前端模块化与代码组织
发布时间: 2024-01-23 11:10:30 阅读量: 40 订阅数: 37 
# 1. 前端模块化的概念
## 1.1 什么是前端模块化
前端模块化是指将前端代码按照一定的规范和方式,拆分成各个独立的模块,以便于代码复用、维护和组织。模块化可以让前端代码更加清晰、灵活,并且利于团队协作开发。
```javascript
// 示例代码:使用CommonJS规范定义一个模块
// utils.js
function add(a, b) {
return a + b;
}
function subtract(a, b) {
return a - b;
}
module.exports = {
add,
subtract
};
```
**代码总结:** 在示例代码中,我们使用 CommonJS 规范定义了一个模块,将加法和减法方法封装在一个模块内,并通过 `module.exports` 导出模块接口。
**结果说明:** 这样的模块化方式可以让其他文件通过 `require` 方法引入该模块,并使用其中的方法。
## 1.2 前端模块化的发展历程
随着前端项目的复杂度不断提高,人们意识到传统的全局变量和函数定义方式已经无法满足需求,因此前端模块化逐渐成为发展趋势。从最初的立即执行函数到CommonJS、AMD、CMD等规范的提出,再到ES6模块化规范的出现,前端模块化经历了不断的发展和完善。
```javascript
// 示例代码:使用ES6模块化规范定义一个模块
// utils.js
export function multiply(a, b) {
return a * b;
}
export function divide(a, b) {
return a / b;
}
```
**代码总结:** 在示例代码中,我们使用 ES6 模块化规范定义了一个模块,通过 `export` 导出模块接口。
**结果说明:** 这样的模块化方式在现代前端开发中得到了广泛应用,被大多数现代浏览器所支持。
## 1.3 前端模块化的优势
前端模块化的优势包括提高代码复用性、便于维护和拓展、减少命名冲突、更好的团队协作等。模块化开发可以让前端项目更加灵活、高效地进行开发和维护。
**代码总结:** 前端模块化的优势是指的模块化对于项目的好处,包括提高代码复用性、便于维护和拓展、减少命名冲突和更好的团队协作。
**结果说明:** 前端模块化的优势使得它成为了现代前端开发中不可或缺的一部分,被广泛应用于各类前端项目中。
# 2. 模块化开发规范
### 2.1 CommonJS规范
CommonJS是一种模块化规范,主要用于服务器端开发。它的特点是同步加载模块,使用`module.exports`导出模块,使用`require`加载模块。以下是一个简单的Node.js示例:
```javascript
// math.js
const add = (a, b) => {
return a + b;
};
module.exports = {
add
};
// app.js
const math = require('./math');
console.log(math.add(2, 3)); // 输出5
```
使用CommonJS规范可以方便地进行模块化开发,在服务器端得到广泛应用。
### 2.2 AMD规范
AMD(Asynchronous Module Definition)是另一种模块化规范,主要用于浏览器端开发。它的特点是异步加载模块,需要使用专门的库(如RequireJS)来实现。以下是一个简单的AMD规范示例:
```javascript
// math.js
define(function() {
return {
add: function(a, b) {
return a + b;
}
};
});
// app.js
require(['math'], function(math) {
console.log(math.add(2, 3)); // 输出5
});
```
AMD规范适用于在浏览器端异步加载模块的场景,有助于提高页面加载性能和模块化开发的灵活性。
### 2.3 ES6模块化规范
ES6模块化规范是ECMAScript 6引入的模块化方案,它成为了JavaScript的官方标准。ES6模块化使用`export`导出模块,使用`import`加载模块。以下是一个简单的ES6模块化示例:
```javascript
// math.js
export const add = (a, b) => {
return a + b;
};
// app.js
import { add } from './math';
console.log(add(2, 3)); // 输出5
```
ES6模块化规范在现代前端开发中得到了广泛应用,因为它提供了更强大且易用的模块化功能。
### 2.4 模块化开发的最佳实践
无论是CommonJS、AMD还是ES6模块化规范,都有各自的优势和适用场景。在实际项目中,可以根据具体情况选择合适的模块化规范,并结合模块化开发的最佳实践,如合理划分模块、减少模块之间的耦合等,来提高代码的可维护性和可扩展性。
# 3. 前端代码组织的原则
前端代码组织是前端开发中非常重要的一环,好的代码组织可以提高代码的可维护性和可扩展性。在进行前端代码组织时,需要遵循一些原则,以保证代码的质量和可维护性。
#### 3.1 单一职责原则
单一职责原则是指一个模块/类/组件应该只有一个改变的理由。换句话说,一个模块/类/组件只负责完成一个功能或承担一个责任。这样做的好处是降低了各部分之间的耦合度,提高了代码的可读性和可维护性。
```java
// 举例:单一职责原则的应用
class ProductService {
public void getProductDetails(int productId) {
// 获取产品详情的代码
}
}
class ProductValidator {
public boolean validateProduct(Product prod
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏旨在全面介绍前端全栈开发的学习路径和关键知识点。我们将深入探讨HTML、CSS和JavaScript的基础知识,包括标签的使用、样式布局、常用函数、DOM操作和事件处理等。此外,我们还会介绍前端框架的实践、网络通信与AJAX技术、性能优化、跨域问题及解决方案、安全性与常见攻击防御、单元测试与自动化测试、模块化与代码组织、前后端分离与RESTful API设计等方面的内容。另外,我们还将探讨数据可视化、响应式设计、国际化与多语言支持、算法与数据结构实践、面试准备与常见问题解答以及性能监控与错误追踪等关键话题。通过本专栏的学习,您将全面掌握前端全栈开发所需的知识和技能,为实际工作和面试做好充分准备。
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
算法到硬件的无缝转换:实现4除4加减交替法逻辑的实战指南
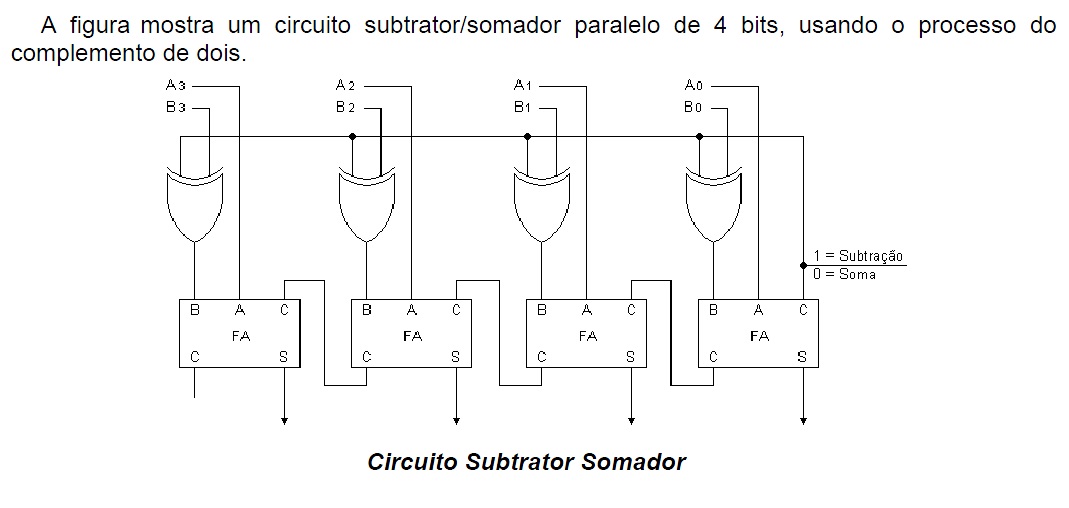
# 摘要
本文旨在介绍一种新颖的4除4加减交替法,探讨了其基本概念、原理及算法设计,并分析了其理论基础、硬件实现和仿真设计。文章详细阐述了算法的逻辑结构、效率评估与优化策略,并通过硬件描述语言(HDL)实现了算法的硬件设计与仿真测试。此外,本文还探讨了硬件实现与集成的过程,包括FPGA的开发流程、逻辑综合与布局布线,以及实际硬件测试。最后,文章对算法优化与性能调优进行了深入分析,并通过实际案例研究,展望了算法与硬件技术未来的发
【升级攻略】:Oracle 11gR2客户端从32位迁移到64位,完全指南

# 摘要
随着信息技术的快速发展,企业对于数据库系统的高效迁移与优化要求越来越高。本文详细介绍了Oracle 11gR2客户端从旧系统向新环境迁移的全过程,包括迁移前的准备工作、安装与配置步骤、兼容性问题处理以及迁移后的优化与维护。通过对系统兼容性评估、数据备份恢复策略、环境变量设置、安装过程中的问题解决、网络
【数据可视化】:煤炭价格历史数据图表的秘密揭示

# 摘要
数据可视化是将复杂数据以图形化形式展现,便于分析和理解的一种技术。本文首先探讨数据可视化的理论基础,再聚焦于煤炭价格数据的可视化实践,
FSIM优化策略:精确与效率的双重奏

# 摘要
本文详细探讨了FSIM(Feature Similarity Index Method)优化策略,旨在提高图像质量评估的准确度和效率。首先,对FSIM算法的基本原理和理论基础进行了分析,然后针对算法的关键参数和局限性进行了详细讨论。在此基础上,提出了一系列提高FSIM算法精确度的改进方法,并通过案例分析评估
IP5306 I2C异步消息处理:应对挑战与策略全解析

# 摘要
本文系统介绍了I2C协议的基础知识和异步消息处理机制,重点分析了IP5306芯片特性及其在I2C接口下的应用。通过对IP5306芯片的技术规格、I2C通信原理及异步消息处理的特点与优势的深入探讨,本文揭示了在硬件设计和软件层面优化异步消息处理的实践策略,并提出了实时性问题、错误处理以及资源竞争等挑战的解决方案。最后,文章
DBF到Oracle迁移高级技巧:提升转换效率的关键策略

# 摘要
本文探讨了从DBF到Oracle数据库的迁移过程中的基础理论和面临的挑战。文章首先详细介绍了迁移前期的准备工作,包括对DBF数据库结构的分析、Oracle目标架构的设计,以及选择适当的迁移工具和策略规划。接着,文章深入讨论了迁移过程中的关键技术和策略,如数据转换和清洗、高效数据迁移的实现方法、以及索引和约束的迁移。在迁移完成后,文章强调了数据验证与性能调优的重要性,并通过案例分析,分享了不同行业数据迁移的经
【VC709原理图解读】:时钟管理与分布策略的终极指南(硬件设计必备)
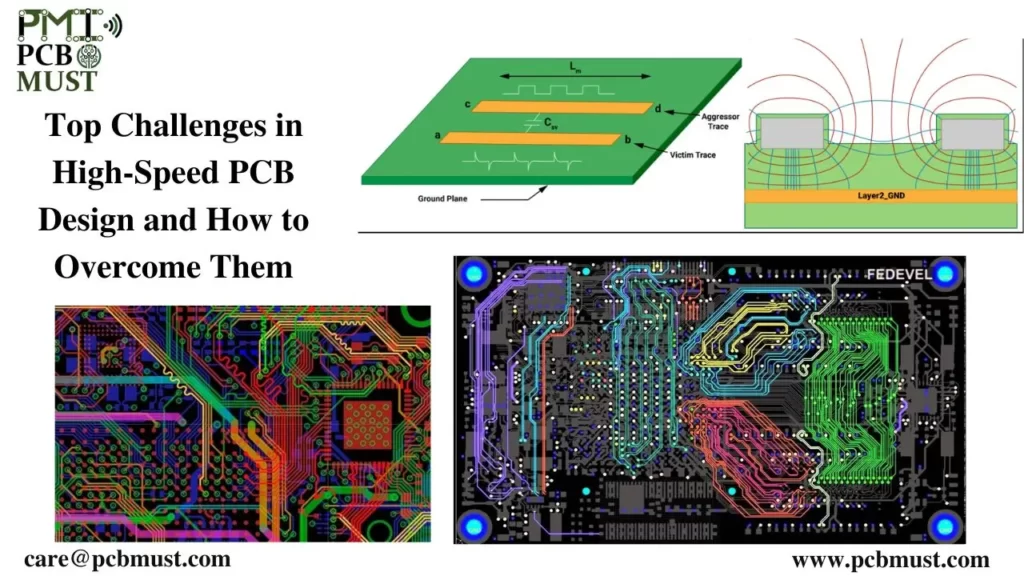
# 摘要
本文详细介绍了VC709硬件的特性及其在时钟管理方面的应用。首先对VC709硬件进行了概述,接着探讨了时钟信号的来源、路径以及时钟树的设计原则。进一步,文章深入分析了时钟分布网络的设计、时钟抖动和偏斜的控制方法,以及时钟管理芯片的应用。实战应用案例部分提供了针对硬件设计和故障诊断的实际策略,强调了性能优化
IEC 60068-2-31标准应用:新产品的开发与耐久性设计
# 摘要
IEC 60068-2-31标准是指导电子产品环境应力筛选的国际规范,本文对其概述和重要性进行了详细讨论,并深入解析了标准的理论框架。文章探讨了环境应力筛选的不同分类和应用,以及耐久性设计的实践方法,强调了理论与实践相结合的重要性。同时,本文还介绍了新产品的开发流程,重点在于质量控制和环境适应性设计。通过对标准应用案例的研究,分析了不同行业如何应用环境应力筛选和耐久性设计,以及当前面临的新技术挑战和未来趋势。本文为相关领域的工程实践和标准应用提供了有价值的参考。
# 关键字
IEC 60068-2-31标准;环境应力筛选;耐久性设计;环境适应性;质量控制;案例研究
参考资源链接:
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )