【R语言进阶必备】:深入理解gmatrix数据包的矩阵操作(专家案例分析)
发布时间: 2024-11-11 05:09:44 阅读量: 42 订阅数: 36 

白色大气风格的建筑商业网站模板下载.rar

# 1. R语言和矩阵操作概述
## 1.1 R语言介绍
R语言是一种用于统计分析、图形表示和报告的编程语言和软件环境。它被广泛应用于数据挖掘、机器学习、生物信息学等领域。R语言以其强大的数学运算和数据处理能力,以及开源免费的特点,吸引了大量数据科学家和统计学家。
## 1.2 矩阵在R中的角色
在R语言中,矩阵是处理数据的基本单位之一。矩阵不仅可以存储大量的数据,还可以利用其数学性质进行高效的计算。矩阵运算是R语言中许多高级统计分析和数据处理功能的基础。
## 1.3 R语言矩阵操作基础
对于初学者而言,理解R语言中的矩阵操作是学习数据分析和统计建模的基石。本章将对R语言中矩阵的基本概念、创建、初始化、运算以及转换等进行概述,并为后续章节中使用gmatrix包进行矩阵操作和数据分析打下坚实的基础。
通过本章学习,读者将掌握R语言中矩阵操作的基本知识,为深入探索gmatrix包的功能和应用做好铺垫。
# 2. gmatrix包的基础矩阵操作
### 2.1 gmatrix包简介
在R语言的生态系统中,矩阵操作是一个非常重要的组成部分,尤其是在数据分析、机器学习、统计计算等领域。而`gmatrix`包作为一个功能强大的矩阵操作库,为用户提供了更加方便和高效的操作方式。
#### 2.1.1 安装和加载gmatrix包
安装`gmatrix`包可以使用以下命令:
```R
install.packages("gmatrix")
```
加载`gmatrix`包的操作如下:
```R
library(gmatrix)
```
#### 2.1.2 gmatrix包的主要功能和优势
`gmatrix`包相较于R语言的基础矩阵操作,其优势主要体现在以下几个方面:
- **易用性**:gmatrix包封装了复杂的矩阵操作,提供了一套简洁易懂的API接口。
- **性能**:在性能上,gmatrix包针对矩阵操作进行了优化,特别是在大规模矩阵处理上。
- **扩展性**:gmatrix包提供了丰富的矩阵操作函数,包括但不限于创建、访问、修改、合并等。
### 2.2 创建和初始化矩阵
#### 2.2.1 使用gmatrix构建矩阵
在R中,创建一个矩阵可以使用`matrix()`函数,而在gmatrix包中,我们可以使用`gm_matrix()`函数进行更加直观的操作:
```R
# 创建一个3x3的矩阵
A <- gm_matrix(1:9, nrow = 3, ncol = 3)
```
#### 2.2.2 矩阵维度与元素赋值
使用gmatrix包,可以非常方便地为矩阵指定维度,并对元素进行赋值:
```R
# 给定一个向量和维度,创建矩阵,并初始化值
B <- gm_matrix(c(1, 2, 3, 4), nrow = 2, ncol = 2)
# 赋值操作
B[2, 1] <- 5
```
### 2.3 矩阵的基本运算
#### 2.3.1 矩阵的加减乘除运算
矩阵的加减乘除在gmatrix包中有着简洁的表示:
```R
# 矩阵加法
C <- A + B
# 矩阵减法
D <- A - B
# 矩阵乘法
E <- A %*% B
# 矩阵除法(左除)
F <- solve(A) %*% B
```
#### 2.3.2 矩阵的转置与行列运算
转置和行列操作是矩阵操作中的基础,gmatrix包也提供了相应的功能:
```R
# 矩阵转置
A_transposed <- t(A)
# 提取矩阵的列
col1 <- A[, 1]
# 提取矩阵的行
row2 <- A[2, ]
```
### 2.4 小结
本章节介绍了`gmatrix`包的基础操作,包括安装、加载包、创建和初始化矩阵,以及矩阵的基本运算和转置操作。我们已经了解了gmatrix包在矩阵操作方面的优势,如易用性和扩展性,以及如何利用gmatrix进行更加简洁和高效的矩阵操作。
在下一章节中,我们将深入了解gmatrix包在执行高级矩阵操作中的技巧,例如矩阵的索引和切片、特殊矩阵的构建与应用以及矩阵分解与变换。这将帮助我们更好地掌握gmatrix包在处理复杂矩阵操作中的强大功能。
# 3. gmatrix包的高级矩阵操作技巧
## 3.1 矩阵的索引和切片
### 3.1.1 条件索引和布尔索引
在R语言中,条件索引是一种强大的工具,它允许我们根据特定条件选择矩阵中的元素。使用gmatrix包,我们可以轻松地利用条件索引来筛选出满足条件的数据。布尔索引是条件索引的一种特殊情况,其中条件表达式的结果是逻辑型(TRUE或FALSE),这使得它在矩阵操作中非常有用。
#### 使用布尔向量进行索引
通过布尔向量索引,我们可以快速地对矩阵的行或列进行筛选。例如,假设我们有一个矩阵 `m`,并希望选择所有第一列大于10的行:
```R
m <- gmatrix(c(11, 2, 3, 12, 5, 6), nrow = 2, ncol = 3)
filtered_rows <- m[m[,1] > 10, ]
```
在这段代码中,`m[,1] > 10` 生成了一个布尔向量,表示矩阵 `m` 第一列中哪些元素满足条件。然后,我们将这个布尔向量用作行索引,从而选择满足条件的行。
#### 逻辑运算符的结合使用
当我们需要结合多个条件进行索引时,可以使用逻辑运算符 `&`(和)、`|`(或)和 `!`(非)。例如,如果我们想选择矩阵中第一列大于10且第三列小于5的所有行和列:
```R
filtered_subset <- m[m[,1] > 10 & m[,3] < 5, ]
```
这段代码结合了两个条件来创建一个更复杂的索引。
### 3.1.2 使用索引和切片进行高级操作
通过gmatrix包,我们可以利用索引和切片技术进行一些高级矩阵操作,例如,插入、删除和替换特定的行或列。
#### 插入和删除行或列
要插入一行或一列,我们可以在矩阵末尾进行操作。删除行或列则需要使用逻辑索引来指定要删除的行或列。
```R
# 插入一行
new_row <- gmatrix(c(1, 2, 3), nrow = 1, ncol = 3)
m <- gmatrix(rbind(m, new_row), make.attr = FALSE)
# 删除一行
m <- m[m[,1] != 11, ]
```
在上面的示例中,我们首先创建了一个新行 `new_row`,然后使用 `rbind` 函数将其添加到 `m` 的底部。删除行的操作是通过排除特定条件的行来实现的。
#### 替换指定位置的元素
替换矩阵中特定位置的元素可以通过直接索引实现。例如,将第一行第二列的元素替换为20:
```R
m[1, 2] <- 20
```
这行代码将矩阵 `m` 中第一行第二列位置的元素更新为20。
#### 结合切片和函数进行操作
我们还可以结合使用切片和R语言的内置函数来执行复杂的操作。例如,如果我们想计算矩阵 `m` 的每一行的平均值并替换原来的行:
```R
row_means <- rowMeans(m)
m[] <- t(replicate(ncol(m), row_means))
```
这里,`rowMeans` 函数计算每一行的平均值,并将结果存储在 `row_means` 中。然后我们使用 `replicate` 和 `t` 函数来创建一个新的矩阵,其每一行都是 `row_means`,并用这个新矩阵替换 `m`。
## 3.2 特殊矩阵的构建与应用
### 3.2.1 对角矩阵、单位矩阵和零矩阵
在R语言中,gmatrix包提供了方便的函数来创建特殊类型的矩阵,包括对角矩阵、单位矩阵和零矩阵。这些矩阵在数学和数据分析中非常有用。
#### 对角矩阵
对角矩阵是一个只在主对角线上有非零元素的矩阵。在R中,我们可以使用 `diag()` 函数来创建对角矩阵。
```R
# 创建一个对角矩阵
diag_matrix <- diag(5)
```
在这个例子中,`diag(5)` 创建了一个5x5的对角矩阵,对角线上的元素默认为1,其他位置的元素默认为0。
#### 单位矩阵
单位矩阵是一个特殊的对角矩阵,其对角线上的元素都是1。单位矩阵通常用作线性代数中乘法的恒等元素。
```R
# 创建一个单位矩阵
identity_matrix <- diag(1, nrow = 5, ncol = 5)
```
`diag(1, nrow = 5, ncol = 5)` 创建了一个5x5的单位矩阵。
#### 零矩阵
零矩阵是指所有元素都是0的矩阵。创建一个零矩阵非常简单:
```R
# 创建一个零矩阵
zero_matrix <- matrix(0, nrow = 5, ncol = 5)
```
这段代码创建了一个5x5的零矩阵,其所有元素都是0。
### 3.2.2 稀疏矩阵的处理
稀疏矩阵是一种特殊的矩阵,在这种矩阵中,大部分元素都是0。在处理大规模数据集时,稀疏矩阵非常有用,因为它们可以显著减少内存的使用。
#### 在R中创建稀疏矩阵
gmatrix包中并不直接提供创建稀疏矩阵的函数,但我们可以使用其他库,比如`Matrix`包,来创建和处理稀疏矩阵。
```R
# 创建一个稀疏矩阵
library(Matrix)
sparse_matrix <- Matrix(0, nrow = 5, ncol = 5)
```
这里,我们使用`Matrix`包中的`Matrix`函数创建了一个5x5的稀疏矩阵。虽然它显示的值是0,但其存储方式是压缩的,以节省内存。
#### 稀疏矩阵的操作
稀疏矩阵支持许多常规矩阵操作,但为了保持存储的紧凑性,某些操作在`Matrix`包中被特别优化。例如,矩阵乘法对于稀疏矩阵来说非常高效:
```R
# 稀疏矩阵乘法
result_matrix <- sparse_matrix %*% diag_matrix
```
在这个例子中,`%*%` 运算符用于矩阵乘法,它考虑到了稀疏矩阵的优化存储。
## 3.3 矩阵分解与变换
### 3.3.1 特征值分解和奇异值分解
特征值分解和奇异值分解是矩阵理论中的重要概念,它们在数据分析、图像处理等领域有着广泛的应用。gmatrix包可以辅助我们完成这些操作。
#### 特征值分解
特征值分解是将矩阵分解为特征值和对应的特征向量的过程。在R中,我们可以使用`eigen()`函数来执行特征值分解。
```R
# 特征值分解
eigen_values <- eigen(m)$values
eigen_vectors <- eigen(m)$vectors
```
这里,`eigen(m)` 对矩阵 `m` 进行特征值分解,并返回一个包含特征值(`values`)和特征向量(`vectors`)的列表。
#### 奇异值分解
奇异值分解(SVD)是另一种矩阵分解技术,它适用于任意矩阵,并且在计算上的稳定性较好。`svd()`函数提供了进行SVD的能力。
```R
# 奇异值分解
svd_result <- svd(m)
```
`svd(m)` 对矩阵 `m` 进行奇异值分解,并返回一个包含奇异值(`d`)、左奇异向量(`u`)和右奇异向量(`v`)的列表。
### 3.3.2 矩阵的QR分解和LU分解
QR分解和LU分解是另一种常见的矩阵分解技术,它们在解决线性方程组和最小二乘问题时非常有用。
#### QR分解
QR分解是将矩阵分解为一个正交矩阵Q和一个上三角矩阵R的过程。`qr()`函数可以用来进行QR分解。
```R
# QR分解
qr_result <- qr(m)
```
`qr(m)` 对矩阵 `m` 进行QR分解,并返回一个包含分解结果的对象,该结果可以用于解线性方程组或者进行最小二乘拟合。
#### LU分解
LU分解是将一个矩阵分解为一个下三角矩阵L和一个上三角矩阵U的过程。`lu()`函数可以用来进行LU分解。
```R
# LU分解
lu_result <- lu(m)
```
`lu(m)` 对矩阵 `m` 进行LU分解,并返回一个包含L和U的列表,该结果可以用来解线性方程组。
在本节中,我们介绍了gmatrix包在高级矩阵操作方面的技巧,包括如何使用索引和切片,如何处理特殊矩阵以及进行矩阵分解。这些技巧在进行复杂的数据分析时至关重要。接下来的章节我们将探讨gmatrix包在实际数据分析中的应用,包括线性回归分析、主成分分析以及更高级的统计分析方法。通过这些内容,我们将逐步深入了解gmatrix包提供的功能,以及如何利用这些功能解决实际问题。
# 4. gmatrix包在数据分析中的实际应用
数据分析是一个复杂的过程,它涉及到数据的收集、整理、分析和解释。在这之中,矩阵的操作是不可或缺的一环。特别是在统计分析、机器学习等领域,矩阵不仅用于存储和计算数据,更是分析模型构建的基础。在本章节中,我们将深入探讨gmatrix包在数据分析中的实际应用。
## 4.1 线性回归分析
线性回归是数据分析中最常见的统计方法之一,用于预测或解释一个连续因变量和一个或多个自变量之间的关系。gmatrix包提供了强大的矩阵操作能力,使得线性回归模型的构建和分析变得更加简洁和高效。
### 4.1.1 使用gmatrix构建回归模型
构建线性回归模型首先需要准备数据。gmatrix包可以方便地对数据集进行操作,包括数据的读取、预处理、以及后续的分析。以下是一个使用gmatrix包构建线性回归模型的基本示例代码:
```r
# 加载gmatrix包
library(gmatrix)
# 假设有一个数据集,包含自变量X和因变量Y
# 这里我们创建一个示例数据框
data <- gmatrix(data.frame(
X = c(1, 2, 3, 4, 5),
Y = c(2, 4, 5, 4, 5)
# 构建线性模型矩阵
model_matrix <- cbind(1, data[, 1]) # 添加截距项
# 使用最小二乘法计算回归系数
coefs <- solve(t(model_matrix) %*% model_matrix) %*% t(model_matrix) %*% data[, 2]
# 输出回归系数
print(coefs)
```
在这段代码中,`cbind` 函数用于将截距项添加到自变量矩阵中。然后,使用最小二乘法公式计算回归系数。`solve` 函数用于求解线性方程组,得到回归系数的估计值。
### 4.1.2 模型系数的解释和应用
得到回归系数后,我们需要对这些系数进行解释。系数的正负和大小可以帮助我们理解变量之间的关系。gmatrix包提供了一系列工具来评估模型的统计显著性和拟合度。
```r
# 计算残差和残差平方和
residuals <- data[, 2] - model_matrix %*% coefs
rss <- sum(residuals^2)
# 计算总平方和和决定系数
tss <- sum((data[, 2] - mean(data[, 2]))^2)
r_squared <- 1 - rss / tss
# 输出决定系数
print(r_squared)
```
这里使用了残差平方和(RSS)和总平方和(TSS)来计算决定系数(R²),它衡量了模型对数据变异的解释能力。一个高的R²值意味着模型很好地拟合了数据。
## 4.2 主成分分析(PCA)
主成分分析(PCA)是一种统计技术,用于数据降维,即将数据从高维空间转换到低维空间中,同时保留数据最重要的特征。
### 4.2.1 PCA的基本原理和步骤
PCA的基本步骤包括:标准化数据、计算协方差矩阵、计算特征值和特征向量、选择主成分并进行转换。gmatrix包可以简化这些步骤。
```r
# 标准化数据
data_scaled <- scale(data)
# 计算协方差矩阵
cov_matrix <- cov(data_scaled)
# 计算特征值和特征向量
eigen_values <- eigen(cov_matrix)$values
eigen_vectors <- eigen(cov_matrix)$vectors
# 选择主成分并进行转换
num_components <- 2 # 假设选择前两个主成分
pca_result <- data_scaled %*% eigen_vectors[, 1:num_components]
# 输出主成分结果
print(pca_result)
```
在这个示例中,`scale` 函数用于标准化数据,`cov` 函数用于计算协方差矩阵,`eigen` 函数用于得到特征值和特征向量。最后,通过选择前几个主成分并将其应用于标准化的数据上,我们得到降维后的PCA结果。
### 4.2.2 使用gmatrix进行PCA分析
使用gmatrix包进行PCA分析可以更加直观和高效。我们可以定义一个函数来执行整个PCA流程,并将结果可视化。
```r
# 定义PCA函数
perform_pca <- function(data, num_components) {
data_scaled <- scale(data)
cov_matrix <- cov(data_scaled)
eigen_values <- eigen(cov_matrix)$values
eigen_vectors <- eigen(cov_matrix)$vectors
pca_result <- data_scaled %*% eigen_vectors[, 1:num_components]
return(pca_result)
}
# 执行PCA分析并存储结果
pca_result <- perform_pca(data, num_components)
# 可视化PCA结果
plot(pca_result[, 1], pca_result[, 2], xlab = "PC1", ylab = "PC2", main = "PCA Result")
text(pca_result[, 1], pca_result[, 2], colnames(data), cex = 1, pos = 4)
```
在这段代码中,我们定义了`perform_pca`函数来执行PCA分析,并用`plot`函数将结果可视化。`text`函数用于在图上标注每个点的名称,增强了结果的可读性。
## 4.3 高级统计分析
在数据分析过程中,经常会遇到需要进行更高级统计分析的情况,如回归诊断和多变量统计方法。
### 4.3.1 回归诊断和模型优化
回归模型建立后,我们需要对其进行诊断,以检查模型的假设是否满足,数据是否具有异常值,以及模型是否能够有效地解释因变量的变化。
```r
# 检查回归模型的残差
residual_plot <- function(model) {
plot(model$fitted.values, model$residuals, xlab = "Fitted Values", ylab = "Residuals", main = "Residual Plot")
abline(h = 0, lty = 2)
}
# 对模型进行诊断
residual_plot(coefs)
```
这段代码展示了一个简单的残差图绘制函数。通过残差图我们可以直观地观察数据点的分布情况和潜在的问题。
### 4.3.2 多变量统计方法的gmatrix实现
多变量统计方法通常涉及多个因变量和多个自变量,gmatrix包为这些高级统计分析提供了强大的工具支持。
```r
# 假设有一个多元数据集
multi_data <- gmatrix(data.frame(
X1 = c(1, 2, 3, 4, 5),
X2 = c(2, 3, 5, 7, 11),
Y = c(2, 4, 6, 8, 10)
# 构建多元回归模型
multi_model_matrix <- cbind(1, multi_data[, 1:2])
multi_coefs <- solve(t(multi_model_matrix) %*% multi_model_matrix) %*% t(multi_model_matrix) %*% multi_data[, 3]
# 输出多元回归系数
print(multi_coefs)
```
在这段代码中,我们构建了一个多元回归模型,并计算了多元回归系数。gmatrix包使得数据矩阵的构建和操作更加高效。
至此,我们已经探讨了gmatrix包在数据分析中的具体应用,包括线性回归分析、主成分分析以及更高级的统计分析方法。接下来的章节中,我们将深入案例研究,了解gmatrix包如何解决实际问题,并探讨其性能优化策略。
# 5. gmatrix包的案例研究与性能优化
## 5.1 案例研究:利用gmatrix解决实际问题
### 5.1.1 案例背景和问题陈述
在数据分析中,面对海量数据时,找出问题的关键因素并提出解决方案是至关重要的。本案例研究将探讨如何使用gmatrix包处理并分析数据,以解决一个假设的业务问题。假设我们拥有一个大型零售公司客户购买行为的数据集,目标是通过分析客户消费模式,预测哪些客户群可能会对新推出的产品感兴趣,从而制定针对性的市场推广策略。
### 5.1.2 案例分析与解决方案
为了进行有效的客户细分,我们可以使用gmatrix包中的矩阵操作和统计分析功能。首先,我们需要加载数据集,然后使用gmatrix构建一个客户-产品消费矩阵。
```r
# 安装并加载gmatrix包
install.packages("gmatrix")
library(gmatrix)
# 加载数据集
data <- read.csv("customer_data.csv")
# 构建客户-产品消费矩阵
consumption_matrix <- as.matrix(data[, -1])
rownames(consumption_matrix) <- data$CustomerID
# 查看矩阵维度
dim(consumption_matrix)
```
接下来,我们可以应用主成分分析(PCA)来降低数据的维度,从而识别出消费模式的潜在因素。
```r
# 使用gmatrix进行PCA分析
pca_result <- PCA(consumption_matrix)
```
通过PCA分析结果,我们可以识别出影响客户消费行为的主要成分,并根据这些成分将客户分群。然后,我们可以利用这些分群来预测潜在的市场细分,并设计出相应的营销策略。
## 5.2 性能测试与优化策略
### 5.2.1 gmatrix操作的性能测试
性能测试是优化过程的关键步骤,它帮助我们了解gmatrix包在处理大规模数据时的效率和稳定性。我们可以使用R语言的`microbenchmark`包来测试不同gmatrix操作的执行时间。
```r
# 安装并加载microbenchmark包
install.packages("microbenchmark")
library(microbenchmark)
# 性能测试示例
benchmark_results <- microbenchmark(
matrix_multiplication = consumption_matrix %*% consumption_matrix,
matrix_transpose = t(consumption_matrix),
times = 10L
)
# 查看测试结果
print(benchmark_results)
```
### 5.2.2 性能优化的最佳实践
根据性能测试的结果,我们可以采取以下措施进行性能优化:
- **矩阵预分配**: 使用`matrix`函数预先分配足够大的内存空间,避免在操作过程中动态扩展。
- **批量处理**: 当处理数据时,尽量减少对单个元素的操作,而采用批量处理。
- **向量化操作**: 利用R的向量化能力,减少循环次数,提高代码执行效率。
```r
# 向量化操作示例
optimized_result <- consumption_matrix %*% consumption_matrix
```
## 5.3 跨领域应用探索
### 5.3.1 gmatrix在金融分析中的应用
在金融领域,gmatrix可用于分析股票价格的历史数据,运用主成分分析来识别影响股价的主要因素,或者运用线性回归分析来预测特定行业股票的表现。
### 5.3.2 gmatrix在生物信息学中的应用
生物信息学中经常需要处理复杂的分子数据。gmatrix可以帮助研究人员进行基因表达矩阵的运算,或者通过聚类分析来识别不同样本之间的关联性。
```r
# 基因表达矩阵示例
gene_expression <- read.csv("gene_expression.csv")
expression_matrix <- as.matrix(gene_expression[, -1])
# 聚类分析示例
cluster_result <- hclust(dist(expression_matrix))
```
通过这些案例,我们可以看到gmatrix包在多领域中都有广泛的应用潜力。这不仅验证了gmatrix强大的矩阵操作能力,也展示了其在解决实际问题中的灵活性和效率。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏是一份全面的指南,介绍了 R 语言中强大的 gmatrix 数据包。从入门到高级应用,本专栏涵盖了安装、矩阵操作、数据处理、数据可视化、性能优化、金融分析、数据挖掘、学习技巧、高级计算、实际问题解决、项目应用和高级编程模式等各个方面。通过专家级的教程、深入的案例分析和实用的技巧,本专栏将帮助 R 语言用户掌握 gmatrix 数据包的全部功能,从而提高数据处理效率、提升分析能力,并创建更深入的数据洞察。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【MV-L101097-00-88E1512技术升级】:手册在系统迭代中的关键作用

# 摘要
技术升级手册作为指导系统迭代和技术升级过程的重要文档,其重要性在于确保升级活动的有效性和安全性。本文详细探讨了技术升级手册的重要性、目的、与系统迭代的关系以及其编写、结构和实践应用。通过分析手册编写流程、内容划分、维护更新策略,以及在升级前的准备、升级过程的指导和升级后的总结,本文强调了手册在降低升级风险和提升效率方面的核心作用。同时,本文还面对挑战提出了创新的思路,并对技术升级手册的未来发展
【西门子PLC通信故障全解析】:组态王帮你快速诊断与解决通信难题

# 摘要
本文全面介绍了西门子PLC通信的概览、通信故障的理论基础和使用组态王软件进行PLC通信故障诊断的方法。首先,文章概述了西门子PLC通信协议以及故障的分类与成因,然后深入探讨了通信故障对系统操作的影响。在此基础上,重点介绍了组态王软件的通信功能
MDB接口协议实用指南:项目经理必备的实施策略

# 摘要
本文全面概述了MDB接口协议的各个方面,包括协议的基本架构、核心组件、数据交换机制以及安全部署方法。通过对MDB接口协议的技术细节深入探讨,本文为读者提供了对其数据封装、消息队列、认证授权和数据加密等关键特性的理解。此外,本文还详细介绍了MDB接口协议在项目实施中的需求分析、系统设计、开发部署、测试维护等环节,以及性能调优、功能扩展和未来趋势的讨论。通过案例研究,本文展示了MDB接口协议在实际应用中的成
深入掌握MicroPython:解锁高级特性与最佳实践
# 摘要
MicroPython作为Python 3语言的一个精简而高效的实现,专为微控制器和嵌入式系统设计,具有良好的易用性和强大的功能。本文系统介绍了MicroPython的基本概念、安装流程和基础语法,深入探讨了其高级特性如异常处理、网络通信以及内存管理,并分享了硬件接口编程和嵌入式系统开发的最佳实践。文章还对MicroPython生态系统进行了拓展,包括第三方库、开发板选型和社区资源,并展望了MicroPython在教育和IoT领域的应用前景以及面临的挑战与机遇。
# 关键字
MicroPython;安装;基础语法;高级特性;最佳实践;生态系统;教育应用;IoT融合;挑战与机遇
参
Surfer 11完全操作手册:数据转换新手到高手的成长之路
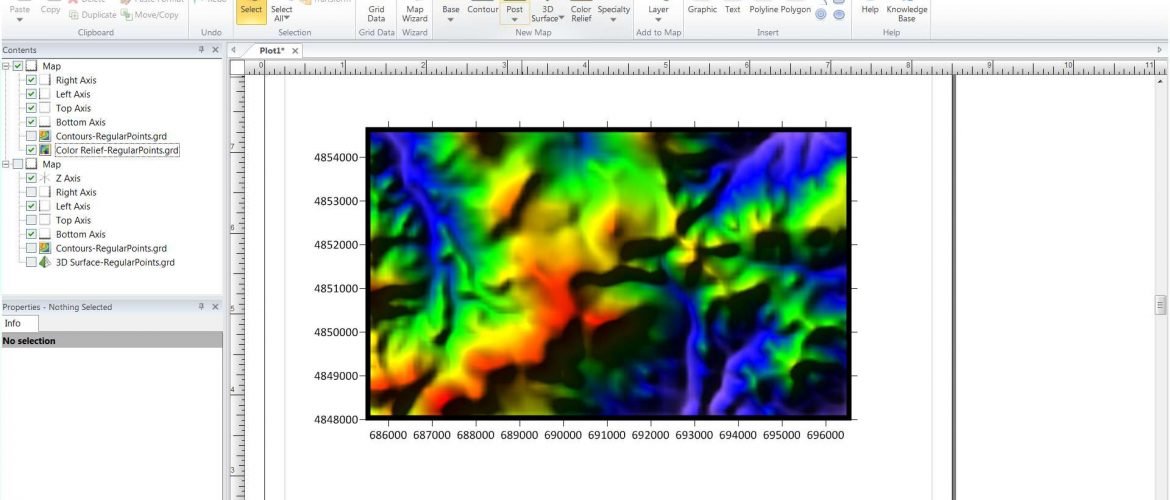
# 摘要
Surfer 11是一款功能强大的地理信息系统软件,广泛应用于地质、环境科学等多个领域。本文首先介绍了Surfer 11的基本概念与界面概览,然后详细阐述了数据准备与导入的技巧,包括Surfer支持的数据格式、导入步骤以及数据预处理的方法。接下来,文章深入探讨了Surfer 11在数据转换方面的核心技术,如网格化、等值线图
【传感器全攻略】:快速入门传感器的世界,掌握核心应用与实战技巧
# 摘要
传感器技术在现代监测系统和自动化应用中扮演着核心角色。本文首先概述了传感器的基本概念和分类,接着深入探讨了传感器的工作原理、特性和各种测量技术。随后,文中分析了传感器在智能家居、工业自动化和移动设备中的具体应用实例,揭示了传感器技术如何改善用户体验和提高工业控制精度。进一步地,本文介绍了传感器数据的采集、处理、分析以及可视化技巧,并通过实战演练展示了如何设计和实施一个高效的传感器监测系统。本文旨在为技术人员提供全面的传感器知识框架,从而更好地理解和运用这项关键技术。
# 关键字
传感器技术;信号转换;特性参数;测量技术;数据处理;数据分析;项目实战
参考资源链接:[金属箔式应变片
7大秘诀揭秘:如何用DevExpress饼状图提升数据可视化效果

# 摘要
数据可视化是将复杂数据转化为直观图形的过程,其艺术性和技术性并重,对于分析和沟通具有重要意义。本文首先介绍了数据可视化的艺术性和DEXExpress饼状图的基本概念。接着,深入探讨了如何理解和选择正确的饼状图类型,并阐述了不同饼状图类型的设计原则和应用场景
【Unreal Engine 4资源打包机制精讲】:掌握.pak文件的结构、功能及优化策略(性能提升必备知识)
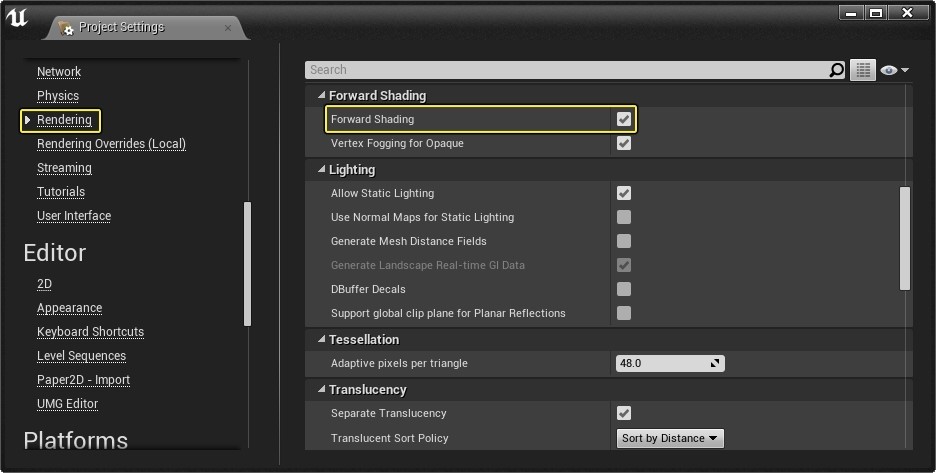
# 摘要
本文深入探讨了Unreal Engine 4中资源打包的技术细节和优化策略。首先,文章介绍了.pak文件的基础知识,包括其结构和功能,以及在游戏中的作用。接着,作者详细阐述了手动与自动化打包.pak文件的具体步骤和常见问题解决方法。在性能优化方面,本文深入分析了资源压缩技术和依赖管理策略,以及这些优化措施对游戏性能的具体影响。通过案例分析,文章展示了优化.pak文件前后的性能对比。最后,本文展望了资源
Visual Studio 2019与C51单片机:打造跨时代开发体验
# 摘要
本文旨在介绍如何利用Visual Studio 2019与
多平台无人机控制揭秘】:DJI Mobile SDK跨设备操作全攻略

# 摘要
本文全面概述了多平台无人机控制的核心技术,重点关注DJI Mobile SDK的安装、初始化及认证,详细探讨了无人机设备控制的基础实践,包括连接、基本飞行操作、摄像头和传感器控制。文章进一步深入到高级控制技巧与应用,涵盖自定义飞行任务、影像数据处理及安全特性。特别地,本文分析了跨平台控制的差异性和兼容性问题,并探讨了多平台应用的开发挑战。
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )