医疗电子病历数仓维度模型设计【数据模型构建】维度建模理论方法
发布时间: 2024-03-19 18:26:09 阅读量: 94 订阅数: 21 
# 1. 引言
## 背景介绍
在当今数字化时代,医疗行业的数据量不断增加,医疗信息化已成为医疗健康领域的重要趋势之一。医疗电子病历作为医疗信息化的核心组成部分,记录了患者的病历信息、诊疗过程和医疗结果等重要数据。随着医疗信息化的深入发展和医疗大数据的应用,对医疗电子病历数据的管理、分析和利用提出了更高要求。
## 目的和意义
本文旨在探讨医疗电子病历数据仓库的设计与维度模型构建,旨在帮助医疗机构更好地管理和分析电子病历数据,提升医疗服务质量和效率。通过建立结构化、规范化的数据仓库和维度模型,实现对医疗数据的多维分析和挖掘,为决策提供更有力的支持。
## 研究方法和框架
本文将采用文献综述、理论分析和实例分析相结合的方法,从医疗电子病历的特点与挑战、数据仓库与维度模型概述、医疗电子病历数据仓库维度模型设计等方面展开研究。通过对现有医疗数据管理和分析方法的总结和比较,提出适合医疗电子病历数据管理的维度模型设计方法。
# 2. 医疗电子病历的特点与挑战
- **医疗行业的数据特点**
- **传统病历管理存在的问题**
- **电子病历的优势和应用**
# 3. 数据仓库与维度模型概述
在本章中,我们将深入探讨数据仓库和维度模型的概念,以及为医疗电子病历设计维度模型的必要性。以下是具体内容:
- **数据仓库概念与作用:** 数据仓库是用于集成、存储和管理企业数据的系统,旨在支持决策制定和业务分析。它通过将来自不同来源的数据整合到一个统一的数据库中,为用户提供一致、准确的数据视图。
- **维度模型介绍:** 维度模型是一种用于描述业务过程的数据结构,包括维度表和事实表。维度表包含描述业务过程的维度属性,事实表则包含与这些维度相关的度量值。维度模型通常采用星型模式或雪花模式进行建模。
- **为医疗电子病历设计维度模型的必要性:** 在医疗领域,病历数据具有复杂的结构和关联,传统的数据管理方法已经无法满足对数据

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏关注医疗电子病历数仓维度模型设计,涵盖了数据准备、存储、系统架构、数据模型构建、数据仓库创建流程、数仓建模工具与技术、应用场景与挑战以及数据治理与优化等多个方面。文章内容包括数据准备区的设计、基础数据记录历史变化、数据融合与应用平台等;系统架构中用户终端实现方式、分层信息系统架构、实时数仓领域落地实践等方面;数据模型构建中的维度建模理论方法、结构化模板构建方法、多维特性数据集合设计等。同时还提及了数据仓库的创建流程、ETL工具的使用、数仓建模工具与技术,以及具体的应用场景如智能护理决策支持系统、智能检索系统等挑战。该专栏还探讨了医疗数据湖建设与治理,以及避免维度模型常见问题的指南,为医疗行业数据管理和应用提供全面指导。
专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
USB3 Vision应用案例:机器视觉部署的终极解决方案

参考资源链接:[USB3 Vision协议详解:工业相机的USB3.0标准指南](https://wenku.csdn.net/doc/6vpdqfiyj3?spm=1055.2635.3001.10343)
# 1. USB3 Vision技术概述
USB3 Vision是一种基于USB 3.0接口标准的工业数字摄像头通讯协议,它为机器视觉系统中的图像采集提供了一种统一的、标准化的方法。通过这种
FLAC3D计算精度控制法:确保模拟结果的可靠性策略
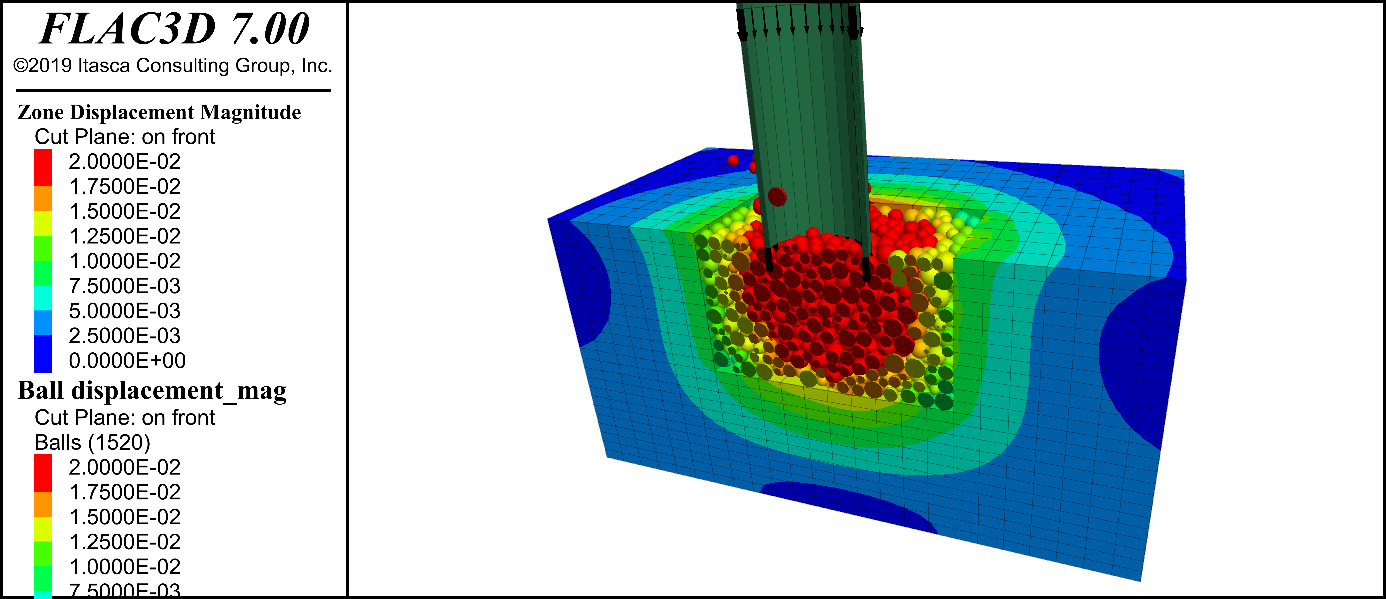
参考资源链接:[FLAC3D中文手册:入门与应用指南](https://wenku.csdn.net/doc/647d6d7e543f8444882a4634?spm=1055.2635.3001.10343)
# 1. FLAC3D软件概述
FLAC3D是专门用于岩土工程数值模拟的一套软件,它基于有限差分法(Finite Difference Method, FDM)来模拟三维空间内复杂的地质材料的行为。该软件
【多任务环境下的MX25L25645G】:挑战与策略
参考资源链接:[MX25L25645G:32M SPI Flash Memory with CMOS MXSMIO Protocol & DTR Support](https://wenku.csdn.net/doc/6v5a8g2o7w?spm=1055.2635.3001.10343)
# 1. MX25L25645G芯片概述与多任务环境介绍
在本章中,我们将了解MX25L25645G这一闪存芯片的基本信息,以及它在多任务处理环境中的定位。首先,我们将从MX25L25645G的基本概况开始,涵盖它的基本用途、性能特点以及如何在多任务环境中发挥其作用。
## 1.1 MX25L25645
【U8运行时错误安全漏洞防护】:检测与防范安全漏洞的有效措施

参考资源链接:[U8 运行时错误 440,运行时错误‘6’溢出解决办法.pdf](https://wenku.csdn.net/doc/644bc130ea0840391e55a560?spm=1055.2635.3001.10343)
# 1. U8运行
【PMF5.0移动应用适配】:随时随地工作的3大关键设置

参考资源链接:[PMF5.0操作指南:VOCs源解析实用手册](https://wenku.csdn.net/doc/6412b4eabe7fbd1778d4148a?spm=1055.2635.3001.10343)
# 1. PMF5.0移动应用适配概述
随着智能手机用户数量的激增和移动网络技术的飞速发展,移动应用的用户体验和性能成为竞争的关键点。PMF5.0作为行业内的领先解决
STM32 HAL库RTC实时时钟:时间管理与闹钟功能的应用

参考资源链接:[STM32CubeMX与STM32HAL库开发者指南](https://wenku.csdn.net/doc/6401ab9dcce7214c316e8df8?spm=1055.2635.3001.10343)
# 1. STM32 HAL库RTC实时时钟概述
STM32微控制器的实时
【LPDDR5的节能特性】:绿色计算新机遇的深入分析

参考资源链接:[LPDDR5详解:架构、比较与关键特性](https://wenku.csdn.net/doc/7spq8iipvh?spm=1055.2635.3001.10343)
# 1. LPDDR5内存技术概述
LPDDR5,即低功耗双倍数据速率5代内存,是LPDDR4的直接继承者,代表了移动设备内存技术的最新进展。它不仅在速度和带宽上实现了飞跃,还
DS3231时钟芯片电源管理:最佳策略与案例分析

参考资源链接:[DS3231:中文手册详解高性能I2C时钟芯片](https://wenku.csdn.net/doc/6412b6efbe7fbd1778d48808?spm=1055.2635.3001.10343)
# 1. DS3231时钟芯片概述
DS3231时钟芯片是Maxim Integrated生产的一款高精度实时时钟(RTC),通常用于需
【注册障碍克服】Spire.Doc for Java注册流程全解析

参考资源链接:[全面破解Spire.Doc for Java注册限制,实现全功能无限制使用](https://wenku.csdn.net/doc/1g1oinwimh?spm=1055.2635.3001.10343)
# 1. Spire.Doc for Java简介
## 1.1 Spire.Doc for Java概述
Spire.Doc for Java是Etarsoft公司推出的一款强大的文档
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )