初识beego框架:了解其概念与特点
发布时间: 2023-12-17 04:46:07 阅读量: 94 订阅数: 43 
# 1. 介绍beego框架
## 1.1 什么是beego框架
beego框架是一个基于Go语言开发的高性能轻量级Web应用框架,它遵循MVC架构模式,提供了丰富的功能和工具,帮助开发者快速构建和部署Web应用程序。
## 1.2 beego框架的发展历程
beego框架最初由beego团队于2012年推出,经过多年的发展和迭代,已被广泛应用于各种Web开发项目中。它不仅吸收了其他成熟框架的优点,还结合了自身的创新理念,使得它成为一款功能强大且易于使用的框架。
## 1.3 beego框架的应用领域和优势
beego框架适用于开发各种规模的Web应用程序,无论是小型个人博客还是大型企业级应用,都能够借助beego框架进行快速开发。其优势主要体现在以下几个方面:
- **高性能**:beego框架采用了高效的路由和并发处理机制,能够处理大量并发请求,保证Web应用的高性能响应。
- **简化开发**:beego框架提供了丰富的内置工具和组件,如ORM、模板引擎、session管理等,减少了开发者的重复工作,使开发过程更加高效。
- **灵活扩展**:beego框架提供了丰富的插件和扩展机制,开发者可以根据自己的需求自由扩展框架的功能。
- **良好的文档和支持**:beego框架有一份完善的官方文档,同时拥有活跃的社区支持,开发者可以快速获得帮助和解决问题。
## beego框架的核心概念
beego框架是基于MVC架构模式的Web开发框架,其中包含了一些重要的核心概念,如路由与控制器、数据模型与视图以及中间件的概念与使用。下面将详细介绍这些核心概念。
### 2.1 MVC架构模式
MVC模式是一种常用的软件架构模式,它将应用程序划分为三个核心组件:模型(Model)、视图(View)和控制器(Controller)。在beego框架中,也采用了MVC模式来组织代码。
- **模型(Model)**:模型层主要用于处理数据相关的操作,包括数据库查询、数据处理等。在beego框架中,可以使用ORM进行数据库操作,或者直接使用原生的数据库操作。
- **视图(View)**:视图层主要负责展示数据给用户,通常是HTML页面或者其他前端模板。在beego框架中,可以使用模板引擎来渲染视图,如beego自带的模板引擎或者第三方模板引擎。
- **控制器(Controller)**:控制器层是MVC模式的核心,负责接收用户的请求,处理业务逻辑,并将结果返回给客户端。在beego框架中,控制器可以通过定义路由来映射URL,并实现相应的处理函数。
### 2.2 路由与控制器
在beego框架中,路由用于将客户端请求映射到相应的控制器处理函数,从而实现URL的分发。beego框架提供了灵活的路由规则,可以支持RESTful风格的URL设计。
```go
// 示例代码:定义一个路由规则
beego.Router("/user/:id", &controllers.UserController{})
```
在上面的示例中,`/user/:id`是一个路由规则,表示将以`/user/`开头的URL映射到`UserController`控制器中,并根据`:id`参数的值来决定具体的处理方法。
控制器是beego框架中处理业务逻辑的核心部分,它通常是一个结构体,其中包含了若干处理函数,每个函数对应一个具体的请求。在处理函数中,可以通过上下文对象(`this.Ctx`)来获取请求信息和返回响应。
```go
// 示例代码:定义一个UserController控制器
type UserController struct {
beego.Controller
}
func (c *UserController) Get() {
id := c.Ctx.Input.Param(":id")
// 根据id查询用户信息
// ...
c.Data["json"] = user // 设置响应数据
c.ServeJSON() // 返回JSON响应
}
```
在上面的示例中,`Get()`是一个处理函数,用于处理以GET方法发送的请求。在函数中,通过`this.Ctx.Input.Param(":id")`获取URL中的参数值,然后根据参数值查询用户信息,并将结果设置到`Controller.Data`中,最后使用`ServeJSON()`返回JSON格式的响应。
### 2.3 数据模型与视图
beego框架中的数据模型通常与数据库进行交互,可以使用ORM框架来简化数据库操作。beego框架提供了自带的ORM工具,可以方便地进行数据的增删改查操作。
```go
// 示例代码:定义一个User数据模型
type User struct {
Id int
Name string
Age int
}
// 查询用户信息
user := User{Id: 1}
err := orm.NewOrm().Read(&user)
if err == orm.ErrNoRows {
// 数据不存在
} else if err == nil {
// 查询成功
} else {
// 查询失败
}
```
在上面的示例中,`User`是一个数据模型,包含了与数据库中的表对应的字段。通过调用`orm.NewOrm().Read(&user)`方法,可以查询对应的用户信息。
视图在beego框架中通常是使用模板引擎来渲染的,可以使用beego自带的模板引擎或者第三方模板引擎。模板引擎可以将动态数据与HTML页面进行组合,最终生成响应给客户端的HTML文档。
```go
// 示例代码:使用beego自带的模板引擎渲染视图
c.Data["username"] = "John"
c.Data["age"] = 20
c.TplName = "user.html"
```
在上面的示例中,通过设置`Controller.Data`来传递动态数据,然后将视图模板的名称(如"user.html")赋值给`Controller.TplName`,beego框架会自动查找并渲染对应的视图模板。
### 2.4 beego中间件的概念与使用
中间件是beego框架中的一个重要概念,它可以在请求到达控制器之前或之后进行一些额外的处理。beego框架提供了丰富的中间件机制,可以用于实现日志记录、权限验证、统计信息等功能。
```go
// 示例代码:定义一个日志中间件
func LogMiddleware(ctx *context.Context) {
// 在请求到达控制器之前输出日志
fmt.Println("Request URL:", ctx.Request.URL)
fmt.Println("Request Method:", ctx.Request.Method)
}
// 在beego应用程序中注册中间件
beego.InsertFilter("/*", beego.BeforeRouter, LogMiddleware)
```
在上面的示例中,`LogMiddleware`是一个中间件函数,用于输出请求的URL和方法信息。通过调用`beego.InsertFilter()`方法将中间件与路由规则进行关联,可以指定中间件在请求到达控制器之前、之后或者其他时机进行执行。
### 3. beego框架的特点与优势
在本章中,我们将讨论beego框架的特点和优势。beego框架作为一个高效、可扩展且易于使用的开发框架,具有以下几个重要特点:
#### 3.1 简单易学的语法
beego框架采用了Go语言作为开发语言,Go语言本身就具有简洁、易读的特点,因此beego框架也继承了这样的特点。使用beego框架,开发者可以快速上手,编写简洁而易于维护的代码。
以下是一个使用beego框架的示例代码:
```go
package controllers
import (
"github.com/astaxie/beego"
)
type MainController struct {
beego.Controller
}
func (c *MainController) Get() {
c.Data["Username"] = "John"
c.TplName = "index.tpl"
}
```
通过这段代码,我们可以看到beego框架的控制器是以结构体的形式定义的,开发者只需要重写对应的方法,并在方法内部进行业务逻辑的处理即可。
#### 3.2 快速开发与高效路由
beego框架提供了丰富而强大的开发工具和函数,以支持快速的web应用开发。通过beego框架的路由功能,我们可以轻松地定义URL与控制器之间的映射关系,实现请求的分发和处理。
以下是一个使用beego框架进行路由定义的示例代码:
```go
package routers
import (
"github.com/astaxie/beego"
"myproject/controllers"
)
func init() {
beego.Router("/", &controllers.MainController{})
beego.Router("/user/:id", &controllers.UserController{})
beego.Router("/product/:id", &controllers.ProductController{})
}
```
在这个示例中,我们定义了三个不同的URL路径,并将它们与对应的控制器进行了绑定。当用户请求不同的URL时,beego框架会自动调用对应的控制器方法进行处理。
#### 3.3 强大的兼容性与可扩展性
beego框架支持多种数据库的操作和使用,包括MySQL、PostgreSQL、SQLite等主流的关系型数据库,以及NoSQL数据库如MongoDB等。开发者可以根据自己的需求选择适合的数据库,并通过beego框架提供的ORM工具进行数据操作。
同时,beego框架还支持丰富的插件扩展机制,开发者可以根据自己的业务需求进行插件的开发和集成,以实现更多功能的扩展。
#### 3.4 完善的文档与活跃的社区支持
beego框架拥有完善的文档和丰富的示例代码,开发者可以通过官方文档快速了解和学习beego框架的使用方法。此外,beego框架有着活跃的社区支持,在社区中开发者可以交流经验、提问问题,并得到及时的解答和帮助。
### 4. beego框架的安装与配置
Beego框架的安装和配置是使用该框架的重要第一步,本章将介绍如何安装Beego框架及其依赖,以及配置Beego框架的运行环境和基本参数。
#### 4.1 安装beego框架及其依赖
在开始使用Beego框架之前,首先需要安装Go语言环境,因为Beego是基于Go语言开发的。安装Go语言的具体步骤可以参考Go官方文档。安装好Go语言后,可以通过以下命令安装Beego框架:
```bash
go get -u github.com/astaxie/beego
```
上述命令会自动下载并安装Beego框架及其相关依赖。安装完成后,可以通过以下命令验证Beego框架是否成功安装:
```bash
beego version
```
如果成功安装,会显示Beego框架的版本信息。
#### 4.2 配置beego框架的运行环境和基本参数
Beego框架的配置文件是`app.conf`,该文件位于Beego应用的根目录下。可以在`app.conf`中配置数据库连接、端口号、模板路径等信息。以下是一个简单的`app.conf`配置示例:
```ini
appname = myapp
httpport = 8080
runmode = dev
mysqluser = root
mysqlpass = 123456
mysqlurls = 127.0.0.1:3306
mysqldb = myapp
```
上述配置定义了应用名称、HTTP端口、运行模式以及MySQL数据库的连接信息。
#### 4.3 搭建beego开发环境
搭建Beego开发环境需要使用Go语言的相关工具,可以使用`bee`工具来创建和管理Beego应用。`bee`工具是Beego框架官方提供的一款命令行工具,可以简化Beego应用的创建、运行、编译等操作。以下是使用`bee`工具创建一个Beego应用的示例命令:
```bash
bee new myapp
```
上述命令会在当前目录下创建一个名为`myapp`的Beego应用。通过以上步骤,就可以成功搭建Beego的开发环境了。
本章介绍了Beego框架的安装和配置步骤,包括安装Beego框架及其依赖、配置框架的运行环境和基本参数,以及搭建Beego开发环境的过程。在完成这些步骤后,读者就可以开始使用Beego框架进行Web应用的开发了。
### 5. beego框架的基本使用
在本章中,我们将会详细介绍如何使用beego框架进行web应用程序的开发。以下是基本使用的步骤和示例代码:
#### 5.1 创建一个简单的beego项目
首先,我们需要在命令行中使用以下命令创建一个新的beego项目:
```
beego new myproject
```
这将在当前目录下创建一个名为 "myproject" 的新文件夹,并生成基本的项目结构。
#### 5.2 定义路由和控制器
接下来,我们需要定义路由和控制器来处理客户端的请求。在beego框架中,我们可以使用路由器(router)来将不同的URL请求映射到相应的控制器处理函数。
在 "routers" 文件夹中,创建一个新的路由文件 "router.go",然后添加以下代码:
```go
package routers
import (
"github.com/astaxie/beego"
"myproject/controllers"
)
func init() {
beego.Router("/", &controllers.MainController{})
beego.Router("/user", &controllers.UserController{})
}
```
上述代码定义了两个路由,分别将根路径 "/" 和 "/user" 请求分别映射到对应的控制器处理函数。
然后,在 "controllers" 文件夹中,创建两个控制器文件 "main_controller.go" 和 "user_controller.go",并添加以下代码:
```go
package controllers
import "github.com/astaxie/beego"
type MainController struct {
beego.Controller
}
func (c *MainController) Get() {
c.Ctx.WriteString("Hello, this is the main page.")
}
type UserController struct {
beego.Controller
}
func (c *UserController) Get() {
c.Ctx.WriteString("Hello, this is the user page.")
}
```
上述代码定义了两个控制器,分别处理根路径和 "/user" 路径的GET请求,并返回相应的文本信息。
#### 5.3 数据模型和视图的使用
beego框架也支持数据模型和视图的使用,以便更方便地进行数据操作和页面展示。
在 "models" 文件夹中,创建一个新的数据模型文件 "user_model.go",并添加以下代码:
```go
package models
type User struct {
ID int
Name string
}
```
上述代码定义了一个简单的用户模型。
在 "views" 文件夹中,创建一个新的视图文件 "user.html",并添加以下代码:
```html
<!DOCTYPE html>
<html>
<body>
<h1>Welcome {{.Name}}!</h1>
</body>
</html>
```
上述代码定义了一个简单的用户页面,通过模板引擎的语法将用户名显示在页面上。
然后,在 "controllers" 文件夹的 "user_controller.go" 文件中,修改 Get 方法的代码如下:
```go
func (c *UserController) Get() {
user := models.User{
ID: 1,
Name: "John",
}
c.Data["Name"] = user.Name
c.TplName = "user.html"
}
```
上述代码创建了一个名为 "John" 的用户,将其名字传递到视图模板中,并将视图模板的名称设置为 "user.html"。
#### 5.4 在beego中使用中间件增强功能
beego框架还提供了中间件(middleware)的概念,可以在请求处理的前后执行一些自定义的逻辑。
在 "middlewares" 文件夹中,创建一个新的中间件文件 "auth_middleware.go",并添加以下代码:
```go
package middlewares
import (
"github.com/astaxie/beego"
)
func Authentication(ctx *context.Context) {
// 在请求之前执行的逻辑
// 进行身份验证等操作
// 继续处理请求
ctx.Input.SetData("userInfo", "user123")
beego.Debug("Authentication middleware executed.")
// 在请求之后执行的逻辑
}
```
上述代码定义了一个简单的身份验证中间件,将用户信息存储在请求上下文中,并输出一条调试信息。
然后,在路由器文件中的 init 函数中添加以下代码:
```go
func init() {
beego.Router("/", &controllers.MainController{})
beego.Router("/user", &controllers.UserController{})
beego.InsertFilter("/user", beego.BeforeExec, middlewares.Authentication)
}
```
上述代码将 "Authentication" 中间件应用于 "/user" 路由。
## 6. beego框架的进阶应用
在前面的章节中我们已经学习了beego框架的基本使用方法,接下来将介绍一些beego框架的进阶应用和一些实用技巧,帮助读者更好地掌握和应用beego框架。本章将涵盖以下内容:
### 6.1 beego的路由规则与URL设计
在beego框架中,路由规则和URL设计非常重要,合理的路由规则和URL设计能够提高应用的可读性和可维护性。以下是一些示例代码和说明:
#### 6.1.1 简单路由规则
```go
beego.Router("/", &controllers.MainController{})
beego.Router("/user", &controllers.UserController{})
```
以上示例代码将根路径和"/user"路径分别映射到了`MainController`和`UserController`两个控制器。
#### 6.1.2 带参数的路由规则
```go
beego.Router("/user/:id", &controllers.UserController{}, "get:GetUser")
beego.Router("/user/:id([0-9]+)", &controllers.UserController{}, "get:GetUserById")
```
以上示例代码演示了两种带参数的路由规则,如"/user/1"和"/user/2"等路径将分别映射到`UserController`的`GetUserById`方法。
#### 6.1.3 RESTful风格的路由规则
```go
beego.Router("/user", &controllers.UserController{}, "get:ListUsers")
beego.Router("/user/:id", &controllers.UserController{}, "get:GetUserById;put:UpdateUser;delete:DeleteUser")
```
以上示例代码展示了RESTful风格的路由规则,不同的HTTP方法在路由规则中通过分号分隔,可以根据需要灵活组合。
### 6.2 beego框架的自动化测试与部署
beego框架提供了一些方便的工具和方法用于自动化测试和部署,以下是一些常用的示例代码和说明:
#### 6.2.1 自动化测试
```go
func TestUserController(t *testing.T) {
this := beego.NewControllerRegister()
this.Add("/user/:id", &controllers.UserController{})
// 创建一个请求并设置参数
req, _ := http.NewRequest("GET", "/user/1", nil)
// 执行请求,获取响应
resp := httptest.NewRecorder()
this.ServeHTTP(req, resp)
// 验证响应结果
assert.Equal(t, 200, resp.Code)
assert.Contains(t, resp.Body.String(), "user_id=1")
}
```
以上示例代码展示了使用beego框架进行自动化测试的基本用法,可以通过创建请求、设置参数、执行请求并验证响应结果来实现自动化测试。
#### 6.2.2 部署到线上环境
```shell
$ go build main.go
# 将编译后的可执行文件和配置文件一同打包
$ tar -czvf myapp.tar.gz main conf
# 上传打包文件到线上服务器
$ scp myapp.tar.gz user@remote-server:/path/to/deploy
# 解压打包文件并启动应用
$ ssh user@remote-server
$ tar -xzvf myapp.tar.gz
$ cd myapp
$ ./main
```
以上示例代码展示了将beego应用部署到线上服务器的基本步骤,包括打包、上传、解压和启动应用。
### 6.3 beego与其他常用框架的整合
beego框架可以与其他常用框架进行整合,以提供更强大的功能和更好的开发体验。以下是一些常见的整合示例:
#### 6.3.1 整合ORM框架
```go
// 在beego中使用gorm作为ORM框架
import (
"github.com/astaxie/beego"
"github.com/jinzhu/gorm"
_ "github.com/jinzhu/gorm/dialects/mysql"
)
func init() {
db, err := gorm.Open("mysql", "user:password@/dbname?charset=utf8&parseTime=True&loc=Local")
if err != nil {
beego.Error(err)
}
// 将gorm的DB实例赋值给beego的Orm变量,以方便在控制器中使用
beego.Orm = db
}
```
以上示例代码演示了如何在beego中整合gorm作为ORM框架,并配置数据库连接信息。
### 6.4 性能优化与错误处理的技巧
在实际开发中,性能优化和错误处理是非常重要的环节。以下是一些常用的性能优化和错误处理的技巧:
#### 6.4.1 缓存技巧
```go
import "github.com/astaxie/beego/cache"
// 使用内存缓存
cacheInstance := cache.NewMemoryCache()
// 设置缓存
key := "user_id:1"
value := "john"
cacheInstance.Put(key, value, 3600*time.Second)
// 获取缓存
result := cacheInstance.Get(key)
```
以上示例代码展示了如何使用beego框架的缓存模块,将数据缓存在内存中以提高访问速度。
#### 6.4.2 错误处理与日志记录
```go
// 错误处理中间件
func ErrorHandler(ctx *context.Context) {
if err := recover(); err != nil {
beego.Error(err)
ctx.Output.SetStatus(http.StatusInternalServerError)
ctx.Output.Body([]byte("Internal Server Error"))
}
}
// 在控制器中使用
func (c *MainController) Get() {
defer c.ServeJSON()
// 业务逻辑处理
if err := doSomething(); err != nil {
panic(err)
}
}
// 日志记录
beego.SetLogger("file", `{"filename": "logs/website.log"}`)
```
以上示例代码展示了错误处理中间件的用法,以及如何在控制器中处理错误并记录日志。通过合理的错误处理和日志记录,可以提高应用的稳定性和可靠性。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
beego是一款基于Go语言开发的Web框架,专注于高性能和可扩展性。本专栏将从初识beego框架开始,通过一系列实践项目,带你逐步掌握beego的各个方面。你将学习到beego的概念和特点,了解安装和配置beego的步骤,使用beego创建新项目并实现简单的Hello World实例。你还将掌握beego的路由配置和参数传递,学习如何使用模板引擎构建动态页面,以及如何与数据库进行交互。专栏还将介绍如何开发RESTful API,实现用户认证和授权,处理日志和错误追踪,进行缓存管理和优化,实现文件上传和邮件发送等功能。你还将学习到如何国际化支持,进行数据库迁移,集成第三方服务,实现Websocket通信以及前后端分离等现代化应用开发方法。专栏最后还将介绍性能优化与并发控制,监控与日志分析,以及将beego应用进行Docker化部署。无论你是刚入门或已有一定经验的开发者,本专栏都能帮助你全面掌握beego框架,并构建高性能、可扩展的Web应用。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
S32K SPI开发者必读:7大优化技巧与故障排除全攻略
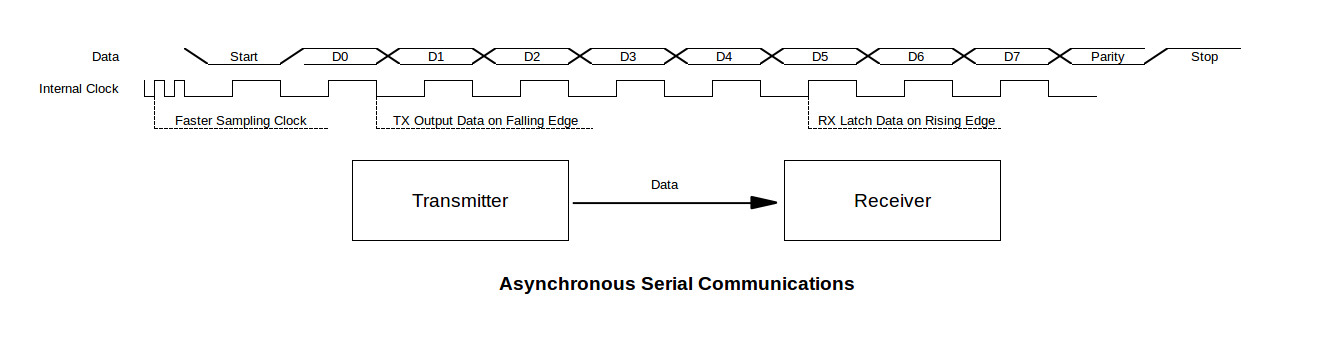
# 摘要
本文深入探讨了S32K微控制器的串行外设接口(SPI)技术,涵盖了从基础知识到高级应用的各个方面。首先介绍了SPI的基础架构和通信机制,包括其工作原理、硬件配置以及软件编程要点。接着,文章详细讨论了SPI的优化技巧,涵盖了代码层面和硬件性能提升的策略,并给出了故障排除及稳定性的提升方法。实战章节着重于故障排除,包括调试工具的使用和性能瓶颈的解决。应用实例和扩展部分分析了SPI在
图解数值计算:快速掌握速度提量图的5个核心构成要素
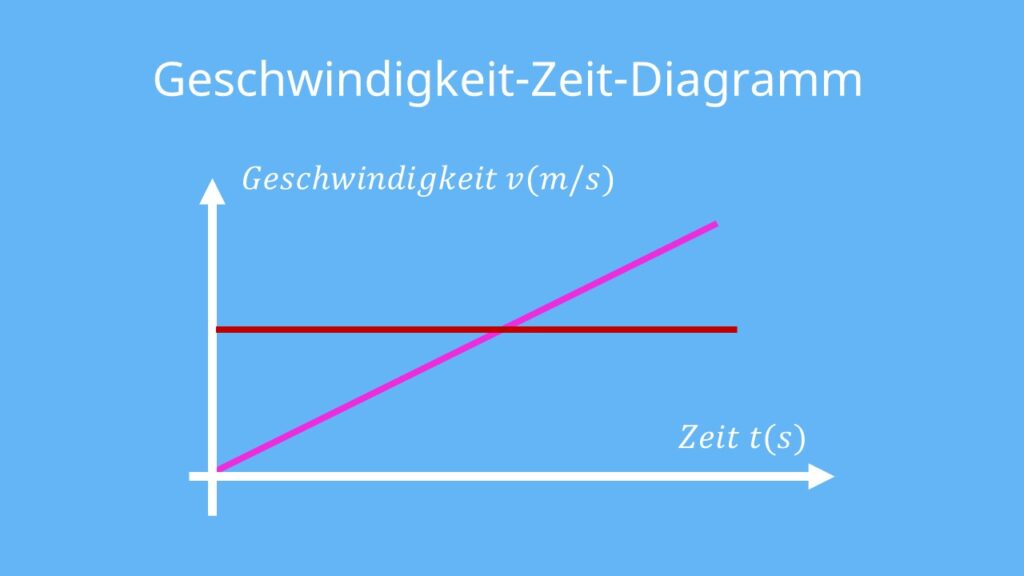
# 摘要
本文全面探讨了速度提量图的理论基础、核心构成要素以及在多个领域的应用实例。通过分析数值计算中的误差来源和减小方法,以及不同数值计算方法的特点,本文揭示了实现高精度和稳定性数值计算的关键。同时,文章深入讨论了时间复杂度和空间复杂度的优化技巧,并展示了数据可视化技术在速度提量图中的作用。文中还举例说明了速度提量图在
动态规划:购物问题的终极解决方案及代码实战

# 摘要
动态规划是解决优化问题的一种强大技术,尤其在购物问题中应用广泛。本文首先介绍动态规划的基本原理和概念,随后深入分析购物问题的动态规划理论,
【随机过程精讲】:工程师版习题解析与实践指南
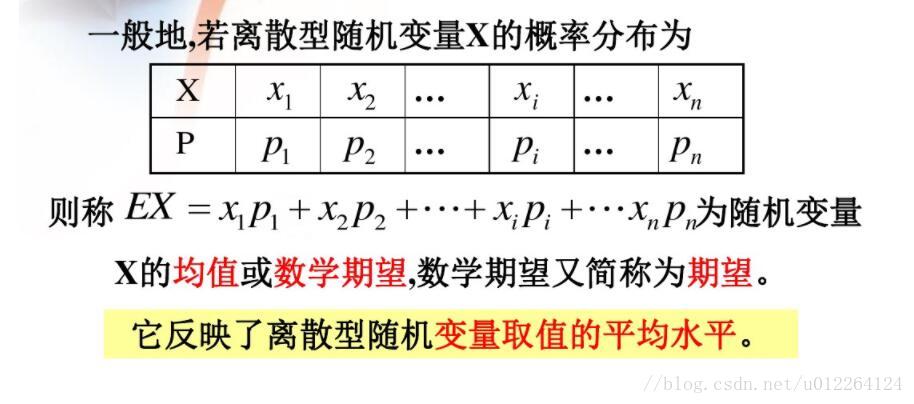
# 摘要
随机过程是概率论的一个重要分支,被广泛应用于各种工程和科学领域中。本文全面介绍了随机过程的基本概念、分类、概率分析、关键理论、模拟实现以及实践应用指南。从随机变量的基本统计特性讲起,深入探讨了各类随机过程的分类和特性,包括马尔可夫过程和泊松过程。文章重点分析了随机过程的概率极限定理、谱分析和最优估计方法,详细解释了如何通过计算机模拟和仿真软件来实现随机过程的模拟。最后,本文通过工程问题中随机过程的实际应用案例,以
【QSPr高级应用案例】:揭示工具在高通校准中的关键效果
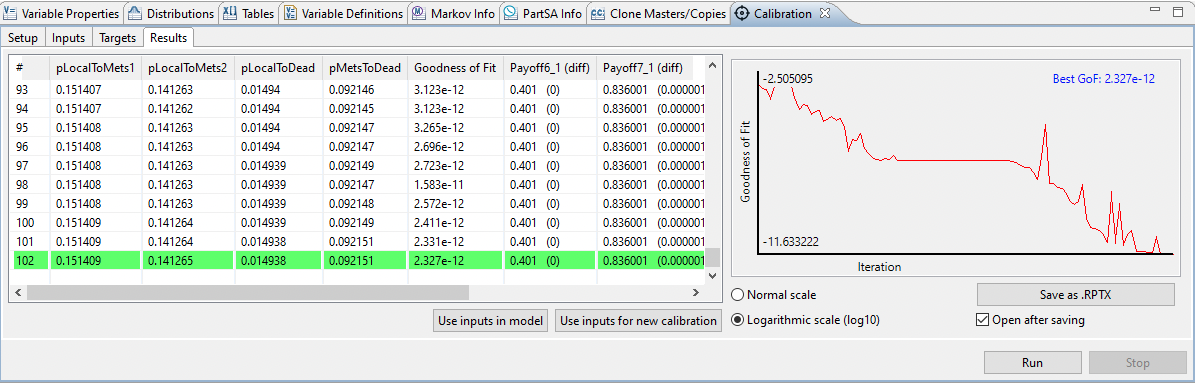
# 摘要
本论文旨在介绍QSPr工具及其在高通校准中的基础和应用。首先,文章概述了QSPr工具的基本功能和理论框架,探讨了高通校准的重要性及其相关标准和流程。随后,文章深入分析了QSPr工具的核心算法原理和数据处理能力,并提供了实践操作的详细步骤,包括数据准备、环境搭建、校准执行以及结果分析和优化。此外,通过具体案例分析展示了QSPr工具在不同设备校准中的定制
Tosmana配置精讲:一步步优化你的网络映射设置

# 摘要
Tosmana作为一种先进的网络映射工具,为网络管理员提供了一套完整的解决方案,以可视化的方式理解网络的结构和流量模式。本文从基础入门开始,详细阐述了网络映射的理论基础,包括网络映射的定义、作用以及Tosmana的工作原理。通过对关键网络映射技术的分析,如设备发现、流量监控,本文旨在指导读者完成Tosmana网络映射的实战演练,并深入探讨其高级应用,包括自动化、安全威胁检测和插件应用。最
【Proteus与ESP32】:新手到专家的库添加全面攻略

# 摘要
本文详细介绍Proteus仿真软件和ESP32微控制器的基础知识、配置、使用和高级实践。首先,对Proteus及ESP32进行了基础介绍,随后重点介绍了在Proteus环境下搭建仿真环境的步骤,包括软件安装、ESP32库文件的获取、安装与管理。第三章讨论了ESP32在Proteus中的配置和使用,包括模块添加、仿真
【自动控制系统设计】:经典措施与现代方法的融合之道
# 摘要
自动控制系统是工业、航空、机器人等多个领域的核心支撑技术。本文首先概述了自动控制系统的基本概念、分类及其应用,并详细探讨了经典控制理论基础,包括开环和闭环控制系统的原理及稳定性分析方法。接着,介绍了现代控制系统的实现技术,如数字控制系统的原理、控制算法的现代实现以及高级控制策略。进一步,本文通过设计实践,阐述了控制系统设计流程、仿真测试以及实际应用案例。此外,分析了自动控制系统设计的当前挑战和未
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )