Muma包深度解析:R语言数据探索与模型构建的实战指南
发布时间: 2024-12-24 02:31:48 阅读量: 5 订阅数: 8 

R语言代谢组学数据分析.zip

# 摘要
本文详细介绍了Muma包的功能、安装配置、数据探索基础、数据可视化方法、统计模型构建与分析,以及在实战案例中的应用,并展望了Muma包的高级功能与未来发展。Muma包不仅支持多样化数据结构的导入和预处理,还提供了丰富的数据探索、描述性统计分析和图形展现功能。文章深入探讨了统计模型在数据分析中的应用,并通过金融数据分析和市场调研分析两个案例展示了Muma包的实际效用。最后,本文讨论了Muma包的扩展功能和在人工智能、大数据分析等领域的未来应用方向,以及社区贡献和开源生态的重要性。
# 关键字
Muma包;数据探索;数据可视化;统计模型;案例分析;未来发展
参考资源链接:[muma R包:代谢组学分析教程与实例](https://wenku.csdn.net/doc/548s39hcex?spm=1055.2635.3001.10343)
# 1. Muma包简介与安装配置
## 1.1 Muma包概述
Muma包是针对数据分析和数据科学领域设计的一个综合性工具包,它集成了数据处理、探索分析、可视化以及统计模型构建等多种功能。该包广泛应用于金融、市场研究、医疗和教育等多个行业,对于需要进行复杂数据分析的IT专业人士来说,Muma包可以极大地提高工作效率和分析的深度。
## 1.2 安装Muma包
在安装Muma包之前,请确保您的计算机上已经安装了R语言环境。如果尚未安装,可以访问R语言官方网站下载并安装最新版本。在R语言环境中,可以通过以下命令安装Muma包:
```R
install.packages("Muma")
```
此命令将从CRAN(综合R档案网络)下载并安装Muma包。
## 1.3 配置与初始化
安装完成后,接下来进行包的加载和基础配置。加载Muma包并进行初始设置如下:
```R
library(Muma)
# Muma包的一些基础配置可以在这里设置,例如:
# 初始化Muma包的数据集路径
options(Muma.dataset.path = "path/to/your/datasets")
```
在完成Muma包的安装和基本配置之后,就可以开始进行数据探索和分析了。接下来的章节将深入介绍Muma包的核心功能,帮助用户充分发挥这个强大的工具包的作用。
# 2. 数据探索基础
## 2.1 数据探索的概念与重要性
### 2.1.1 数据探索的定义
数据探索是数据分析的第一步,它涉及使用统计度量和可视化技术来理解数据集的基本特征。在这一阶段,数据分析师会努力回答关于数据的几个核心问题:数据集包含了哪些信息?数据的结构如何?数据集中存在什么异常或偏差?数据探索的答案将为后续的深入分析提供方向。
### 2.1.2 数据探索的作用
数据探索的作用是为后续的数据分析和建模工作打下坚实的基础。通过数据探索,我们可以识别数据集中的有用信息,发现数据的潜在模式和异常值,以及检查数据的完整性和质量。这一过程不仅帮助我们理解数据的分布和关联性,还能够为数据清洗、变量转换和最终模型的选择提供依据。
## 2.2 Muma包的数据结构
### 2.2.1 Muma包支持的数据类型
Muma包支持多种数据类型,包括但不限于数值型、分类型、时间序列型数据等。这为用户处理不同类型的数据提供了极大的灵活性。在实际操作中,Muma包允许用户轻松地进行数据转换和类型识别。
```r
# 示例代码:数据类型转换与检查
# 加载Muma包
library(Muma)
# 创建一个包含不同类型的数据集
data <- data.frame(
id = 1:100,
category = sample(c("A", "B", "C"), 100, replace = TRUE),
numeric_var = rnorm(100),
date = Sys.Date() - sample(1:100, 100)
)
# 使用str()函数检查数据类型
str(data)
# 转换数据类型
data$numeric_var <- as.numeric(data$numeric_var)
data$date <- as.Date(data$date)
```
### 2.2.2 数据集的导入与预处理
在数据探索过程中,数据的导入和预处理至关重要。Muma包提供了多种函数来导入数据集,如`read_csv()`, `read_excel()`, `read_table()`等,并允许数据分析师进行初步的预处理,包括数据清洗、缺失值处理和异常值检测。
```r
# 示例代码:数据导入与预处理
# 导入数据集
data <- read_csv("path_to_file.csv")
# 检查数据集的前几行
head(data)
# 缺失值处理
data[is.na(data)] <- median(data, na.rm = TRUE)
# 异常值检测
boxplot(data$numeric_var)
```
## 2.3 描述性统计分析
### 2.3.1 中心趋势度量
中心趋势是描述数据集中趋势的统计量,它可以帮助我们理解数据的集中位置。常用的中心趋势度量包括平均值、中位数和众数。Muma包提供了计算这些度量的函数,可以快速得到结果。
```r
# 示例代码:计算中心趋势度量
# 计算平均值
mean(data$numeric_var)
# 计算中位数
median(data$numeric_var)
# 计算众数
library(modes)
modes(data$numeric_var)
```
### 2.3.2 离散程度度量
离散程度度量用于描述数据的分布范围,常见的包括方差、标准差和范围。通过这些度量,分析师可以评估数据的稳定性和变化性。
```r
# 示例代码:计算离散程度度量
# 计算方差
var(data$numeric_var)
# 计算标准差
sd(data$numeric_var)
# 计算范围
max(data$numeric_var) - min(data$numeric_var)
```
### 2.3.3 分布形态和位置度量
分布形态和位置度量提供了关于数据分布的更深入理解。偏度和峰度是衡量数据分布形态的两个重要指标。偏度告诉我们分布是否对称,而峰度则反映了分布的尖峭程度。
```r
# 示例代码:计算分布形态和位置度量
# 计算偏度
skewness(data$numeric_var)
# 计算峰度
kurtosis(data$numeric_var)
```
通过以上各小节的介绍,Muma包的数据探索基础能力得到了初步的展示,从数据类型的支持,到数据集的导入与预处理,再到描述性统计分析的多种度量,Muma包提供了一系列强大的工具和函数。这些工具不仅方便了数据分析师对数据进行快速且深入的理解,而且为后续的数据处理和分析工作奠定了坚实的基础。
# 3. 数据可视化与图形展现
## 3.1 基础图形绘制
数据可视化是数据分析中不可或缺的一环,它使得复杂的数据集能够以直观易懂的形式呈现。基础图形绘制是数据可视化的起点,为后续的深入分析打下坚实的基础。
### 3.1.1 常用的图形类型
在数据分析和探索阶段,常用的图形类型包括条形图、柱状图、折线图、饼图和散点图等。这些图形各有其应用场景:
- **条形图和柱状图**:用于展示不同类别的频率分布,适合比较分类数据。
- **折线图**:常用于显示趋势变化,例如时间序列数据。
- **饼图**:用来展示比例关系,适用于分类数据。
- **散点图**:用于探索两个变量之间的关系,常用于初步识别变量间的相关性。
### 3.1.2 自定义图形属性
在使用Muma包进行图形绘制时,可以通过自定义图形属性来提升图形的美观性和信息表达效果。这包括但不限于调整颜色、添加标题、图例、标签、网格线等。例如:
```r
# 使用Muma包绘制散点图,并自定义图形属性
scatter_plot <- muma_plot(data, aes(x = var1, y = var2)) +
geom_point()
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
专栏《R包Muma补充资料》是一份全面的指南,深入探讨了R语言中强大的Muma包。它涵盖了Muma包的广泛应用,包括数据预处理、数据探索、模型构建、数据可视化和数据整合。专栏提供了7大高效数据预处理技巧、处理复杂数据集的高级技巧、优化R数据分析的常见误区、以及在多数据源环境中运用Muma包的策略。此外,专栏还介绍了Muma包在社交网络数据分析、机器学习数据预处理、数据筛选、数据汇总、异常值检测、交互性分析和探索性分析中的应用。通过案例分析和实战指南,专栏帮助读者掌握Muma包的高级功能,提升R语言中的数据处理效率和质量。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
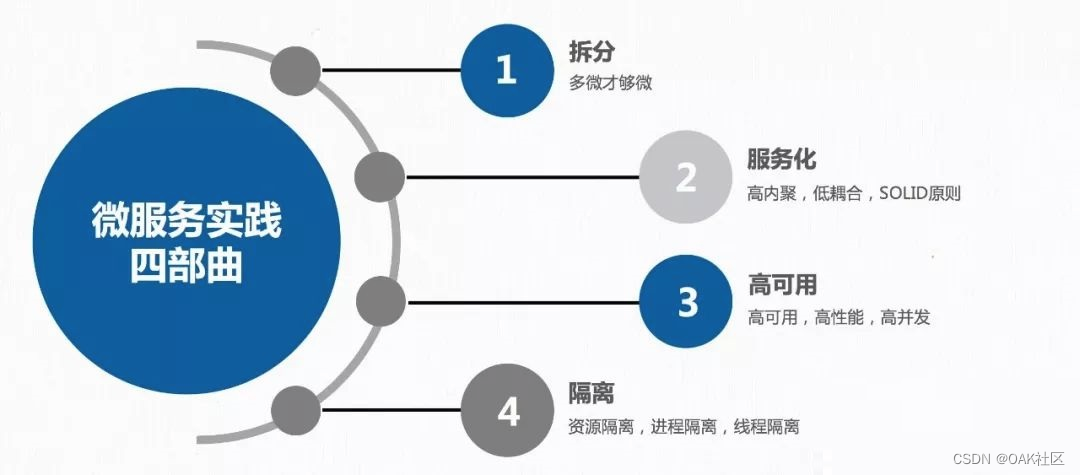
构建可扩展的微服务架构:系统架构设计从零开始的必备技巧
# 摘要
微服务架构作为一种现代化的分布式系统设计方法,已成为构建大规模软件应用的主流选择。本文首先概述了微服务架构的基本概念及其设计原则,随后探讨了微服务的典型设计模式和部署策略,包括服务发现、通信模式、熔断容错机制、容器化技术、CI/CD流程以及蓝绿部署等。在技术栈选择与实践方面,重点讨论了不同编程语言和框架下的微服务实现,以及关系型和NoSQL数据库在微服务环境中的应用。此外,本文还着重于微服务监控、日志记录和故障处理的最佳实践,并对微服
NYASM最新功能大揭秘:彻底释放你的开发潜力
# 摘要
NYASM是一个功能强大的汇编语言工具,支持多种高级编程特性并具备良好的模块化编程支持。本文首先对NYASM的安装配置进行了概述,并介绍了其基础与进阶语法。接着,本文探讨了NYASM在系统编程、嵌入式开发以及安全领域的多种应用场景。文章还分享了NYASM的高级编程技巧、性能调优方法以及最佳实践,并对调试和测试进行了深入讨论。最后,本文展望了NYASM的未来发展方向,强调了其与现代技
【ACC自适应巡航软件功能规范】:揭秘设计理念与实现路径,引领行业新标准

# 摘要
自适应巡航控制(ACC)系统作为先进的驾驶辅助系统之一,其设计理念在于提高行车安全性和驾驶舒适性。本文从ACC系统的概述出发,详细探讨了其设计理念与框架,包括系统的设计目标、原则、创新要点及系统架构。关键技术如传感器融合和算法优化也被着重解析。通过介绍ACC软件的功能模块开发、测试验证和人机交互设计,本文详述了系统的实现
ICCAP调优初探:提效IC分析的六大技巧

# 摘要
ICCAP(Image Correlation for Camera Pose)是一种用于估计相机位姿和场景结构的先进算法,广泛应用于计算机视觉领域。本文首先概述了ICCAP的基础知识和分析挑战,深入探讨了ICCAP调优理论,包括其分析框架的工作原理、主要组件、性能瓶颈分析,以及有效的调优策略。随后,本文介绍了ICCAP调优实践中的代码优化、系统资源管理优化和数据处理与存储优化
LinkHome APP与iMaster NCE-FAN V100R022C10协同工作原理:深度解析与实践

# 摘要
本文首先介绍了LinkHome APP与iMaster NCE-FAN V100R022C10的基本概念及其核心功能和原理,强调了协同工作在云边协同架构中的作用,包括网络自动化与设备发现机制。接下来,本文通过实践案例探讨了LinkHome APP与iMaster NCE-FAN V100R022C1
紧急掌握:单因子方差分析在Minitab中的高级应用及案例分析
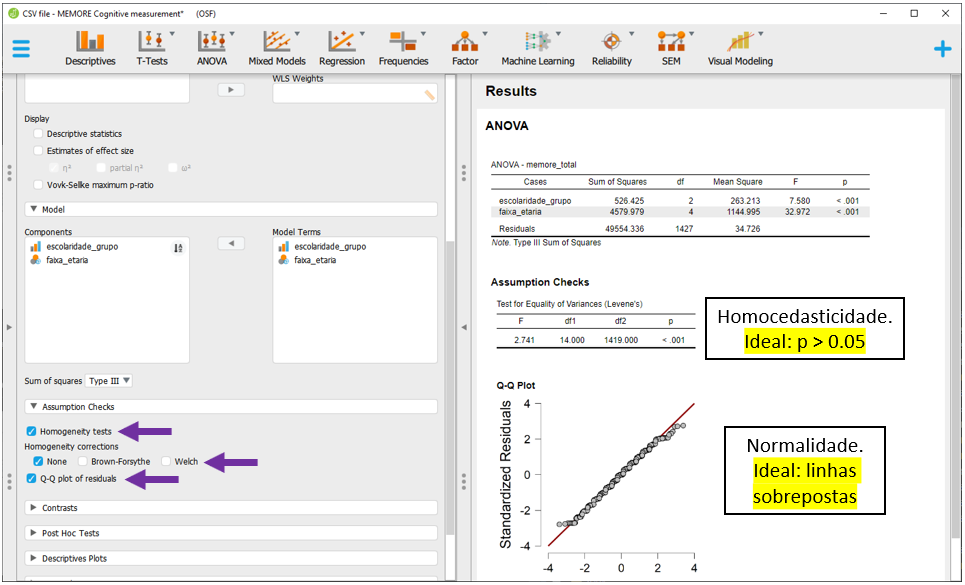
# 摘要
本文详细介绍了单因子方差分析的理论基础、在Minitab软件中的操作流程以及实际案例应用。首先概述了单因子方差分析的概念和原理,并探讨了F检验及其统计假设。随后,文章转向Minitab界面的基础操作,包括数据导入、管理和描述性统计分析。第三章深入解释了方差分析表的解读,包括平方和的计算和平均值差异的多重比较。第四章和第五章分别讲述了如何在Minitab中执行单因子方
全球定位系统(GPS)精确原理与应用:专家级指南

# 摘要
本文对全球定位系统(GPS)的历史、技术原理、应用领域以及挑战和发展方向进行了全面综述。从GPS的历史和技术概述开始,详细探讨了其工作原理,包括卫星信号构成、定位的数学模型、信号增强技术等。文章进一步分析了GPS在航海导航、航空运输、军事应用以及民用技术等不同领域的具体应用,并讨论了当前面临的信号干扰、安全问题及新技术融合的挑战。最后,文
AutoCAD VBA交互设计秘籍:5个技巧打造极致用户体验
# 摘要
本论文系统介绍了AutoCAD VBA交互设计的入门知识、界面定制技巧、自动化操作以及高级实践案例,旨在帮助设计者和开发者提升工作效率与交互体验。文章从基本的VBA用户界面设置出发,深入探讨了表单和控件的应用,强调了优化用户交互体验的重要性。随后,文章转向自动化操作,阐述了对象模型的理解和自动化脚本的编写。第三部分展示了如何应用ActiveX Automation进行高级交互设计,以及如何定制更复杂的用户界面元素,以及解决方案设计过程中的用户反馈收集和应用。最后一章重点介绍了VBA在AutoCAD中的性能优化、调试方法和交互设计的维护更新策略。通过这些内容,论文提供了全面的指南,以应
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )