【Python终极指南】:__main__模块的10大妙用与实践案例
发布时间: 2024-10-10 04:43:16 阅读量: 130 订阅数: 23 

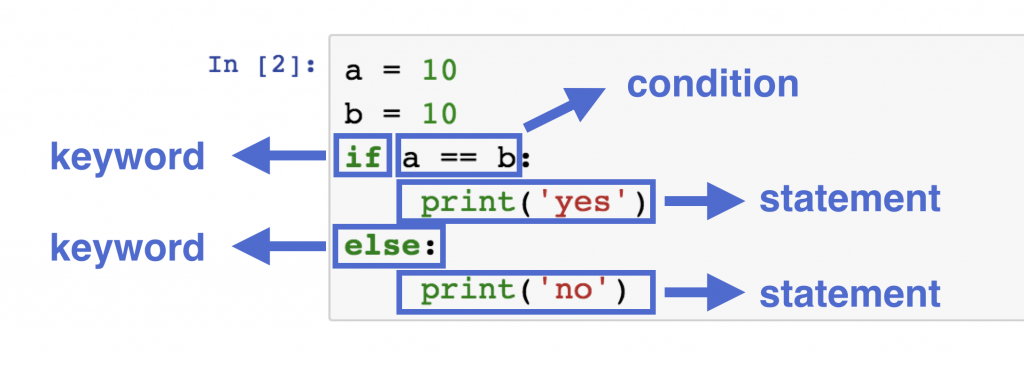
Python中if __name__ == '__main__'作用解析
# 1. Python __main__模块简介
Python作为一门解释型的高级编程语言,提供了一个名为`__main__`的模块,它允许程序员对代码的执行进行更精细的控制。`__main__`模块在Python中起到了一个特殊的角色,它用作程序启动的入口点。在命令行中直接运行Python脚本时,Python会自动将该脚本作为`__main__`模块来执行。
```python
# 示例代码:基本的__main__使用方式
if __name__ == "__main__":
print("此代码块仅在直接运行脚本时执行")
```
在上面的示例中,`if __name__ == "__main__":`这样的条件判断语句非常常见,它用于检测当前模块是否作为主程序运行,而非被其他模块导入。这不仅有助于组织代码结构,还可以提高代码的可复用性与可维护性。在了解`__main__`模块的工作原理和它在不同环境下的行为之后,开发者可以利用它来执行模块级别的代码封装、命令行参数解析以及创建交互式命令行工具等等。
# 2. 理解__main__模块的工作原理
### 2.1 __main__模块的作用与特性
#### 2.1.1 模块的导入与执行机制
在Python中,每个`.py`文件都可以被视为一个模块。当一个模块被导入到另一个模块中时,解释器会执行该模块内的顶层代码。但有时我们需要区分是直接运行脚本还是被其他模块导入。这就是`__main__`模块发挥作用的地方。
`__main__`模块的特殊之处在于它代表的是当前运行的主程序。如果一个模块被当作脚本直接运行,`__name__`变量会被设置为`"__main__"`。这允许开发者编写可在导入时正常执行的模块,同时提供一个入口点用于当模块被直接运行时执行特定的代码。
**示例代码:**
```python
# my_module.py
def some_function():
print("Function inside my_module")
if __name__ == "__main__":
print("Directly running the module")
some_function()
```
**执行逻辑:**
- 当`my_module.py`被直接运行时,`__name__`变量的值为`"__main__"`,所以会执行`if __name__ == "__main__":`块内的代码,输出`"Directly running the module"`和函数调用结果。
- 当`my_module.py`被导入至另一个模块时,`__name__`的值将不再是`"__main__"`,因此`if __name__ == "__main__":`内的代码不会执行,`some_function()`只有在导入模块中显式调用时才会运行。
#### 2.1.2 __name__变量与模块身份标识
`__name__`是一个内置变量,当一个Python文件被导入到其他文件中时,`__name__`将自动被设置为模块名。例如,如果`moduleA.py`导入了`moduleB.py`,那么在`moduleB.py`中,`__name__`的值将会是`"moduleB"`。
当Python文件被直接执行时,`__name__`的值会自动被设置为`"__main__"`。利用这一特性,可以编写一个模块,在导入时提供功能,在直接执行时提供测试或示例代码。
**示例代码:**
```python
# moduleB.py
def print_module_name():
print(f"The module's name is {__name__}")
if __name__ == "__main__":
print("This module is being run directly")
else:
print("This module is being imported into another module")
```
**代码逻辑分析:**
- 如果`moduleB.py`被直接运行,`if __name__ == "__main__":`块内的代码执行,输出`"This module is being run directly"`。
- 如果`moduleB.py`被导入,`__name__`将被设置为模块名`"moduleB"`,`else`块内的代码执行,输出`"This module is being imported into another module"`。
### 2.2 __main__模块在不同环境下的行为
#### 2.2.1 直接运行脚本时的执行流
在直接运行Python脚本时,Python解释器将执行脚本文件中的所有顶级语句。此时,`__name__`变量的值为`"__main__"`。这是`__main__`模块最为直接和常见的用途。
**示例代码:**
```python
# main_script.py
print("Top-level code in main_script.py")
def main():
print("This is the main entry point of the script")
if __name__ == "__main__":
main()
```
**代码逻辑分析:**
- 当`main_script.py`被直接运行时,输出首先显示`"Top-level code in main_script.py"`。
- 然后,解释器会找到`if __name__ == "__main__":`块并执行其中的`main()`函数,输出`"This is the main entry point of the script"`。
#### 2.2.2 导入作为模块时的处理
当一个Python脚本被另一个脚本作为模块导入时,所有的顶级语句将被执行,但是`if __name__ == "__main__":`块内的代码则不会执行。这允许模块在导入时提供方法和类,但只有在作为主程序运行时才执行特定的逻辑。
**示例代码:**
```python
# helper_module.py
def helper_function():
print("Helper function inside helper_module")
if __name__ == "__main__":
print("This block is executed only when running the module directly")
# main_script.py
from helper_module import helper_function
helper_function()
```
**代码逻辑分析:**
- 即使`helper_module.py`包含`if __name__ == "__main__":`块,当它被`main_script.py`导入时,该块不会被执行。
- `helper_function()`可以在导入模块`helper_module`的任何脚本中被调用,无论`helper_module.py`是否被直接运行。
#### 2.2.3 脚本作为包的一部分时的行为
在更复杂的项目中,Python文件可以被组织成一个包。在这种情况下,直接运行脚本的行为可能有所不同。特别是如果脚本位于包的子目录中,Python解释器可能无法正确识别脚本作为可运行的主程序。
**示例代码:**
```python
# package/__main__.py
print("This is a package __main__ module")
# package/script.py
import package
def my_function():
print("Executing function from script.py")
```
**代码逻辑分析:**
- 直接运行`python package/__main__.py`会执行`__main__.py`文件内的代码,输出`"This is a package __main__ module"`。
- 如果尝试直接运行`python package/script.py`,输出将显示`"Executing function from script.py"`,因为`__main__.py`位于包的子目录中。
### 2.3 深入探讨__main__与作用域的关系
#### 2.3.1 全局作用域与局部作用域的区别
在Python中,作用域定义了变量的可见性。`__main__`模块允许我们区分全局变量和局部变量。全局变量在整个模块内都是可见的,而局部变量则只在定义它们的函数或代码块内可见。
**示例代码:**
```python
# scope_module.py
global_var = "I am a global variable"
def function_with_local_scope():
local_var = "I am a local variable"
print(global_var)
print(local_var)
function_with_local_scope()
print(local_var)
```
**代码逻辑分析:**
- `global_var`作为全局变量,可以在模块的任何地方访问。
- `local_var`作为局部变量,仅在其定义的函数`function_with_local_scope`内部可见。
- 当尝试打印`local_var`时,会抛出`NameError`,因为`local_var`不在当前作用域内。
#### 2.3.2 __main__中变量的作用域层级
当模块被直接运行时,变量定义在`__main__`中,它们具有模块级别的作用域。当模块被导入时,这些变量也会在导入模块的作用域内可用。
**示例代码:**
```python
# scope_main.py
if __name__ == "__main__":
main_var = "I am a variable defined in __main__"
def function():
print(main_var)
function()
```
**代码逻辑分析:**
- 当`scope_main.py`被直接运行时,`main_var`变量在`__main__`作用域内定义,能够被函数`function()`访问。
- 如果`scope_main.py`被导入到另一个模块,`main_var`同样可以被访问,因为它已经是模块变量的一部分。
通过理解`__main__`模块的工作原理和其与Python作用域的关系,可以更好地控制代码的执行路径和变量的可见性。这不仅能够帮助你创建更为结构化的程序,还能使得代码更加健壮和可维护。下一章节,我们将深入探讨`__main__`模块的多个实用案例。
# 3. __main__模块的10大妙用
## 3.1 模块级别的代码封装与执行
### 3.1.1 封装测试代码
在软件开发中,编写可测试的代码是保证产品质量的关键步骤。Python的`unittest`框架提供了一个丰富的测试库,但有时候你可能需要一个更快速、更直接的方式来测试你的代码片段。在这种情况下,`__main__`模块可以成为你的得力助手。
假设我们有一个简单的函数`add`,我们需要快速测试它:
```python
def add(a, b):
return a + b
if __name__ == '__main__':
# 测试代码
print(add(3, 4)) # 输出 7
```
在这个例子中,我们定义了一个函数`add`,并在`__main__`块中直接测试了这个函数。这样做可以方便我们在开发过程中快速验证代码逻辑是否正确。
### 3.1.2 创建可复用的脚本入口
很多开发者都喜欢将常用的代码封装成脚本文件,以便在命令行中直接调用。在这种情况下,`__main__`模块可以帮助我们创建可复用的脚本入口点。
例如,我们有一个`utils.py`脚本,提供了多种工具函数:
```python
def print_message(message):
print(message)
def reverse_string(s):
return s[::-1]
if __name__ == '__main__':
# 为用户提供可执行选项
import sys
if sys.argv[1] == 'reverse':
print(reverse_string(sys.argv[2]))
elif sys.argv[1] == 'print':
print_message(sys.argv[2])
```
上述代码演示了如何在`__main__`模块中根据命令行参数执行不同的函数。这样的设计使得脚本可执行且具有了更好的灵活性和可用性。
## 3.2 命令行参数的解析与使用
### 3.2.1 使用argparse处理命令行参数
当编写需要从命令行接收参数的脚本时,Python的`argparse`模块是一个非常强大的工具。通过在`__main__`模块中使用`argparse`,我们可以构建清晰的命令行接口。
例如,我们创建一个脚本`script.py`,它可以接收用户输入并打印出来:
```python
import argparse
def main():
parser = argparse.ArgumentParser(description="Print user input")
parser.add_argument('message', type=str, help='The message to print')
args = parser.parse_args()
print(args.message)
if __name__ == '__main__':
main()
```
使用这个脚本,用户可以通过命令行输入一个消息并将其打印出来,如`python script.py Hello World`。
### 3.2.2 结合__main__动态设置参数
有时,我们希望在运行脚本时能够动态地设置某些参数。`__main__`模块允许我们在执行时定义参数,从而提供更大的灵活性。
```python
# main.py
import sys
def main(default_message):
user_message = sys.argv[1] if len(sys.argv) > 1 else default_message
print(user_message)
if __name__ == '__main__':
import argparse
parser = argparse.ArgumentParser()
parser.add_argument('--message', default='Hello World', help='message to be printed')
args = parser.parse_args()
main(args.message)
```
在这个例子中,我们通过`argparse`允许用户通过`--message`选项自定义消息。如果用户未指定,脚本将使用默认值。
## 3.3 开发可交互式命令行工具
### 3.3.1 创建交互式命令行接口
有时我们需要更复杂的交互式命令行工具。我们可以利用`__main__`模块结合`readline`或`cmd`模块来实现。
```python
import cmd
class InteractiveShell(cmd.Cmd):
prompt = '(shell) '
def do_greet(self, arg):
print(f"Hello, {arg}!")
def do_exit(self, arg):
print("Exiting shell...")
return True
if __name__ == '__main__':
InteractiveShell().cmdloop()
```
上面的代码创建了一个简单的交互式shell,用户可以输入`greet [name]`来得到问候,或者输入`exit`来退出程序。
### 3.3.2 实现简单但强大的命令行应用
下面,我们展示如何创建一个功能较为丰富的命令行应用,它集成了前面提到的参数解析和交互式命令行。
```python
import argparse
import sys
import cmd
class CustomShell(cmd.Cmd):
prompt = '(myapp) '
def do_greet(self, arg):
"""Greet the user with a message."""
_, name = arg.split(maxsplit=1)
print(f"Hello, {name}! Welcome to MyApp.")
def do_exit(self, arg):
"""Exit the shell."""
return True
def main():
parser = argparse.ArgumentParser(description="MyApp command line interface")
parser.add_argument('--name', default='User', help='Name to greet')
args = parser.parse_args()
shell = CustomShell()
shell.prompt = f'({args.name}) '
shell.cmdloop()
if __name__ == '__main__':
main()
```
当运行此脚本时,用户可以通过命令行参数指定名字,或者在交互式shell中指定名字,程序将相应地进行问候。
这个命令行工具示例展示了`__main__`模块的灵活性和功能,可帮助开发者构建复杂的用户交互系统。
# 4. __main__模块实践案例
## 4.1 构建自动化脚本与任务
### 4.1.1 定时任务的Python实现
Python的`schedule`库可以用来安排定时任务,其使用简单,灵活性高。在构建定时任务时,我们可以将任务逻辑放在`__main__`模块中,以确保当Python脚本作为主程序运行时,定时任务可以自动启动。
```python
import schedule
import time
def job():
print("I'm working...")
# 定义定时任务,每10秒执行一次
schedule.every(10).seconds.do(job)
while True:
schedule.run_pending()
time.sleep(1)
```
在上述代码中,`job`函数代表一个要定时执行的任务。使用`schedule.every(10).seconds.do(job)`来设置定时任务,表示每10秒执行一次`job`函数。
### 4.1.2 使用__main__模块管理自动化流程
自动化流程往往需要在特定条件下运行,利用`__main__`模块可以简化流程的管理。下面是一个使用`__main__`模块在脚本作为主程序执行时运行定时任务的例子。
```python
import schedule
import time
def job():
print("I'm working...")
def main():
# 定义定时任务
schedule.every(10).seconds.do(job)
print("Press Ctrl+C to exit")
# 运行定时任务
while True:
schedule.run_pending()
time.sleep(1)
# 仅当脚本直接运行时,执行main函数
if __name__ == '__main__':
main()
```
在这里,我们定义了`main`函数来封装所有与定时任务相关的逻辑。当Python文件被直接运行时,`__name__`的值将是`"__main__"`,此时`main`函数会被调用。如果文件是作为模块被其他文件导入,`__name__`的值将不会是`"__main__"`,`main`函数将不会执行。
## 4.2 构建模块化的应用程序
### 4.2.1 设计模块化的程序结构
模块化是一种设计模式,将程序分解为独立的、可替换的部分。这通常涉及定义清晰的接口,并确保组件之间的依赖关系最小化。以下是一个模块化设计的基本结构:
```python
# module_a.py
def module_a_function():
print("Module A function is called")
# module_b.py
def module_b_function():
print("Module B function is called")
```
在使用`__main__`模块来组装模块化程序时,我们可以在主程序文件中导入所需的模块,并在合适的时机调用其功能。
```python
# main.py
import module_a
import module_b
def main_program():
module_a.module_a_function()
module_b.module_b_function()
if __name__ == '__main__':
main_program()
```
### 4.2.2 在__main__中组装模块
将模块组合到`__main__`中是创建一个可运行的程序的一个关键步骤。在此步骤中,我们将定义如何使用模块提供的功能来实现程序的整体逻辑。
```python
# main.py
import module_a
import module_b
def main_program():
# 调用module_a中的函数
module_a.module_a_function()
# 调用module_b中的函数
module_b.module_b_function()
def command_line_interface():
print("Welcome to the CLI")
main_program()
if __name__ == '__main__':
command_line_interface()
```
在上面的例子中,我们添加了一个命令行接口函数`command_line_interface`,当直接运行`main.py`时,它将提供用户界面来执行主程序。这种方法使得程序更加模块化,更容易维护和扩展。
## 4.3 创建可执行的Python包
### 4.3.1 利用__main__构建独立可执行包
创建独立可执行的Python包,通常需要使用`setuptools`。利用`__main__`模块可以定义包的入口点,使得包可以直接被调用或作为可执行文件运行。
```python
# setup.py
from setuptools import setup, find_packages
setup(
name='example_package',
version='0.1',
packages=find_packages(),
entry_points={
'console_scripts': [
'exampleCLI = package.module:main',
],
},
)
```
在这个`setup.py`配置文件中,我们定义了一个名为`exampleCLI`的命令行脚本入口点,它在安装该包后可以直接通过命令行运行。
### 4.3.2 分发和部署程序的最佳实践
一旦有了可执行的包,就可以将其分发给其他用户,而最佳实践包括清晰的文档、版本控制、持续集成和自动测试。以下是一些关于如何进行这些最佳实践的说明。
- **文档**:确保你的程序包含清晰的README文件,说明如何安装和使用程序。
- **版本控制**:使用如Git等版本控制系统来追踪代码变更,并为重要的版本打上标签。
- **持续集成(CI)**:通过诸如GitHub Actions、Travis CI或GitLab CI/CD的工具自动化测试和部署过程。
- **自动测试**:编写单元测试和集成测试,以确保程序在部署后能够正常工作。
下面是一个简单的文档示例,通常包括在`README.md`文件中:
```markdown
# Example Package
## Installation
To install the Example Package, run the following command:
```bash
pip install example-package
```
## Usage
After installation, you can run the package's CLI by typing:
```bash
exampleCLI
```
## Development
To contribute to this package, please follow the instructions in the [Contributing Guide](***
```
这些最佳实践将帮助确保你的Python项目是可维护的,易于部署和扩展。
# 5. __main__模块的高级应用与调试
## 5.1 使用__main__模块进行单元测试
### 5.1.1 测试模块的入口点
在编写单元测试时,我们通常会使用Python的unittest或pytest框架。通过使用__main__模块,我们可以在不改变测试代码结构的前提下,灵活地控制测试的入口点。这样做可以让我们在需要时快速切换到命令行执行测试,或在开发过程中从IDE中运行测试,而无需修改测试代码结构。
为了将测试模块设计为可以通过__main__执行,我们首先需要编写测试用例,然后在模块的末尾添加入口点代码。以下是使用unittest框架进行的一个简单示例:
```python
# test_main.py
import unittest
class TestMainModule(unittest.TestCase):
def test_some_functionality(self):
# 测试一些功能
self.assertEqual(some_functionality(), expected_result)
if __name__ == '__main__':
unittest.main()
```
在上面的代码中,我们定义了一个`TestMainModule`类,其中包含一个测试方法`test_some_functionality`。在模块的底部,我们检查`__name__`变量是否等于`'__main__'`,如果是,则调用`unittest.main()`函数来运行测试。这样,我们既可以作为脚本运行测试,也可以导入模块到其他测试套件中。
### 5.1.2 从__main__触发测试用例
从__main__触发测试用例的好处是,它允许我们通过命令行参数自定义测试行为。例如,我们可以使用`-v`参数来增加测试的详细程度。这里是如何实现这一点的:
```python
import unittest
import sys
def main(test_cases, verbosity=1):
if verbosity == 1:
runner = unittest.TextTestRunner()
else:
runner = unittest.TextTestRunner(verbosity=verbosity)
suite = unittest.TestSuite(test_cases)
runner.run(suite)
if __name__ == '__main__':
# 自定义测试用例
test_cases = [TestMainModule]
if len(sys.argv) > 1 and sys.argv[1] == '-v':
main(test_cases, verbosity=2)
else:
main(test_cases)
```
在上述代码中,我们定义了一个`main`函数,它接受一个测试用例列表和一个可选的详细程度参数。从__main__触发时,如果命令行提供了`'-v'`参数,则执行更详细的测试报告输出。
## 5.2 调试与优化__main__模块
### 5.2.1 常见问题诊断
使用__main__模块时,开发者可能遇到几个常见问题。例如,在模块作为脚本运行时,可能会意外地执行了不应该在命令行运行的部分代码。为了诊断这些问题,我们可以使用Python的`trace`模块来追踪代码的执行路径,或者使用`pdb`模块进行交互式调试。
下面是一个使用`trace`模块追踪执行路径的示例:
```python
import trace
def main():
# 执行一些操作
...
if __name__ == '__main__':
tracer = trace.Trace(
ignoredirs=[sys.prefix, sys.exec_prefix],
ignoremods=[
"trace",
"sys",
"encodings",
"_bootstrap"
],
trace=1
)
tracer.runfunc(main)
```
这个`main`函数将追踪并打印出所有被访问过的文件,帮助开发者识别出在作为脚本执行时不应该被执行的部分。
### 5.2.2 性能调优技巧
在处理性能优化时,针对__main__模块,我们可以应用多种策略。例如,我们可以使用`cProfile`模块来分析运行时的性能瓶颈,或者对__main__中的关键部分进行缓存优化。
下面是使用`cProfile`对__main__模块进行性能分析的示例:
```python
import cProfile
import pstats
def main():
# 执行一些操作
...
if __name__ == '__main__':
profiler = cProfile.Profile()
profiler.runcall(main)
stats = pstats.Stats(profiler).sort_stats('cumulative')
stats.print_stats(10) # 打印消耗时间最多的前10个函数
```
在这个例子中,我们使用`cProfile.Profile()`来创建一个性能分析器实例,然后通过`runcall`方法对`main`函数进行分析。性能分析完成后,我们使用`pstats.Stats`将数据打印出来,以便于我们识别出性能瓶颈所在。
这样,通过诊断与性能分析,开发者可以有针对性地调整代码逻辑,提升__main__模块的运行效率,确保应用在各种环境下的表现都是最优的。
# 6. 总结与展望
## 6.1 __main__模块的最佳实践总结
在IT行业,尤其是在Python编程中,__main__模块扮演着至关重要的角色。对于有经验的程序员来说,了解如何利用__main__模块来增强代码的灵活性和模块化是核心实践之一。在本节中,我们将深入探讨__main__模块使用的核心原则与设计模式以及代码组织和维护策略。
### 6.1.1 核心原则与设计模式
__main__模块的核心原则之一就是封装与抽象。通过将代码逻辑置于__main__中,我们可以轻松控制脚本的执行流程,提高代码的复用性。此外,设计模式如单例模式和工厂模式也可以与__main__模块结合使用,以便在脚本和模块中管理资源和实例。
```python
# 示例代码:单例模式实现
class Singleton:
_instance = None
def __new__(cls, *args, **kwargs):
if cls._instance is None:
cls._instance = super(Singleton, cls).__new__(cls, *args, **kwargs)
return cls._instance
def main():
singleton_instance = Singleton()
# 使用singleton_instance进行相关操作
if __name__ == '__main__':
main()
```
在此代码示例中,`Singleton`类确保在任何时候只有一个实例被创建。`main()`函数是程序的入口点,负责创建和使用`Singleton`的实例。
### 6.1.2 代码组织与维护策略
组织和维护代码的策略之一是模块化。将程序划分为多个模块,并在__main__模块中合理地导入和使用这些模块,可以帮助我们维护和更新代码库。此外,版本控制工具如Git也应当在代码维护中占据一席之地,它们能够帮助开发者跟踪代码变更,管理不同的开发分支,并进行有效的代码合并。
## 6.2 对未来Python编程模式的展望
随着Python语言的不断发展,__main__模块在未来编程模式中的地位可能会有所变化。新的Python特性,如异步编程、类型提示和元编程,都可能对__main__模块的应用产生影响。同时,社区对于__main__模块的创新和贡献也在不断推动其进步。
### 6.2.1 新兴的Python特性对__main__的影响
Python的异步编程模型,尤其是`asyncio`模块,可以与__main__模块结合使用,来实现高效的异步执行脚本。此外,类型提示(Type Hints)可以帮助开发者在编写__main__模块时更好地理解和维护代码逻辑。
```python
# 示例代码:使用asyncio与__main__结合
import asyncio
async def main():
# 这里放置异步执行的代码
print("Hello, asyncio!")
if __name__ == '__main__':
asyncio.run(main())
```
在这个示例中,我们定义了一个异步函数`main()`,它可以在支持异步的环境中运行,例如在一个异步事件循环中。
### 6.2.2 社区对__main__模块的贡献与创新
社区对于__main__模块的贡献和创新也是不可忽视的力量。开源项目的贡献者们不断提出新的使用案例、优化技巧和最佳实践,这些都极大地丰富了__main__模块的应用范畴。
通过本章的分析,我们对__main__模块有了更深入的理解,并展望了其未来的发展。我们相信,__main__模块将继续在Python编程中发挥重要的作用,而社区的创新将会不断推动其进步。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
欢迎来到 Python 库文件学习专栏!本专栏将深入探讨 Python 中至关重要的 __main__ 模块,揭示其强大功能和最佳实践。从入门到精通,您将掌握 __main__ 模块的 10 大妙用、代码灵活和性能优化技巧、调试和性能调优方法、模块化设计和代码复用策略、文档编写和维护指南、并行和异步编程秘籍。通过深入了解 __main__ 模块,您将打造出完美无瑕的代码入口,提升库文件的性能和灵活性,并轻松驾驭不同环境和应用场景。
专栏目录

文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
虚拟串口驱动7.2升级指南:旧版本迁移必看最佳实践

# 摘要
本文针对虚拟串口驱动7.2版本进行全面概述,重点介绍了该版本的新特性和改进,包括核心性能的提升、用户界面的优化以及兼容性和安全性的增强。文中详细阐述了驱动的安装、部署、迁移实践以及应用案例分析,并提供了针对常见问题的技术支持与解决方案。通过实际应用案例展示了新版驱动在不同场景下的迁移策略和问题解决方法,旨在帮助用户更高效地完成驱动升级,确保系统的稳定运行和
数学爱好者必备:小波变换的数学基础与尺度函数深度解析
# 摘要
小波变换作为一种强大的数学工具,在信号处理、图像分析、数据分析等多个领域得到了广泛应用。本文首先介绍小波变换的基本概念和数学理论基础,包括线性代数、傅里
【Surpac脚本高级技巧】:自动化地质数据处理,提升工作效率的黄金法则
# 摘要
本文旨在全面介绍Surpac脚本的基础知识、核心语法、应用实践以及高级技巧。通过对Surpac脚本基础命令、内置函数、数据结构、逻辑控制等方面的深入解析,揭示其在地质数据处理、矿体建模、资源估算等领域的实际应用。文章还着重探讨了脚本编写中的交互性、三维空间分析可视化、模块化复用等高级技术,以及
虚拟局域网(VLAN)深度剖析:网络架构的核心技术
# 摘要
本文全面探讨了虚拟局域网(VLAN)的技术原理、网络架构设计、实践应用案例,以及未来发展展望。首先,概述了VLAN的定义、作用及其工作原理,包括标签协议的标准和配置方法。随后,深入分析了VLAN在不同网络架构设计中的应用,包括设计模型、策略以及安全设计。文章还通过具体案例,展示了VLAN在企业网络和数据中心的应用,以及如何进行故障排查和性能优
射流管式伺服阀设计与应用从零开始
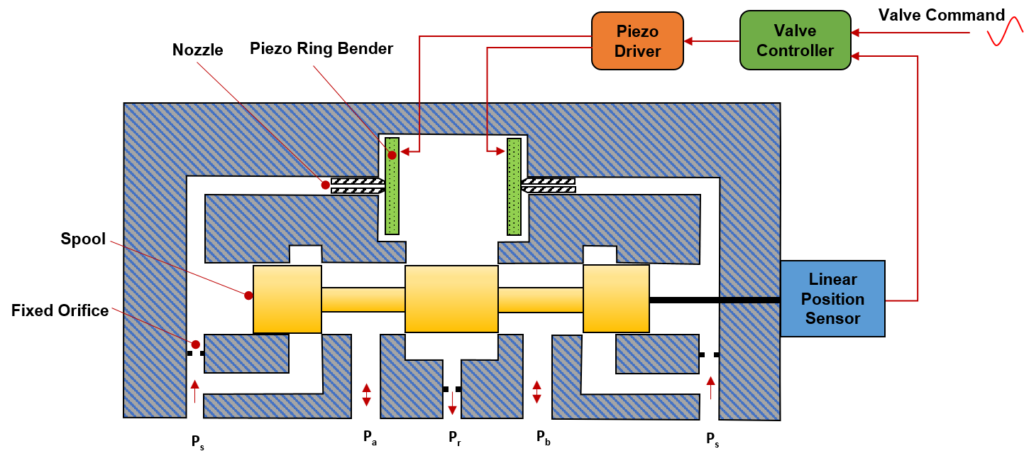
# 摘要
射流管式伺服阀是一种精密的流体控制设备,广泛应用于工业自动化及特种设备领域。本文从理论基础、设计流程、制造与测试以及应用案例等方面对射流管式伺服阀进行了全面介绍。文章首先阐述了伺服阀的流体力学原理和伺服控制理论,然后详细介绍了设计过程中的关键步骤,包括设计参数的确定、射流管的结构优化、材料选择及其对性能的影响。在制造与测试环节,文章探讨了制造工艺、性能测试方法以及
【混沌信号发生器优化】:提升调校效果与性能的终极策略
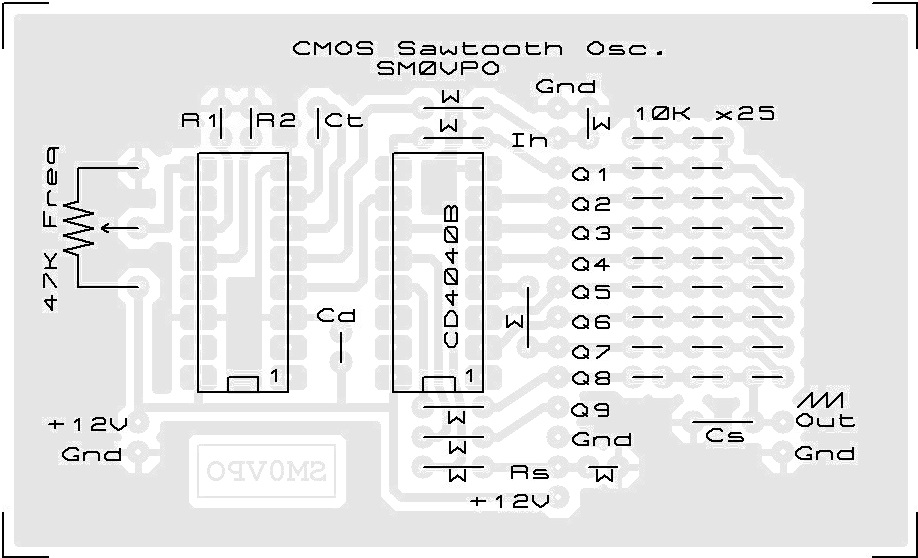
# 摘要
混沌信号发生器作为一种创新技术,在信号处理和通信系统中显示出巨大潜力。本文首先概述混沌信号发生器的概念及其理论基础,深入探讨了混沌现象的定义、混沌系统的模型以及混沌信号的关键参数。随后,文章详细阐述了混沌信号发生器的设计与实现方法,包括硬件和软件的设计要点,并通过实际构建和性能测试来验证其有效性。在混沌信号发生器的优化策略章节中,提出了提升信号质量和增强性能的具体方法。最后,本
【自动化操作录制】:易语言键盘鼠标操作基础教程全解析

# 摘要
随着软件自动化需求的增长,自动化操作录制技术得到了广泛应用。本文首先介绍了自动化操作录制的基本概念,并详细探讨了易语言的环境搭建、基本语法和控制语句。接着,本文深入分析了如何实现键盘和鼠标操作的自动化录制与模拟,并阐述了高级自动化控制技巧,如图像识别与像素操作。进阶章节则针对自动化脚本的调试优化、任务调度以及复杂场景下的应用进行了探讨。最后,通过具体的易语言自动化操作
ROS初探:揭开“鱼香肉丝”包的神秘面纱

# 摘要
本文全面介绍了机器人操作系统(ROS)的基本概念、安装配置、通信机制,以及通过一个实践项目来加深理解。首先,文章简要介绍了ROS的背景和核心概念,为读者提供了对ROS的初步认识。接着,详细阐述了ROS的安装与配置过程,包括必要的系统要求、安装步骤和环境配置测试。第三章深入探讨了ROS节点和话题通信机制,包括节点的生命周期、创建与管理,以及话题发布和订阅的实现。第
GSM信令流程全面解析:网络通信脉络一览无余

# 摘要
GSM网络作为第二代移动通信技术的代表,其信令流程对于网络通信的稳定性和效率至关重要。本文首先介绍了GSM网络通信的基础知识和信令流程的理论基础,然后深入探讨了呼叫控制流程的具体实践和数据传输的信令机制,以及短消息服务(SMS)和移动性管理的信令细节。在信令安全和优化方面,本文阐述了信令加密与认证机制,以及针对信令风暴的控制策略和信令容量管理。最后,本文通过信令分析工具的介绍和应用实例分析,展示了如何在实
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )