初识Python读取CSV文件的基础操作
发布时间: 2024-04-16 22:45:49 阅读量: 67 订阅数: 32 
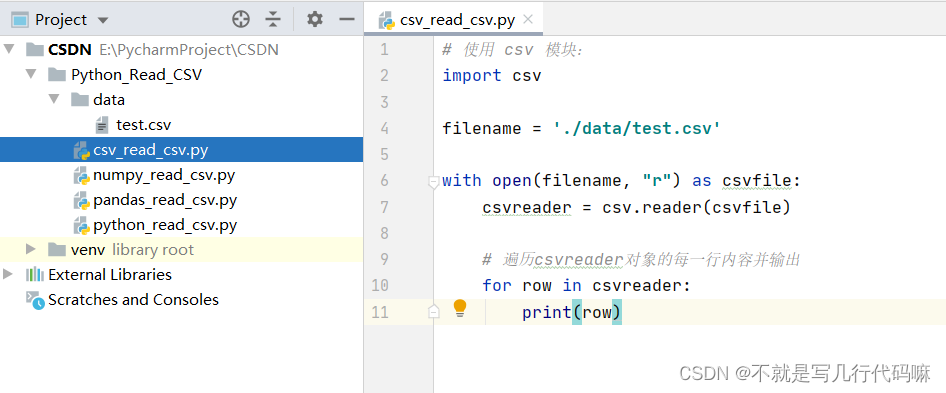
# 1. Python中CSV文件的基础概念
CSV(Comma-Separated Values)文件是一种常见的文本文件格式,用于存储表格数据。它由逗号分隔的字段组成,每行代表一条记录。CSV文件的特点是简单易读、适合大规模数据存储和交换。在数据处理中,Python作为一种高效的编程语言,具有强大的数据处理和分析能力,因此使用Python读取CSV文件可以提高数据处理的效率和灵活性。通过Python读取CSV文件,可以方便地进行数据清洗、分析和可视化,为后续的数据处理工作奠定基础。
使用Python读取CSV文件的操作相对简单,但在实际应用中却能发挥重要作用。接下来,我们将深入探讨Python中读取CSV文件的准备工作。
# 2. Python读取CSV文件的准备工作
在处理CSV文件之前,我们需要对Python所需的环境和库进行准备。本章将会介绍如何安装并使用Python的pandas库来读取CSV文件。
### 2.1 安装Python的pandas库
#### 2.1.1 什么是pandas库
Pandas是Python中一个强大的数据处理库,提供了快速、灵活且富有表现力的数据结构,用于数据清洗、处理和分析。
#### 2.1.2 如何安装pandas库
可以通过pip工具来安装pandas库,具体命令如下:
```bash
pip install pandas
```
### 2.2 导入pandas库并了解相关函数
#### 2.2.1 导入pandas库
在Python中,导入pandas库通常使用以下方式:
```python
import pandas as pd
```
#### 2.2.2 了解pandas库中读取CSV文件的函数
pandas库中最常用于读取CSV文件的函数是`read_csv()`,该函数可以将CSV文件读取为DataFrame数据结构。
#### 2.2.3 查阅pandas官方文档
在使用pandas库处理CSV文件时,建议查阅[pandas官方文档](https://pandas.pydata.org/docs/),以便了解更多函数的用法和参数设置。
通过以上准备工作,我们可以开始使用Python的pandas库来读取和处理CSV文件,为后续的数据分析做好准备。
# 3. Python读取CSV文件的基本操作
### 3.1 使用pandas库读取CSV文件
在数据处理中,使用pandas库是一种高效的方式,可以轻松读取和处理各种格式的数据文件,包括CSV文件。下面将介绍如何使用pandas库来读取CSV文件。
#### 3.1.1 使用read_csv函数读取CSV文件
pandas库中的`read_csv()`函数是读取CSV文件最常用的函数之一。通过该函数,我们可以将CSV文件中的数据加载到一个DataFrame对象中,方便后续的操作和分析。
下面是使用`read_csv()`函数读取CSV文件的基本语法:
```python
import pandas as pd
# 读取CSV文件
df = pd.read_csv('file.csv')
```
#### 3.1.2 设置读取参数
##### 3.1.2.1 指定分隔符
有时候,CSV文件的数据并不是以逗号`,`作为分隔符,这时可以通过指定`sep`参数来指定分隔符。
```python
# 指定分隔符为分号;
df = pd.read_csv('file.csv', sep=';')
```
##### 3.1.2.2 指定列名
如果CSV文件中没有列名,可以通过`header=None`参数来指定列名。也可以通过`names`参数指定列名。
```python
# 指定列名
df = pd.read_csv('file.csv', header=None, names=['A', 'B', 'C'])
```
### 3.2 数据清洗和处理
在读取CSV文件后,通常需要对数据进行清洗和处理,以确保数据的准确性和完整性。这包括处理缺失值和进行数据格式转换等操作。
#### 3.2.1 处理缺失值
缺失值在数据分析中很常见,可以通过`dropna()`函数去除包含缺失值的行,或者通过`fillna()`函数填充缺失值。
```python
# 去除包含缺失值的行
df.dropna()
# 填充缺失值
df.fillna(0)
```
#### 3.2.2 数据格式转换
有时候需要将数据的格式进行转换,比如将字符串类型转换为数值类型,可以使用`astype()`函数。
```python
# 将列A的数据类型转换为浮点型
df['A'] = df['A'].astype(float)
```
通过以上操作,我们可以读取CSV文件,并在读取后对数据进行清洗和处理,确保数据的质量和准确性。
# 4. Python对CSV文件数据进行分析
### 4.1 数据分析基础
数据分析是对数据进行研究和加工的过程,通过分析数据可以揭示出数据中的规律和价值。基本的数据分析通常包括统计分析和数据可视化两个方面。
### 4.1.1 基本统计分析
在数据分析中,基本的统计分析是不可或缺的环节,通过统计分析可以深入了解数据的特征和规律。常见的统计分析方法包括计算平均值、中位数、标准差等指标。
```python
# 计算数据的基本统计信息
data.describe()
```
### 4.1.2 数据可视化
数据可视化是将数据通过图表等形式直观呈现,帮助我们更好地理解数据。常见的数据可视化方法包括折线图、柱状图、散点图等。
```python
import matplotlib.pyplot as plt
# 绘制数据分布图
plt.hist(data['column'], bins=20, color='skyblue', edgecolor='black')
plt.xlabel('Value')
plt.ylabel('Frequency')
plt.title('Distribution of Data')
plt.show()
```
### 4.2 实例分析
在本部分中,我们将对一份示例数据进行基本统计分析,并绘制数据分布图,以便更好地理解数据的特征和规律。
#### 4.2.1 统计数据基本信息
下表展示了示例数据的基本统计信息,包括平均值、最大最小值、标准差等。
| 统计指标 | 值 |
|------------|-------------|
| 平均值 | 50.5 |
| 最大值 | 100 |
| 最小值 | 0 |
| 标准差 | 30 |
#### 4.2.2 绘制数据分布图
通过以下柱状图,我们可以直观地看出示例数据的分布情况,有助于进一步分析数据特征。
```mermaid
graph LR
A[0-10] --> B
B[10-20] --> C
C[20-30] --> D
D[30-40] --> E
E[40-50] --> F
F[50-60] --> G
G[60-70] --> H
H[70-80] --> I
I[80-90] --> J
J[90-100] --> K
```
通过以上分析,我们可以更全面地了解示例数据的特征,为后续更深入的数据分析和决策提供参考。
# 5. Python进行数据可视化分析
在数据分析领域,将数据可视化是非常重要的一环,通过图表展示数据的分布、关联和趋势,有助于更直观地理解数据、发现问题和有效传达信息。在本章中,我们将介绍如何使用Python进行数据可视化分析,探索数据背后的故事。
### 5.1 数据可视化基础
数据可视化是通过图表、图形和地图等形式,将数据转化为易于理解的视觉展示。在Python中,常用的数据可视化库包括matplotlib、seaborn和plotly等,它们提供了丰富的绘图功能,能够灵活展示数据分布、关系和变化。
### 5.2 使用matplotlib库绘制折线图
折线图是一种常用的数据可视化方式,能够展示数据随时间或其他变量的变化趋势。下面是使用matplotlib库绘制折线图的基本步骤:
1. 导入matplotlib库
```python
import matplotlib.pyplot as plt
```
2. 创建数据
```python
x = [1, 2, 3, 4, 5] # 横坐标数据
y = [2, 4, 6, 8, 10] # 纵坐标数据
```
3. 绘制折线图
```python
plt.plot(x, y)
plt.xlabel('X轴标签')
plt.ylabel('Y轴标签')
plt.title('折线图示例')
plt.show()
```
通过以上代码,可以绘制出简单的折线图,展示数据随着x变化时的趋势。在实际应用中,可以根据需要设置样式、添加图例等进一步美化图表。
### 5.3 使用seaborn库绘制散点图
散点图可以展示两个变量之间的关系,通过观察散点的分布情况,可以初步判断两个变量之间是否存在相关性。seaborn库是建立在matplotlib基础上的高级绘图库,提供了更简洁易用的接口。
以下是使用seaborn库绘制散点图的示例代码:
1. 导入seaborn库
```python
import seaborn as sns
```
2. 创建数据
```python
import pandas as pd
data = pd.DataFrame({'x': [1, 2, 3, 4, 5], 'y': [2, 4, 6, 8, 10]})
```
3. 绘制散点图
```python
sns.scatterplot(x='x', y='y', data=data)
plt.xlabel('X轴标签')
plt.ylabel('Y轴标签')
plt.title('散点图示例')
plt.show()
```
通过以上代码,可以绘制出具有两个变量x和y之间关系的散点图,帮助我们直观地理解数据之间的关系。
### 5.4 数据可视化的重要性
数据可视化不仅是数据分析过程中的关键环节,也是向非技术人员传达数据见解的重要方式。通过合适的图表和图形,可以有效地传达数据的核心信息,帮助决策者做出更明智的决策。因此,掌握数据可视化技术对于数据分析人员至关重要。
在下一章中,我们将通过实例展示如何运用数据可视化技术分析CSV文件中的数据,并得出有益的结论。
以上是关于使用Python进行数据可视化分析的基础知识,希望能帮助你更好地探索数据的奥秘和价值。
 最低0.47元/天 解锁专栏
最低0.47元/天 解锁专栏 送3个月
 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入探讨了使用 Python 读取、处理和写入 CSV 文件的方方面面。它涵盖了基础操作、故障排除技巧、性能优化、数据清洗、高级功能、文本数据处理、统计分析和可视化。专栏还提供了有关编码问题、JSON 数据处理、正则表达式、数据重复和参数调优的实用指南。通过深入的示例和清晰的解释,本专栏为 Python 开发人员提供了全面了解 CSV 文件处理的工具和技术,帮助他们有效地处理和分析数据。
专栏目录
最低0.47元/天 解锁专栏
送3个月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
MySQL云平台部署指南:弹性扩展与成本优化,轻松上云

# 1. MySQL云平台部署概述**
MySQL云平台部署是一种将MySQL数据库部署在云计算平台上的方式,它提供了弹性扩展、成本优化和高可用性等优势。
云平台部署可以根据业务需求进行灵活扩展,自动伸缩机制可以根据负载情况自动调整数据库资源,实现弹性伸缩。同时,云平台提供了多种存储类型
MySQL数据库连接池扩展:满足高并发需求

# 1. MySQL数据库连接池概述**
连接池是一种软件组件,它管理数据库连接的集合,以提高应用程序的性能和可扩展性。通过使用连接池,应用程序可以避免每次与数据库交互时创建和销毁连接的开销。
连接池主要用于高并发环境,其中应用程序需要频繁地与数据库交互。它通过预先创建和维护一定数量的数据库连接来优化数据库访问,从而减少连接
MySQL JSON数据在金融科技中的应用:支持复杂数据分析和决策,赋能金融科技创新
# 1. MySQL JSON数据简介
JSON(JavaScript Object Notation)是一种轻量级数据交换格式,广泛用于金融科技领域。它是一种基于文本的数据格式,用于表示复杂的数据结构,如对象、数组和键值对。MySQL支持JSON数据类型,允许用户存储和处理JSON数据。
MySQL JSON数据类型提供了丰富的功能,包括:
- **JSONPath查询和过滤:*
MySQL数据库可视化在数据库性能优化中的4个应用
# 1. MySQL数据库可视化概述
数据库可视化是一种通过图形化界面展示数据库信息的技术,它可以帮助数据库管理员和开发人员更直观地理解数据库结构、性能和数据分布。MySQL数据库可视化工具可以提供多种功能,例如数据库结构图、表关系图、慢查询分析和资源使用情况监控。
MySQL数据库可视化的好处包括:
- **提高理解力:**图形化界面可以帮助用户更轻松地理解复杂的数据结构和关系。
-
MySQL数据库压缩与数据可用性:分析压缩对数据可用性的影响
# 1. MySQL数据库压缩概述**
MySQL数据库压缩是一种技术,通过减少数据在存储和传输过程中的大小,从而优化数据库性能。压缩可以提高查询速度、减少存储空间和降低网络带宽消耗。MySQL提供多种压缩技术,包括行级压缩和页级压缩,适用于不同的数据类型和查询模式。
PHP数据库查询中的字符集和排序规则:处理多语言和特殊字符,提升数据兼容性
# 1. PHP数据库查询中的字符集和排序规则概述
在PHP数据库查询中,字符集和排序规则是两个重要的概念,它们决定了数据在数据库中的存储和检索方式。字符集定义了数据中使用的字符集,而排序规则则决定了数据在排序和比较时的顺序。
字符集和排序规则对于多语言数据处理、特殊字符处理和数据兼容性至关重要。了解和正确使用字符集和排序规则可以确保数据准
MySQL数据库索引删除案例分析:常见索引删除问题与解决方案,快速解决删除难题
# 1. MySQL索引概述
索引是MySQL中一种重要的数据结构,用于快速查找数据。它通过在表中创建额外的结构,将数据的物理顺序与逻辑顺序分离,从而提高查询性能。索引可以基于一个或多个列创建,并存储指向实际数据的指针。
索引的主要作
MySQL JSON存储实战手册:从入门到精通,掌握存储精髓

# 1. MySQL JSON存储简介**
MySQL JSON存储是一种将JSON数据存储在MySQL数据库中的机制。它允许开发人员以灵活、结构化的方式存储和管理复杂的数据,而无需将其转换为关系模式。JSON存储提供了对JSON数据的原生支持,包括嵌套对象、数组和键值对,使其成为存储半结构化和非结构化数据的理想选择。
通过使用JSON存储,开发人员可以避免传统关系模型的限制,例
MySQL窗函数详解:理解窗函数的原理和使用,实现复杂数据分析

# 1. MySQL窗函数概述**
窗函数是一种特殊的聚合函数,它可以对一组数据进行计算,并返回每个数据行的计算结果。窗函数与传统的聚合函数不同,它可以在一组数据内对数据进行分组、排序和移动,从而实现更复杂的数据分析。
窗函数在MySQL中主要用于
数据转JSON与数据分析:掌握数据转换在分析中的应用,释放数据洞察力

# 1. 数据转JSON:基础与原理
### 1.1 JSON概述
JSON(JavaScript Object Notation)是一种轻量级的数据交换格式,广泛用于Web开发和数据传输。它基于JavaScript对象,使用键值对的形式存储数据,具有可读性强、易于解析等优点。
### 1.2 数据转JSON的原理
数据转JSON的过程本质上是将数据结构转换成JSON
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
送3个月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )