使用Minikube进行本地Kubernetes(K8s)开发
发布时间: 2024-01-18 06:57:12 阅读量: 52 订阅数: 38 
# 1. 介绍Minikube和本地Kubernetes开发
## 1.1 什么是Minikube?
Minikube是一个轻量级的工具,用于在本地计算机上快速搭建一个单节点的Kubernetes集群。它可以模拟一个完整的Kubernetes环境,包括Master节点和Worker节点,提供了一种便捷的方式进行Kubernetes应用程序的开发、测试和调试。
## 1.2 为什么选择Minikube进行本地Kubernetes开发?
使用Minikube进行本地Kubernetes开发有以下几个优势:
- **便捷性**:Minikube可以在几分钟之内启动一个完整的Kubernetes集群,无需复杂的配置和安装步骤。
- **资源利用率**:Minikube在本地计算机上运行一个轻量级的Kubernetes集群,可以最大限度地利用硬件资源。
- **可移植性**:Minikube可以在多种操作系统和虚拟化平台上运行,使得应用程序可以在不同的开发环境中无缝迁移。
- **学习成本低**:Minikube提供了一个简单的接口和命令,使得开发人员可以快速上手并理解Kubernetes的核心概念和操作。
## 1.3 Minikube的优势和限制
使用Minikube进行本地Kubernetes开发具有以下优势:
- **快速启动**:Minikube可以在几分钟之内启动一个完整的Kubernetes集群,加快应用程序的开发和测试速度。
- **独立性**:Minikube在本地计算机上运行,不会影响其他正在运行的应用程序和服务。
- **易于管理**:Minikube提供了一组命令和工具,使得集群的管理变得简单易用。
然而,Minikube也有一些限制:
- **单节点集群**:Minikube仅支持单节点的Kubernetes集群,无法模拟复杂的多节点场景。
- **资源限制**:由于运行在本地计算机上,Minikube的资源受限于计算机的硬件性能和可用资源。
- **不适用于生产环境**:Minikube主要用于本地开发和测试,不适用于部署生产环境中的应用程序。
- **网络配置复杂**:在某些情况下,Minikube的网络配置可能会比较复杂,需要一定的网络知识和调试能力。
在接下来的章节中,我们将会详细介绍如何安装和设置Minikube,以及如何使用Minikube进行本地Kubernetes开发。
# 2. 安装和设置Minikube
Minikube是一种轻量级的工具,用于在本地环境中运行和测试Kubernetes集群。本章将介绍如何在不同平台上安装Minikube,以及如何设置Minikube和Kubectl,以便能够开始使用和管理本地Kubernetes集群。
### 2.1 在不同平台上安装Minikube
Minikube可以在多个操作系统平台上安装和运行,包括Windows、Mac和Linux。下面将以每个平台为例介绍Minikube的安装方法。
#### 2.1.1 Windows平台安装Minikube
在Windows平台上安装Minikube需要以下步骤:
1. 下载Minikube二进制文件。
```markdown
$ curl -LO https://storage.googleapis.com/minikube/releases/latest/minikube-windows-amd64.exe
```
2. 将Minikube可执行文件移动到系统的PATH目录。
```markdown
$ move minikube-windows-amd64.exe C:\Windows\Minikube\minikube.exe
```
3. 验证Minikube安装是否成功。
```markdown
$ minikube version
```
#### 2.1.2 Mac平台安装Minikube
在Mac平台上安装Minikube需要以下步骤:
1. 使用Homebrew包管理器安装Minikube。
```markdown
$ brew install minikube
```
2. 验证Minikube安装是否成功。
```markdown
$ minikube version
```
#### 2.1.3 Linux平台安装Minikube
在Linux平台上安装Minikube需要以下步骤:
1. 下载Minikube二进制文件。
```markdown
$ curl -LO https://storage.googleapis.com/minikube/releases/latest/minikube-linux-amd64
```
2. 赋予Minikube可执行权限。
```markdown
$ chmod +x minikube-linux-amd64
```
3. 将Minikube可执行文件移动到系统的PATH目录。
```markdown
$ sudo mv minikube-linux-amd64 /usr/local/bin/minikube
```
4. 验证Minikube安装是否成功。
```markdown
$ minikube version
```
### 2.2 设置Minikube和Kubectl
安装Minikube后,还需要设置Minikube和Kubectl,以便可以通过命令行进行集群管理和操作。
1. 启动Minikube集群。
```markdown
$ minikube start
```
2. 验证Minikube集群是否正常运行。
```markdown
$ minikube status
```
3. 设置kubectl使用Minikube集群。
```markdown
$ kubectl config use-context minikube
```
4. 验证kubectl与Minikube集群的连接。
```markdown
$ kubectl get nodes
```
### 2.3 启动和停止Minikube集群
在使用Minikube进行本地Kubernetes开发时,可以根据需要启动或停止Minikube集群。
1. 启动Minikube集群。
```markdown
$ minikube start
```
2. 停止Minikube集群。
```markdown
$ minikube stop
```
3. 删除Minikube集群。
```markdown
$ minikube delete
```
本章介绍了如何在不同平台上安装Minikube,以及如何设置和管理Minikube集群。下一章将介绍如何使用Kubectl部署应用程序。
# 3. Kubernetes应用程序部署
在本章中,我们将介绍如何使用Minikube和Kubectl部署应用程序到本地Kubernetes集群中。我们还将学习如何创建和管理Kubernetes资源,以及管理应用程序的配置和存储。
#### 3.1 使用Kubectl部署应用程序
Kubectl是Kubernetes的命令行工具,可以帮助我们与Kubernetes集群进行交互。要部署一个应用程序,我们可以使用Kubectl的`apply`命令,该命令通过读取配置文件的方式将应用程序的资源部署到集群中。
下面是一个简单的示例,以Python的Flask应用程序为例:
首先,我们需要编写一个Deployment的配置文件 `flask-deployment.yaml`,内容如下:
```yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: flask-app
spec:
replicas: 3
selector:
matchLabels:
app: flask-app
template:
metadata:
labels:
app: flask-app
spec:
containers:
- name: flask-app
image: flask-app:latest
ports:
- containerPort: 5000
```
然后,使用以下命令将部署应用程序到Kubernetes集群中:
```bash
kubectl apply -f flask-deployment.yaml
```
#### 3.2 创建和管理Kubernetes资源
除了Deployment,Kubernetes还有许多其他资源类型,如Service、ConfigMap、Secret等,它们可以帮助我们管理应用程序所需的各种资源。通过Kubectl,我们可以轻松地创建、查看和删除这些资源。
下面是一个创建Service资源的示例:
```yaml
apiVersion: v1
kind: Service
metadata:
name: flask-service
spec:
selector:
app: flask-app
ports:
- protocol: TCP
port: 80
targetPort: 5000
type: NodePort
```
使用以下命令创建Service:
```bash
kubectl apply -f flask-service.yaml
```
#### 3.3 管理应用程序配置和存储
Kubernetes提供了ConfigMap和Secret等资源类型,用于存储应用程序的配置信息和敏感数据。我们可以通过这些资源将配置信息注入到应用程序的环境变量中,或者作为文件挂载到应用程序的Pod中。
下面是一个创建ConfigMap资源的示例:
```yaml
apiVersion: v1
kind: ConfigMap
metadata:
name: app-config
data:
app.properties: |
key1=value1
key2=value2
```
使用以下命令创建ConfigMap:
```bash
kubectl apply -f app-config.yaml
```
以上是在本地Kubernetes集群中部署应用程序和管理资源的基本操作。在实际开发中,还会涉及到更多高级的概念和技术,如自动伸缩、监控和日志管理等,这些将在后续章节进行介绍。
# 4. 本地Kubernetes集群调试和测试
在进行本地Kubernetes开发时,调试和测试是非常重要的环节。本章将介绍如何使用Minikube进行调试和测试,以确保应用程序在集群中正常运行。
### 4.1 调试Kubernetes应用程序
调试Kubernetes应用程序在本地集群中通常可以通过以下几个步骤完成:
#### 步骤 1:查看应用程序日志
可以使用以下命令查看Pod的日志:
```bash
kubectl logs <pod-name>
```
这将输出Pod的日志信息,可以用来诊断应用程序的问题。
#### 步骤 2:进入容器内部
如果需要在容器内部运行命令,可以使用以下命令进入容器:
```bash
kubectl exec -it <pod-name> -- /bin/bash
```
这将以交互方式进入容器的bash终端,从而可以执行命令和调试应用程序。
#### 步骤 3:端口转发
如果应用程序暴露了端口,但是无法从本地访问,可以使用以下命令进行端口转发:
```bash
kubectl port-forward <pod-name> <local-port>:<container-port>
```
这将把容器的端口转发到本地,以便可以直接访问应用程序。
### 4.2 使用Minikube进行单元测试
在本地Kubernetes开发中,进行单元测试是非常重要的。Minikube提供了一些工具和特性,方便进行单元测试。
#### 使用Minikube的内部DNS解析服务
在进行单元测试时,我们可能需要访问其他Pod或服务。而Minikube提供了一个内部DNS解析服务,可以直接使用Pod或服务的名称进行解析。
例如,在Python中使用requests库发送HTTP请求,可以使用以下代码:
```python
import requests
response = requests.get("http://<service-name>")
```
Minikube的内部DNS解析服务将会解析出正确的service IP地址,从而可以正常访问服务。
#### 使用Minikube的虚拟LoadBalancer
在进行单元测试时,可能需要测试集群中的负载均衡器(Load Balancer)。而如果没有实际硬件或云平台的支持,可以使用Minikube的虚拟LoadBalancer。
可以通过以下命令创建一个虚拟LoadBalancer:
```bash
kubectl expose deployment <deployment-name> --type=LoadBalancer
```
然后可以使用以下命令查看虚拟LoadBalancer的IP地址:
```bash
minikube service <service-name> --url
```
通过这个IP地址可以直接访问负载均衡器的服务。
### 4.3 监控本地Kubernetes集群
在本地Kubernetes开发中,监控集群的健康状态是很重要的。Minikube提供了一些工具和特性,方便进行集群监控。
#### 使用Minikube的Dashboard
Minikube提供了一个内置的Dashboard,可以用于监控集群的健康状态、查看资源使用情况等。
可以通过以下命令打开Dashboard:
```bash
minikube dashboard
```
然后可以通过浏览器访问`http://localhost:8001/api/v1/namespaces/kubernetes-dashboard/services/http:kubernetes-dashboard:/proxy/`来查看Dashboard。
#### 使用Heapster进行资源监控
Heapster是Kubernetes的一个插件,可以用于监控集群的资源使用情况、容器的性能指标等。
可以通过以下命令安装Heapster:
```bash
minikube addons enable heapster
```
然后可以通过以下命令查看Heapster的监控信息:
```bash
minikube addons open heapster
```
这将打开一个基于Grafana的监控界面,可以查看集群的资源使用情况和容器的性能指标。
以上是使用Minikube进行本地Kubernetes集群调试和测试的一些常见方法和工具。
本章介绍了如何通过查看应用程序日志、进入容器内部、进行端口转发等方式进行调试。同时也介绍了如何使用Minikube的工具和特性进行单元测试和集群监控。
在下一章节中,我们将讨论本地开发中的常见问题和解决方案。
# 5. 本地开发中的常见问题和解决方案
在进行本地Kubernetes开发过程中,可能会遇到一些常见问题,比如网络和存储配置、资源限制和性能优化,以及容器和镜像管理的挑战。本章将介绍这些常见问题,并提供相应的解决方案。
#### 5.1 网络和存储配置
在本地Kubernetes开发中,经常需要配置网络和存储来满足应用程序的需求。例如,需要创建Persistent Volume(PV)来持久化存储数据,或者配置Ingress来管理应用程序的入口流量。以下是一些常见的解决方案:
```yaml
# 示例:配置Persistent Volume
apiVersion: v1
kind: PersistentVolume
metadata:
name: example-pv
spec:
capacity:
storage: 1Gi
volumeMode: Filesystem
accessModes:
- ReadWriteOnce
hostPath:
path: /data
# 示例:配置Ingress
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: example-ingress
spec:
rules:
- host: example.com
http:
paths:
- pathType: Prefix
path: "/"
backend:
service:
name: example-service
port:
number: 80
```
#### 5.2 资源限制和性能优化
在本地Kubernetes集群中,需要合理地设置资源限制和优化性能,以确保应用程序能够稳定运行。可以通过定义资源请求和限制(Resource Requests and Limits)来对应用程序进行调优。以下是一个基本的资源请求和限制示例:
```yaml
apiVersion: v1
kind: Pod
metadata:
name: example-pod
spec:
containers:
- name: example-container
image: nginx
resources:
requests:
memory: "64Mi"
cpu: "250m"
limits:
memory: "128Mi"
cpu: "500m"
```
#### 5.3 容器和镜像管理
在本地Kubernetes开发中,需要管理容器和镜像,确保它们能够正确地构建、部署和运行。使用容器编排工具可以方便地管理容器的生命周期,而使用容器注册表可以有效地存储和分享镜像。以下是一些常见的容器和镜像管理操作:
```bash
# 构建镜像
docker build -t my-image:latest .
# 将镜像推送至注册表
docker push my-registry.com/my-image:latest
# 从注册表拉取镜像
docker pull my-registry.com/my-image:latest
```
通过以上解决方案,我们可以更好地应对本地Kubernetes开发中的常见问题,确保应用程序能够稳定、高效地运行。
# 6. 将本地开发的应用程序部署到生产环境
在本地开发和测试完成后,将应用程序部署到生产环境是至关重要的。本章将探讨如何从本地Kubernetes集群将应用程序迁移至生产环境,并介绍持续集成和持续部署(CI/CD)流程以及处理不同环境之间的配置和性能差异。
#### 6.1 从本地Kubernetes集群迁移至生产环境
迁移应用程序至生产环境需要考虑诸多因素,包括但不限于环境配置、安全性、性能和可扩展性。您可以使用Kubernetes的工具和最佳实践来简化这一迁移过程。首先,您需要创建一个生产环境的Kubernetes集群,并确保其与本地开发环境保持一致。随后,您可以使用Kubectl工具将应用程序配置和服务部署到生产环境。
#### 6.2 持续集成和持续部署(CI/CD)流程
在本地开发环境成功部署应用程序后,您可以考虑实施持续集成和持续部署流程。CI/CD工作流能够自动化构建、测试和部署应用程序,从而提高开发效率并减少人为错误。您可以选择不同的CI/CD工具,如Jenkins、GitLab CI、CircleCI等,并配置适当的流程以满足生产环境的需求。
#### 6.3 处理不同环境之间的配置和性能差异
生产环境与本地开发环境通常存在诸多差异,包括但不限于网络配置、数据库连接、安全设置和性能优化。因此,在将应用程序部署至生产环境之前,您需要仔细考虑并处理这些差异。可能的解决方案包括使用不同的配置文件、集成健康检查和负载均衡机制以确保高可用性,以及调整容器资源限制以满足生产环境的性能需求。
通过本章的指导,您将能够顺利将经过本地开发和测试的应用程序部署到生产环境,并建立起持续集成和持续部署的流程,同时处理不同环境之间的配置和性能差异。
现在让我们深入讨论如何从本地Kubernetes集群迁移至生产环境。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
《Kubernetes(K8s)快速入门》专栏全面介绍了Kubernetes的基本概念、安装、配置和各种实用功能的详细操作方法。从最初的Kubernetes是什么开始,逐步深入到在本地环境中安装和配置Kubernetes,使用Minikube进行本地开发,以及深入探讨Kubernetes中的Pod概念、容器化应用部署、Service和Ingress等重要功能。涵盖了如何创建和管理Pod、Service,利用Kubernetes进行应用的扩展和负载均衡,以及ConfigMap、Secret用法和自动化容器伸缩等内容。此外,还涵盖了Helm的使用、监控和日志管理、Jobs和CronJobs的实现,以及Kubernetes的安全最佳实践、故障排除和调试方法,最后介绍了Kubernetes中的网络策略。这些内容全面而深入,是Kubernetes初学者快速入门的良好指南。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
WLC3504配置实战手册:无线安全与网络融合的终极指南

# 摘要
WLC3504无线控制器作为网络管理的核心设备,在保证网络安全、配置网络融合特性以及进行高级网络配置方面扮演着关键角色。本文首先概述了WLC3504无线控制器的基本功能,然后深入探讨了其无线安全配置的策略和高级安全特性,包括加密、认证、访问控制等。接着,文章分析了网络融合功能,解释了无线与有线网络融合的理论与配置方法,并讨论
【802.11协议深度解析】RTL8188EE无线网卡支持的协议细节大揭秘

# 摘要
无线通信技术是现代社会信息传输的重要基础设施,其中802.11协议作为无线局域网的主要技术标准,对于无线通信的发展起到了核心作用。本文从无线通信的基础知识出发,详细介绍了802.11协议的物理层和数据链路层技术细节,包括物理层传输媒介、标准和数据传输机制,以及数据链路层的MAC地址、帧格式、接入控制和安全协议。同时,文章还探讨了RTL8188EE无线网
Allegro 172版DFM规则深入学习:掌握DFA Package spacing的实施步骤
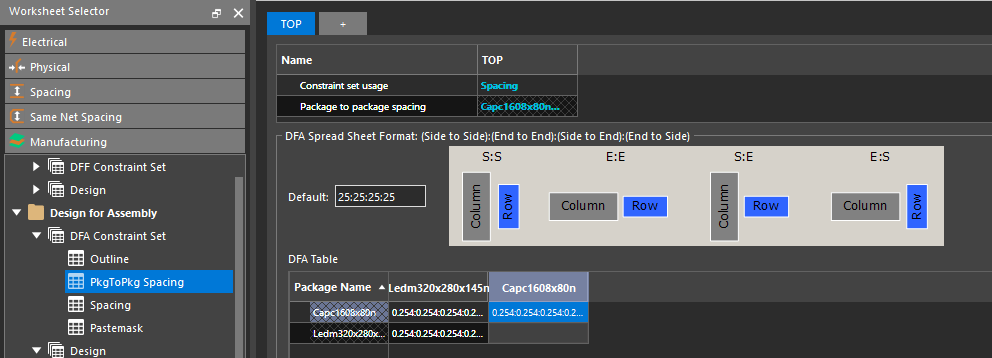
# 摘要
本文围绕Allegro PCB设计与DFM规则,重点介绍了DFA Package Spacing的概念、重要性、行业标准以及在Allegro软件中的实施方法。文章首先定义了DFA Packag
【AUTOSAR TPS深度解析】:掌握TPS在ARXML中的5大应用与技巧

# 摘要
本文系统地介绍了AUTOSAR TPS(测试和验证平台)的基础和进阶应用,尤其侧重于TPS在ARXML(AUTOSAR扩展标记语言)中的使用。首先概述了TPS的基本概念,接着详细探讨了TPS在ARXML中的结构和组成、配置方法、验证与测试
【低频数字频率计设计核心揭秘】:精通工作原理与优化设计要点

# 摘要
数字频率计作为一种精确测量信号频率的仪器,其工作原理涉及硬件设计与软件算法的紧密结合。本文首先概述了数字频率计的工作原理和测量基础理论,随后详细探讨了其硬件设计要点,包括时钟源选择、计数器和分频器的使用、高精度时钟同步技术以及用户界面和通信接口设计。在软件设计与算法优化方面,本文分析了不同的测量算法以
SAP用户管理精进课:批量创建技巧与权限安全的黄金平衡

# 摘要
随着企业信息化程度的加深,有效的SAP用户管理成为确保企业信息安全和运营效率的关键。本文详细阐述了SAP用户管理的各个方面,从批量创建用户的技术和方法,到用户权限分配的艺术,再到权限安全与合规性的要求。此外,还探讨了在云和移动环境下的用户管理高级策略,并通过案例研究来展示理论在实践中的应用。文章旨在为SAP系统管理员提供一套全面的用户管理解决方案,帮助他们优化管理流程,提
【引擎选择秘籍】《弹壳特攻队》挑选最适合你的游戏引擎指南

# 摘要
本文全面分析了游戏引擎的基本概念与分类,并深入探讨了游戏引擎技术核心,包括渲染技术、物理引擎和音效系统等关键技术组件。通过对《弹壳特攻队》游戏引擎实战案例的研究,本文揭示了游戏引擎选择和定制的过程,以及如何针对特定游戏需求进行优化和多平台适配。此外,本文提供了游戏引擎选择的标准与策略,强调了商业条款、功能特性以及对未来技术趋势的考量。通过案例分析,本
【指示灯识别的机器学习方法】:理论与实践结合
# 摘要
本文全面探讨了机器学习在指示灯识别中的应用,涵盖了基础理论、特征工程、机器学习模型及其优化策略。首先介绍了机器学习的基础和指示灯识别的重要性。随后,详细阐述了从图像处理到颜色空间分析的特征提取方法,以及特征选择和降维技术,结合实际案例分析和工具使用,展示了特征工程的实践过程。接着,讨论了传统和深度学习模
【卷积块高效实现】:代码优化与性能提升的秘密武器
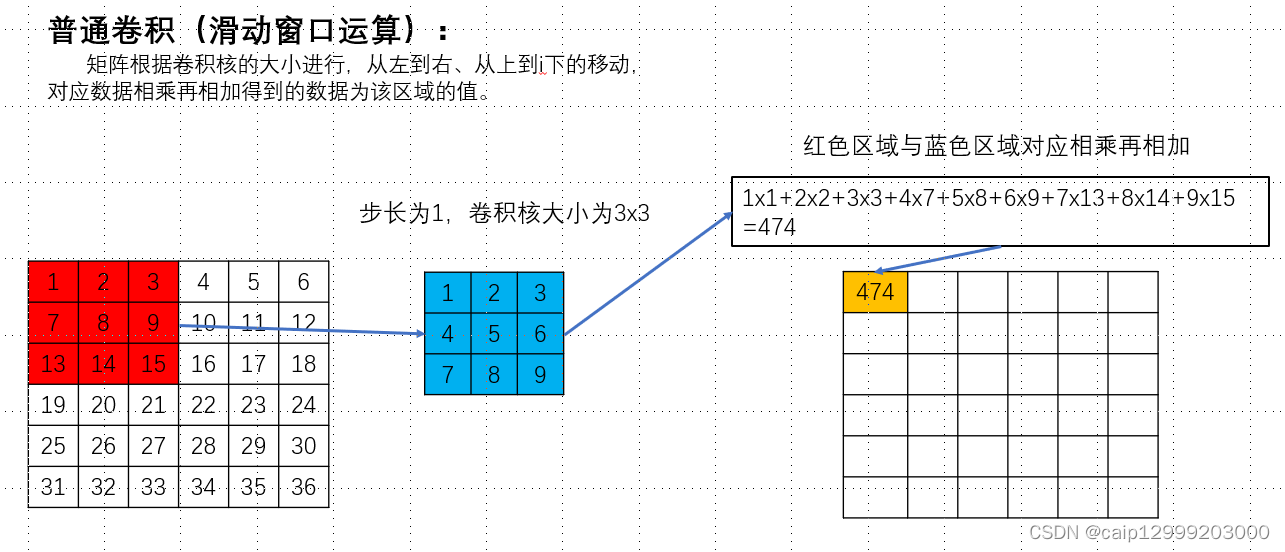
# 摘要
卷积神经网络(CNN)是深度学习领域的重要分支,在图像和视频识别、自然语言处理等方面取得了显著成果。本文从基础知识出发,深入探讨了卷积块的核心原理,包括其结构、数学模型、权重初始化及梯度问题。随后,详细介绍了卷积块的代码实现技巧,包括算法优化、编程框架选择和性能调优。性能测试与分析部分讨论了测试方法和实际应用中性能对比,以及优化策略的评估与选择。最后,展望了卷积块优化的未来趋势,包括新型架构、算法
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )