【模型评估与选择】:今日头条BP高清版中的算法评估与选择标准
发布时间: 2024-12-17 10:25:20 订阅数: 1 

今日头条BP(高清版).pdf

参考资源链接:[今日头条早期商业计划书:成长之路解析](https://wenku.csdn.net/doc/bwkk2p8tdg?spm=1055.2635.3001.10343)
# 1. 模型评估与选择的基本概念
## 简介
在进行机器学习项目时,模型评估与选择是关键步骤之一。它们关系到最终模型能否准确预测结果并广泛应用于现实世界问题。本章节将介绍模型评估与选择的一些基本概念。
## 模型评估的目的
模型评估的主要目的是为了衡量模型在未知数据上的表现。通过对模型在训练集和测试集上的表现进行分析,我们可以得到模型的准确度、召回率、精确度等关键性能指标。这些指标帮助我们了解模型的强弱,并作出进一步优化。
## 模型选择的重要性
模型选择则涉及到从多个候选模型中选取最适合解决特定问题的模型。选择时不仅要考虑模型的性能,也要权衡模型的复杂度、可解释性以及计算效率等因素。正确的模型选择可以减少资源的浪费并提升模型的实际应用价值。
# 2. 模型性能评估指标
### 2.1 模型准确性评估
在机器学习中,准确性评估是最直观、最常见的评估指标。它指的是模型预测正确的样本占总样本的比例。在分类问题中,准确性通常用来衡量模型预测与真实标签的一致性。
#### 2.1.1 正确率、召回率和精确度
**正确率**(Accuracy)是模型正确预测的样本数占总样本数的比例。它是一个简单直观的评估指标,但当数据集中的正负样本分布极不平衡时,正确率可能无法准确反映模型性能。例如,在一个99%的数据点属于类别A,只有1%属于类别B的数据集中,即使模型始终预测类别A,其正确率也能达到99%。
```python
from sklearn.metrics import accuracy_score
# 假设 y_true 是真实标签,y_pred 是模型预测标签
y_true = [1, 2, 3, 4, 1, 2, 3, 4, 1, 2]
y_pred = [2, 3, 4, 1, 2, 3, 4, 1, 2, 3]
# 计算正确率
accuracy = accuracy_score(y_true, y_pred)
print(f"Accuracy: {accuracy}")
```
**召回率**(Recall)又称为真阳性率(True Positive Rate, TPR),指模型正确预测为正的样本占实际正样本的比例。召回率关注于正类样本,对于那些漏掉正类样本损失很大的应用场景尤为重要。
```python
from sklearn.metrics import recall_score
# 计算召回率
recall = recall_score(y_true, y_pred, average='macro') # 平均值计算所有类的召回率
print(f"Recall: {recall}")
```
**精确度**(Precision)则是指模型正确预测为正的样本占预测为正样本的比例。精确度关注于正类预测的准确性,对于成本消耗高的错误预测需要高度重视的场景下,精确度尤为关键。
```python
from sklearn.metrics import precision_score
# 计算精确度
precision = precision_score(y_true, y_pred, average='macro')
print(f"Precision: {precision}")
```
#### 2.1.2 F1分数和混淆矩阵
**F1分数**是精确度和召回率的调和平均数,它在精确度和召回率之间取得平衡,是一个非常有用的单一度量指标。F1分数最高的模型通常会更好地平衡正确率和召回率。
```python
from sklearn.metrics import f1_score
# 计算F1分数
f1 = f1_score(y_true, y_pred, average='macro')
print(f"F1 Score: {f1}")
```
**混淆矩阵**(Confusion Matrix)是一个非常有用的工具,用于可视化模型性能。它的每一行代表了实际的类别,每一列代表了预测的类别。通过混淆矩阵,可以直观地看出模型预测的真正类、假正类、真负类和假负类的数量。
```python
from sklearn.metrics import confusion_matrix
# 计算混淆矩阵
conf_matrix = confusion_matrix(y_true, y_pred)
print(f"Confusion Matrix:\n{conf_matrix}")
```
### 2.2 模型复杂度与泛化能力
#### 2.2.1 模型复杂度的影响
模型复杂度是指模型参数的数量以及模型结构的复杂性。对于线性模型而言,复杂度通常与特征数量相关;对于非线性模型(如神经网络),复杂度则与层数、每层的单元数以及参数数量相关。一个模型的复杂度越高,它对训练数据的拟合能力越强,但可能导致过拟合,降低泛化能力。
过拟合是指模型对训练数据拟合过度,导致无法很好地泛化到新的数据上。相反,欠拟合则是指模型无法在训练数据上获得良好的性能,泛化能力同样不佳。
#### 2.2.2 泛化误差和过拟合
**泛化误差**是指模型在未见数据上的性能。泛化能力越强的模型,其泛化误差越小。在实际操作中,我们通常用交叉验证等方法来估计模型的泛化误差。
**过拟合**的直接表现是训练误差远低于验证误差。当过拟合发生时,模型学习到了数据中的噪声,没有捕捉到数据的底层分布。解决过拟合的方法有很多,例如增加训练数据、减少模型复杂度、正则化、提前停止等。
### 2.3 模型比较与验证
#### 2.3.1 交叉验证方法
交叉验证是一种统计方法,用来评估并比较学习算法的性能。它将原始样本分成k个子样本,一个单独的子样本被保留作为验证模型的数据,其他k-1个子样本用来训练。这样会得到k个模型,在k个验证集上的性能可以用来评估模型的泛化能力。
**k折交叉验证**是最常用的交叉验证方法之一。通常将数据集分成k个大小相等的子集。其中的k-1个子集用于训练模型,剩下的一个子集用于验证模型。这个过程会重复k次,每次选择不同的子集作为验证集。最后,我们计算k次验证过程中性能指标的平均值。
```python
from sklearn.model_selection import cross_val_score
# 假设我们有一个模型和数据集 X 和 y
# 我们使用交叉验证来评估
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
自动化采购审批流程:SAP MM中的高效策略大公开

参考资源链接:[SAP MM审批策略详解:采购申请与订单审批配置](https://wenku.csdn.net/doc/r6x5urovpm?spm=1055.2635.3001.10343)
# 1. SAP MM模块概述
## SAP MM模块的核心价值
SAP MM (Material Management) 模块是企业资源规划 (ERP) 系统中
PFC3D项目管理手册:多任务并行模拟的高效协调术

参考资源链接:[PFC3D中文教程:从入门到实践](https://wenku.csdn.net/doc/551ab8hgb4?spm=1055.2635.3001.10343)
# 1. PFC3D项目管理的理论基础
在工程领域中,项目管理是确保项目按时、按预算和按质量完成的关键。PFC3D(Particle Flow Code in 3 Dimensions)作为一种模拟颗粒流体动力学行为的软件,其项目管理的理论基础尤为重要。PFC3D项目管理
【CSR8635数据手册深度解析】:揭秘蓝牙芯片技术细节与应用精髓
参考资源链接:[CSR8635蓝牙芯片技术规格解析](https://wenku.csdn.net/doc/646d658f543f844488d69646?spm=1055.2635.3001.10343)
# 1. CSR8635芯片概述
CSR8635芯片是Cambridge Silicon Radio公司(现为高
【充电芯片选择攻略】:LTH7与其他芯片的性能对比分析

参考资源链接:[LTH7充电芯片技术详解与应用](https://wenku.csdn.net/doc/6412b66ebe7fbd1778d46b3e?spm=1055.2635.3001.10343)
# 1. 充电芯片基础知识概述
充电芯片作为电子设备中不可或缺的组成部分,它的核心作用是将电源适
【戴尔R730操作系统部署攻略】:选择最佳系统并规避常见陷阱
参考资源链接:[戴尔R730服务器Windows Server 2012R2系统安装指南](https://wenku.csdn.net/doc/3bbt4e9nu2?spm=1055.2635.3001.10343)
# 1. 戴尔R730服务器概述
## 1.1 服务器硬件概览
戴尔PowerEdge R730服务器是企业级数据中心的支柱,它搭载了Intel Xeon处理器,支持双路配置,可提供强大的处理能力。具备多种扩展槽和大量内存插槽,最高支持24个硬盘驱动器,使它在存储解决方案中脱颖而出。
## 1.2 核心特性分析
R730的核心特性包括灵活的存储选项和出色的能效表现。服务器的
【TMS320F28335系统效率提升秘籍】:电源管理优化的7种策略

参考资源链接:[TMS320F28335中文数据手册:DSP开发速查](https://wenku.csdn.net/doc/6401ac00cce7214c316ea451?spm=1055.2635.3001.10343)
# 1. TMS320F28335概述与电源管理基础
## 1.1 TMS320F28335简介
TMS320F28335是德州仪器(Texas Instruments)推出的一款高性能微控
PLC编程基础:自动化包装机逻辑控制的必修课

参考资源链接:[《机械原理》课程设计:巧克力糖自动包装机机构详解](https://wenku.csdn.net/doc/6to1n1amvq?spm=1055.2635.3001.10343)
# 1. PLC编程概述与基础
## 1.1 PLC的定义与应用领域
PLC(Programmable Logic Controller,可编程逻辑控制器)是一种
一步到位的流程优化:Gabi软件自动化工作流设计秘籍
参考资源链接:[GaBi4入门教程:全面解析软件操作与数据库应用](https://wenku.csdn.net/doc/4u2agq0o4r?spm=1055.2635.3001.10343)
# 1. 软件自动化工作流设计概述
在现代软件开发中,自动化工作流设计是提高效率、降低成本和减少错误的关键因素之一。工作流自动化不
星三角降压启动安全操作规程:遵循这5大原则,确保零事故运行
参考资源链接:[星三角降压启动plc梯形图电路图](https://wenku.csdn.net/doc/6412b783be7fbd1778d4a91d?spm=1055.2635.3001.10343)
# 1. 星三角降压启动概述
星三角降压启动是一种广泛应用于工业电机控制中的启动方式,其设计的初衷是为了减少直接启动大功率电机时产生的高电流冲击。通过这一技术,电机可以较为平稳地启动,从而延长设备寿命,并且有效降低对电网的冲击。
在本章中,我们将简要介绍星三角降压启动的基本概念,以及其在工业应用中的重要性。接下来的章节将深入探讨星三角降压启动的工作原理、系统组成、关键参数以及实际应用和
【ANSYS ICEM CFD并行计算优化大揭秘】:计算效率提升不止一倍!
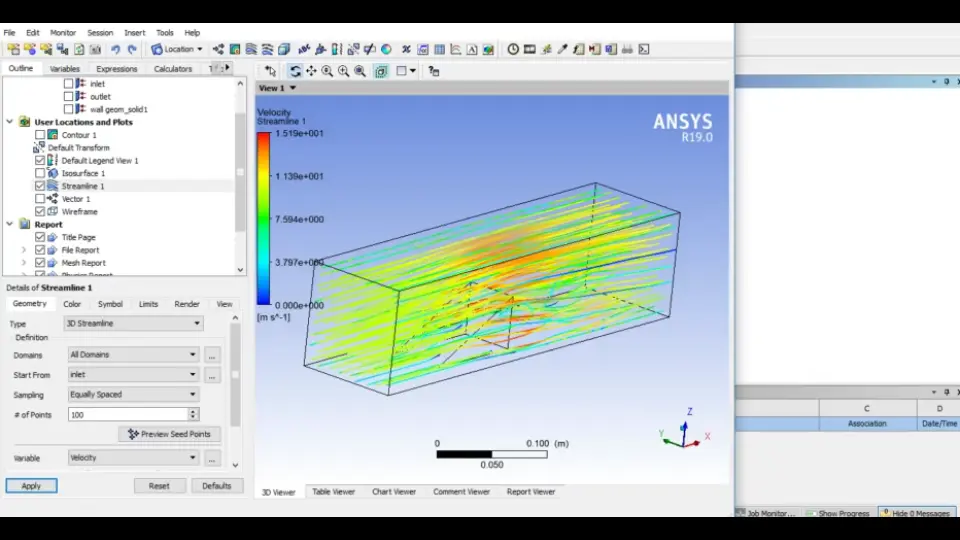
参考资源链接:[ANSYS ICEM CFD 19.0用户手册:权威指南](https://wenku.csdn.net/doc/5btqfdc8a9?spm=1055.2635.3001.10343)
# 1. ANSYS ICEM CFD并行计算基础
ANSYS ICEM CFD是业界领先的计算流体动力学(CFD)前处理软件,它在工程仿真领域扮演着至
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录

文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )