Gradle与持续集成:构建与部署的无缝衔接
发布时间: 2024-01-12 09:54:13 阅读量: 51 订阅数: 41 

燃料电池汽车Cruise整车仿真模型(燃料电池电电混动整车仿真模型) 1.基于Cruise与MATLAB Simulink联合仿真完成整个模型搭建,策略为多点恒功率(多点功率跟随)式控制策略,策略模
# 1. Gradle和持续集成简介
## 1.1 Gradle概述
Gradle是一款基于Apache Ant和Apache Maven概念的构建自动化工具。它使用一种基于Groovy的特定领域语言(DSL)来描述构建过程,允许开发人员将构建逻辑视为代码进行管理。
## 1.2 持续集成概念和重要性
持续集成是一种软件开发实践,旨在通过频繁地集成代码到共享存储库中,然后自动构建和测试代码,来尽早地发现和解决集成问题。持续集成有助于减少开发周期和在开发过程中发现和解决问题。
## 1.3 Gradle在持续集成中的作用
Gradle在持续集成中扮演着重要角色,它能够自动化构建和测试过程,确保代码质量和稳定性。通过与持续集成工具集成,如Jenkins、Travis CI和CircleCI等,Gradle能够实现自动化构建、测试和部署,从而加快软件交付速度。
# 2. 构建流程与工具
在软件开发的过程中,构建流程和工具是非常重要的环节。本章将介绍构建流程的概述、Gradle的基本用法与特性以及持续集成工具的介绍。让我们一起来深入了解!
#### 2.1 构建流程概述
软件项目的构建过程包括代码编译、单元测试、打包、部署等多个环节。在构建流程中,每个环节都需要有清晰的定义和规范,以确保软件质量和交付效率。构建流程的概述将会涉及这些环节的具体流程和关键点。
#### 2.2 Gradle的基本用法与特性
Gradle是一款基于Apache Ant和Apache Maven概念的构建自动化工具。它使用一种基于Groovy的特定领域语言(DSL)来定义项目设置和构建脚本。本节将介绍Gradle的基本用法,包括项目构建、任务定义、依赖管理等特性,以及与其他构建工具的对比和优势。
#### 2.3 持续集成工具介绍
持续集成工具可以帮助团队自动化构建、测试和部署软件。本节将介绍几种常用的持续集成工具,如Jenkins、Travis CI、CircleCI等,包括其特点、使用方法以及与Gradle的集成方式。
希望本章内容能够帮助你更好地理解构建流程和工具的重要性,以及掌握Gradle的基本用法和持续集成工具的选择。
# 3. Gradle配置与最佳实践
Gradle配置和最佳实践是持续集成过程中非常重要的一部分。在本章中,我们将深入探讨Gradle项目的配置和最佳实践,以及在持续集成中如何运用Gradle来达到最佳效果。
#### 3.1 Gradle项目配置
Gradle项目配置是指在构建过程中设置项目的各种属性和依赖关系。在这一节中,我们将学习如何编写一个基本的Gradle配置文件,包括项目结构、依赖管理和自定义任务等。
```gradle
// build.gradle
// 定义项目的基本信息
group 'com.example'
version '1.0'
// 应用Java插件
apply plugin: 'java'
// 依赖管理
repositories {
mavenCentral()
}
dependencies {
implementation 'com.google.guava:guava:30.1-jre'
testImplementation 'junit:junit:4.12'
}
// 自定义任务
task sayHello {
doLast {
println 'Hello, Gradle!'
}
}
```
在上述示例中,我们定义了一个基本的Gradle项目配置文件 `build.gradle`,包括了项目的基本信息、Java插件的应用、依赖管理和自定义任务。这些配置将帮助我们构建一个基本的Java项目并执行自定义任务。
#### 3.2 构建脚本最佳实践
在持续集成过程中,良好的构建脚本实践可以提高项目的构建效率和可维护性。下面是一些Gradle构建脚本的最佳实践:
- 尽量避免在构建脚本中硬编码配置信息,而是通过外部配置文件或环境变量来管理敏感信息。
- 使用函数或插件来封装重复的构建逻辑,以提高构建脚本的可读性和可维护性。
- 合理使用Gradle的生命周期任务(如 `doFirst`、`doLast`)来控制任务执行的顺序,以确保任务的依赖关系正确设置。
#### 3.3 持续集成中的Gradle配置技巧
在持续集成环境中,合理的Gradle配置可以帮助我们更好地管理项目的构建流程和依赖关系。以下是一些持续集成中常用的Gradle配置技巧:
- 在持续集成工具中,通过缓存依赖项和构建结果,加快构建速度。
- 使用Gradle的构建缓存功能,以使增量构建更高效。
- 结合持续集成工具的钩子和触发器,实现自动化的构建和部署流程。
以上是Gradle配置与最佳实践的一些内容,通过合理的配置和实践,可以使Gradle在持续集成中发挥更大的作用,提高项目的构建效率和质量。
希

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
《gradle实战》专栏深入探讨了Gradle构建工具的各个方面,从基本概念到高级实战技巧无一不包括。专栏以"初探Gradle"为开篇,详细介绍了构建工具的基本概念与用法,随后逐步深入探讨了项目结构、任务管理、依赖管理、插件开发等方面。文章涵盖了多模块项目实践与配置、自定义构建逻辑、任务分析等高级话题,并介绍了优化构建性能的实用技巧与策略。此外,专栏还覆盖了持续集成、测试、编译、代码质量、性能优化、持续交付等方面与Gradle的紧密结合,以及在Java、Android开发、Spring框架、数据库迁移等领域的实际应用。通过本专栏的学习,读者不仅可以熟练掌握Gradle的基本使用,还能够深入理解并灵活运用Gradle进行项目构建、优化性能和实现持续集成与交付。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
Madagascar程序安装详解:手把手教你解决安装难题

# 摘要
Madagascar是一套用于地球物理数据处理与分析的软件程序。本文首先概述了Madagascar程序的基本概念、系统要求,然后详述了其安装步骤,包括从源代码、二进制包安装以及容器技术部署的方法。接下来,文章介绍了如何对Madagascar程序进行配置与优化,包括
【Abaqus动力学仿真入门】:掌握时间和空间离散化的关键点

# 摘要
本文综合概述了Abaqus软件在动力学仿真领域的应用,重点介绍了时间离散化和空间离散化的基本理论、选择标准和在仿真实践中的重要性。时间离散化的探讨涵盖了不同积分方案的选择及其适用性,以及误差来源与控制策略。空间离散化部分详细阐述了网格类型、密度、生成技术及其在动力学仿真中的应用。在动力学仿真实践操作中,文中给出了创建模型、设置分析步骤、数据提取和后处理的具体指导。最后,本文还探讨了非线
精确控制每一分电流:Xilinx FPGA电源管理深度剖析
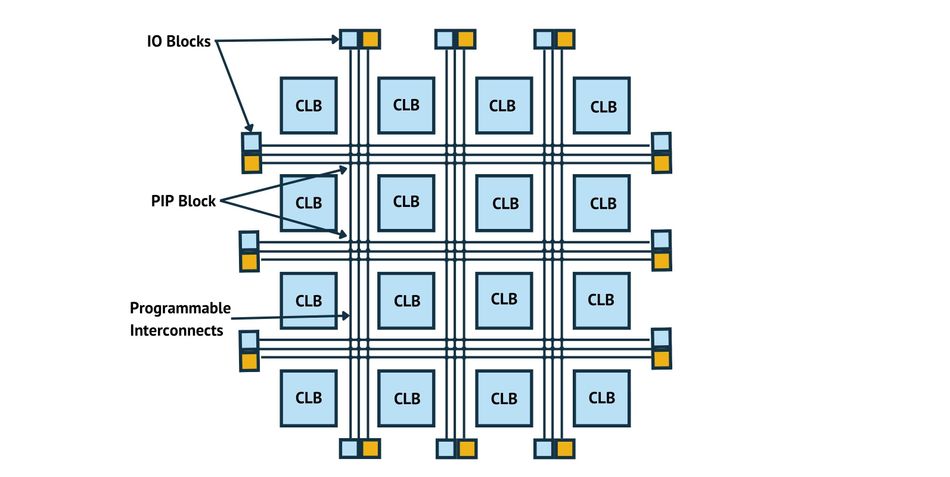
# 摘要
本文全面介绍并分析了FPGA电源管理的各个方面,从电源管理的系统架构和关键技术到实践应用和创新案例。重点探讨了Xilinx F
三维激光扫描技术在行业中的12个独特角色:从传统到前沿案例
# 摘要
三维激光扫描技术是一种高精度的非接触式测量技术,广泛应用于多个行业,包括建筑、制造和交通。本文首先概述了三维激光扫描技术的基本概念及其理论基础,详细探讨了其工作原理、关键参数以及分类方式。随后,文章通过分析各行业的应用案例,展示了该技术在实际操作中的实践技巧、面临的挑战以及创新应用。最后,探讨了三维激光扫描技术的前沿发展和行业发展趋势,强调了技术创新对行业发展的推动作用。本研究旨在为相关行业提供技术应用和发展的参考,促进三维激光扫描技术的进一步普及和深化应用。
# 关键字
三维激光扫描技术;非接触式测量;数据采集与处理;精度与分辨率;多源数据融合;行业应用案例
参考资源链接:[三维
【深入EA】:揭秘UML数据建模工具的高级使用技巧

# 摘要
UML数据建模是软件工程中用于可视化系统设计的关键技术之一。本文旨在为读者提供UML数据建模的基础概念、工具使用和高级特性分析,并探讨最佳实践以及未来发展的方向。文章从数据建模的基础出发,详细介绍了UML数据建模工具的理论框架和核心要素,并着重分析了模型驱动架构(MDA)以及数据建模自动化工具的应用。文章进一步提出了数据建模的优化与重构策略,讨论了模式与反模式,并通过案例研究展示了UML数据建模
CPCI标准2.0合规检查清单:企业达标必知的12项标准要求

# 摘要
CPCI标准2.0作为一项广泛认可的合规性框架,旨在为技术产品与服务提供清晰的合规性指南。本文全面概述了CPCI标准2.0的背景、发展、核心内容及其对企业和行业的价值。通过对标准要求的深入分析,包括技术、过程及管理方面的要求,本文提供了对合规性检查工具和方法的理解,并通过案例研究展示了标准的应用与不合规的后果。文章还探讨了实施前的准备工作、实施过程中的
【系统管理捷径】:Win7用户文件夹中Administrator.xxx文件夹的一键处理方案
/i.s3.glbimg.com/v1/AUTH_08fbf48bc0524877943fe86e43087e7a/internal_photos/bs/2021/z/U/B8daU9QrCGUjGluubd2Q/2013-02-19-ao-clicar-em-detalhes-reparem
RTD2555T应用案例分析:嵌入式系统中的10个成功运用

# 摘要
RTD2555T芯片作为嵌入式系统领域的重要组件,因其高效能和高度集成的特性,在多种应用场合显示出显著优势。本文首先介绍了RTD2555T芯片的硬件架构和软件支持,深入分析了其在嵌入式系统中的理论基础。随后,通过实际应用案例展示了RTD2555T芯片在工业控制、消费电子产品及汽车电子系统中的多样
按键扫描技术揭秘:C51单片机编程的终极指南

# 摘要
本文全面介绍了按键扫描技术的基础知识和应用实践,首先概述了C51单片机的基础知识,包括硬件结构、指令系统以及编程基础。随后,深入探讨了按键扫描技术的原理,包括按键的工作原理、基本扫描方法和高级技术。文章详细讨论了C51单片机按键扫描编程实践,以及如何实现去抖动和处理复杂按键功能。最后,针对按键扫描技术的优化与应用进行了探讨,包括效率优化策略、实际项目应用实例以及对未来趋势的预
【C语言数组与字符串】:K&R风格的处理技巧与高级应用
# 摘要
本论文深入探讨了C语言中数组与字符串的底层机制、高级应用和安全编程实践。文章首先回顾了数组与字符串的基础知识,并进一步分析了数组的内存布局和字符串的表示方法。接着,通过比较和分析C语言标准库中的关键函数,深入讲解了数组与字符串处理的高级技巧。此外,文章探讨了K&R编程风格及其在现代编程实践中的应用,并研究了在动态内存管理、正则表达式以及防御性编程中的具体案例。最后,通过对大型项目和自定义数据结构中数组与字符串应用的分析,
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )