【性能监控与调优】:Landmark & Wellplan 高级性能管理策略
发布时间: 2024-12-13 22:22:56 阅读量: 2 订阅数: 8 
参考资源链接:[Landmark & Wellplan教程:钻井深度与水力参数设计](https://wenku.csdn.net/doc/216ebc28f5?spm=1055.2635.3001.10343)
# 1. 性能监控与调优的理论基础
在IT行业中,性能监控与调优是确保系统稳定运行,提升用户体验的重要手段。理解性能监控与调优的理论基础,是深入实践的前提。
## 1.1 性能监控的概念
性能监控是通过各种工具和技术,实时获取系统运行状态,分析系统性能的过程。它包括CPU使用率、内存利用率、磁盘IO、网络IO等关键指标的监控。
## 1.2 性能调优的定义
性能调优则是根据性能监控的结果,调整系统配置和参数,以优化系统性能。它需要对系统架构和工作原理有深入的理解。
## 1.3 性能监控与调优的关系
性能监控与调优是相辅相成的。监控是调优的基础,调优是监控的延伸。只有通过有效的监控,才能发现系统的瓶颈,进而进行针对性的调优。
性能监控与调优的过程,就是系统性能优化的过程。在这个过程中,我们需要掌握一些关键技术和工具,如Linux命令、性能分析工具、调优策略等。同时,我们也需要建立一个良好的性能优化思维,这样才能在遇到性能问题时,能够快速定位和解决。
# 2. Landmark系统性能监控实践
## 2.1 Landmark系统架构概述
### 2.1.1 Landmark的核心组件
Landmark是一套强大的监控和调优系统,它主要依赖于几个核心组件来确保系统的健康与性能。首先,数据收集器(Data Collectors)是系统中的基础组件,它负责从Landmark监控的目标服务器上采集实时性能数据。这些数据包括但不限于CPU、内存、磁盘I/O、网络I/O以及应用服务的响应时间等。紧接着,数据传输器(Data Transporters)将收集器采集到的数据打包,并安全地传输到数据处理引擎(Data Processing Engine)进行处理。
数据处理引擎是Landmark系统的核心,它负责解析、归一化以及存储这些数据。这些处理过的数据被存储在高性能的数据库中,这样它们就可以被查询和分析。最后,用户界面(UI)为用户提供了一个可视化的平台,以便他们可以实时查看、分析和理解系统的健康状况,甚至可以进行预测性分析和调优。
### 2.1.2 系统监控的关键指标
监控的关键指标是确保系统运行效率和性能优化的重要数据。在Landmark系统中,关键指标包括但不限于以下几点:
- **资源使用率**:监控CPU、内存、磁盘和网络资源的使用率,以确保它们没有过度使用导致系统性能下降。
- **响应时间和延迟**:跟踪应用程序的响应时间和延迟,及时发现和处理性能瓶颈。
- **吞吐量**:监控系统在单位时间内的处理能力,比如每秒处理的交易数。
- **错误和异常**:收集和分析系统错误和异常情况,为故障排除提供线索。
- **容量规划**:分析历史数据,帮助进行未来资源的容量规划和预测。
## 2.2 实时监控工具的应用
### 2.2.1 监控工具的选择标准
在众多可用的监控工具中,选择合适的工具来监视Landmark系统是一个重要的决策。选择标准包括但不限于:
- **可扩展性**:监控工具应能支持从小型环境到企业级环境的扩展。
- **集成能力**:工具应能与现有的系统和第三方应用无缝集成。
- **实时性**:数据采集和警报通知应实时进行,以便快速响应问题。
- **易用性**:用户界面应直观易用,以减少培训成本和误操作。
- **成本效益**:工具的总体拥有成本应合理,包括采购、实施和维护成本。
### 2.2.2 配置监控工具进行性能数据采集
一旦选择了合适的工具,接下来就是配置和部署的过程。以Prometheus为例,这是一个广泛使用的开源监控工具,非常适合用于监控基于容器的应用程序。以下是一个配置Prometheus进行性能数据采集的基本步骤:
1. **安装Prometheus服务器**:可以从官方仓库下载安装包或者使用容器化的方式部署。
2. **配置目标**:在Prometheus的配置文件中指定要监控的目标实例,例如通过静态配置或服务发现机制。
3. **收集器配置**:为系统的关键指标编写或配置对应的收集器,比如node_exporter用于Linux服务器的硬件和操作系统指标。
4. **数据抓取**:设置抓取间隔和抓取时间,以定期从目标实例上获取监控数据。
5. **警报规则**:编写警报规则文件,以便在指标超过预设阈值时触发警报。
下面是一个Prometheus配置文件的片段,用于抓取一个名为example-app的web服务的指标数据:
```yaml
scrape_configs:
- job_name: 'example-app'
static_configs:
- targets: ['192.168.1.100:9090']
```
在这个配置中,Prometheus被配置为每15秒抓取一次位于`192.168.1.100`地址上,端口为`9090`的example-app服务的指标数据。
## 2.3 性能数据的分析与解读
### 2.3.1 性能数据可视化技术
一旦收集到性能数据,接下来的关键步骤是将这些数据进行可视化,以便更容易理解和分析。Grafana是一个流行的开源可视化工具,它能够与Prometheus很好地集成。使用Grafana,用户可以创建仪表板和图表来展示性能指标。例如,可以创建一个CPU使用率的图表,显示过去一小时的平均使用率,或者构建一个仪表板,同时显示多个关键指标的实时数据。
构建可视化仪表板的过程通常涉及以下步骤:
1. **连接数据源**:将Grafana连接到Prometheus。
2. **创建面板**:在Grafana中创建新的面板,并选择相应的数据源。
3. **查询数据**:为面板编写PromQL查询来获取所需的数据。
4. **设置图表类型**:根据需要,将面板设置为不同的图表类型,如折线图、图表或表格。
5. **配置面板选项**:设置适当的图表轴、颜色主题、阈值等。
6. **构建仪表板**:将多个面板组合成一个仪表板,并进行布局调整。
### 2.3.2 性能瓶颈的诊断方法
性能瓶颈的诊断是一个需要综合分析多个指标和数据点的过程。通常,以下几个步骤可以帮助识别和定位性能瓶颈:
1. **识别异常行为**:通过仪表板观察指标的异常跳动或长时间的高负载状态。
2. **查看日志文件**:检查与特定性能问题相关的系统和应用日志。
3. **进行深入分析**:使用系统工具(如top, htop, iotop)或专用的性能分析工具(如perf, bcc)来深入分析系统资源的使用情况。
4. **应用分析方法**:对于CPU密集型应用,使用火焰图或调用栈分析;对于内存问题,使用内存泄漏检测工具如Valgrind;对于I/O问题,使用I/O性能分析工具。
5. **历史数据对比**:与历史数据进行对比,确定性能下降的趋势或周期性问题。
在实践中,可以使用以下的bash脚本,它使用`top`命令检查当前CPU使

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
《Landmark & Wellplan 教程》专栏是一份全面的指南,涵盖了Landmark和Wellplan软件的各个方面。它提供了从初学者到高级用户的教程,包括核心功能、高效使用技巧、数据管理、数据集成、自动化和脚本编写、跨平台应用、数据备份和恢复、监控和报警、高级报告技巧、系统扩展和集群部署、负载均衡和高可用、最佳实践和性能监控等内容。该专栏旨在帮助用户充分利用这些软件,提高工作效率,并确保系统的稳定性和可靠性。
专栏目录

文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【dSPACE RTI 环境搭建全攻略】:开发新手必备的环境配置教程

参考资源链接:[DSpace RTI CAN Multi Message开发配置教程](https://wenku.csdn.net/doc/33wfcned3q?spm=1055.2635.3001.10343)
# 1. dSPACE RTI环境概述
dSPACE Real-Time Interface (RTI) 是一
【Dev C++编译错误快速定位】:Id returned 1 exit status问题的诊断与解决
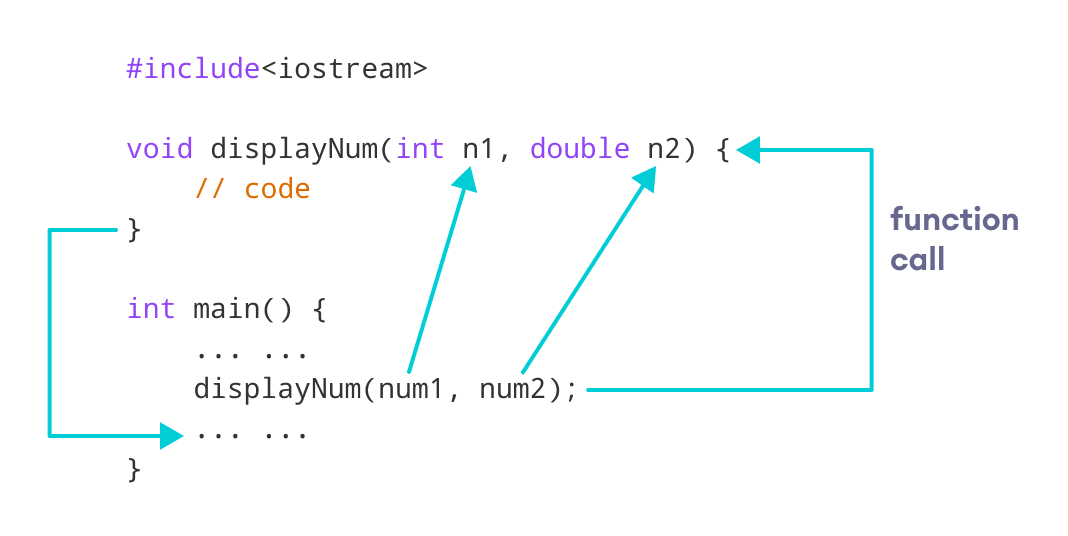
参考资源链接:[解决Dev C++编译错误:Id returned 1 exit status](https://wenku.csdn.net/doc/6412b470be7fbd1778d3f976?spm=1055.2635.3001.10343)
# 1. Dev C++编译错误概览
## 理解编译过程
在软
【SAP财务处理:移动与评估类型协调全攻略】:财务与物流的完美结合

参考资源链接:[SAP物料评估与移动类型深度解析](https://wenku.csdn.net/doc/6487e1d8619bb054bf57ad44?spm=1055.2635.3001.10343)
# 1. SAP财务处理概述
## SAP财务处理基础
SAP作为先进的企业资源计划(ERP)系统,其核心功能之一是财务处理。财务处理在SAP系统中扮演着关键角色,因为所有的业务交易最终都会反映在财务报表上
实验室安全隐患排查:BUPT试题解析与实战演练的终极指南
参考资源链接:[北邮实验室安全试题与答案解析](https://wenku.csdn.net/doc/12n6v787z3?spm=1055.2635.3001.10343)
# 1. 实验室安全隐患排查的重要性与原则
## 实验室安全隐患排查的重要性
在当今社会,实验室安全已成为全社会关注的焦点。实验室安全隐患排查的重要性不言而喻,它直接关系到实验人员的生命安全和身体健康。对于实验室管理者来说,确保实验室安全运行是其基本职责。忽视安全隐患排查将导致严重后果,包括环境污染、财产损失甚至人员伤亡。因此,必须强调实验室安全隐患排查的重要性,从源头上预防和控制安全事故的发生。
## 实验室安全
【高效网络传输秘诀】:RoCEv2在高性能计算中的应用及优化
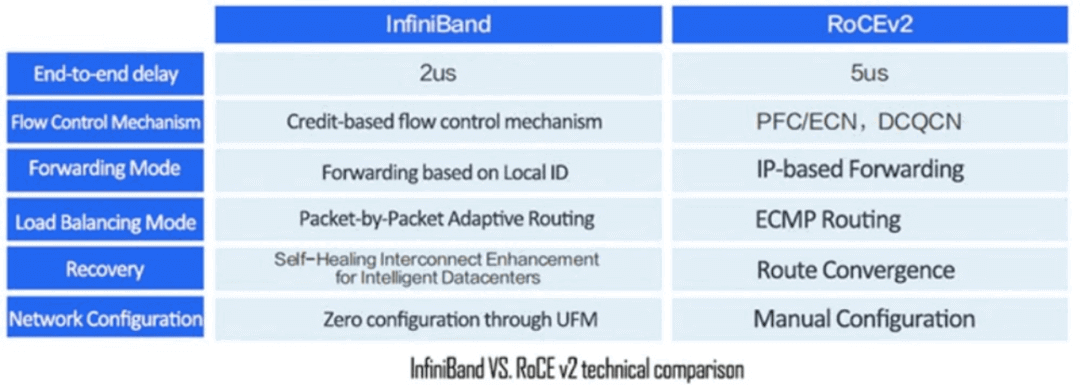
参考资源链接:[InfiniBand Architecture 1.2.1: RoCEv2 IPRoutable Protocol Extension](https://wenku.csdn.net/doc/645f20cb543f8444888a9c3d?spm=1055.2635.3001.10343)
# 1. RoCEv2技术概述
## 1.1 简介
RDMA over Converged Ethernet ver
从入门到精通:V93000 Wave Scale RF训练进阶指南,专家手把手教你
参考资源链接:[Advantest V93000 Wave Scale RF 训练教程](https://wenku.csdn.net/doc/1u2r85x0y8?spm=1055.2635.3001.10343)
# 1. V93000 Wave
【毫米波信道建模】:深入分析与应用,专家指南

参考资源链接:[TI mmWave Studio用户指南:安装与功能详解](https://wenku.csdn.net/doc/3moqmq4ho0?spm=1055.2635.3001.10343)
# 1. 毫米波信道建模的理论基础
毫米波技术,作为无线通信领域的一项突破性进展,其信道建模理论基础是研究该频段信号传播特性的关键。在深入探讨技术原
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )