AnnotationUtils在Spring中的应用:5个技巧助你提高注解处理效率
发布时间: 2024-09-27 00:56:46 阅读量: 60 订阅数: 25 

Spring核心注解深入解析:提升开发效率
# 1. AnnotationUtils在Spring中的基础应用
## 1.1 AnnotationUtils简介
AnnotationUtils是一个强大的工具类,它位于Spring框架的`org.springframework.core.annotation`包中。它提供了丰富的API,使开发者能够方便地处理Java中的注解,特别适用于对注解进行反射时获取信息和操作注解属性。在Spring框架中,AnnotationUtils常常用于在运行时解析注解,从而支持例如依赖注入、事务管理等多种功能。
## 1.2 AnnotationUtils使用场景
在Spring开发中,AnnotationUtils的使用场景非常广泛,例如在自动装配、声明式事务管理、AOP编程等方面。AnnotationUtils提供了一套简洁的API来获取注解的属性值,解析注解的元数据,这对于提高代码的可读性和可维护性起到了非常关键的作用。
## 1.3 如何开始使用AnnotationUtils
要在Spring项目中开始使用AnnotationUtils,首先要确保Spring框架已经加入到项目依赖中。随后,你可以通过导入相应的包并创建一个工具类来开始使用它。以下是一个基本的使用示例:
```java
import org.springframework.core.annotation.AnnotationUtils;
public class AnnotationTest {
public static void main(String[] args) {
// 假设有一个使用了@MyAnnotation注解的类
Class<?> clazz = MyAnnotatedClass.class;
// 获取类上的@MyAnnotation注解
MyAnnotation myAnnotation = AnnotationUtils.findAnnotation(clazz, MyAnnotation.class);
// 如果存在注解,则打印出注解的属性值
if (myAnnotation != null) {
System.out.println("Value: " + myAnnotation.value());
}
}
}
```
上述代码展示了如何使用AnnotationUtils找到一个类上的注解,并获取其属性值。这只是 AnnotationUtils 功能的一个简单示例,后面章节将会详细介绍更复杂的应用技巧和场景。
# 2. 深入理解Spring中的注解
在本章中,我们将深入探讨Spring框架中注解的基础知识,包括定义、作用以及如何使用它们。我们将首先从定义和作用入手,解释注解与接口、类的关系以及它们在Spring框架中的角色。接着,我们将详细解析Spring内置注解,并且展示如何使用这些注解及其参数。最后,我们会介绍自定义注解的创建过程和在实际业务逻辑中的应用案例。
## 2.1 注解的定义和作用
注解是Java语言的一个重要特性,它允许开发者在不改变原有代码结构的情况下,增加额外的描述信息。在Spring框架中,注解扮演了关键角色,它们简化了配置,增加了代码的可读性和可维护性。
### 2.1.1 注解与接口、类的关系
注解可以看作是一种特殊类型的接口,它不能直接作用于类或方法,但可以通过元注解(meta-annotation)的方式被用作标记,从而向程序提供附加信息。一个注解可以关联到类、方法、变量、参数和包等不同级别的Java实体上。
在Spring框架中,注解通常用于声明Spring容器中的bean、事务管理、依赖注入等。例如,`@Component`可以标记类为Spring管理的组件,`@Autowired`用于自动装配依赖。
### 2.1.2 注解在Spring框架中的角色
在Spring框架中,注解不仅有助于简化配置,还能够提高代码的清晰度。它们提供了一种声明式编程范式,允许开发者用注解声明来替代XML配置,减少代码量并提高开发效率。注解如`@Transactional`和`@Service`等,让开发者能够轻松地声明事务边界和业务逻辑层。
此外,注解也是Spring实现AOP(面向切面编程)的关键,通过`@Aspect`注解声明切面,`@Before`、`@After`等注解定义切面的具体行为。
## 2.2 Spring内置注解详解
Spring内置了众多的注解,用于简化和增强开发过程。本节我们将介绍一些常用Spring注解以及它们参数的使用和含义。
### 2.2.1 常用的Spring注解介绍
- `@Component`: 基础注解,用于标记类作为Spring容器中的一个组件。
- `@Service`: 特定于服务层,指示Spring为业务逻辑层的类提供服务。
- `@Repository`: 用于数据访问层,它将类标记为数据仓库组件。
- `@Controller`: 用于Spring MVC控制器组件,与`@RequestMapping`结合使用,提供Web请求的处理逻辑。
- `@Autowired`: 用于自动装配,Spring自动寻找匹配的bean注入到相应的位置。
- `@Transactional`: 用于声明一个方法或类的事务边界。
- `@Value`: 用于注入外部的属性值到Spring管理的bean中。
### 2.2.2 注解参数的使用和含义
大多数注解都提供了可配置的参数,这些参数允许开发者根据需求自定义注解行为。例如,`@Value`注解的参数可以是一个SpEL(Spring Expression Language)表达式,允许你在运行时计算值。
```java
@Value("${app.name}")
private String appName;
```
在上面的代码示例中,`@Value`注解使用一个属性值来注入`appName`字段。`${app.name}`是一个SpEL表达式,它将在运行时被解析为配置文件中`app.name`属性的值。
## 2.3 自定义注解的创建和应用
在某些情况下,内置的Spring注解无法满足特定需求,这时候就需要自定义注解。下面我们将介绍创建自定义注解的基本步骤,并提供一个业务逻辑中的应用案例。
### 2.3.1 自定义注解的基本步骤
创建自定义注解首先需要定义一个接口,使用`@interface`关键字,并且可以定义注解的属性。例如:
```java
@Target(ElementType.METHOD)
@Retention(RetentionPolicy.RUNTIME)
public @interface MyCustomAnnotation {
String value() default "default";
}
```
在上面的代码中,定义了一个名为`MyCustomAnnotation`的自定义注解,它使用`@interface`声明,并且指定了它的目标(方法)和保留策略(运行时)。注解中包含一个名为`value`的属性,有一个默认值。
### 2.3.2 自定义注解在业务逻辑中的应用案例
假设我们要创建一个简单的日志记录器,我们可以定义一个自定义注解`@Loggable`来标记需要记录日志的方法。
```java
@Target(ElementType.METHOD)
@Retention(RetentionPolicy.RUNTIME)
public @interface Loggable {
String operation();
}
```
然后,在业务逻辑中使用该注解:
```java
@Service
public class MyService {
@Loggable(operation = "SERVICE_OPERATION")
public void myMethod() {
// some business logic
}
}
```
在这个例子中,`@Loggable`被标记在`myMethod`方法上。这可以作为一个钩子,触发日志记录的逻辑,如通过AOP切面在运行时注入日志行为。
```java
@Aspect
@Component
public class LoggingAspect {
@Around("@annotation(Loggable)")
public Object log(ProceedingJoinPoint joinPoint) throws Throwable {
MethodSignature signature = (MethodSignature) joinPoint.getSignature();
Loggable loggable = signature.getMethod().getAnnotation(Loggable.class);
String operation = loggable.operation();
System.out.println("Starting " + operation);
Object result = joinPoint.proceed();
System.out.println("Ending " + operation);
return result;
}
}
```
上面的切面`LoggingAspect`使用了`@Around`注解,它会在`@Loggable`标记的方法周围执行。这个AOP切面利用了动态代理机制,在调用方法之前和之后输出日志信息。
在下一章中,我们将介绍AnnotationUtils工具类的API概述,如何利用它读取和处理注解,以及它的高级用法。
# 3. AnnotationUtils工具类应用技巧
## 3.1 AnnotationUtils的API概述
### 3.1.1 AnnotationUtils提供的主要方法
`AnnotationUtils` 是 Spring Framework 提供的一个工具类,它简化了 Java 注解的处理,特别是在反射场景中。以下是 `AnnotationUtils` 提供的一些主要方法:
- `getAnnotation`: 用于获取指定对象上的注解实例。
- `getAnnotationAttributes`: 提取注解的属性,支持从继承中检索属性。
- `synthesizeAnnotation`: 将注解属性合成注解实例。
- `Nullannotations`: 用于处理可能为 null 的注解类型。
### 3.1.2 方法参数和返回值解析
每个 `AnnotationUtils` 方法都设计得非常灵活,支持从不同层级检索注解。例如:
- `getAnnotation` 方法接受一个对象和注解类型作为参数,返回该对象上声明的指定类型的注解。
- `getAnnotationAttributes` 方法接受一个注解实例和可选的 `Class<T>` 参数,返回一个 `Map<String, Object>`,其中包含注解的所有属性和值。
这些方法极大地简化了在运行时获取和处理注解的代码,减少了样板代码的编写。
## 3.2 利用AnnotationUtils读取注解属性
### 3.2.1 获取注解类型的方法
获取注解类型的最基本方法是使用 `getAnnotation`。考虑以下示例:
```java
public class ExampleBean {
@MyAnnotation
public void myMethod() {
}
}
Annotation myAnnotation = AnnotationUtils.getAnnotation(ExampleBean.class.getMethod("myMethod"), MyAnnotation.class);
```
此代码片段获取了 `ExampleBean` 类中 `myMethod` 方法上的 `@MyAnnotation` 注解。
### 3.2.2 读取注解属性值的策略
一旦获取了注解实例,就可以使用 `AnnotationUtils` 提供的其他方法来读取其属性值。例如:
```java
Map<String, Object> attributes = AnnotationUtils.getAnnotationAttributes(myAnnotation);
Object value = attributes.get("value");
```
这里,我们首先提取注解的所有属性,然后通过键 `"value"` 获取特定属性的值。
## 3.3 AnnotationUtils在注解处理中的高级用法
### 3.3.1 与反射结合使用处理复杂场景
结合反射API,`AnnotationUtils` 可以处理更复杂的场景,比如递归查找注解、处理继承自父类或父接口的注解等。例如:
```java
for (Method method : ExampleBean.class.getMethods()) {
MyAnnotation myAnnotation = AnnotationUtils.getAnnotation(method, MyAnnotation.class);
if (myAnnotation != null) {
// 处理注解
}
}
```
此循环遍历 `ExampleBean` 类的所有方法,并对每个方法上声明的 `@MyAnnotation` 注解进行处理。
### 3.3.2 优化注解处理性能的技巧
为了提高处理注解时的性能,`AnnotationUtils` 提供了一些优化技巧,比如缓存机制。当你多次查找相同的注解时,`AnnotationUtils` 会自动缓存结果,减少重复的查找和解析操作。例如:
```java
Annotation annotation = AnnotationUtils.getAnnotation(someClass, MyAnnotation.class);
// 后续代码
```
在此例中,如果后续代码再次请求相同的注解实例,`AnnotationUtils` 会直接从缓存中返回结果,而不是重新解析。
上述章节内容是根据给定的目录大纲,深入挖掘了 AnnotationUtils 在处理 Java 注解方面的应用技巧。在实际应用中,这一章节可以作为开发人员在 Spring 框架下深入利用注解的参考资料。
# 4. AnnotationUtils在实际开发中的应用实践
### 4.1 提升业务逻辑代码的清晰度
#### 4.1.1 使用注解简化配置和依赖注入
注解在Spring框架中是用于简化配置和依赖注入的强大工具。通过使用`@Autowired`, `@Resource`, `@Inject`等注解,开发者可以将原本需要在XML文件或Java配置类中手动声明的依赖关系自动化,从而使代码更加简洁明了。
举例来说,当需要将一个服务类注入到一个控制器中时,传统的方式可能需要一个显式的注入语句:
```java
@Controller
public class MyController {
@Autowired
private MyService myService;
// ...
}
```
通过`@Autowired`注解,Spring容器能够自动识别并注入对应的Bean实例,无需在配置文件中进行显式声明。这不仅减少了配置的繁琐性,还增强了代码的可读性和维护性。
#### 4.1.2 利用注解进行事务管理的实践
事务管理是企业级应用开发中的一个关键方面。Spring通过注解使得声明式事务管理变得更加容易。开发者可以使用`@Transactional`注解来声明方法或类的事务边界,让Spring框架负责事务的开启、提交和回滚。
例如,要管理一个转账操作的事务性,可以这样做:
```java
@Service
public class TransferService {
@Autowired
private AccountRepository accountRepository;
@Transactional
public void transferMoney(Long fromId, Long toId, BigDecimal amount) {
Account fromAccount = accountRepository.findById(fromId);
Account toAccount = accountRepository.findById(toId);
fromAccount.withdraw(amount);
toAccount.deposit(amount);
accountRepository.save(fromAccount);
accountRepository.save(toAccount);
}
}
```
在这段代码中,`@Transactional`注解声明了`transferMoney`方法需要进行事务管理。Spring会确保在这个方法中的所有操作要么全部成功,要么在遇到异常时全部回滚,保证数据的一致性和完整性。
### 4.2 解耦代码与提高测试效率
#### 4.2.1 注解驱动的单元测试
单元测试是保证代码质量的重要手段。在Spring框架中,可以使用`@RunWith(SpringRunner.class)`和`@ContextConfiguration`等注解来设置测试环境,使测试更为便捷和高效。
例如,一个简单的Spring Boot应用程序的单元测试可能如下:
```java
@RunWith(SpringRunner.class)
@SpringBootTest
public class MyServiceTest {
@Autowired
private MyService myService;
@Test
public void testTransferMoney() {
// Given
Long fromId = 1L;
Long toId = 2L;
BigDecimal amount = BigDecimal.TEN;
// When
myService.transferMoney(fromId, toId, amount);
// Then
// 这里可以验证转账后账户状态是否符合预期
}
}
```
通过注解驱动的单元测试,开发者可以轻松地将测试代码与业务代码分离,从而提高测试效率并保证测试的独立性和准确性。
#### 4.2.2 利用注解进行代码分离和整合
在Spring框架中,注解不仅可以用于简化代码,还可以帮助开发者将不同的关注点分离,从而实现更好的代码整合。例如,`@Profile`注解允许开发者根据不同的环境配置条件来激活不同的Bean配置。
假设开发者需要为不同的部署环境准备不同的数据源配置,可以这样做:
```java
@Configuration
@Profile("dev")
public class DevDataSourceConfig {
// Dev环境下数据源的配置
}
@Configuration
@Profile("prod")
public class ProdDataSourceConfig {
// Prod环境下数据源的配置
}
```
通过上述配置,当Spring应用启动时,开发者可以根据激活的Profile来决定使用哪一个数据源配置。这样的做法使得代码更加灵活,同时也便于维护和扩展。
### 4.3 实现自定义注解的元编程
#### 4.3.1 元编程在Spring中的应用场景
元编程是编程的高级形式,它涉及到“编写编写程序的代码”,即编写能够操作代码本身的程序。在Spring框架中,AnnotationUtils工具类使得开发者可以更方便地进行元编程操作。
例如,可以创建自定义注解来提供特定的行为,比如声明一个`@Loggable`注解来自动记录方法的调用日志:
```java
@Target(ElementType.METHOD)
@Retention(RetentionPolicy.RUNTIME)
public @interface Loggable {
// 可以添加注解参数来自定义日志行为
}
```
然后,在方法执行前后插入日志记录逻辑,类似于AOP(面向切面编程)的方式,可以增强业务逻辑而不改变原有代码。
#### 4.3.2 利用AnnotationUtils实现元编程技术
AnnotationUtils在自定义注解和元编程场景中扮演重要角色,它能够帮助开发者在运行时解析注解属性,从而动态地控制程序的行为。
以`@Loggable`注解为例,可以通过AnnotationUtils获取注解实例,并在运行时检查其属性:
```java
public void logMethodCall(ProceedingJoinPoint joinPoint) throws Throwable {
MethodSignature signature = (MethodSignature) joinPoint.getSignature();
Method method = signature.getMethod();
Loggable loggable = AnnotationUtils.findAnnotation(method, Loggable.class);
// 如果方法上有@Loggable注解,则执行日志记录操作
if (loggable != null) {
logBeforeMethodCall(joinPoint);
}
// 调用原始方法
joinPoint.proceed();
// 如果方法上有@Loggable注解,则执行日志记录操作
if (loggable != null) {
logAfterMethodCall(joinPoint);
}
}
```
在上述示例中,通过`AnnotationUtils.findAnnotation`方法可以判断当前执行的方法是否有`@Loggable`注解,如果有,则记录日志。这种方式提高了代码的复用性和可维护性,同时也使得代码更加灵活。
通过这些具体的应用实践案例,可以体会到AnnotationUtils在实际开发中的强大功能和便捷性,使开发者能够更加专注于业务逻辑的实现,而不是底层的配置和管理细节。
# 5. AnnotationUtils在Spring未来版本中的展望
随着技术的不断进步,Spring框架也在不断地更新迭代,其中注解作为框架的重要组成部分,其在未来版本中的发展和改进同样备受瞩目。本章将探讨Spring注解的发展趋势,并针对AnnotationUtils在新版本中的可能改进方向提出预测和建议。
## 5.1 Spring注解的发展趋势
### 5.1.1 新版本中注解的创新
在Spring的新版本中,我们可以预见注解将继续朝着更加智能化、功能化的方向发展。开发者可能会看到更多的注解能够与框架的其他组件如Spring Boot、Spring Data等进行更深层次的整合,提供更为强大的功能。
例如,假设在未来的Spring版本中引入了名为`@AutoConfig`的新注解,这个注解可以自动扫描和配置应用所需的所有组件,极大地简化了开发者配置复杂环境的工作量。
```java
@AutoConfig
public class MySpringConfiguration {
// 类体中无需手动配置组件,@AutoConfig注解会自动处理
}
```
### 5.1.2 AnnotationUtils可能的改进方向
AnnotationUtils作为一个强大的工具类,主要负责处理注解的相关操作。在未来的版本中,它可能会支持更多的元注解处理能力,比如能够更智能地识别和处理注解之间的继承关系、依赖关系等。
此外,AnnotationUtils可能会引入一些智能化的功能,比如根据应用的上下文自动识别注解的最佳使用场景,或者提供更加丰富的API来处理注解属性的默认值、继承和覆盖等问题。
## 5.2 预测和建议
### 5.2.1 对开发者使用注解的建议
随着Spring框架的不断优化,对于开发者而言,紧跟技术的发展趋势,合理利用注解进行开发是非常重要的。建议开发者:
- 关注新版本的发布和注解的新特性。
- 学习并理解每个注解背后的原理和最佳实践。
- 尝试创建自定义注解以实现业务逻辑的优化和复用。
### 5.2.2 为新版本Spring框架的准备策略
开发者在面对新的Spring框架版本时,可以采取以下策略来确保平滑过渡:
- 定期阅读Spring官方文档和社区更新,了解最新的注解特性和框架改动。
- 在项目中使用feature toggles(特性开关)的方式来管理新旧注解的使用,便于在必要时回退。
- 对于复杂的注解逻辑,编写单元测试和集成测试来确保其稳定性和正确性。
通过上述建议和策略,开发者可以更好地为即将到来的Spring框架版本做好准备,并且充分利用AnnotationUtils来提升开发效率和应用性能。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏全面介绍了 Spring 框架中 AnnotationUtils 的用法和技巧。它提供了 10 个技巧,帮助开发人员提升代码效率;5 个技巧,提高注解处理效率;深入探究了 AnnotationUtils 的内部实现;阐述了它在 Spring Bean 生命周期中的关键作用;指导如何自定义注解并高效处理;介绍了高级特性,打造高效应用;提供了优雅处理切面编程的指南;阐明了它在依赖注入中的核心角色;分享了优化 Spring Boot 应用的 8 个技巧;展示了注解管理的最佳实践;详细解释了注解的继承机制;探索了 AnnotationUtils 与 Spring 表达式语言的结合;介绍了在缓存管理和事务管理中的应用;阐述了它在消息驱动 POJO 和 RESTful 服务中的关键作用。通过这些内容,开发人员可以深入了解 AnnotationUtils,并有效地利用它来增强 Spring 应用程序。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
高效编码秘籍:Tempus Text自定义快捷操作全面解析

# 摘要
Tempus Text编辑器作为一款高效的编程工具,其快捷键功能在提升编码效率和个性化工作流中起到了关键作用。本文从自定义快捷键的基础讲起,详细探讨了Tempus Text的快捷键机制,包括原生快捷键的解析和用户自定义快捷键的步骤。进阶部分介绍了复合快捷键的创建和应用,以及快捷键与插件的协同工作,并提供了快捷键冲突的诊断与解决方法。通过实践操作演示与案例分析,展
STM32 HardFault异常终极指南:13个实用技巧揭示调试与预防策略
# 摘要
STM32微控制器中的HardFault异常是常见的系统错误之一,其发生会立即打断程序执行流程,导致系统不稳定甚至崩溃。本文首先介绍了HardFault异常的基础知识,随后深入探讨了其成因,包括堆栈溢出、中断优先级配置不当和内存访问错误等。硬件与软件层面的异常触发机制也是本文研究的重点。在此基础上,本文提出了有效的预防策略,涵盖了编
AD19快捷键高级应用:构建自动化工作流的必杀技

# 摘要
本文系统地介绍了AD19软件中快捷键的使用概览、高级技巧和自动化工作流构建的基础与高级应用。文章从快捷键的基本操作开始,详细探讨了快捷键的定制、优化以及在复杂操作中的高效应用。之后,文章转向自动化工作流的构建,阐述了工作流自动化的概念、实现方式和自动化脚本的编辑与执行。在高级应用部分,文章讲解了如何通过快捷键和自动化脚本提升工作效率,并探索了跨平台操作和协
【迁移挑战】:跨EDA工具数据迁移的深度剖析与应对策略
# 摘要
随着电子设计自动化(EDA)技术的快速发展,数据在不同EDA工具间的有效迁移变得日益重要。本文概述了跨EDA工具数据迁移的概念及其必要性,并深入探讨了数据迁移的类型、模型、挑战与风险。通过实际案例研究,文章分析了成功的迁移策略,并总结了实施过程中的问题解决方法与性能优化技巧。最后,本文展望了人工智能、机器学习、云平台和大数据技术等新兴技术对EDA数据迁移未来趋势的影响,以及标准化进程和最佳实践的发展前景。
# 关键字
跨EDA工具数
系统工程分析:递阶结构模型的案例研究与实操技巧
# 摘要
递阶结构模型作为一种系统化分析和设计工具,在多个领域内得到了广泛应用,具有明确的层次划分和功能分解特点。本文首先介绍了递阶结构模型的基本概念和理论基础,随后通过不同行业案例,展示了该模型的实际应用效果和操作技巧。重点分析了模型在设计、构建、优化和维护过程中的关键步骤,并对面临的挑战进行了深入探讨。文章最终提出了针对现有挑战的解决策略,并对递阶结构模型的未来应用和发展趋势进行了展望。本文旨在为专业实践者提供实用的理论指导和实操建议
【实时操作系统】:医疗器械软件严苛时延要求的解决方案
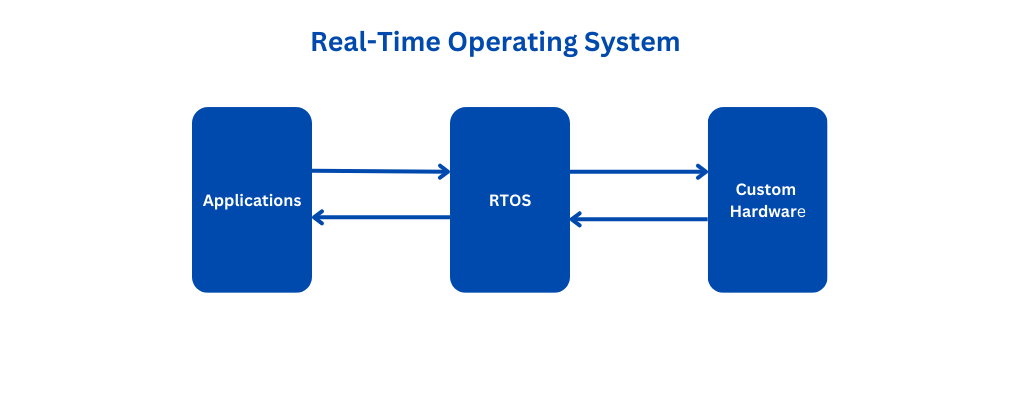
# 摘要
实时操作系统(RTOS)在医疗器械领域扮演着至关重要的角色,以其高可靠性和实时性保障了医疗设备的安全与效率。本文从RTOS的基础理论出发,详细讨论了硬实时与软实时的区别、性能指标、关键调度算法和设计原则。在应用层面,文章分析了医疗器械对RTOS的严格要求,并结合实际案例展示了RTOS在心电监护设备和医学影像处理中的应用。同时,文中还探讨了设计中面临的医疗标准、实时性与资源限制的挑战。技术实践章节阐述了R
快手短视频推荐系统协同过滤技术:用户与内容协同的智能算法

# 摘要
本论文全面概述了快手短视频推荐系统的关键技术与实践应用,详细介绍了协同过滤技术的理论基础,包括其原理、分类、数据处理及优缺点分析。此外,深入探讨了用户与内容协同推荐算法的设计与实践,以及推荐系统面临的技术挑战,如实时性、冷启动问题和可解释性。文章还通过案例分析,展示了短视频推荐系统的用户界面设计和成功推荐算法的实际应用。最后,展望了快手短视频推荐系统的未来发展方向,包括人工智能技术的潜在应用和推荐系统研究的新趋势。
# 关键字
短
S参数测量实战:实验室技巧与现场应用
# 摘要
S参数测量是微波工程中用于描述网络散射特性的参数,广泛应用于射频和微波电路的分析与设计。本文全面介绍了S参数测量的基础知识、实验室中的测量技巧、软件应用、现场应用技巧、高级分析与故障排除方法,以及该技术的未来发展趋势。通过对实验室和现场测量实践的详细阐述,以及通过软件进行数据处理与问题诊断的深入探讨,本文旨在提供一系列实用的测量与分析策略。此外,本文还对S参数测量技术的进步方向进行了预测,强调了教
Mike21FM网格生成功能进阶攻略:处理复杂地形的神技巧

# 摘要
本文详细介绍了Mike21FM网格生成功能,并分析了其在地形复杂性分析、网格需求确定、高级应用、优化与调试以及案例研究中的应用实践。文章首先概述了Mike21FM网格生成功能,然后深入探讨了地形复杂性对网格需求的影响,包括地形不规则性和水文动态
【UG901-Vivado综合技巧】:处理大型设计,你不可不知的高效方法

# 摘要
Vivado综合是现代数字设计流程中不可或缺的一步,它将高层次的设计描述转换为可实现的硬件结构。本文深入探讨了Vivado综合的基础理论,包括综合的概念、流程、优化理论,以及高层次综合(HLS)的应用。此外,本文还提供了处理大型设计、高效使用综合工具、解决常见问题的实践技巧。高级应用章节中详细讨论了针对特定设计的优化实例、IP核的集成与复用,以及跨时钟域设计的综合处理方
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )