docutils.nodes教程:节点过滤与修改的8大技巧
发布时间: 2024-10-16 02:25:09 阅读量: 14 订阅数: 15 

DocUtils.java

# 1. docutils.nodes概述
## 1.1 docutils和nodes简介
在文档处理领域,`docutils` 是一个非常强大的 Python 库,它提供了一整套工具,用于将结构化文本转换成各种格式的文档,比如 HTML、PDF 等。`nodes` 是 `docutils` 中的一个核心概念,代表文档的结构化元素,如段落、标题、列表等。在本章节中,我们将探讨 `docutils.nodes` 的基本概念及其在文档处理中的作用。
## 1.2 docutils.nodes的组成
`docutils.nodes` 主要由节点(Node)和节点访问者(NodeVisitor)组成。节点是文档结构的基本单位,每个节点都具有类型、属性和子节点。节点访问者则是一种用于遍历和操作节点树的特殊对象。通过节点和节点访问者,`docutils` 能够将文本解析成一个层次化的结构,并在此基础上进行文档的生成和转换。
## 1.3 节点树的构建
在 `docutils` 中,文档的解析过程最终会构建出一个节点树。这个树结构是嵌套的,其中每个节点可以包含子节点,形成一个层级化的文档结构。例如,一个文档的根节点可能包含多个块级元素,如标题和段落,而每个块级元素又是由更小的节点构成的。理解节点树的构建对于深入掌握 `docutils.nodes` 和进行文档处理至关重要。
# 2. 节点基础与过滤
### 2.1 节点的定义和类型
#### 2.1.1 节点的基本概念
在`docutils.nodes`中,节点是构成文档树的基本单位。每个节点代表文档中的一个元素,比如段落、标题或者列表项等。节点可以包含其他节点,形成一个树状结构。理解节点的基本概念是使用`docutils`进行文档处理的第一步。
节点由类型、属性和子节点组成。类型定义了节点的种类,如`paragraph`、`title`等;属性则是一个键值对集合,用于存储节点的各种元数据,如`ids`、`classes`等;子节点是该节点的直接子元素,它们也是节点对象。
#### 2.1.2 节点的分类与用途
节点可以根据其功能和用途进行分类。常见的分类包括:
- **结构性节点**:如`document`、`section`、`bullet_list`等,它们定义了文档的结构框架。
- **文本内容节点**:如`paragraph`、`text`等,用于表示文档中的文本内容。
- **装饰性节点**:如`emphasis`、`literal`等,用于对文本进行特定样式的装饰。
### 2.2 节点过滤技巧
#### 2.2.1 过滤方法与原则
节点过滤是根据节点的类型、属性或者位置等条件来选择特定节点的过程。在`docutils`中,过滤节点通常用于文档的解析、转换或者生成特定格式的输出。
过滤节点的基本方法包括:
- **递归遍历**:从文档的根节点开始,递归访问每一个子节点,直到找到满足条件的节点。
- **使用迭代器**:利用`docutils`提供的迭代器,如`visit`和`depart`方法,来遍历节点树。
过滤节点的原则包括:
- **最小化遍历**:尽量减少不必要的节点遍历,提高过滤效率。
- **正则表达式**:在处理文本内容时,合理使用正则表达式可以简化过滤逻辑。
#### 2.2.2 实用过滤示例
以下是使用`docutils`进行节点过滤的一个示例代码:
```python
from docutils import nodes, utils
def find_paragraphs_with_url(app, doctree, docname):
for node in doctree.traverse(nodes.paragraph):
for child in node.children:
if isinstance(child, nodes.Text) and utils.isurllike(child):
app.env.note_dependency(docname)
# 处理找到的包含URL的段落节点
handle_paragraph_with_url(node)
def handle_paragraph_with_url(node):
# 这里可以添加自定义处理逻辑
pass
def setup(app):
app.connect('doctree-resolved', find_paragraphs_with_url)
```
在这个示例中,我们定义了一个`find_paragraphs_with_url`函数,它会遍历文档树中的所有段落节点,并检查其中的文本是否包含URL。如果找到包含URL的段落节点,我们会调用`handle_paragraph_with_url`函数进行处理。
### 2.3 节点访问与查询
#### 2.3.1 访问节点树结构
访问节点树结构通常涉及到递归遍历。下面是一个使用递归函数访问节点树结构的示例:
```python
def traverse_nodes(node):
print(node.__class__.__name__) # 打印当前节点的类型
for child in node:
if isinstance(child, nodes.Node):
traverse_nodes(child) # 递归访问子节
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
**专栏简介:**
本专栏深入探讨 Python 中强大的 docutils.nodes 库,旨在帮助开发者掌握文档处理的艺术。通过一系列深入的文章,我们将揭示 docutils.nodes 的 10 大技巧,优化其性能,深入了解节点操作和应用,探索文档自动化最佳实践,并分析文档生成项目的关键步骤。此外,我们将提供调试技巧、布局设计指南、安全风险分析、扩展开发说明以及 Web 框架集成技巧。专栏还将重点介绍节点过滤和修改、版本控制管理以及 reStructuredText 解析,为读者提供全面的 docutils.nodes 指南,帮助他们构建高效、安全且美观的文档。
专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
ACS运动控制进阶优化:提升性能的4大秘籍

参考资源链接:[ACS运动控制快速调试指南](https://wenku.csdn.net/doc/6412b753be7fbd1778d49e42?spm=1055.2635.3001.10343)
# 1. ACS运动控制系统的概述
## 1.1 ACS运动控制系统的定义和应用
ACS(Advanced Control Syste
深入解析FOCAS接口技术:基础篇与高级应用全揭秘

参考资源链接:[FANUC FOCAS函数API测试工程详解](https://wenku.csdn.net/doc/6412b4fbbe7fbd1778d41859?spm=1055.2635.3001.10343)
# 1. FOCAS接口技术概述
FOCAS,即FANUC Open CNC API Specification,是FANUC数控系统对外开
揭秘Python数据类型:字符串、列表、字典和元组的高效操作指南

参考资源链接:[传智播客&黑马程序员PYTHON教程课件汇总](https://wenku.csdn.net/doc/6412b749be7fbd1778d49c25?spm=1055.2635.3001.10343)
# 1. Python基础数据类型的概述
Python作为一门高级编程语言,其内置的多种数据类型为程序员提供了强大的工具。本章将带领读者了解Python的
CSS图层提升秘籍:专家指导Web层级优化
参考资源链接:[Origin8.5 图层管理教程:调整大小与位置](https://wenku.csdn.net/doc/38n32u79fn?spm=1055.2635.3001.10343)
# 1. CSS图层提升基础概念解析
在现代Web开发中,页面的性能往往决定了用户体验的优劣。CSS图层提升(也称为层提升或层分离)是提高Web页面渲染性能的关键技术之一。为了深入理解图层
【DC1模块载荷谱深度解析】:掌握载荷谱构成与分析方法

参考资源链接:[Romax软件教程:DC1模块-载荷谱分析与处理](https://wenku.csdn.net/doc/4tnpu1h6n7?spm=1055.2635.3001.10343)
# 1. DC1模块载荷谱概述
## 1.1 模块载荷谱的定义
在DC1模块中,载荷谱指的是对模块运行期间所需承载的各类载荷进行的分类和描述。这些载荷可能包括机械应力、温度变化、电磁干扰
【提升HLW8032精度】:掌握精准调试与校准方法
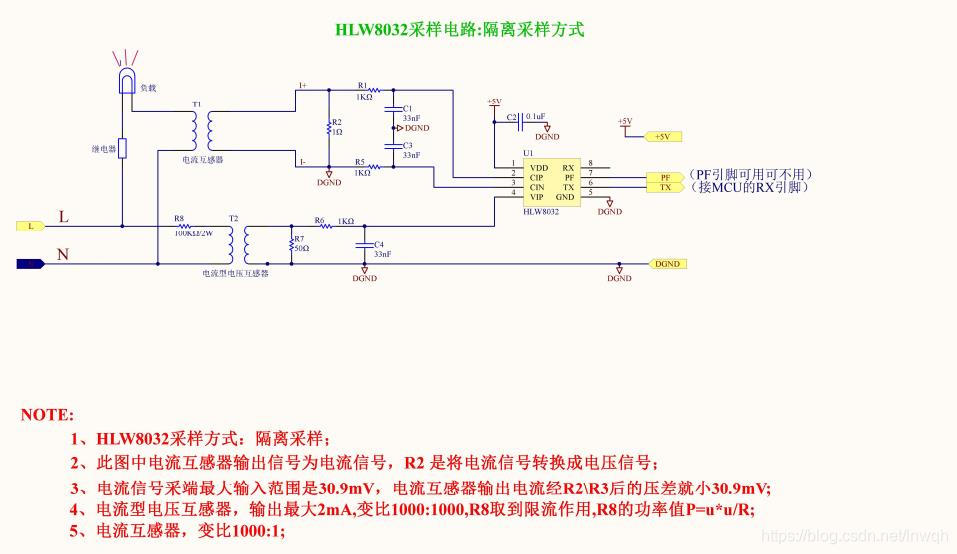
参考资源链接:[HLW8032:高精度单相电能计量IC](https://wenku.csdn.net/doc/6412b732be7fbd1778d49708?spm=10
Element-UI布局实战:国际化、本地化与可访问性优化一步到位
参考资源链接:[Element-UI弹性布局教程:使用el-row和el-col实现自动换行](https://wenku.csdn.net
ImSL 7.0性能调优:安装后的10个关键步骤
参考资源链接:[IMSL7.0安装全攻略:Win10+VS2010+IVF2013](https://wenku.csdn.net/doc/6412b67abe7fbd1778d46df3?spm=1055.2635.3001.10343)
# 1. ImSL 7.0性能调优概述
在信息技术迅速发展的今天,企业对于应用软件性能的要求已经提升到了一个
【S7-1200编程实战】:如何高效实现BYTE到char的转换
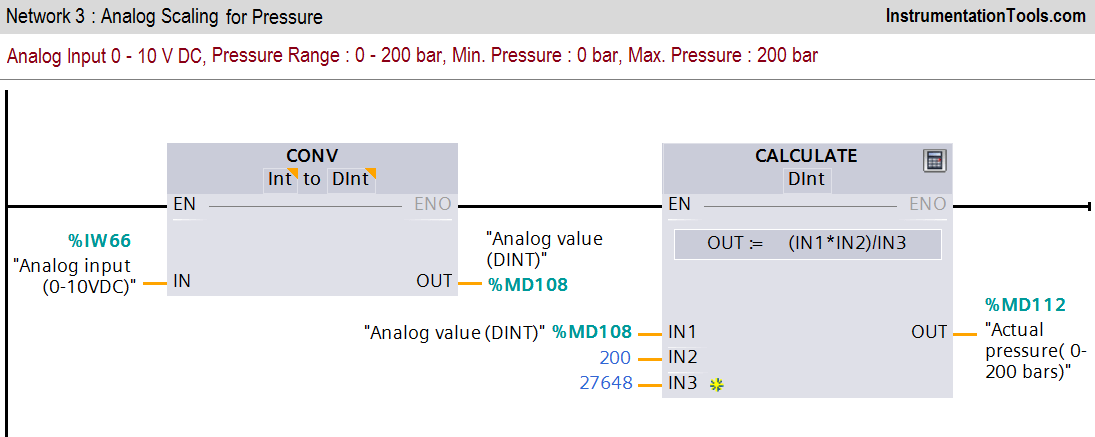
参考资源链接:[S7-1200转换BYTE到char及Char_TO_Strg指令应用解析](https://wenku.csdn.net/doc/51pkntrszz?spm=1055.2635.3001.10343)
# 1. S7-1200 PLC概述及基础数据类型
在工业自动化领域,可编程逻辑控制器(PLC)扮演着至关重要
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )