理解JavaScript缓存机制:内存限制与数据管理(深入浅出教程)
发布时间: 2024-09-14 13:07:13 阅读量: 200 订阅数: 53 

# 1. JavaScript缓存机制概述
## 1.1 缓存的定义与重要性
缓存是一种临时存储技术,用于保存频繁访问的数据,减少对原始数据源的请求,从而提高系统性能和用户体验。在Web开发中,JavaScript缓存机制对于优化资源加载、降低服务器负载以及加快页面响应至关重要。
## 1.2 JavaScript缓存的类型
在JavaScript中,缓存可以分为客户端缓存和服务器端缓存。客户端缓存主要应用于浏览器中,通过本地存储来缓存数据,服务器端缓存则由服务器进行管理,以提高数据处理速度和减少网络延迟。
## 1.3 缓存策略的选择
选择合适的缓存策略是提高应用性能的关键。常见的缓存策略包括缓存穿透、缓存雪崩和缓存击穿。合理地应用这些策略能够有效避免不必要的数据加载和网络请求,提升用户的操作流畅度。
通过本章的内容,读者应能理解缓存机制的基本概念,并在后续章节中深入了解JavaScript在内存限制、数据管理、实现技术和优化实战方面的应用。
# 2. 内存限制基础
## 2.1 浏览器内存模型
### 2.1.1 栈内存和堆内存的基本概念
在JavaScript中,内存管理与数据存储方式紧密相关。内存模型主要分为两种:栈内存(stack)和堆内存(heap)。
- 栈内存(Stack)是静态分配内存,存储的是基础数据类型以及对象的引用地址。它按照“后进先出”(Last In First Out, LIFO)的原则管理数据。当你调用一个函数时,它会将其执行所需的所有信息放入栈中。函数执行结束后,这些信息会被清除出栈。
- 堆内存(Heap)则是动态分配内存,用于存储复杂数据类型(如对象、数组等)。在JavaScript中,当你创建一个对象时,实际是在堆上分配一块空间存储对象,并在栈中保存一个引用指针。
这种设计允许JavaScript引擎在处理内存时根据需要分配和回收空间,但同时也带来了内存管理上的复杂性,增加了内存泄漏的可能性。
### 2.1.2 JavaScript中的内存分配
在JavaScript中,内存分配主要涉及变量和对象的生命周期管理。变量被分配在栈内存,它们有明确的作用域和生命周期,当函数执行完毕,局部变量所占用的栈内存被自动清除。
```javascript
function createData() {
let object = new Object(); // 对象在堆中分配内存
object.name = "JavaScript Memory";
// 函数返回后,object的引用在栈中被清除,
// 但实际的对象数据还在堆中,等待垃圾回收
}
createData();
```
对于对象和数组这样的复杂数据类型,JavaScript使用引用计数(reference counting)机制跟踪内存使用情况。当对象没有被任何变量引用时,它将成为垃圾回收的目标。然而,这种机制不能很好地处理循环引用的情况,这也是导致内存泄漏的一个常见原因。
## 2.2 垃圾回收机制
### 2.2.1 垃圾回收的基本原理
垃圾回收(Garbage Collection, GC)是自动化内存管理的过程,它定期识别和清除不再使用的内存空间。JavaScript引擎使用多种算法来实现垃圾回收,确保程序运行时的内存得到有效的管理。
大多数现代浏览器使用标记-清除(Mark-and-Sweep)算法来实现垃圾回收。这个过程分为两个阶段:
1. **标记(Mark)阶段**:从根对象开始,递归地标记所有从根对象可达的对象。
2. **清除(Sweep)阶段**:清除那些没有被标记的对象,释放其占用的内存。
### 2.2.2 常见的垃圾回收算法
除了标记-清除算法外,JavaScript引擎还使用其他垃圾回收算法:
- **引用计数(Reference Counting)**:跟踪每个对象被引用的次数。对象一旦引用计数为零,意味着没有任何变量引用它,就可以立即回收。
```javascript
let obj1 = {name: "Object1"};
let obj2 = obj1;
obj1 = null; // obj1的引用计数减1
// obj2依然引用obj1所指向的对象,因此该对象不会被回收
```
- **分代垃圾回收(Generational Garbage Collection)**:将内存分为新生代和老生代,新对象通常在新生代中,频繁进行垃圾回收;而老生代对象则较少进行回收。这个机制基于一个观察:大多数对象的生命周期都很短,只有少数对象存在时间长。
这些算法的使用取决于具体的JavaScript引擎。了解这些机制对于开发者来说十分重要,它可以帮助你写出更加高效和内存友好的代码。
## 2.3 内存泄漏识别与处理
### 2.3.1 内存泄漏的常见原因
内存泄漏是当应用程序不再需要某些内存时,由于错误或疏忽,没有释放这些内存,导致内存使用量逐渐增加的问题。在JavaScript中,内存泄漏常见的原因包括:
- **闭包(Closures)**:如果闭包中的变量需要被长期存储,而闭包本身没有被垃圾回收,那么这些变量引用的内存就不会被释放。
```javascript
function setup() {
let largeArray = new Array(100000).fill('memory');
return () => {
// 这个闭包会阻止largeArray被回收
}
}
let leakFunction = setup();
```
- **全局变量**:未使用的全局变量会阻止整个JavaScript文件的内存被释放。
- **未解绑的事件处理器**:事件处理器通常会持有其挂载元素的引用,如果它们没有正确解绑,可能导致相关元素无法回收。
- **定时器(Timers)**:如果定时器的回调函数引用了外部变量,而这个定时器没有被清除,那么这些变量也无法被回收。
### 2.3.2 如何监控和定位内存泄漏
为了识别和处理内存泄漏,可以使用不同的工具和策略:
- **浏览器的开发者工具**:大多数现代浏览器都提供了强大的内存监控工具,例如Chrome的Memory Tab,可以监视内存的分配、使用和垃圾回收过程。
- **代码审查**:定期进行代码审查,特别是检查可能产生内存泄漏的部分,如事件处理器、定时器、以及全局变量的使用情况。
- **使用性能分析工具**:性能分析工具如Chrome的Performance Tab可以帮助开发者观察内存使用情况和进行性能分析。
- **内存泄漏检测库**:使用专门的库如lodash的`_.memoize`或者开发自定义的内存泄漏检测工具,对内存使用进行监控。
```javascript
// 使用lodash的memoize方法缓存函数返回值,防止重复执行
let memoized = _.memoize(() => {
// 计算成本高的操作
});
```
通过上述工具和方法,结合代码逻辑分析,可以有效地识别和处理内存泄漏问题,提升应用程序的性能和稳定性。
# 3. 数据管理策略
数据管理是缓存策略中最为关键的组成部分之一,它直接决定了缓存的有效性和应用程序的性能。在本章节中,我们将深入探讨数据缓存技术、缓存数据的有效期管理以及如何在保持缓存高效的同时确保数据一致性。
## 3.1 数据缓存技术
### 3.1.1 缓存的必要性及其优势
缓存技术的存在主要源于数据访问模式的不均匀性。在数据访问过程中,某些数据经常会被重复访问,而这些数据的频繁读取会极大地影响系统的性能,尤其是在分布式系统中,数据可能需要在不同的服务器节点之间传输。因此,缓存这些频繁访问的数据,可以显著提高数据访问速度,减少网络延迟和服务器负载。
缓存技术的优势主要包括:
- **提高性能**:通过将数据存储在离用户更近的地方(例如浏览器缓存或CDN),减少数据获取所需的网络延迟。
- **减轻后端压力**:缓存减少了对后端服务器的请求次数,从而减轻服务器处理压力。
- **成本节省**:有效利用缓存减少了服务器和带宽的需求,进而降低运营成本。
### 3.1.2 缓存数据的存储策略
缓存数据的存储策略直接影响到数据的访问效率和缓存的命中率。常见的存储策略有:
- **内存缓存**:将数据存储在服务器的RAM中,由于内存访问速度非常快,因此可以极大提升数据读取效率。
- **持久化缓存**:将数据存储在硬盘或其他持久化存储设备中,适用于长时间缓存数据,即使服务器重启,数据也不会丢失。
### *.*.*.* 代码块示例:使用内存缓存技术
假设我们使用JavaScript开发一个Web应用,并希望在内存中缓存一些数据以提高访问速度,我们可以使用简单的对象作为缓存存储:
```javascript
class MemoryCache {
constructor() {
this.cache = new Map();
}
set(key, value) {
this.cache.set(key, value);
}
get(key) {
return this.cache.get(key);
}
remove(key) {
this.cache.delete(key);
}
}
// 使用示例
const cache = new MemoryCache();
// 缓存数据
cache.set('user', { id: 1, name: 'Alice' });
// 获取数据
const user = cache.get('user');
console.log(user);
// 删除数据
cache.remove('user');
```
### *.*.*.* 参数说明与逻辑分析
- `set(key, value)`: 向缓存中添加一个数据项,通过键值对的方式存储。
- `get(key)`: 根据给定的键获取缓存项。
- `remove(key)`: 通过键从缓存中移除数据项。
在上述代码块中,我们创建了一个简单的内存缓存类`MemoryCache`,它使用一个Map对象作为存储机制,Map对象是一个键值对集合,它允许我们快速地通过键访问值。此策略在内存中实现了一个非常基础的缓存机制。
## 3.2 缓存数据的有效期管理
### 3.2.1 缓存数据失效的条件
缓存数据不是永久有效的,必须在

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0

专栏简介
本专栏深入探讨了 JavaScript 中的缓存数据结构,旨在帮助前端开发人员优化网站和应用程序的性能。它涵盖了各种主题,包括:
* 缓存技巧以立即提升网站速度
* JavaScript 内存缓存的技术原理和实践
* 浏览器到服务端的完整缓存优化路线图
* LRU 缓存算法在 JavaScript 中的实现
* 用 JavaScript 管理数据结构以构建高效缓存机制
* JavaScript 缓存设计模式,用于构建可扩展的缓存系统
* JavaScript 缓存数据结构的最佳实践,以优化性能和资源管理
* 缓存数据结构在实际项目中的应用案例分析
* 避免 JavaScript 缓存失效的黄金法则
* 并发控制在 JavaScript 缓存数据结构中的高级策略
* 从本地存储到网络请求的 JavaScript 缓存数据结构完整指南
* 理解 JavaScript 缓存机制,包括内存限制和数据管理
* JavaScript 缓存数据结构中内存泄漏的预防和检测
* JavaScript 缓存世界中的数据结构和算法结合
* 使用 Proxy 对象提升 JavaScript 缓存数据结构的性能
* JavaScript 中的 Set 和 WeakSet,用于缓存数据结构
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
KISTLER 5847故障速查手册:3步定位与解决常见问题

# 摘要
本文提供了一个全面指南,以快速定位和解决KISTLER 5847设备的故障问题。首先介绍了该设备的基础知识,包括工作原理、硬件组成和软件环境。接着,详细阐述了通过三个步骤识别、分析和解决故障的过程。文章还提供了针对不同故障实例的具体分析和解决方法。为了更有效的维护和优化设备,本文还提出了预防性维护计划、性能优化技巧和故障预防策略。最后,针对高级故障解决提供了专业工具和方法,以
数据处理能力倍增:MSP430F5529数字信号处理技巧大公开
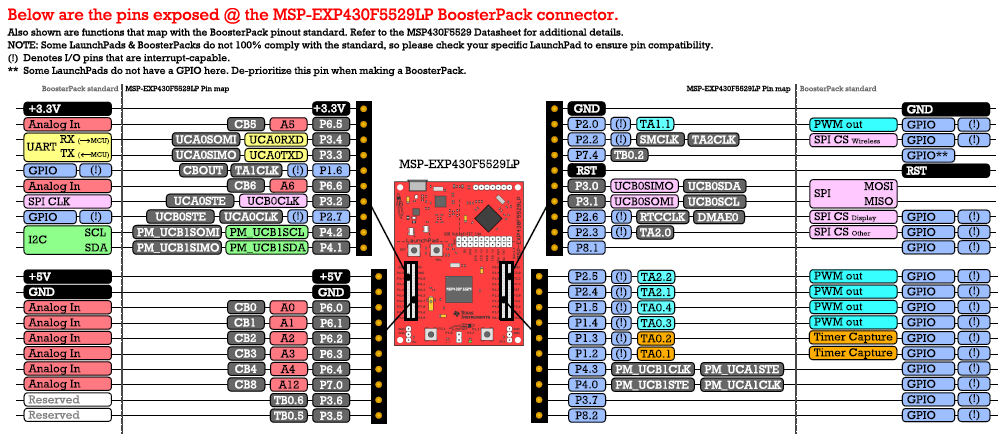
# 摘要
MSP430F5529微控制器由于其在数字信号处理(DSP)领域的高性能和低功耗特性,已成为各种应用中的理想选择。本文首先介绍了MSP430F5529的基础知识和数字信号处理基础,然后深入探讨了其数字信号处理理论、滤波器设计、频谱分析技术等核心内容。第三章通过实际应用案例展示了MSP430F5529在音频、图像处理以及无线通信领域的应用。进阶技巧部分详细介绍了
【视频输出格式:PreScan Viewer终极指南】:输出最合适的格式,只需5分钟!
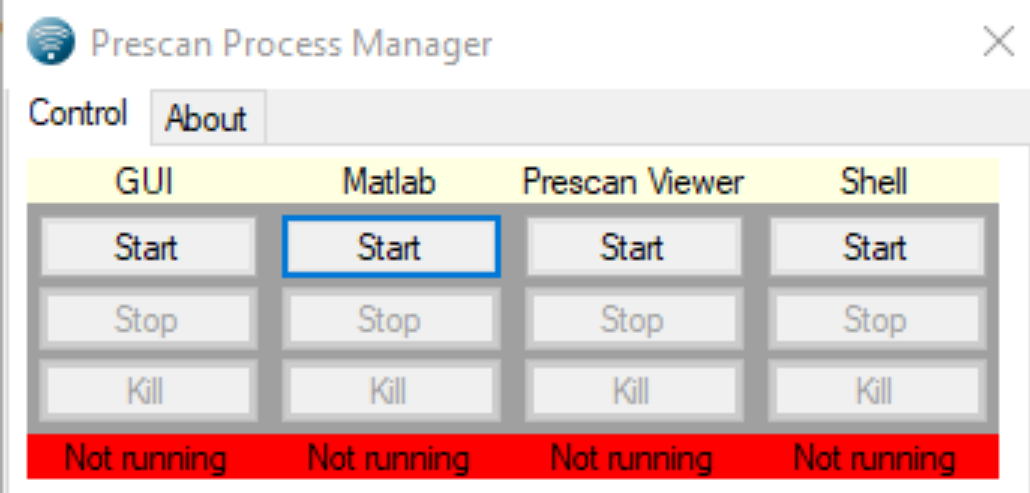
# 摘要
PreScan Viewer是一款集多功能于一身的视频处理软件,其操作界面直观、功能丰富,满足从基础到高级用户的需求。本文首先介绍了PreScan Viewer的基本概况,随后详细阐述了其操作界面布局、核心功能以及性能调整方法。接着,文章深入探讨了视频处理流程,包括视频文件的导入管理、编辑预处理和输出分享等。为了进一步提升用户的使用体
自动化转换流程构建指南:SRecord工具链实践详解
# 摘要
随着软件工程领域的不断进步,自动化转换流程的需求日益增长,本文对自动化转换流程进行了全面的概述。首先,本文介绍了自动化转换流程的基础知识,并详细讲解了SRecord工具链的安装、配置及命令使用。接着,本文深入探讨了自动化流程设计的理论基础和实践中的定制方法,并对流程的优化、测试与部署提出了具体的策略。高级应用章节分析了错误处理、性能监控与调优技巧,以及工具链安全性考虑。最后,本文
【V90 PN伺服状态字与控制字】:实现高效通信与实时控制的终极指南
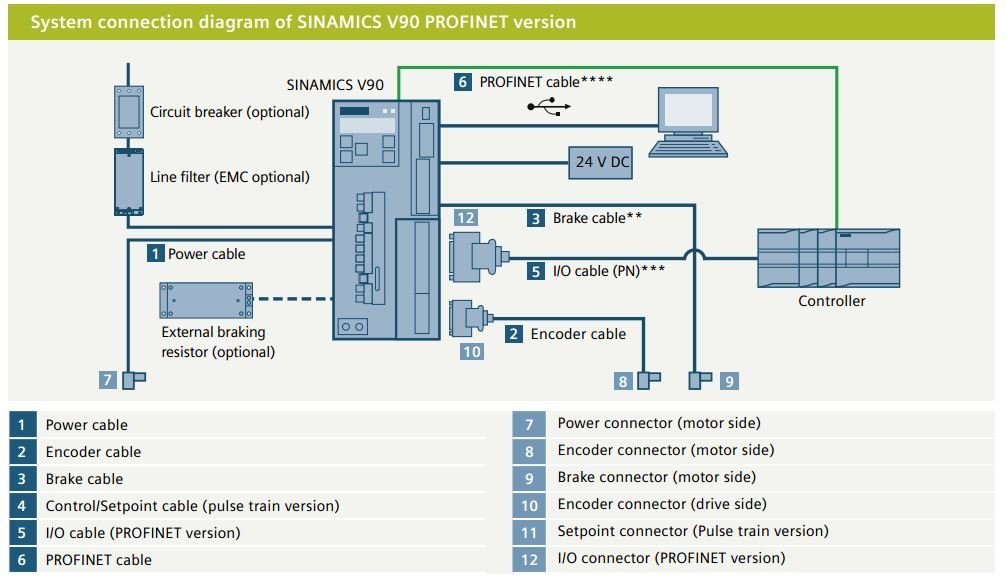
# 摘要
V90 PN伺服驱动器在工业自动化领域发挥着关键作用,本文系统地概述了伺服驱动器的结构和通信协议基础,并深入探讨了其状态字与控制字的设计原理及其应用。通过对伺服状态字与控制字的监控、调整和通信实践的分析,本文揭示了如何实现精确的运动控制和与自动化系统的高效集成。文中还讨论了将V90 PN伺服驱动器应用于实际案
无线资源管理策略:3GPP TS 36.413的实操与实践
# 摘要
无线资源管理是保障移动通信系统性能的关键技术之一,本论文首先介绍了无线资源管理的基础知识,随后详细解读了3GPP TS 36.413协议的要点。文章深入探讨了无线资源调度策略的实现原理、技术实现及性能评估,并且对资源控制和优化技术进行了分析。通过对调度算法设计、信道信息采集和实时调度实例的研究,以及负载均衡和频谱效率优化方法的讨论,本论文旨在提升无线网络性能,并在高密度和特殊场景下的资源管理提供
【金融数据分析揭秘】:如何运用总体最小二乘法揭示隐藏价值

# 摘要
总体最小二乘法作为一种强大的数学工具,在金融数据分析中发挥着重要作用。本文首先介绍了总体最小二乘法的理论基础,阐述了其算法原
【Ubuntu系统恢复秘籍】:用Mini.iso轻松恢复系统

# 摘要
本文详细探讨了Ubuntu系统恢复的全过程,特别强调了Mini.iso工具在系统恢复中的作用和应用。首先对Mini.iso的功能、原理、优势进行了介绍,随后详述了安装此工具的步骤。文章深入讲解了使用Mini.iso进行基础和高级系统恢复的流程,包括系统引导检查、引导加载器修复和文件系统检查。此外,本文还探讨了Mini.iso在不同场景下的应用,例如数据恢复与备份
【瑞萨E1仿真器高级功能】:解锁嵌入式开发的新境界

# 摘要
本文介绍了瑞萨E1仿真器的概况、安装、基础操作、高级特性解析,以及在实际项目中的应用和未来展望。首先概述了瑞萨E1仿真器的基本功能和安装流程,随后深入探讨了基础操作,如硬件连接、软件配置、项目创建与编译,以及调试与监视功能的使用。第三章分析了瑞萨E1仿真器的高级特性,包括实时跟踪、性能分析、系统资源管理和硬件仿真等。第四章通过实际项目应用实例,讲解了瑞萨E1仿真器在项目设置、调试流
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )