OpenMV如何实现实时多条形码识别
发布时间: 2024-03-28 13:21:53 阅读量: 53 订阅数: 73 

基于OpenCV的多种条形码识别算法实现
# 1. 简介
OpenMV是一款基于MicroPython的开源嵌入式视觉处理平台,旨在提供快速、简便的视觉处理解决方案。在物联网领域,OpenMV能够广泛应用于智能家居、智能监控、智能农业等场景中,为设备赋予视觉感知能力,实现智能化、自动化控制。
条形码识别在物联网应用中扮演着重要的角色。通过对产品包装、设备标识等物品进行条形码识别,物联网设备能够实现自动识别产品信息、快速定位设备位置等功能,提高工作效率和数据准确性。因此,实现实时多条形码识别对于物联网设备的发展具有重要意义。
# 2. OpenMV基础知识
OpenMV是一款基于MicroPython的开源嵌入式视觉处理平台,旨在为用户提供简单易用的视觉处理功能。在物联网领域,OpenMV可以广泛应用于智能监控、智能家居、智能农业等领域,以实现物体识别、跟踪、计数等功能。其中,条形码的识别在物联网应用中占据重要地位,可以实现产品溯源、库存管理、支付扫码等功能。
### OpenMV硬件介绍
OpenMV主要由处理器、图像传感器和各种接口组成。常用的OpenMV模块包括OpenMV Cam H7和OpenMV Cam M7,其中H7性能更强大,适合处理复杂的视觉任务。
### OpenMV支持的条形码识别算法概览
OpenMV内置了针对条形码识别的算法库,支持常见的一维码(Code 39、Code 128等)和二维码(QR Code、Data Matrix等)的识别。通过调用相关库函数,可以轻松实现对条形码的识别功能。
在接下来的章节中,我们将探讨如何在OpenMV上实现实时多条形码识别,为物联网应用提供更多可能性。
# 3. 单条形码识别实现
在这一节中,我们将详细介绍如何使用OpenMV进行单条形码识别,并提供相应的代码示例。
#### 使用OpenMV进行单条形码识别的步骤和流程
1. 初始化摄像头:
```python
import sensor, image, time
sensor.reset()
sensor.set_pixformat(sensor.RGB565)
sensor.set_framesize(sensor.QVGA)
sensor.skip_frames(time = 2000
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入探讨OpenMV硬件平台的条形码识别能力,并展示相应的代码实现。从OpenMV入门指南开始,逐步介绍安装配置、基础编程、图像采集处理等基础知识,帮助读者全面了解OpenMV的功能和应用。进而深入探讨条形码识别原理,介绍图像处理技术和常用算法,并逐步展开进阶教程,包括人工智能与深度学习的简要介绍以及其在条形码识别中的应用。同时探讨OpenMV在实时图像处理、多条形码识别、物体检测、物联网和云计算等领域的应用,为读者提供全面的知识体系和实践案例,助力他们在OpenMV平台上开展更丰富的应用和项目实践。
专栏目录

文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【51单片机矩阵键盘扫描终极指南】:全面解析编程技巧及优化策略

# 摘要
本论文主要探讨了基于51单片机的矩阵键盘扫描技术,包括其工作原理、编程技巧、性能优化及高级应用案例。首先介绍了矩阵键盘的硬件接口、信号特性以及单片机的选择与配置。接着深入分析了不同的扫
【Pycharm源镜像优化】:提升下载速度的3大技巧

# 摘要
Pycharm作为一款流行的Python集成开发环境,其源镜像配置对开发效率和软件性能至关重要。本文旨在介绍Pycharm源镜像的重要性,探讨选择和评估源镜像的理论基础,并提供实践技巧以优化Pycharm的源镜像设置。文章详细阐述了Pycharm的更新机制、源镜像的工作原理、性能评估方法,并提出了配置官方源、利用第三方源镜像、缓存与持久化设置等优化技巧。进一步,文章探索了多源镜像组
【VTK动画与交互式开发】:提升用户体验的实用技巧
# 摘要
本文旨在介绍VTK(Visualization Toolkit)动画与交互式开发的核心概念、实践技巧以及在不同领域的应用。通过详细介绍VTK动画制作的基础理论,包括渲染管线、动画基础和交互机制等,本文阐述了如何实现动画效果、增强用户交互,并对性能进行优化和调试。此外,文章深入探讨了VTK交互式应用的高级开发,涵盖了高级交互技术和实用的动画
【转换器应用秘典】:RS232_RS485_RS422转换器的应用指南
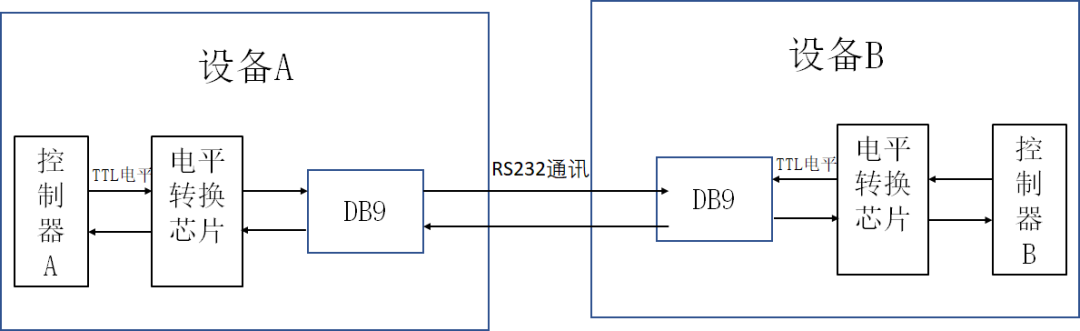
# 摘要
本论文全面概述了RS232、RS485、RS422转换器的原理、特性及应用场景,并深入探讨了其在不同领域中的应用和配置方法。文中不仅详细介绍了转换器的理论基础,包括串行通信协议的基本概念、标准详解以及转换器的物理和电气特性,还提供了转换器安装、配置、故障排除及维护的实践指南。通过分析多个实际应用案例,论文展示了转
【Strip控件多语言实现】:Visual C#中的国际化与本地化(语言处理高手)

# 摘要
本文全面探讨了Visual C#环境下应用程序的国际化与本地化实施策略。首先介绍了国际化基础和本地化流程,包括本地化与国际化的关系以及基本步骤。接着,详细阐述了资源文件的创建与管理,以及字符串本地化的技巧。第三章专注于Strip控件的多语言实现,涵盖实现策略、高级实践和案例研究。文章第四章则讨论了多语言应用程序的最佳实践和性能优化措施。最后,第五章通过具体案例分析,总结了国际化与本地化的核心概念,并展望了未来的技术趋势。
# 关
C++高级话题:处理ASCII文件时的异常处理完全指南
# 摘要
本文旨在探讨异常处理在C++编程中的重要性以及处理ASCII文件时如何有效地应用异常机制。首先,文章介绍了ASCII文件的基础知识和读写原理,为理解后续异常处理做好铺垫。接着,文章深入分析了C++中的异常处理机制,包括基础语法、标准异常类使用、自定义异常以及异常安全性概念与实现。在此基础上,文章详细探讨了C++在处理ASCII文件时的异常情况,包括文件操作中常见异常分析和异常处理策
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )