【Django Sitemaps深入】:数据库交互与性能调优必知
发布时间: 2024-10-11 22:12:07 阅读量: 19 订阅数: 25 

# 1. Django Sitemaps基础概述
在构建复杂网络应用时,确保搜索引擎能高效地发现和索引网站内容至关重要。Django Sitemaps框架为此提供了一个简便的解决方案。本章节旨在为读者提供Django Sitemaps的基础概念和用法,让开发者能够快速上手并集成到自己的项目中。
## Django Sitemaps框架简介
Django Sitemaps是一个用于生成XML Sitemap的框架,旨在帮助开发者自动地维护一个站点地图。站点地图是一个XML文件,它列出了网站上所有需要被搜索引擎抓取的页面地址。搜索引擎如Google、Bing等会使用这个文件来优化搜索结果。
Django Sitemaps利用了Django框架的ORM特性,与模型紧密集成,使得创建和更新站点地图变得异常简单。开发者仅需定义Sitemap类,Django即可负责处理后续的URL生成工作。
## 使用Django Sitemaps的基本步骤
1. 定义一个继承自`***map`的Sitemap类,并指定模型(`sitemap.py`)。
```***
***maps import Sitemap
from .models import MyModel
class MyModelSitemap(Sitemap):
changefreq = "daily" # 指定更新频率
priority = 0.5 # 指定页面的优先级
def items(self):
return MyModel.objects.all()
```
2. 在`urls.py`中配置路由,以便让搜索引擎能够访问到生成的站点地图文件。
```***
***
***maps import MyModelSitemap
sitemaps = {
'mymodel': MyModelSitemap,
}
urlpatterns = [
path('sitemap.xml', sitemap, {'sitemaps': sitemaps}),
]
```
通过这两个步骤,一个基本的站点地图就配置完成了。接下来的章节中,我们将深入探讨Django Sitemaps更高级的使用方法,包括数据库交互、性能优化和SEO应用等方面。
# 2. Django Sitemaps的数据库交互机制
## 2.1 Django ORM系统的基础
### 2.1.1 ORM模型的定义和使用
在Django框架中,ORM(Object-Relational Mapping)系统允许开发者使用Python语言操作数据库,而不需要编写SQL语句。这大大简化了数据库的操作,并且提高了代码的可读性和维护性。
Django ORM定义模型的方式,是通过Python类继承自`django.db.models.Model`。每个类的属性对应数据库表中的一列。例如,我们有一个博客应用,我们可以定义一个`Post`模型:
```python
from django.db import models
class Post(models.Model):
title = models.CharField(max_length=200)
author = models.ForeignKey('auth.User', on_delete=models.CASCADE)
body = models.TextField()
created_on = models.DateTimeField(auto_now_add=True)
updated_on = models.DateTimeField(auto_now=True)
def __str__(self):
return self.title
```
在这个模型中,我们定义了一个博客帖子的数据结构,包括标题、作者、内容以及创建和更新的时间戳。`author`字段是一个外键,指向一个用户。
使用模型进行数据库操作主要包括创建、读取、更新和删除(CRUD)数据:
```python
# 创建
post = Post(title="My first post", body="Hello world!")
post.save()
# 读取
all_posts = Post.objects.all()
latest_post = Post.objects.latest('created_on')
# 更新
post.title = "My updated post"
post.save()
# 删除
post.delete()
```
### 2.1.2 Django查询集(QuerySet)的高级特性
Django的ORM系统使用查询集(QuerySet)来处理数据库查询操作。QuerySet是一个可迭代的对象,它表示从数据库中检索出来的对象集合。它支持链式操作,并可以执行复杂的查询。
例如,我们可以使用`filter()`和`exclude()`方法来实现条件查询:
```python
# 获取所有标题包含"post"的帖子
posts_with_post_in_title = Post.objects.filter(title__contains="post")
# 获取作者是特定用户的帖子
posts_by_author = Post.objects.filter(author=author_user)
```
Django的ORM还提供了`order_by()`方法用于排序:
```python
# 根据创建时间降序排列
ordered_posts = Post.objects.order_by('-created_on')
```
此外,Django的ORM支持联结操作,使用`select_related`和`prefetch_related`来减少数据库查询次数,提高性能:
```python
# 优化帖子及其作者信息的查询
optimized_posts = Post.objects.select_related('author')
```
## 2.2 Django Sitemaps与数据库的交互
### 2.2.1 利用Sitemaps框架实现数据库查询
Django Sitemaps框架允许我们轻松地将数据库中的内容映射到Sitemap XML文件中。Sitemap通过`Sitemap`类来指定,它从`***maps`继承。
以下是一个基本的例子:
```***
***maps import Sitemap
from .models import Post
class PostSitemap(Sitemap):
changefreq = "daily" # 指定更新频率
priority = 0.5 # 指定访问优先级
def items(self):
return Post.objects.all()
def lastmod(self, obj):
return obj.updated_on
```
在`sitemaps`配置中指定这个类,然后在URL配置中引用它,就可以生成对应的Sitemap XML文件。
### 2.2.2 数据库查询优化策略
当数据库中的数据量很大时,不恰当的查询会严重影响性能。Django Sitemaps框架提供了一些优化策略。
首先是减少查询集的大小。例如,如果你只需要最新的一部分帖子,可以使用`Post.objects.all().order_by('-created_on')[:10]`来获取最新的10篇帖子,而不是将所有帖子加载到内存中。
其次,可以使用`iterator()`方法来逐条处理查询集中的对象,这对于非常大的数据集很有帮助:
```python
for post in Post.objects.iterator():
# 处理每篇帖子
```
### 2.2.3 处理数据库中的动态内容
对于动态内容,例如,根据用户请求显示不同的内容,可以使用`Sitemap`类中的`location`方法来动态决定URL。此方法应返回该对象的URL。
例如,根据用户的语言偏好设置,动态生成URL:
```python
def location(self, obj):
return obj.get_absolute_url(lang=self.lang)
```
## 2.3 实践中的数据库交互技巧
### 2.3.1 数据库索引和查询性能提升
数据库索引是提升查询性能的重要手段。Django模型的每个字段默认情况下都不会创建索引。为了优化性能,我们可以为数据库表添加索引:
```python
class Post(models.Model):
...
created_on = models.DateTimeField(db_index=True)
...
```
我们也可以在数据库层面对特定字段创建索引,比如:
```sql
CREATE INDEX idx_title ON app_name_post (title);
```
数据库索引虽然可以提升查询性能,但会增加数据库写操作的成本,因此需要权衡利弊。
### 2.3.2 大数据量下的分页处理
当数据量非常大时,进行全量查询是不现实的。Django ORM提供了分页处理功能,可以有效地分批次处理数据。
```python
from django.core.paginator import Paginator
posts = Post.objects.all()
paginator = Paginator(posts, 10) # 每页10条数据
try:
page = int(request.GET.get('page', '1'))
except ValueError:
page = 1
try:
posts = paginator.page(page)
except (EmptyPage, InvalidPage):
posts = paginator.page(paginator.num_pages)
```
这段代码将数据集分页处理,每个页面只处理10条数据。使用分页可以显著减少单个请求处理的数据量,提升页面加载速度。
在实际应用中,我们可以通过Django的`django-pipeline`来进一步优化分页数据的加载过程。通过异步加载数据,减少用户等待时间,并提升用户体验。
# 3. Django Sitemaps的性能调优
## 3.1 性能调优的理论基础
### 3.1.1 理解性能瓶颈
性能瓶颈是系统中性能最差的环节,限制了整个系统的效率。在Django Sitemaps的应用中,性能瓶颈通常发生在以下几个方面:
- 数据库访问:如果Sitemap需要从数据库中检索大量数据,数据库的I/O操作可能成为瓶颈。
- 数据处理:在生成Sitemap时,对数据的处理(如排序、过滤)可能消耗大量CPU资源。
- 内存使用:Sitemap在处理大量数据时,如果没有有效管理内存,可能会导致内存不足。
- 网络传输:特别是当Sitemap文件非常大时,网络带宽和响应时间成为瓶颈。
理解这些瓶颈对于设计有效的性能调优策略至关重要。性能测试工具可以帮助我们识别系统中的瓶颈。例如,使用Django内置的性能测试工具或第三方工具(如Locust、Apache JMeter等)可以模拟高负载情况下的系统表现,从而发现瓶颈所在。
### 3.1.2 性能测试和监控
性能测试和监控是调优过程中的关键步骤。性能测试旨在衡量系统在特定条件下的表现,而监控则侧重于持续跟踪系统性能指标。
Django的测试框架允许我们编写测试用例来模拟高负载情况。我们可以使用Django的`TestCase`类来模拟请求,并使用`assertNumQueries`来测试数据库查询次数是否符合预期。
监控方面,可以采用以下几种方法:
- 日志分析:在代码中增加日志记录,分析日志可以了解系统运行情况和性能瓶颈。
- 监控工具:例如使用Prometheus和Grafana来实时监控Django应用的性能指标,如响应时间、处理吞吐量等。
- 性能分析器:Python提供了多个性能分析工具,如`cProfile`和`line_profiler`,可以帮助开发者了解程序的运行瓶颈。
## 3.2 Django Sitemaps的性能优化技术
### 3.2.1 内存和CPU资源的优化
当处理大量数据时,优化内存和CPU资源的使用至关重要。以下是一些优化建议:
- 使用生成器:对于大数据量的处理,应该避免一次性加载所有数据到内存中,而是采用生成器逐条处理。
- 精简数据模型:在数据库查询中,只选择需要的字段,减少数据加载的内存占用。
- 使用缓存:对于不经常变化的数据,可以使用缓存来减少数据库的查询次数。
- 异步处理:将耗时的任务放在后台异步处理,避免阻塞主线程。
##

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
欢迎来到 Django Sitemaps 终极指南!本专栏由经验丰富的技术专家撰写,旨在帮助您从入门到精通地掌握 Django Sitemaps。从 Sitemaps 的工作原理到高级生成技巧,再到与 Django 视图和缓存的集成,您将深入了解如何优化网站地图以提升搜索引擎排名。此外,本专栏还涵盖了国际优化、自定义序列化、第三方应用集成、AJAX 内容整合和正确性测试等高级主题。无论您是初学者还是经验丰富的开发人员,本专栏都将为您提供宝贵的见解和实用技巧,帮助您构建完美网站地图,并最大限度地提高您的网站在搜索引擎中的可见性。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【ACC自适应巡航软件功能规范】:揭秘设计理念与实现路径,引领行业新标准

# 摘要
自适应巡航控制(ACC)系统作为先进的驾驶辅助系统之一,其设计理念在于提高行车安全性和驾驶舒适性。本文从ACC系统的概述出发,详细探讨了其设计理念与框架,包括系统的设计目标、原则、创新要点及系统架构。关键技术如传感器融合和算法优化也被着重解析。通过介绍ACC软件的功能模块开发、测试验证和人机交互设计,本文详述了系统的实现
敏捷开发与DevOps的融合之道:软件开发流程的高效实践

# 摘要
敏捷开发与DevOps是现代软件工程中的关键实践,它们推动了从开发到运维的快速迭代和紧密协作。本文深入解析了敏捷开发的核心实践和价值观,探讨了DevOps的实践框架及其在自动化、持续集成和监控等方面的应用。同时,文章还分析了敏捷开发与DevOps的融合策略,包括集成模式、跨功能团队构建和敏捷DevOps文化的培养。通过案例分析,本文提供了实施敏捷DevOps的实用技巧和策略
【汇川ES630P伺服驱动器终极指南】:全面覆盖安装、故障诊断与优化策略
# 摘要
汇川ES630P伺服驱动器是工业自动化领域中先进的伺服驱动产品,它拥有卓越的基本特性和广泛的应用领域。本文从概述ES630P伺服驱动器的基础特性入手,详细介绍了其主要应用行业以及与其他伺服驱动器的对比。进一步,探讨了ES630P伺服驱动
AutoCAD VBA项目实操揭秘:掌握开发流程的10个关键步骤
# 摘要
本文旨在全面介绍AutoCAD VBA的基础知识、开发环境搭建、项目实战构建、编程深入分析以及性能优化与调试。文章首先概述AutoCAD VBA的基本概念和开发环境,然后通过项目实战方式,指导读者如何从零开始构建AutoCAD VBA应用。文章深入探讨了VBA编程的高级技巧,包括对象模型、类模块的应用以及代码优化和错误处理。最后,文章提供了性能优化和调试的方法,并
NYASM最新功能大揭秘:彻底释放你的开发潜力
# 摘要
NYASM是一个功能强大的汇编语言工具,支持多种高级编程特性并具备良好的模块化编程支持。本文首先对NYASM的安装配置进行了概述,并介绍了其基础与进阶语法。接着,本文探讨了NYASM在系统编程、嵌入式开发以及安全领域的多种应用场景。文章还分享了NYASM的高级编程技巧、性能调优方法以及最佳实践,并对调试和测试进行了深入讨论。最后,本文展望了NYASM的未来发展方向,强调了其与现代技
ICCAP高级分析:挖掘IC深层特性的专家指南
# 摘要
本文全面介绍了ICCAP的理论基础、实践应用及高级分析技巧,并对其未来发展趋势进行了展望。首先,文章介绍了ICCAP的基本概念和基础知识,随后深入探讨了ICCAP软件的架构、运行机制以及IC模型的建立和分析方法。在实践应用章节,本文详细阐述了ICCAP在IC参数提取和设计优化中的具体应用,包括方法步骤和案例分析。此外,还介绍了ICCAP的脚本编程技巧和故障诊断排除方法。最后,文章预测了ICCAP在物联网和人工智能
【Minitab单因子方差分析】:零基础到专家的进阶路径
# 摘要
本文详细介绍了Minitab单因子方差分析的各个方面。第一章概览了单因子方差分析的基本概念和用途。第二章深入探讨了理论基础,包括方差分析的原理、数学模型、假设检验以及单因子方差分析的类型和特点。第三章则转向实践操作,涵盖了Minitab界面介绍、数据分析步骤、结果解读和报告输出。第四章讨论了高级应用,如多重比较、方差齐性检验及案例研究。第五章关注在应用单因子方差分析时可能
FTTR部署实战:LinkHome APP用户场景优化的终极指南
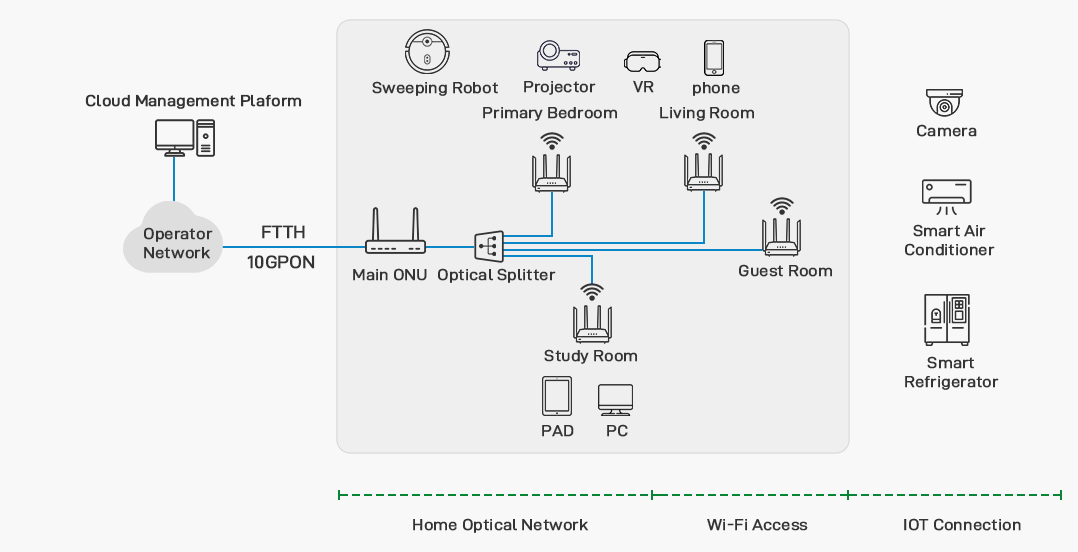
# 摘要
本论文首先介绍了FTTR(Fiber To The Room)技术的基本概念及其背景,以及LinkHome APP的概况和功能。随后详细阐述了在FTTR部署前需要进行的准备工作,包括评估网络环境与硬件需求、分析LinkHome APP的功能适配性,以及进行预部署测试与问题排查。重点介绍了FTTR与LinkHome APP集成的实践,涵盖了用户场景配置、网络环境部署实施,以及网络性能监
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )