【情感计算与人机交互】:AI理解人类情感的前沿技术与挑战
发布时间: 2024-12-16 22:28:49 订阅数: 3 

百度-人工智能 AI 人机交互趋势研究报告-综合文档

参考资源链接:[人工智能及其应用:课后习题详解](https://wenku.csdn.net/doc/2mui54aymf?spm=1055.2635.3001.10343)
# 1. 情感计算与人机交互概述
在当今数字化时代,人机交互(HCI)已经不仅仅是基于功能性和效率的对话,而是正朝着更加自然和情感化的方向发展。情感计算作为这一趋势的核心技术之一,它允许计算机理解和解析用户的情绪状态,并作出相应的反馈,从而提升用户体验并开辟全新的交互方式。
情感计算涉及多个学科,包括心理学、计算机科学和人工智能等。它不仅包括了对用户情绪状态的分析,如喜怒哀乐等,还包括了机器对于这些情绪的理解和适应,以及能够在交互过程中模拟人类情感反应的能力。
为了实现情感计算,系统需要集成高级的感知技术来捕获用户的情绪信号,如语音、面部表情、生理信号等,并通过数据挖掘、机器学习和人工智能算法来进行情感分析和处理。这一过程需要系统具备高度的智能和学习能力,以精确地响应人类的情感需求。随着技术的进步,情感计算与人机交互的结合,正在开启创新应用的新浪潮。
# 2. 情感识别技术基础
## 2.1 情感识别的技术分类
情感识别技术是情感计算的核心部分,它能够使机器理解人类的情感状态。情感识别技术可以从不同的感官渠道提取信息,从而识别个体的情绪状态。按照技术手段的不同,情感识别可以分为以下几类:
### 2.1.1 声音与语音分析
语音是情感表达的重要途径,通过分析语音信号,可以提取出许多有关情感状态的特征,如音调、音量、语速、语调等。利用这些特征,机器可以识别出说话者的情绪。
```python
import librosa
import numpy as np
# 加载音频文件
audio_path = 'example_audio.wav'
y, sr = librosa.load(audio_path)
# 提取音高特征
pitch = librosa.yin(y, sr)
# 计算音高变化率
pitch_diff = np.diff(pitch)
# 输出音高特征和音高变化率的平均值,用于后续的情感分析
print("Average Pitch:", np.mean(pitch))
print("Average Pitch Diff:", np.mean(pitch_diff))
```
在上述代码中,我们使用`librosa`库来加载音频文件并计算音高特征。在实际的情感识别系统中,这些特征会被输入到分类器中,以便识别出情感状态。
### 2.1.2 视觉与面部表情分析
面部表情是表达情感最直观的方式之一。通过分析视频或图片中的面部表情,机器可以识别人物的情感状态。常见的面部表情分析方法包括使用预训练的人脸检测模型(如OpenCV、Dlib等),进而进行表情识别。
```python
import cv2
import dlib
# 使用Dlib的面部检测模型
detector = dlib.get_frontal_face_detector()
# 加载图像
image_path = 'example_image.jpg'
image = cv2.imread(image_path)
# 转换图像到灰度
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
# 检测图像中的面部
rects = detector(gray, 1)
# 对于每个检测到的面部,可以进一步分析其表情特征
for (i, rect) in enumerate(rects):
x1 = rect.left()
y1 = rect.top()
x2 = rect.right()
y2 = rect.bottom()
# 在原图上绘制矩形框
cv2.rectangle(image, (x1, y1), (x2, y2), (0, 255, 0), 2)
# 显示检测结果
cv2.imshow('Face Detection', image)
cv2.waitKey(0)
cv2.destroyAllWindows()
```
在该示例代码中,我们使用了Dlib的预训练模型来检测面部,为下一步的情感识别分析做准备。
## 2.2 数据收集与预处理方法
### 2.2.1 数据采集渠道与工具
为了进行有效的情感分析,首先需要采集足够的数据。数据采集渠道包括但不限于社交媒体、在线调查、实验记录等。相应地,数据收集工具可能包括API(如Twitter API、Facebook API),或者专业的音频/视频记录设备等。
### 2.2.2 数据清洗和特征提取
数据清洗是数据预处理的一个重要环节。它涉及去除噪声、填补缺失值、数据归一化等。特征提取则关注于从原始数据中提取有用信息,例如对音频信号进行傅里叶变换,或者对图像数据提取边缘特征等。
```python
# 假设data是一个包含原始数据的Pandas DataFrame
# 对数据进行预处理的伪代码
import pandas as pd
from sklearn.preprocessing import MinMaxScaler
# 数据清洗
data.dropna(inplace=True) # 去除缺失值
data.fillna(method='ffill', inplace=True) # 前向填充
# 特征提取
# 假设我们使用FFT(快速傅里叶变换)作为音频特征
fft_data = np.fft.fft(data['audio_signal'])
magnitude = np.abs(fft_data) # 计算幅度谱
# 归一化特征
scaler = MinMaxScaler()
normalized_features = scaler.fit_transform(magnitude)
# 将特征添加到数据中
data['fft_magnitude'] = normalized_features
```
在实际操作中,特征提取需要根据情感识别的需求定制,如声音的情感特征提取可能包括基频、共振峰等。
## 2.3 模型训练与验证
### 2.3.1 机器学习算法的选用
机器学习算法在情感识别中的选择取决于数据的类型和质量。常见的算法包括支持向量机(SVM)、随机森林、神经网络等。选择合适算法可以提高识别的准确性。
### 2.3.2 模型验证与优化技术
模型验证通常使用交叉验证、保留验证集等技术来评估模型的泛化能力。优化技术包括调整模型参数、使用集成学习等策略来提高模型性能。
```python
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
# 假设我们已经得到了特征数据X和标签y
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
# 使用随机森林进行分类
clf = RandomForestClassifier(n_estimators=100)
clf.fit(X_train, y_train)
# 使用测试集进行验证
accuracy = clf.s
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
《人工智能及其应用》专栏提供深入的知识和见解,涵盖人工智能的各个方面。从机器学习到深度学习的技术演进,到工业界人工智能应用的实战案例,专栏探索了人工智能的最新进展。它还探讨了人工智能伦理和法规的平衡点,以及人工智能在计算机视觉、大数据、推荐系统、硬件加速、情感计算和人机交互等领域的应用。此外,专栏还提供了构建智能推荐系统和优化神经网络的实用技巧,并为人工智能创业提供了全面的指南。通过专家分析和实际案例,该专栏旨在帮助读者了解人工智能的潜力,并为其在各种行业中的应用做好准备。
专栏目录

文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【ADS滤波器设计全攻略】:新手必备的12个基础知识
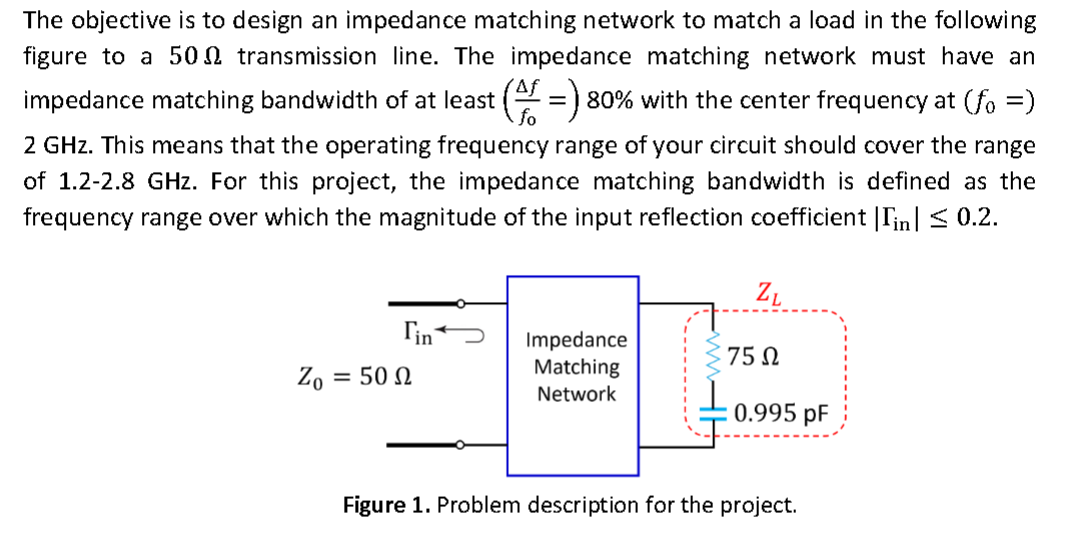
参考资源链接:[ads 差分滤波器设计及阻抗匹配](https://wenku.csdn.net/doc/6412b59abe7fbd1778d43bd8?spm=1055.2635.3001.10343)
# 1. ADS滤波器设计概述
在无线通信、雷达系统以及信号处理领域,滤波器是实现信号选择性传输的核心组件。ADS(Advanced Design System)是一款功能强大的
【模拟信号转数字】:电压电流信号采集技术要点,让你秒变数据采集高手
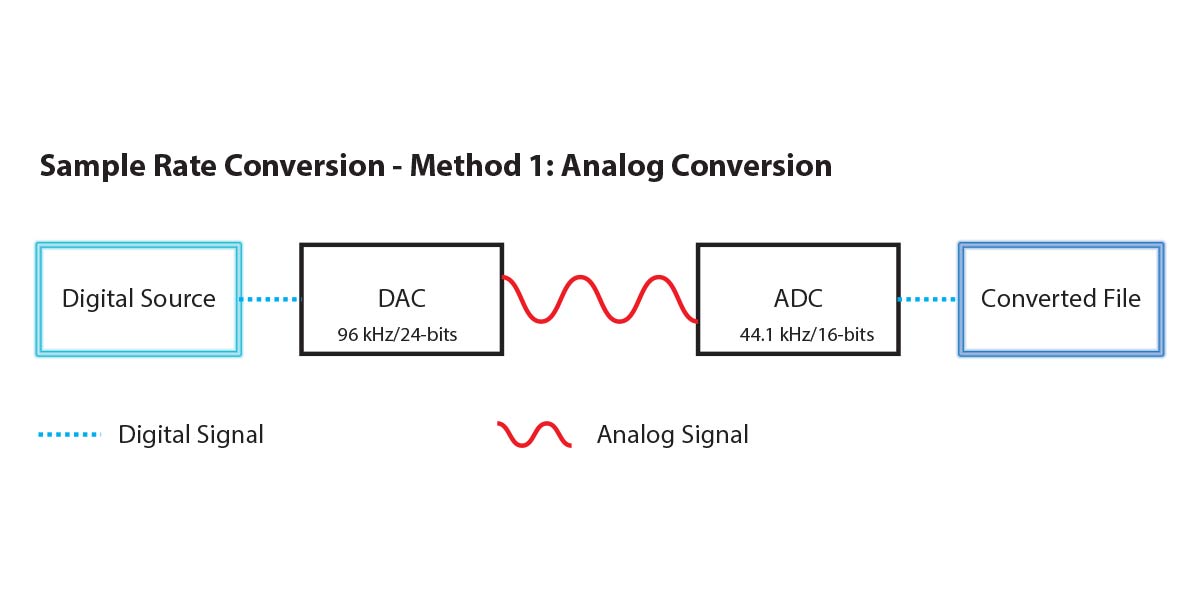
参考资源链接:[STM32 ADC应用:太阳能电池板电压电流监测与数码管显示](https://wenku.csdn.net/doc/6412b75abe7fbd1778d49fed?spm=1055.2635.3001.10343)
# 1. 模拟信号与数字信号的基本概念
## 1.1 模拟信号的特性
模拟信号是时间连续且值连续的信号,它们可以通过连续变化的电压或电流来表示信息,例如人的声音和乐器的声音在麦克风中转换为电信
【CUDA vs OpenCL】:深度剖析选择GPGPU框架的决定性因素
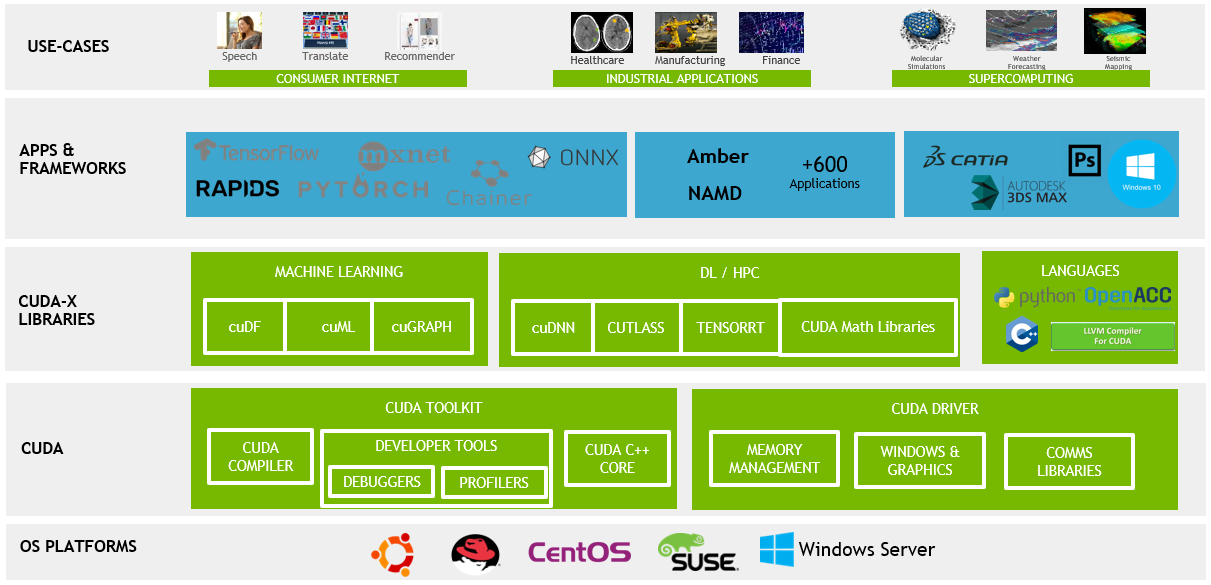
参考资源链接:[GPGPU编程模型与架构解析:CUDA、OpenCL及应用](https://wenku.csdn.net/doc/5pe6wpvw55?spm=1055.2635.3001.10343)
# 1. CUDA与OpenCL框架概述
## 1.1 GPU计算的崛起
随着计算需求的不断提升,GPU(图形处理单元)已从单纯的图形渲染扩展到科学
Ambarella H22芯片全解析:如何在90天内实现性能跃升与系统优化
参考资源链接:[Ambarella H22芯片规格与特性:低功耗4K视频处理与无人机应用](https://wenku.csdn.net/doc/6401abf8cce7214c316ea27b?spm=1055.2635.3001.10343)
# 1. Ambarella H22芯片概述
Ambarella H22是一款先进的SoC芯片,它在视觉处理和A
STM32F4中断系统高级配置:库函数下的高效调试方法

参考资源链接:[STM32F4开发指南-库函数版本_V1.1.pdf](https://wenku.csdn.net/doc/6460ce9e59284
博通 WIFI6芯片调试技巧:专家级别的问题解决与调优秘籍
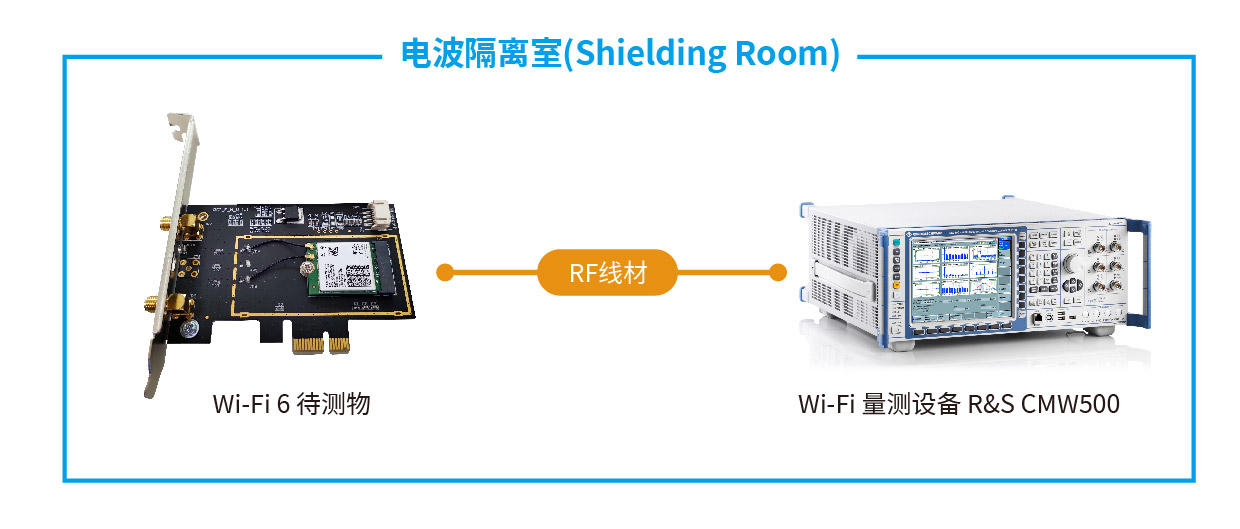
参考资源链接:[博通BCM6755:高性能WIFI6 SoC芯片详析](https://wenku.csdn.net/doc/595ytnkk26?spm=1055.2635.3001.10343)
# 1. WIFI6技术概述与芯片介绍
## WIFI6技
跨平台办公新时代:LibreOffice 7.1.8 AArch64的变革性体验
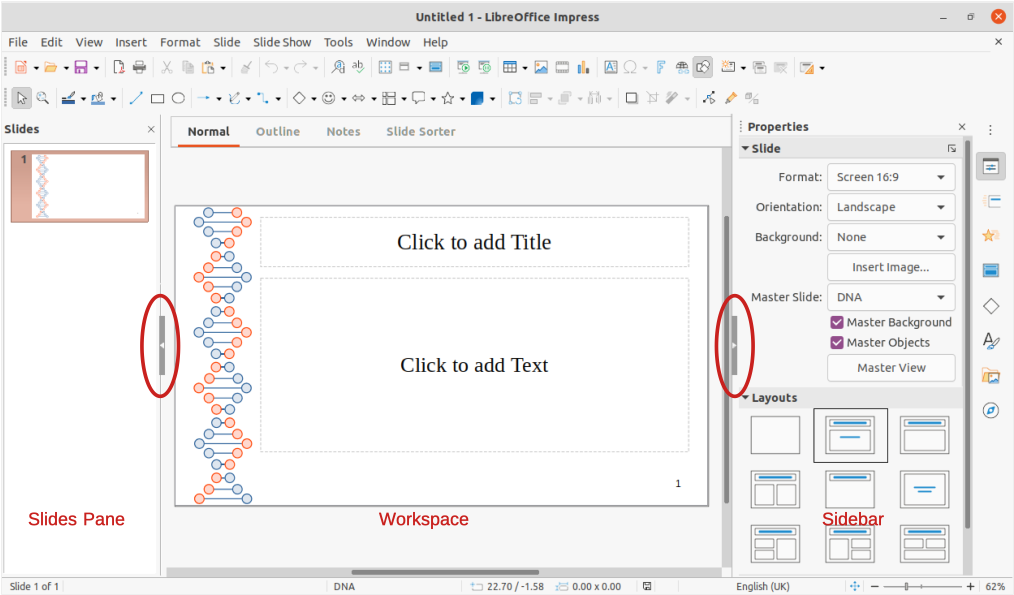
参考资源链接:[ARM架构下libreoffice 7.1.8预编译安装包](https://wenku.csdn.net/doc/2fg8nrvwtt?spm=1055.2635.3001.10343)
# 1. LibreOffice 7.1.8 AArch64简介
LibreOff
【版图设计实战】:CMOS反相器版图的先进工艺趋势与自动化工具应用
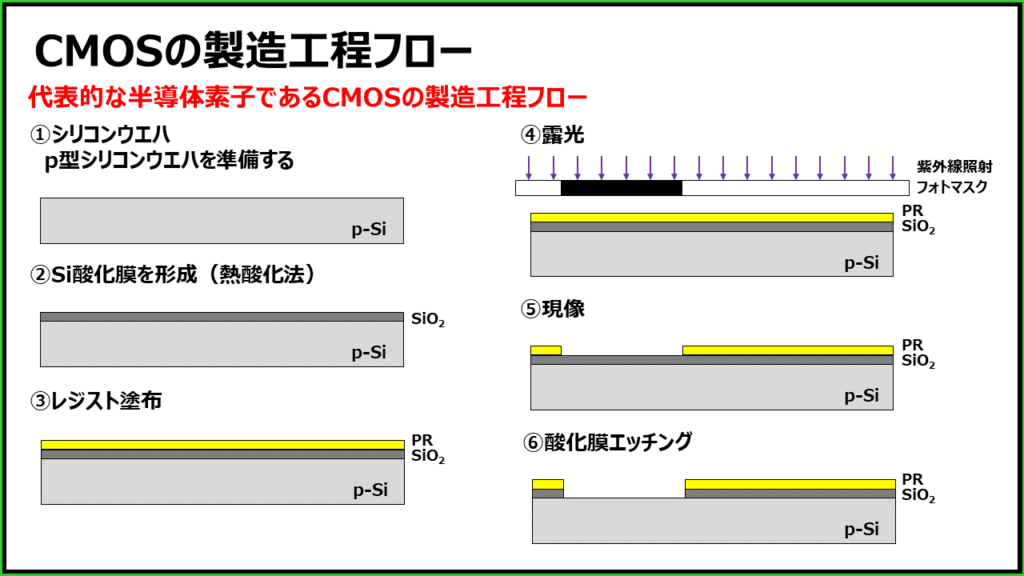
参考资源链接:[CMOS反相器版图设计原理与步骤](https://wenku.csdn.net/doc/7d3axkm5es?spm=1055.2635.3001.10343)
# 1. CMOS反相器的基础原理
## CMOS反相器简介
CMOS(Complementary Metal-Oxide-Semiconductor)反相器是数字集成电路中最基本
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )