替换
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )