【R语言时间序列分析】:evd包带你洞悉时间序列中的极端事件
发布时间: 2024-11-05 10:45:56 阅读量: 23 订阅数: 30 

EVD:你大胆往前走 (2004年)

# 1. 时间序列分析与极端事件的概念
在现代数据分析领域,时间序列分析和极端事件研究是两个关键课题,对于理解和预测未来的趋势与风险具有重要意义。时间序列是指按照时间顺序排列的数据点集合,常用于研究和预测随时间变化的现象。而极端事件,如自然灾害、金融市场崩溃等,虽然发生频率低,但其影响深远且难以预测,对社会经济系统构成了巨大威胁。本章将概述时间序列分析的基础知识,并介绍极端事件的相关概念与挑战,为读者提供理解后续章节内容的基石。
## 1.1 时间序列分析基础
时间序列分析是一种统计工具,用于处理按时间顺序排列的数据点集合。它能够揭示数据中的周期性、趋势和季节性等特征,帮助预测未来值。在实际应用中,时间序列分析被广泛用于经济、金融、环境和工程等领域的预测和决策制定。
## 1.2 极端事件的定义和影响
极端事件是指在一定条件下,观测值偏离其正常水平极大程度的事件。这类事件由于其罕见性,往往给社会带来严重的影响和损失。在统计学中,极端值的分析和预测是通过极端值理论来实现的,该理论涉及对极端值分布的理解和建模。
## 1.3 时间序列分析与极端事件的关系
时间序列分析和极端事件研究在许多实际应用中是互补的。时间序列方法可以揭示潜在的极端事件模式,而对极端事件的研究也可以增强时间序列预测的鲁棒性。例如,在金融市场中,通过时间序列分析可以预测资产价格的长期趋势,而极端值理论有助于评估市场崩溃等罕见事件的风险。
# 2. R语言与时间序列数据的处理
## 2.1 R语言基础入门
### 2.1.1 R语言安装与配置
R语言是一种用于统计分析、图形表示和报告的编程语言和软件环境。它是开源的,拥有活跃的社区和大量的扩展包,使其非常适合处理和分析时间序列数据。安装R语言相当简单。对于大多数操作系统,可以从CRAN(综合R档案网络)下载安装程序。
以下是R语言在Windows系统中的安装步骤:
1. 访问CRAN网站(***)。
2. 点击“Download R for Windows”链接。
3. 点击“install R for the first time”下载安装程序。
4. 运行安装程序,遵循安装向导的步骤。
在配置R语言环境之前,建议您检查并设置R语言的环境变量,这样可以在命令行中直接调用R。安装完成后,打开R控制台,您将看到提示符`>`,表示R已准备好接收命令。
### 2.1.2 R语言基本数据结构
R语言有几种基础数据结构,包括向量(vector)、矩阵(matrix)、数组(array)、数据框(data.frame)和列表(list)。这些数据结构是处理时间序列数据的基础。
向量是R中最基本的数据结构,它是由相同类型的元素组成的集合。可以通过`c()`函数来创建向量:
```R
# 创建一个数值向量
numbers <- c(1, 2, 3, 4, 5)
# 创建一个字符向量
characters <- c("apple", "banana", "cherry")
```
矩阵和数组用于存储多维数据,矩阵是二维的,而数组可以有多个维度。数据框是一种用于存储表格数据的数据结构,它类似于数据库中的表,每列可以包含不同的数据类型,是分析时间序列数据的常用结构。
列表是R中最灵活的数据结构,可以包含任何类型的数据结构,包括其他列表。
```R
# 创建一个数据框
df <- data.frame(
Time = 1:10,
Value = rnorm(10)
)
```
## 2.2 R语言中的时间序列对象
### 2.2.1 创建和识别时间序列对象
在R中,可以使用`ts()`函数来创建时间序列对象。这个函数的基本用法是`ts(data, start, end, frequency)`,其中`data`是一个数值型向量,`start`和`end`定义时间序列的起始和结束时间,`frequency`表示数据的频率。
```R
# 创建一个时间序列对象
ts_data <- ts(c(1, 2, 3, 4, 5, 6, 7, 8, 9, 10), start=c(2020, 1), frequency=12)
```
要检查时间序列对象的结构,可以使用`str()`函数,它提供了一个对象的内部结构概览:
```R
str(ts_data)
```
### 2.2.2 时间序列对象的常用操作
时间序列对象创建后,我们可以对其进行各种操作,例如索引、切片和转换。R提供了一系列函数来处理这些操作。
- 索引和切片允许您访问时间序列中的特定部分:
```R
# 索引时间序列的第一个元素
first_element <- ts_data[1]
# 切片时间序列从第二个元素到第五个元素
slice_data <- ts_data[2:5]
```
- 转换操作,如对时间序列对象应用函数,例如`diff()`计算差分,`log()`计算对数等,可以帮助我们从不同角度分析数据:
```R
# 计算时间序列对象的差分
ts_diff <- diff(ts_data)
# 计算时间序列对象的对数
ts_log <- log(ts_data)
```
## 2.3 时间序列数据的预处理
### 2.3.1 数据清洗与转换
在分析时间序列之前,通常需要进行数据清洗和转换。这包括处理缺失值、异常值、平滑数据等。R语言提供了多种函数和方法来处理这些问题。
处理缺失值,可以使用`na.omit()`函数删除缺失值,或者使用插值方法如`na.approx()`从`zoo`包来填充缺失值。
```R
# 删除缺失值
clean_data <- na.omit(ts_data)
# 使用线性插值方法填充缺失值
approx_data <- na.approx(ts_data)
```
平滑时间序列数据,可以使用`ma()`函数从`forecast`包来计算移动平均:
```R
library(forecast)
# 计算移动平均
smoothed_data <- ma(ts_data, order=3)
```
### 2.3.2 时间序列的平滑和趋势分析
时间序列的平滑可以去除数据中的随机波动,从而帮助识别趋势。趋势分析能够揭示数据随时间的变化趋势。在R中,可以使用`decompose()`函数来分解时间序列,并分离出趋势、季节性和随机成分。
```R
# 分解时间序列
decomposed_ts <- decompose(ts_data)
# 绘制分解后的趋势图
plot(decomposed_ts$tr
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏提供了一系列关于 R 语言 evd 数据包的详细教程,涵盖了从基础到高级的各个方面。通过循序渐进的讲解和实战案例,读者可以快速掌握 evd 包的安装、使用和应用技巧。专栏深入探讨了概率分布、极值理论、数据分析、风险评估、图形界面构建、机器学习、时间序列分析、数据清洗、生存分析和数据可视化等广泛主题。通过学习本专栏,读者将能够熟练运用 evd 包处理极值数据,提升数据分析能力,并深入理解数据中的极端值和风险分布。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
揭秘STM32:如何用PWM精确控制WS2812LED亮度(专业速成课)

# 摘要
本文系统介绍了STM32微控制器基础,PWM信号与WS2812LED通信机制,以及实现PWM精确控制的技术细节。首先,探讨了PWM信号的理论基础和在微控制器中的实现方法,随后深入分析了WS2812LED的工作原理和与PWM信号的对接技术。文章进一步阐述了实现PWM精确控制的技术要点,包括STM32定时器配置、软件PWM的实现与优化以及硬件PWM的配置和
深入解构MULTIPROG软件架构:掌握软件设计五大核心原则的终极指南
# 摘要
本文旨在探讨MULTIPROG软件架构的设计原则和模式应用,并通过实践案例分析,评估其在实际开发中的表现和优化策略。文章首先介绍了软件设计的五大核心原则——单一职责原则(SRP)、开闭原则(OCP)、里氏替换原则(LSP)、接口隔离原则(ISP)、依赖倒置原则(DIP)——以及它们在MULTIPROG架构中的具体应用。随后,本文深入分析了创建型、结构型和行为型设计模式在
【天清IPS问题快速诊断手册】:一步到位解决配置难题
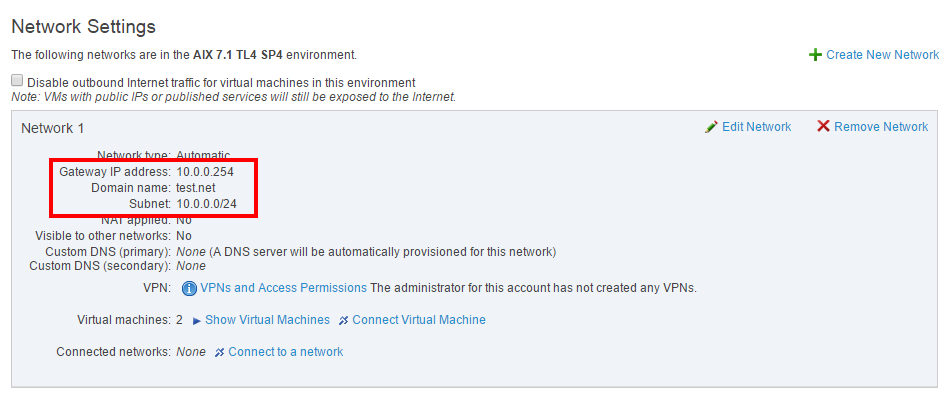
# 摘要
本文全面介绍了天清IPS系统,从基础配置到高级技巧,再到故障排除与维护。首先概述了IPS系统的基本概念和配置基础,重点解析了用户界面布局、网络参数配置、安全策略设置及审计日志配置。之后,深入探讨了高级配置技巧,包括网络环境设置、安全策略定制、性能调优与优化等。此外,本文还提供了详细的故障诊断流程、定期维护措施以及安全性强化方法。最后,通过实际部署案例分析、模拟攻击场景演练及系统升级与迁移实
薪酬增长趋势预测:2024-2025年度人力资源市场深度分析

# 摘要
本论文旨在探讨薪酬增长的市场趋势,通过分析人力资源市场理论、经济因素、劳动力供需关系,并结合传统和现代数据分析方法对薪酬进行预
【Linux文件格式转换秘籍】:只需5步,轻松实现xlsx到txt的高效转换

# 摘要
本文全面探讨了Linux环境下文件格式转换的技术与实践,从理论基础到具体操作,再到高级技巧和最佳维护实践进行了详尽的论述。首先介绍了文件格式转换的概念、分类以及转换工具。随后,重点介绍了xlsx到txt格式转换的具体步骤,包括命令行、脚本语言和图形界面工具的使用。文章还涉及了转换过程中的高级技
QEMU-Q35芯片组存储管理:如何优化虚拟磁盘性能以支撑大规模应用
# 摘要
本文详细探讨了QEMU-Q35芯片组在虚拟化环境中的存储管理及性能优化。首先,介绍了QEMU-Q35芯片组的存储架构和虚拟磁盘性能影响因素,深入解析了存储管理机制和性能优化理论。接着,通过实践技巧部分,具体阐述了虚拟磁盘性能优化方法,并提供了配置优化、存储后端优化和QEMU-Q35特性应用的实际案例。案例研究章节分析了大规模应用环境下的虚拟磁盘性能支撑,并展
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )