Metasploit 控制台的高级使用技巧
发布时间: 2024-01-08 20:29:54 阅读量: 52 订阅数: 30 
# 1. 简介
## 1.1 Metasploit 控制台的作用和重要性
Metasploit 控制台是 Metasploit 框架中的一个重要组件,它提供了一个交互式的命令行界面,用于执行渗透测试和安全评估。它被广泛用于网络安全专业人员进行系统漏洞扫描、渗透攻击和后渗透操作。
Metasploit 控制台的主要作用包括:
- 实施目标系统的渗透测试:通过利用系统漏洞,获取目标系统的控制权,以评估系统的安全性。
- 提供高级扫描功能:Metasploit 控制台可以进行主机扫描、漏洞扫描和信息收集,帮助寻找目标系统的弱点和漏洞。
- 自动化攻击过程:Metasploit 控制台内置了众多的渗透攻击模块,可以自动化执行攻击过程,提高攻击效率。
## 1.2 Metasploit 控制台的基本使用方法和界面介绍
Metasploit 控制台的基本使用方法如下:
1. 启动控制台:在终端或命令提示符窗口中输入`msfconsole`命令启动 Metasploit 控制台。
2. 显示模块列表:输入`show modules`命令可以显示 Metasploit 框架中可用的模块列表。模块包括扫描模块、攻击模块、提权模块等。
3. 选择模块:使用`use`命令加模块路径选择需要使用的模块。例如,`use exploit/windows/smb/ms08_067_netapi`选择了 Windows SMB MS08-067 漏洞攻击模块。
4. 配置模块参数:使用`set`命令来设置模块的参数值,例如设置目标主机的 IP 地址和端口号。
5. 运行模块:使用`exploit`命令来运行模块。根据模块的功能,可能需要提前进行一些准备工作,如扫描目标主机,获取目标信息等。
6. 查看结果:模块执行完毕后,可以使用`show options`命令查看模块的可配置参数和结果,使用`sessions`命令查看当前会话信息。
Metasploit 控制台的界面由命令行和交互式提示符组成,命令行用于输入指令,提示符用于交互和显示执行结果。控制台界面通常包括当前使用的模块路径、当前会话信息、历史命令记录等部分。
# 2. 高级扫描技巧
在 Metasploit 控制台中,我们不仅可以进行基本的主机扫描,还可以利用多种模块进行漏洞扫描和渗透测试。本章将介绍一些高级的扫描技巧,包括主机扫描,漏洞扫描和信息收集。
### 2.1 使用 Metasploit 控制台进行主机扫描
Metasploit 提供了强大的扫描功能,可以用来探测网络中的活动主机。通过主机扫描,我们可以快速了解目标网络的拓扑结构和主机存活情况。
```ruby
msf > use auxiliary/scanner/discovery/arp_sweep
msf auxiliary(arp_sweep) > set RHOSTS 192.168.0.0/24
msf auxiliary(arp_sweep) > run
```
以上代码展示了如何使用 `arp_sweep` 模块对 `192.168.0.0/24` 网段进行主机扫描。其中 `RHOSTS` 参数可以指定待扫描的目标 IP 地址范围。执行 `run` 命令后,Metasploit 将会自动进行主机扫描,并输出扫描结果。
### 2.2 利用模块进行漏洞扫描和渗透测试
Metasploit 还提供了大量的漏洞扫描和渗透测试模块,可以用于发现目标系统的漏洞并利用其进行渗透攻击。
```ruby
msf > use auxiliary/scanner/http/nmap_http_sickbeard
msf auxiliary(nmap_http_sickbeard) > set RHOSTS 192.168.0.100
msf auxiliary(nmap_http_sickbeard) > set THREADS 10
msf auxiliary(nmap_http_sickbeard) > run
```
以上代码展示了如何使用 `nmap_http_sickbeard` 模块对单个主机进行漏洞扫描。通过设置 `RHOSTS` 参数指定目标 IP 地址,以及 `THREADS` 参数设定扫描线程数量,可以加快扫描速度。执行 `run` 命令后,Metasploit 将会对目标主机进行漏洞扫描,并输出扫描结果。
### 2.3 如何进行信息收集和目标识别
信息收集和目标识别是渗透测试的重要步骤,Metasploit 提供了多种模块来辅助我们进行这些任务。
```ruby
msf > use auxiliary/gather/enum_domain
msf auxiliary(enum_domain) > set DOMAIN example.com
msf auxiliary(enum_domain) > run
```
以上代码展示了如何使用 `enum_domain` 模块对域名 `example.com` 进行信息收集和目标识别。通过设置 `DOMAIN` 参数指定目标域名,执行 `run` 命令后,Metasploit 将会自动收集目标域名的相关信息,并输出结果。
通过上述高级扫描技巧,我们可以更准确地了解目标网络的情况,并为后续的渗透攻击做好准备。接下来,我们将介绍如何利用 Metasploit 控制台进行入侵和渗透攻击。
该章节详细介绍了使用Metasploit进行高级扫描技巧的方法和示例代码。包含了探测网络中的活动主机、漏洞扫描和渗透测试等内容,读者可以根据具体的目标网络情况选择合适的模块完成相应的任务。
# 3. 入侵技巧和渗透攻击
在本章中,我们将介绍如何使用 Metasploit 控制台进行入侵技巧和渗透攻击。Metasploit 提供了多种高级功能和模块,用于执行各种渗透攻击。以下是本章的具体

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏将全面介绍Kali Linux操作系统及其强大的渗透测试框架Metasploit。通过文章的逐一讲解,读者将了解Kali Linux的简介与安装,掌握Metasploit的基本用法以及框架的模块与插件。此外,专栏还涵盖了Metasploit利用模块的分类与使用、控制台的高级技巧、免杀与绕过安全防护、持久化与后门技术、自定义模块与脚本的编写,以及特定目标渗透测试技巧。此外,还将重点讲解Metasploit在无线网络渗透和Web应用渗透中的应用。通过本专栏,读者将获得从入门到实战的全面知识,掌握Kali Linux与Metasploit的强大功能,为日后的渗透测试工作提供有力支持。
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【从零开始学Verilog】:如何在Cadence中成功搭建第一个项目

# 摘要
本文旨在提供一个全面的Verilog语言和Cadence工具使用指南,涵盖了从基础入门到项目综合与仿真的深入应用。第一章介绍了Verilog语言的基础知识,包括基本语法和结构。第二章则深入讲解了Cadence工具的使用技巧,包括界面操作、项目管理和设计库应用。第三章专注于在Cadence环境中构建和维护Verilog项目,着重讲述了代码编写、组织和集成。第四章探讨
微服务架构精要:实现高质量设计与最佳实践
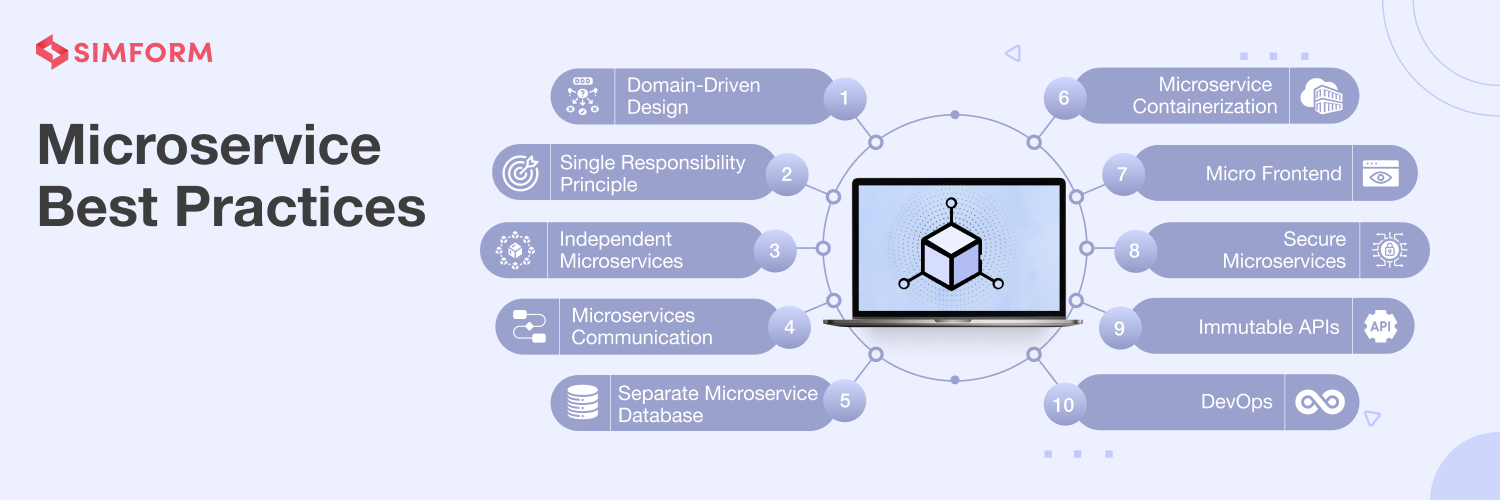
# 摘要
微服务架构作为一种现代化的软件开发范式,以其模块化、灵活性和可扩展性优势正逐渐成为企业级应用开发的首选。本文从基本概念入手,深入探讨了微服务的设计原则与模式、持续集成和部署策略、以及安全、测试与优化方法。通过对微服务架构模式的详细介绍,如API网关、断路器、CQRS等,文章强调了微服务通信机制的重要性。同时,本文还分析了微服务在持续集成和自动化部署中的实践,包括容器化技术的应用和监控、日志管理。此
【快速定位HMI通信故障】:自由口协议故障排查手册

# 摘要
自由口协议作为工业通信中的关键组件,其基础、故障定位及优化对于保证系统的稳定运行至关重要。本文首先介绍了自由口协议的基本原理、标准与参数配置以及数据包结构,为理解其工作机制奠定基础。接着,详细阐述了自由口协议故障排查技术,包括常见故障类型、诊断工具与方法及解
C语言内存管理速成课:避开动态内存分配的坑
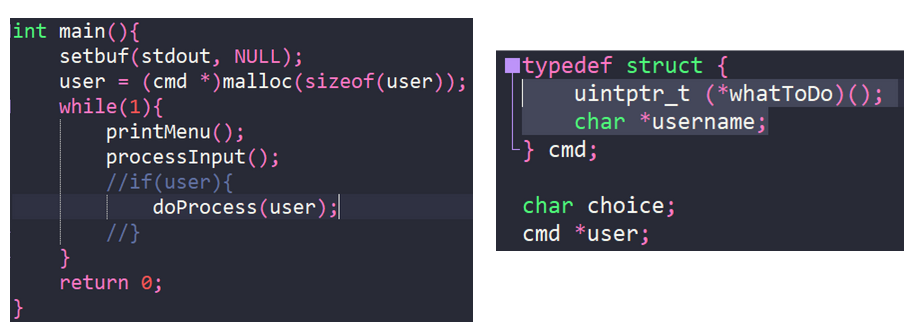
# 摘要
C语言作为经典的编程语言,其内存管理机制对程序的性能和稳定性具有决定性影响。本文首先概述了C语言内存管理的基础知识,随后深入探讨了动态内存分配的原理、使用技巧及常见错误。通过案例分析,本文进一步实践了内存管理在实际项目中的应用,并讨论了内存分配的安全性和优化策略。本文还涵盖了高级内存管理技术,并展望了内存管理技术的发展趋势和新兴技术的应用前景。通
【招投标方案书的语言艺术】:让技术文档更具说服力的技巧

# 摘要
本文探讨了招投标方案书撰写过程中的语言艺术及结构设计。重点分析了技术细节的语言表达技巧,包括技术规格的准确描述、方案的逻辑性和条理性构建、以及提升语言说服力的方法。接着,文章详细介绍了招投标方案书的结构设计,强调了标准结构和突出技术展示的重要性,以及结尾部分总结与承诺的撰写技巧。此外,本文还提供了写作实践的案例分析和写作技巧的演练,强调了与甲方沟通与互动的重要性,包括沟通技巧、语言策略和后续跟进调整。最后
【效能对比】:TAN时间明晰网络与传统网络的差异,新一代网络技术的效能评估
.jpg)
# 摘要
时间明晰网络作为新型网络架构,提供了比传统网络更精准的时间同步和更高的服务质量(QoS)。本文首先概述了时间明晰网络的基本概念、运作机制及其与传统网络的对比优势。接着,文章深入探讨了实现时间明晰网络的关键技术,包括精确时间协议(PTP)、网络时间协议(NTP)和时间敏感网络(TSN)技术等。通过对工业自动化
【UDS错误代码秘密解读】:专家级分析与故障排查技巧

# 摘要
统一诊断服务(UDS)协议是汽车行业中用于诊断和通信的国际标准,其错误代码机制对于检测和解决车载系统问题至关重要。本文首先概述了UDS协议的基础知识,包括其架构和消
【RTX 2080 Ti性能调优技巧】:硬件潜力全挖掘
/i.s3.glbimg.com/v1/AUTH_08fbf48bc0524877943fe86e43087e7a/internal_photos/bs/2021/8/v/dscSt1S7GuYFTJNrIH0g/2017-03-01-limpa-2.png)
# 摘要
本文全面概述了RTX 2080 Ti显卡的架构特点及其性能
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录

文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )