如何快速连接数据源并进行基本数据查询
发布时间: 2024-04-12 10:07:30 阅读量: 71 订阅数: 91 

如何连接数据来源
# 1.1 选择合适的数据源类型
在开始建立数据连接之前,首先需要选择合适的数据源类型。常见的数据源类型包括关系型数据源和非关系型数据源。关系型数据源如 MySQL、PostgreSQL 等,适用于结构化数据。而非关系型数据源如 MongoDB、Redis 等,则适用于非结构化数据。根据项目需求和数据特点,选择合适的数据源类型至关重要,可以提高操作效率并保证数据的完整性和一致性。在选择数据源类型时,需要考虑数据量大小、数据结构复杂度、读写频率等因素,并确保选择的数据源类型能够满足项目的需求。
### 1.2 获取连接信息
获取数据源连接信息是建立数据源连接的第一步。连接信息通常包括认证信息(用户名和密码)、数据库地址、端口号以及数据库名称。这些信息通常由数据库管理员或数据提供方提供,确保信息准确无误非常重要。认证信息用于验证身份权限,数据库地址和端口号用于确定数据源的位置,数据库名称则用于指定具体的数据库实例。在获取连接信息时,需要注意信息的安全性,避免将敏感信息泄露给未授权的人员。
# 2.1 安装必要的驱动程序
在建立数据源连接之前,首先需要确保系统中安装了与目标数据库类型相对应的驱动程序。驱动程序相当于一个桥梁,可以让应用程序与特定类型的数据库进行通信。
#### 2.1.1 查找适用的驱动
在选择驱动程序之前,需要明确目标数据库的类型(如MySQL、PostgreSQL、MongoDB等)。不同的数据库有不同的驱动程序,确保选择对应的驱动程序版本。
#### 2.1.2 下载并安装驱动
一般来说,官方文档会提供驱动程序的下载链接。下载后,根据相应的安装说明进行安装。安装成功后,驱动程序就可以被应用程序所调用。
### 2.2 配置连接参数
安装完驱动程序后,需要配置连接参数,以便应用程序能够成功连接到目标数据库。
#### 2.2.1 设置连接串
连接串是连接数据库时所需的参数集合,包括数据库地址、端口号、数据库名称等。根据数据库类型的不同,连接串的格式也会有所不同。
```python
# 示例:MySQL连接串
host = 'localhost'
port = '3306'
database_name = 'mydb'
connection_string = f"mysql://{host}:{port}/{database_name}"
```
#### 2.2.2 输入用户名和密码
大多数数据库连接还需要提供用户名和密码进行认证。确保在连接参数中包含正确的用户名和密码信息。这些信息通常是在连接串中配置。
```python
# 示例:添加用户名和密码到连接串
username = 'myuser'
password = 'mypassword'
connection_string_with_auth = f"mysql://{username}:{password}@{host}:{port}/{database_name}"
```
#### 2.2.3 测试连接
在配置完连接参数后,可以尝试连接到数据库,并进行简单的测试,确保连接顺利建立。这可以帮助及早发现配置上的问题。
```python
# 示例:测试连接
import sqlalchemy
engine = sqlalchemy.create_engine(connection_string_with_auth)
try:
with engine.connect():
print("Connection successful!")
except Exception as e:
print(f"Connection failed: {str(e)}")
```
### 2.3 确保网络连通性
除了配置数据库连接参数外,还需要确保网络连通性良好,确保应用程序能够顺利连接到数据库服务器。
#### 2.3.1 检查防火墙设置
如果数据库服务器所在的主机有防火墙,需要检查防火墙设置,确保允许应用程序所在主机的IP地址通过相应端口访问数据库。
#### 2.3.2 确认服务器地址和端口可访问
确保数据库服务器的地址和端口是可以被应用程序所在主机访问的。可以通过 ping 命令或 telnet 命令进行检查。
以上是建立数据源连接的过程中安装驱动程序、配置连接参数以及确保网络连通性的主要步骤。接下来,我们将进入第三章,学习如何进行基本数据查询。
# 3. 进行基本数据查询
#### 3.1 编写简单的查询语句
在数据查询过程中,编写简单的查询语句是基础中的基础。通过 SELECT 语句,可以从数据表中检索出需要的数据。在写查询语句时,可以使用 WHERE 条件来限制返回结果的行数,也可以通过 ORDER BY 对结果进行排序。
```sql
-- 查询所有员工的姓名和工资
SELECT 姓名, 工资
FROM 员工表;
-- 查询工资大于5000的员工信息
SELECT *
FROM 员工表
WHERE 工资 > 5000;
-- 查询所有员工按照工资从高到低排序
SELECT *
FROM 员工表
ORDER BY 工资 DESC;
```
#### 3.2 运行并查看查询结果
在编写查询语句后,需要运行查询并查看结果。检查语法错误是必要的,可以通过分析结果集来验证查询效果,并利用工具来优化查询性能。
```sql
-- 编写查询语句
SELECT *
FROM 订单表
WHERE 金额 > 1000
ORDER BY 日期;
-- 运行查询,检查语法并查看结果
```
#### 3.3 学习常见的数据操作
除了查询,数据操作也是数据库中常见的任务。这包括添加新数据、更新现有数据以及删除数据等操作。
```sql
-- 添加新员工记录
INSERT INTO 员工表 (姓名, 工资, 部门)
VALUES ('张三', 6000, '销售部');
-- 更新员工工资
UPDATE 员工表
SET 工资 = 6500
WHERE 姓名 = '张三';
-- 删除工资低于4000的员工记录
DELETE FROM 员工表
WHERE 工资 < 4000;
```
以上是进行基本数据查询的部分方法和技巧,通过对数据进行简单的检索、操作和查询,可以更好地理解数据库中的数据结构和内容。
# 4. 优化数据查询流程
在进行数据查询时,优化查询流程是至关重要的一步。通过使用合适的索引、编写高效的查询语句以及处理性能问题,可以显著提高数据检索的效率和准确性。本章将介绍如何使用索引提高查询效率、编写复杂查询语句以及分析性能问题并优化。
#### 4.1 使用索引提高查询效率
索引是数据库中用来加快查询速度的一种数据结构。它类似于书籍的目录,可以快速指向需要查找的数据。理解索引结构是优化查询效率的第一步。在关系型数据库中,索引通常可以加速 WHERE 和 ORDER BY 操作。创建适当的索引是提高查询性能的关键。
在SQL中,可以通过以下语句创建索引:
```sql
CREATE INDEX index_name ON table_name(column_name);
```
通过以上语句即可为相应的表的列创建索引,提高查询速度。
#### 4.2 编写复杂查询语句
除了基本的查询语句外,还可以编写复杂的查询语句来满足更加具体的需求。嵌套查询是一种常见的复杂查询方式,可以在查询中嵌入其他查询语句以实现更精细的条件筛选。聚合函数可以对查询结果进行统计计算,如求和、平均值等。JOIN操作用于关联多个表,通过共同的字段将它们连接起来。
在SQL中,可以通过以下语句进行JOIN操作:
```sql
SELECT column_name(s)
FROM table1
JOIN table2 ON table1.column_name = table2.column_name;
```
#### 4.3 分析性能问题并优化
在进行大量数据查询时,可能出现性能问题,如查询时间过长等。为了解决这些问题,需要对查询过程进行监控和分析,并进行相应的优化处理。可以通过监控查询执行时间来找出耗时较长的查询语句,进而优化查询计划。此外,可以考虑使用缓存技术,将查询结果缓存起来,减少对数据库的频繁访问,提高查询效率。
```mermaid
graph TD;
A[开始] --> B(创建索引);
B --> C(编写复杂查询语句);
C --> D(分析性能问题并优化);
D --> E[结束];
```
综合以上方法,可以有效地优化数据查询过程,提高系统性能和用户体验。不断优化查询流程,可以使数据查询更加高效和精准,为后续的数据处理和分析工作打下良好基础。
# 5. 数据可视化与报表生成
在数据分析和查询过程中,数据可视化是至关重要的环节。通过可视化,我们能更直观地展现数据分布、关联性和趋势,从而更好地理解数据并作出决策。本章将介绍如何利用各种工具进行数据可视化与报表生成。
- **5.1 选择合适的可视化工具**
5.1.1 数据可视化的重要性
5.1.2 常见的数据可视化工具
- 数据可视化库(如Matplotlib、Seaborn)
- 商业可视化工具(如Tableau、Power BI)
- Web 可视化框架(如D3.js、ECharts)
- **5.2 创建基本图表**
数据可视化的基本形式包括柱状图、折线图、饼图等,以下是一个用 Matplotlib 绘制柱状图的示例代码:
```python
import matplotlib.pyplot as plt
data = {'Apple': 10, 'Banana': 15, 'Orange': 7, 'Grape': 22}
fruits = list(data.keys())
values = list(data.values())
plt.bar(fruits, values)
plt.xlabel('Fruits')
plt.ylabel('Quantity')
plt.title('Fruit Distribution')
plt.show()
```
以上代码会生成一个简单的柱状图,展示不同水果的数量分布。
- **5.3 制作交互式图表**
交互式图表能够提供更多操作和展示的可能性,例如悬停查看数值、筛选数据等。使用 Plotly 可以轻松创建交互式图表,以下是一个简单的示例流程图:
```mermaid
graph TD;
A(开始)-->B(数据准备)
B-->C(创建交互式图表)
C-->D(添加交互功能)
D-->E(发布图表)
```
- **5.4 生成报表**
报表通常包括多个图表和数据展示,能够全面呈现数据分析结果。通过使用工具如Tableau、JasperReports等,可以便捷地生成专业的报表,提供决策所需的数据支持。
- **5.5 导出与共享报表**
一旦报表生成完成,通常需要导出并与团队共享。常见的方式包括导出为PDF、图片格式,或者直接通过Web链接共享给相关人员查看。
- **5.6 设计美观的数据可视化**
除了数据准确性,数据可视化的美观性也极为重要。合理选择颜色、图表样式,调整布局等设计因素,能够让数据更具吸引力和易懂性。
- **5.7 数据可视化应用场景**
数据可视化不仅局限于报表生成,还可以应用于监控大屏、数据仪表盘、企业BI系统等各种场景,为业务决策提供实时支持。
- **5.8 数据可视化与未来发展**
随着人工智能和大数据技术的发展,数据可视化也将朝着智能化、自动化的方向发展,为用户提供更加个性化、智能化的数据分析和展示服务。
- **5.9 综述**
通过本章的学习,我们不仅了解了数据可视化的重要性和基本操作,还掌握了如何利用不同工具进行数据可视化与报表生成。数据可视化不仅能够提升数据分析效率,还能更好地传达数据背后的信息,为决策提供支持。
- **5.10 展望未来**
随着数据科学领域的不断发展,数据可视化将扮演着越来越重要的角色。我们需要不断学习和探索新的数据可视化技术,以更好地满足不断增长的数据分析需求,推动企业决策和创新发展。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
《Datagrip》专栏全面介绍了这款数据库管理工具的各种功能和使用方法。从基本界面布局解析到高级数据操作技巧,专栏文章涵盖了广泛的主题,包括:
* 连接数据源、执行查询和导入导出数据
* 筛选、排序和过滤数据以提高检索效率
* 使用自动完成功能和SQL编辑器快捷键提升开发效率
* 创建、管理和修改数据库对象
* 利用数据库版本控制功能实现协作和数据安全
* 进行数据表关联查询并使用可视化工具探索数据
* 编辑表数据、进行数据导航和对象搜索
* 调试SQL脚本、优化性能并使用代码片段生成SQL语句
* 创建数据图表和图形,备份和恢复数据库
* 整理、清洗和转换数据,以及使用格式化和转换功能处理数据。
通过深入浅出的讲解和丰富的示例,该专栏为数据库开发人员提供了全面而实用的指导,帮助他们充分利用Datagrip的功能,提升工作效率和数据管理能力。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
Catia曲线曲率分析深度解析:专家级技巧揭秘(实用型、权威性、急迫性)
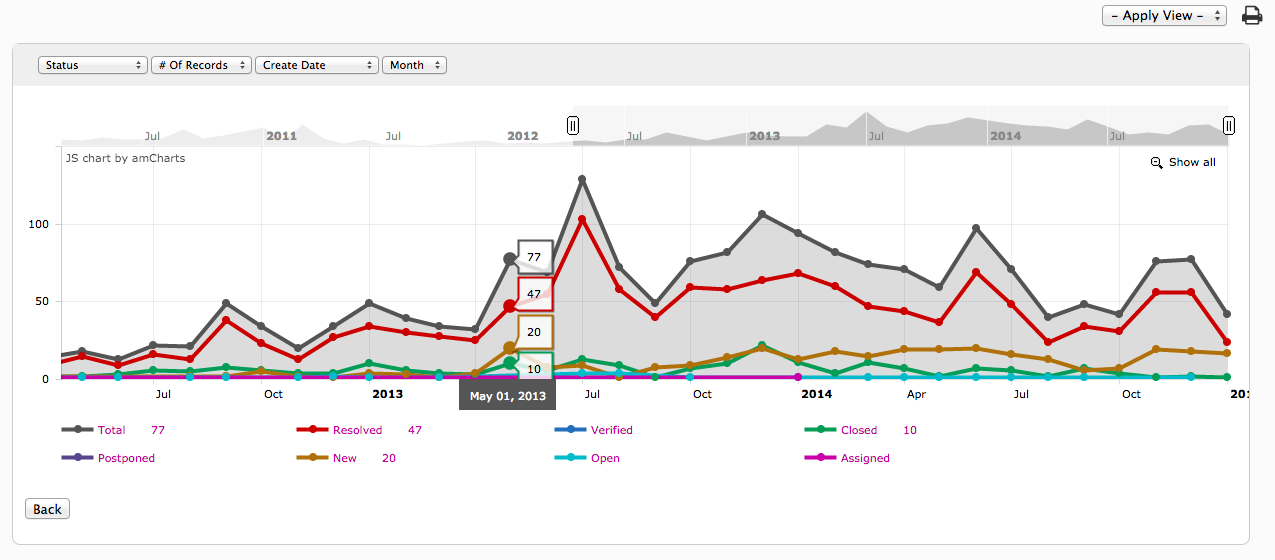
# 摘要
本文全面介绍了Catia软件中曲线曲率分析的理论、工具、实践技巧以及高级应用。首先概述了曲线曲率的基本概念和数学基础,随后详细探讨了曲线曲率的物理意义及其在机械设计中的应用。文章第三章和第四章分别介绍了Catia中曲线曲率分析的实践技巧和高级技巧,包括曲线建模优化、问题解决、自动化定制化分析方法。第五章进一步探讨了曲率分析与动态仿真、工业设计中的扩展应用,以及曲率分析技术的未来趋势。最后,第六章对Catia曲线曲率分析进行了
【MySQL日常维护】:运维专家分享的数据库高效维护策略
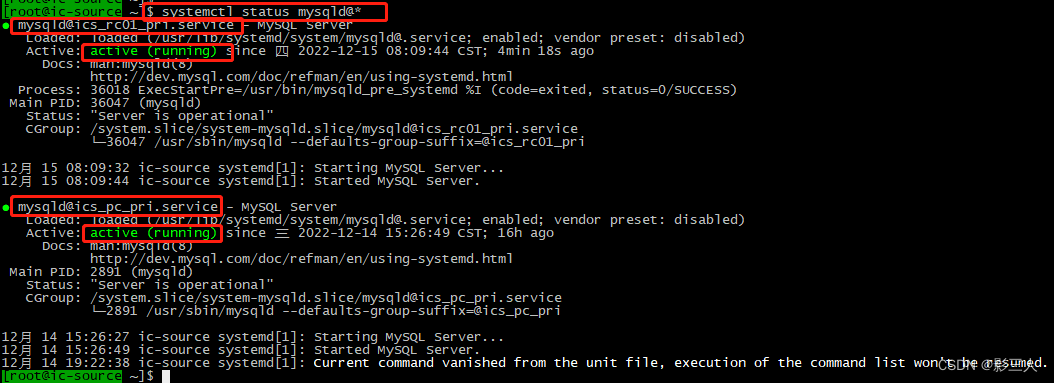
# 摘要
本文全面介绍了MySQL数据库的维护、性能监控与优化、数据备份与恢复、安全性和权限管理以及故障诊断与应对策略。首先概述了MySQL基础和维护的重要性,接着深入探讨了性能监控的关键性能指标,索引优化实践,SQL语句调优技术。文章还详细讨论了数据备份的不同策略和方法,高级备份工具及技巧。在安全性方面,重点分析了用户认证和授权机制、安全审计以及防御常见数据库攻击的策略。针对故障诊断,本文提供了常
EMC VNX5100控制器SP硬件兼容性检查:专家的完整指南

# 摘要
本文旨在深入解析EMC VNX5100控制器的硬件兼容性问题。首先,介绍了EMC VNX5100控制器的基础知识,然后着重强调了硬件兼容性的重要性及其理论基础,包括对系统稳定性的影响及兼容性检查的必要性。文中进一步分析了控制器的硬件组件,探讨了存储介质及网络组件的兼容性评估。接着,详细说明了SP硬件兼容性检查的流程,包括准备工作、实施步骤和问题解决策略。此外
【IT专业深度】:西数硬盘检测修复工具的专业解读与应用(IT专家的深度剖析)
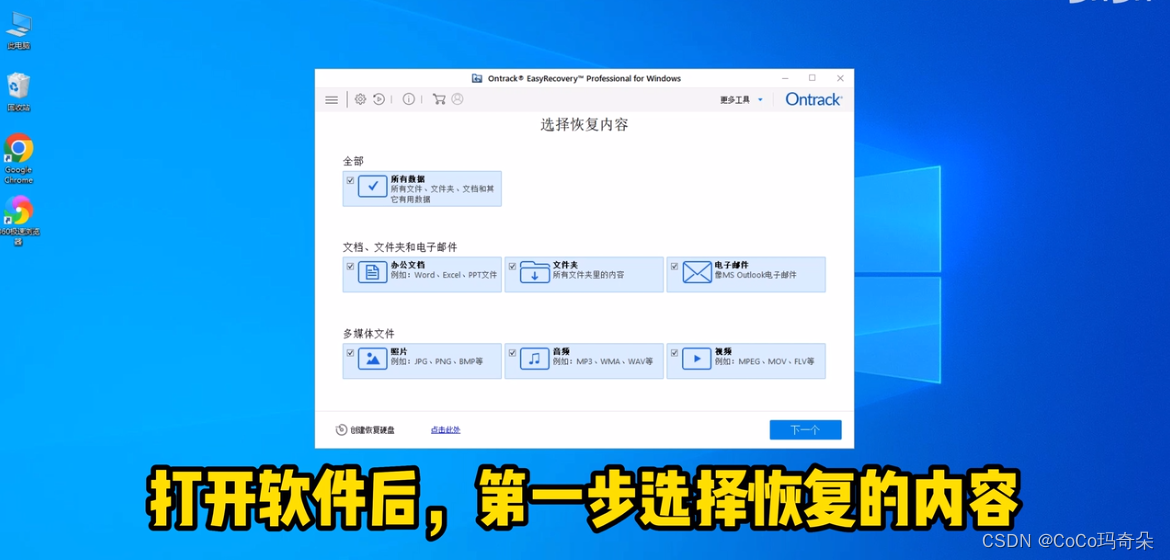
# 摘要
本文旨在全面介绍硬盘的基础知识、故障检测和修复技术,特别是针对西部数据(西数)品牌的硬盘产品。第一章对硬盘的基本概念和故障现象进行了概述,为后续章节提供了理论基础。第二章深入探讨了西数硬盘检测工具的理论基础,包括硬盘的工作原理、检测软件的分类与功能,以及故障检测的理论依据。第三章则着重于西数硬盘修复工具的使用技巧,包括修复前的准备工作、实际操作步骤和常见问题的解决方法。第四章与第五章进一步探讨了检测修复工具的深入应
【永磁电机热效应探究】:磁链计算如何影响电机温度管理
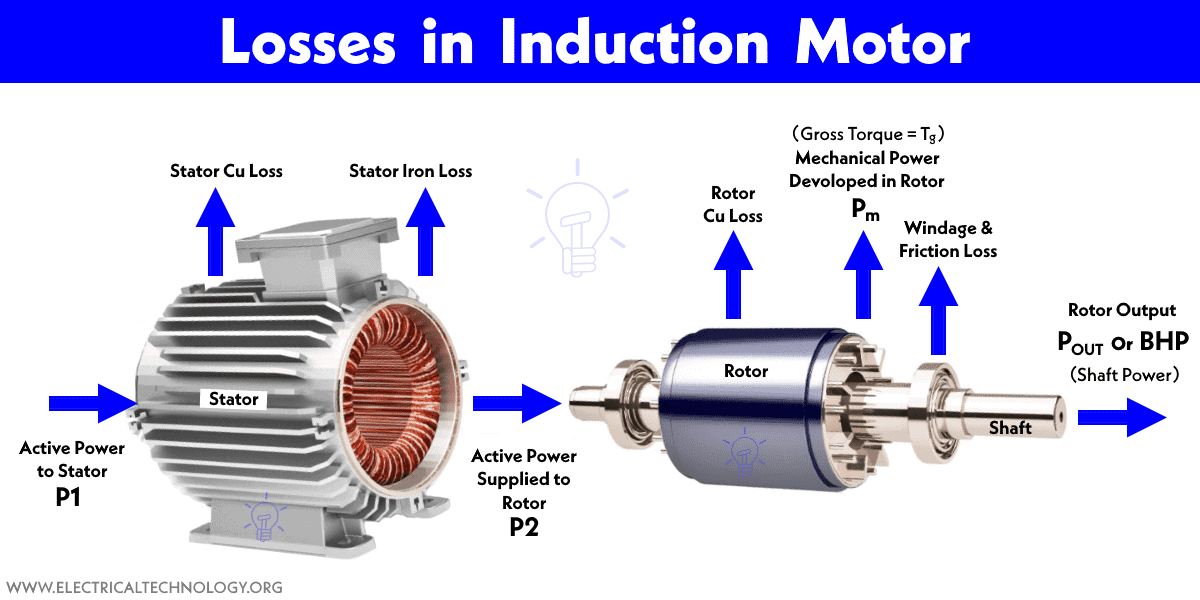
# 摘要
本论文对永磁电机的基础知识及其热效应进行了系统的概述。首先,介绍了永磁电机的基本理论和热效应的产生机制。接着,详细探讨了磁链计算的理论基础和计算方法,以及磁链对电机温度的影响。通过仿真模拟与分析,评估了磁链计算在电机热效应分析中的应用,并对仿真结果进行了验证。进一步地,本文讨论了电机温度管理的实际应用,包括热效应监测技术和磁链控制策略的
【代码重构在软件管理中的应用】:详细设计的革新方法

# 摘要
代码重构是软件维护和升级中的关键环节,它关注如何提升代码质量而不改变外部行为。本文综合探讨了代码重构的基础理论、深
【SketchUp设计自动化】

# 摘要
本文系统地探讨了SketchUp设计自动化在现代设计行业中的概念与重要性,着重介绍了SketchUp的基础操作、脚本语言特性及其在自动化任务中的应用。通过详细阐述如何通过脚本实现基础及复杂设计任务的自动化
【CentOS 7时间同步终极指南】:掌握NTP配置,提升系统准确性
# 摘要
本文深入探讨了CentOS 7系统中时间同步的必要性、NTP(Network Time Protocol)的基础知识、配置和高级优化技术。首先阐述了时
轮胎充气仿真深度解析:ABAQUS模型构建与结果解读(案例实战)

# 摘要
轮胎充气仿真是一项重要的工程应用,它通过理论基础和仿真软件的应用,能够有效地预测轮胎在充气过程中的性能和潜在问题。本文首先介绍了轮胎充气仿真的理论基础和应用,然后详细探讨了ABAQUS仿真软件的环境配置、工作环境以及前处理工具的应用。接下来,本文构建了轮胎充气模型,并设置了相应的仿真参数。第四章分析了仿真的结果,并通过后处理技术和数值评估方法进行了深入解读。最后,通过案例实战演练,本文演示了
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )