常用的8088_8086存储器编址模式
发布时间: 2024-02-07 17:56:54 阅读量: 180 订阅数: 25 

东北大学20春《计算机硬件技术基础》在线平时作业1答案.docx
# 1. 引言
## 1.1 8088和8086处理器简介
8088和8086处理器是英特尔公司推出的16位微处理器,分别于1979年和1978年发布。它们是第一代x86处理器,对于个人电脑的普及起到了重要的推动作用。
## 1.2 存储器编址模式的重要性和作用
存储器编址模式是计算机体系结构中的关键概念之一,它决定了CPU如何访问和管理存储器。不同的存储器编址模式可以影响计算机的性能、存储容量和兼容性等方面。
在本文中,我们将重点讨论8088和8086处理器的存储器编址模式,包括实模式和保护模式。实模式是初始时的默认模式,主要用于兼容早期的计算机系统。保护模式则是后来引入的一种改进模式,提供了更高的安全性和灵活性。我们将深入探讨它们的原理、特点和差异,以及如何在两种模式之间进行转换。
接下来,让我们先了解实模式的存储器编址模式。
# 2. 实模式存储器编址模式
在实模式下,8088和8086处理器使用的是简单的存储器编址模式。在这种模式下,处理器的地址线和数据线可以直接连接到存储器芯片,没有任何额外的转换或管理。下面将详细介绍实模式存储器编址模式的几个关键要点。
### 2.1 实模式下的地址线和数据线
在实模式下,8088和8086处理器使用的是20位的地址线和16位的数据线。地址线的宽度决定了处理器可以访问的存储器空间的大小,即2^20个地址,也就是1MB的存储器空间。数据线的宽度决定了处理器一次可以传送的数据的位数,即16位。
### 2.2 存储器分段和偏移地址
为了能够处理更大容量的存储器空间,实模式下引入了存储器分段的概念。存储器被分为多个段,每个段由一个起始地址和一个段长度来确定。实模式下的地址由段地址和偏移地址组成,其中段地址表示段的起始地址,偏移地址表示段内的相对位置。
### 2.3 地址转换机制
在实模式下,地址转换非常简单。处理器根据段地址和偏移地址计算出实际的物理地址,并将其发送给存储器。地址转换的计算公式为物理地址 = 段地址 × 16 + 偏移地址,其中16表示一个段内的偏移量的倍数。
下面是一个简单的示例代码,演示了实模式下的地址转换过程:
```python
segment_address = 0x1234
offset_address = 0x5678
physical_address = segment_address * 16 + offset_address
print(f"Segment address: {segment_address}")
print(f"Offset address: {offset_address}")
print(f"Physical address: {physical_address}")
```
代码输出结果为:
```
Segment address: 4660
Offset address: 22136
Physical address: 22296
```
以上是实模式存储器编址模式的主要内容。在下一章节中,我们将介绍保护模式下的存储器编址模式。
# 3. 保护模式存储器编址模式
保护模式是8086系列处理器中的一种工作模式,它提供了更强大的虚拟内存管理和硬件保护功能。在保护模式下,存储器编址模式与实模式有所不同,具体如下:
#### 3.1 保护模式下的内存分段系统
在保护模式下,存储器被划分为多个段,每个段可以包含不同的代码、数据和堆栈。这种内存分段系统使程序可以更加灵活地管理内存,可以实现多任务、多用户等复杂的操作。
#### 3.2 段描述符和选择子
在保护模式下,每个段都有一个相应的段描述符,用来描述段的属性和位置。段描述符包含段的基地址、段的长度、访问权限等信息。选择子则是一个指向段描述符的指针,通过选择子可以访问相应的段。
#### 3.3 分页机制和虚拟地址
除了内存分段系统,保护模式还引入了分页机制。每个页表项描述了一个页的属性和位置,包括物理地址和访问权限等信息。通过分页机制,程序可以通过虚拟地址访问内存,而不需要关心具体的物理地址。
在保护模式下,虚拟地址由段选择子和偏移地址组成。通过选择子找到相应的段描述符,然后再将偏移地址与段描述符中的基地址进行相加,得到最终的物理地址。
保护模式下的存储器编址模式相比实模式更加灵活,可以实现更高级的内存管理和保护机制。然而,由于增加了额外的地址转换和权限检查等步骤,相比实模式,访问内存的速度会稍微慢一些。
下面是一个示例代码,演示了如何在保护模式下访问内存:
```python
# 示例代码只是一种简化的实现,具体实现方式会依赖具体的编程语言和操作系统
# 定义一个段描述符
class SegmentDescriptor:
def __init__(self, base, limit, access):
self.base = base
self.limit = limit
self.access = access
# 定义一个页表项
class PageTableEntry:
def __init__(self, physical_address, access):
self.physical_address = physical_address
self.access = access
# 定义一个页表
page_table = [
PageTableEntry(0x1000, "RW"),
PageTableEntry(0x2000, "R"),
# ...
]
# 定义一个段选择子
segment_selector = 0x1234
# 通过选择子找到段描述符
segment_descriptor = segment_table[segment_selector]
# 计算虚拟地址
virtual_address = 0x5678
# 计算偏移地址
offset = virtual_address + segment_descriptor.base
# 访问内存
physical_address = page_table[offset]
data = memory[physical_address]
# 打印结果
print("虚拟地址: 0x{:x}".format(virtual_address))
print("物理地址: 0x{:x}".format(physical_address))
print("数据: {}".format(data))
```
这个示例代码演示了如何通过段选择子、段描述符、页表和偏移地址来访问内存。它只是一个简化的实现,实际的内存管理和地址转换会更加复杂。通过理解保护模式下的存储器编址模式,可以更好地理解和应用相关的概念和技术。
# 4. 实模式与保护模式的转换
在计算机系统中,实模式和保护模式是两种不同的工作模式。实模式是早期的模式,它是IBM PC的初始工作模式,而保护模式是后期引入的一种更高级的工作模式。实模式提供了简单的存储器编址模式,而保护模式则更加灵活和安全。
#### 4.1 从实模式到保护模式的切换
从实模式切换到保护模式需要执行一系列的操作。首先,需要设置正确的系统寄存器。通过修改CR0控制寄存器的相关位,可以将处理器从实模式切换到保护模式。然后,需要加载全局描述符表(GDT)和中断描述符表(IDT)的地址,在保护模式下,这两个表用于管理内存段和中断处理。
#### 4.2 切换过程中的存储器编址模式变化
实模式和保护模式的存储器编址模式有所不同。在实模式下,物理地址由段地址和偏移地址组成,它们直接映射到物理存储器。而在保护模式下,使用虚拟地址进行存储器访问,在访问过程中需要通过内存管理单元(MMU)进行地址转换。
#### 4.3 使用代码段选择子与追踪指针实现保护模式到实模式的切换
保护模式下,需要通过代码段选择子和追踪指针实现切换到实模式。代码段选择子包含了实模式下的段值和偏移地址,通过加载合适的选择子,可以将处理器切换到实模式,并执行实模式下的代码。追踪指针用于记录切换回保护模式后的继续执行位置。
下面是一个示例代码片段,演示了通过汇编语言实现从保护模式切换到实模式的过程:
```assembly
section .data
gdt_start:
dw 0x0000
dw 0x0000
db 0x00
db 0x00
db 0x00
db 0x00
db 0x00
db 0x00
gdt_code:
dw 0xFFFF
dw 0x0000
db 0x00
db 0x9A
db 0xCF
db 0x00
db 0x00
db 0x00
gdt_end:
section .text
global _start
extern _real_mode
_start:
; 设置代码段选择子
xor ax, ax
mov ds, ax
mov es, ax
mov ss, ax
; 加载GDT表
lgdt [gdt_start]
; 切换到保护模式
mov eax, cr0
or eax, 0x01
mov cr0, eax
; 加载选择子和追踪指针
jmp 0x08:protected_mode
protected_mode:
mov eax, cr0
and eax, 0xFFFFFFFE
mov cr0, eax
; 切换到实模式
; ...
call _real_mode
section .text
_real_mode:
; 在实模式下执行的代码
; ...
; 切换回保护模式
; ...
ret
```
在上述代码中,通过设置代码段选择子加载GDT表,然后将CR0寄存器的相关位设置为0x01,切换到保护模式。接着,通过使用jmp指令和选择子 "0x08" 切换到实模式下执行代码,最后通过调用_real_mode函数切换回保护模式。
通过以上的代码实例,我们可以清楚地理解实模式和保护模式的切换过程,并理解切换过程中存储器编址模式的变化。这些特性使得保护模式具有更灵活和安全的存储器管理能力。
# 5. 8088和8086存储器编址模式的差异
在本章中,我们将讨论8088和8086处理器在存储器编址模式方面的一些差异。这些差异主要包括存储器容量限制、内存访问速度差异以及存储器寻址能力的不同。
### 5.1 存储器容量限制
8088处理器的地址总线只有20根,因此它最多可以访问1MB的内存地址空间。而8086处理器的地址总线有24根,可以访问16MB的内存地址空间。这意味着8086处理器能够访问更多的内存,相比之下,8088处理器的存储容量受到了限制。
### 5.2 内存访问速度差异
8088和8086处理器之间的主频差异导致了内存访问速度的差异。8088处理器的主频为4.77MHz,而8086处理器的主频为5MHz。尽管8086处理器的主频稍高,但由于两者的存储器总线宽度相同(16位),8086处理器在访问内存时需要更多的时钟周期。
### 5.3 存储器寻址能力的不同
8088和8086的存储器寻址能力也存在一些差异。8088处理器在实模式下,使用的是20位的地址线,可以访问1MB的内存空间。而8086处理器在实模式下也是20位的地址线,但是可以通过一些特殊的技术扩展到1GB的内存空间。在保护模式下,8086处理器可以使用32位的地址线,能够访问4GB的内存空间。相比之下,8088处理器在保护模式下无法扩展到32位地址线,因此无法访问4GB以上的内存空间。
综上所述,8088和8086处理器在存储器编址模式方面存在一些差异,包括存储器容量限制、内存访问速度差异以及存储器寻址能力的不同。这些差异在实际应用中需要考虑,以便选择适合的处理器来满足系统需要。
# 6. 结论
### 6.1 总结存储器编址模式的重要性和应用场景
存储器编址模式是计算机系统中非常重要的一部分,它决定了程序能否正确地访问存储器,并且直接影响了系统的性能和安全性。通过实模式和保护模式的存储器编址模式,我们可以更好地理解计算机系统的运行原理。
在实模式下,存储器编址模式相对简单,可以直接使用物理地址访问存储器。这种模式适用于一些简单的应用场景,如实时控制和嵌入式系统。然而,实模式的存储器容量和访问速度受到限制,无法满足复杂应用的需求。
保护模式下的存储器编址模式更为复杂,但也更加灵活和安全。通过内存分段和分页机制,保护模式可以实现内存的隔离和保护,提高系统的安全性。同时,保护模式也支持更大容量的存储器和更快的访问速度,适用于大型操作系统和复杂的应用程序。
### 6.2 建议实践与进一步学习的内容
要深入学习存储器编址模式,可以从以下几个方面进行实践和进一步学习:
- 实践编写程序,通过实际编程来加深对存储器编址模式的理解。可以选择使用汇编语言或高级语言,编写一些简单的程序,模拟实模式和保护模式下的存储器访问。
- 学习操作系统和编译原理的相关知识,深入理解保护模式下的内存分段和分页机制。可以阅读相关的教材或参考资料,了解操作系统如何管理和保护存储器。
- 研究现代处理器的存储器编址模式,如x86-64架构的处理器。了解新的存储器编址模式对系统性能和安全性的影响,以及与8088和8086的差异。
- 参与开源项目或进行相关的研究,深入探索存储器编址模式在实际应用中的问题和挑战。可以与其他开发者或研究者一起讨论,分享经验和学习成果。
通过不断学习和实践,我们可以更好地理解存储器编址模式的重要性和应用场景,为系统的设计和优化提供有效的指导。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏以"8088/8086存储器架构基础与应用"为主题,深入探讨了8088/8086存储器的基本概念、组成以及相关的应用技术。文章围绕着8088/8086存储器架构入门指南、存储器编址模式、段寄存器的影响、内存的映射、物理内存与逻辑内存概念及转换等方面展开论述。同时对实模式和保护模式下的存储器访问速度、特殊用途存储器、内存管理单位的优化、存储器扩展方案、内存的读写操作与时序分析等进行了深入分析。此外,还囊括了存储器带宽和延迟的优化策略以及异步访问技术等高级话题。通过该专栏的学习,读者可以全面掌握8088/8086存储器架构的理论基础和实际应用,有助于提升对该领域的理解和应用能力。
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
ADS1256与STM32通信协议:构建稳定数据链路的必知
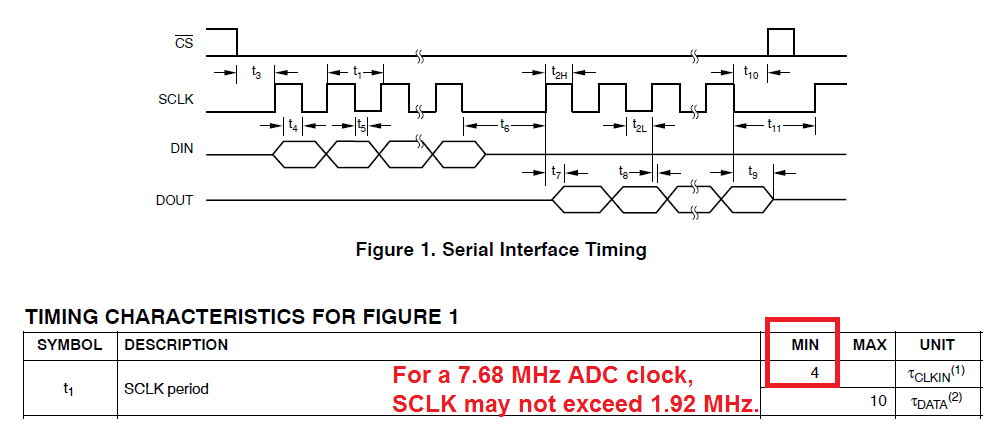
# 摘要
本文详细阐述了ADS1256与STM32的通信协议及其在数据采集系统中的应用。首先介绍了ADS1256模块的特性、引脚功能,以及与STM32的硬件连接和配置方法。随后,分析了通信协议的基础知识,包括数据链路层的作用、SPI协议以及软件层的通信管理。接着,探讨了提高数据链路稳定性的关键因素和实践策略,并通过案例分析展示了稳
【响应式网页设计】:让花店网站在不同设备上都美观

# 摘要
响应式网页设计是一种确保网页在不同设备上均能提供良好用户体验的设计方法。本文从基础原理到实践技巧,系统地介绍了响应式设计的核心技术和方法。首先,概述了响应式设计的基本原理,包括媒体查询、弹性布局(Flexbox)和网格布局(CSS Grid)等技术的应用。随后,详细探讨了实践中应掌握的技巧,如流式图片和媒体的使用、视口设置、响应式字体及导航菜单设计。在高级主题中,本文还讨论了响应式
【Synology File Station API版本控制】:API版本管理艺术,升级不乱阵脚
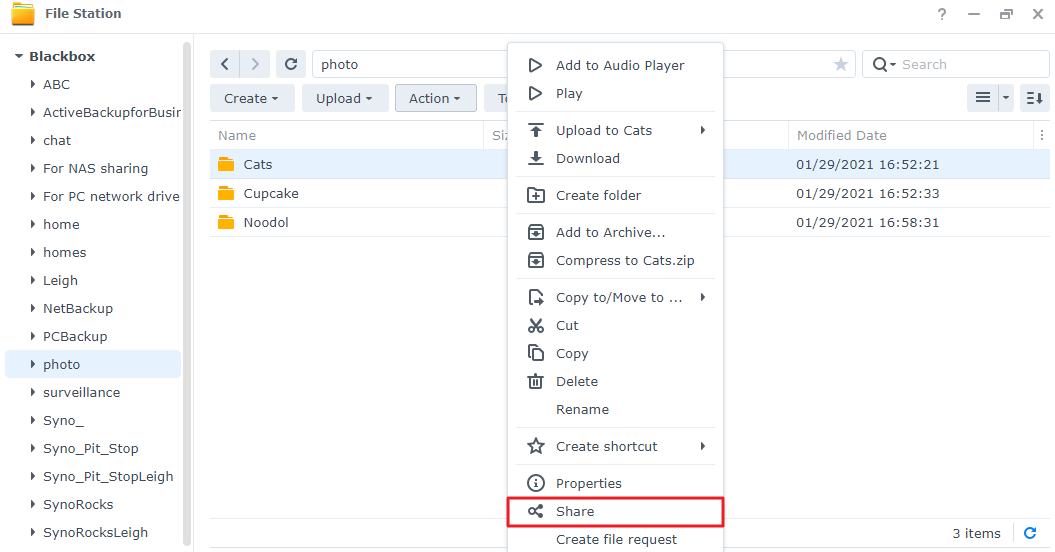
# 摘要
本文全面探讨了API版本控制的基础理念、核心概念、实践指南、案例研究以及理论框架。首先介绍了API版本控制的重要性和核心概念,然后深入解析了Synology File Station API的架构和版本更新策略。接着,本文提供了API版本控制的实践指南,包括管理流程和最佳实践。案例研究部分通过分析具
揭秘IT策略:BOP2_BA20_022016_zh_zh-CHS.pdf深度剖析

# 摘要
本文对BOP2_BA20_022016进行了全面的概览和目标阐述,提出了研究的核心策略和实施路径。文章首先介绍了基础概念、理论框架和文档结构,随后深入分析了核心策略的思维框架,实施步骤,以及成功因素。通过案例研究,本文展示了策略在实际应用中的挑战、解决方案和经验教训,最后对策略的未来展望和持续改进方法进行了探讨。本文旨在
【水晶报表故障排除大全】:常见问题诊断与解决指南
# 摘要
水晶报表作为一种广泛使用的报表生成工具,其在企业应用中的高效性和灵活性是确保数据准确呈现的关键。本文从基础和应用场景开始,深入分析了水晶报表在设计、打印、运行时等不同阶段可能出现的常见问题,并提供了相应的诊断技巧。文章还探讨了故障排除的准备工作、分析方法和实践技巧,并针对高级故障处理如性能优化、安全性和权限问题以及版本兼容性迁移等提供了详细指导。此外
IBM M5210 RAID基础与实施:从概念到实践的7步骤详解
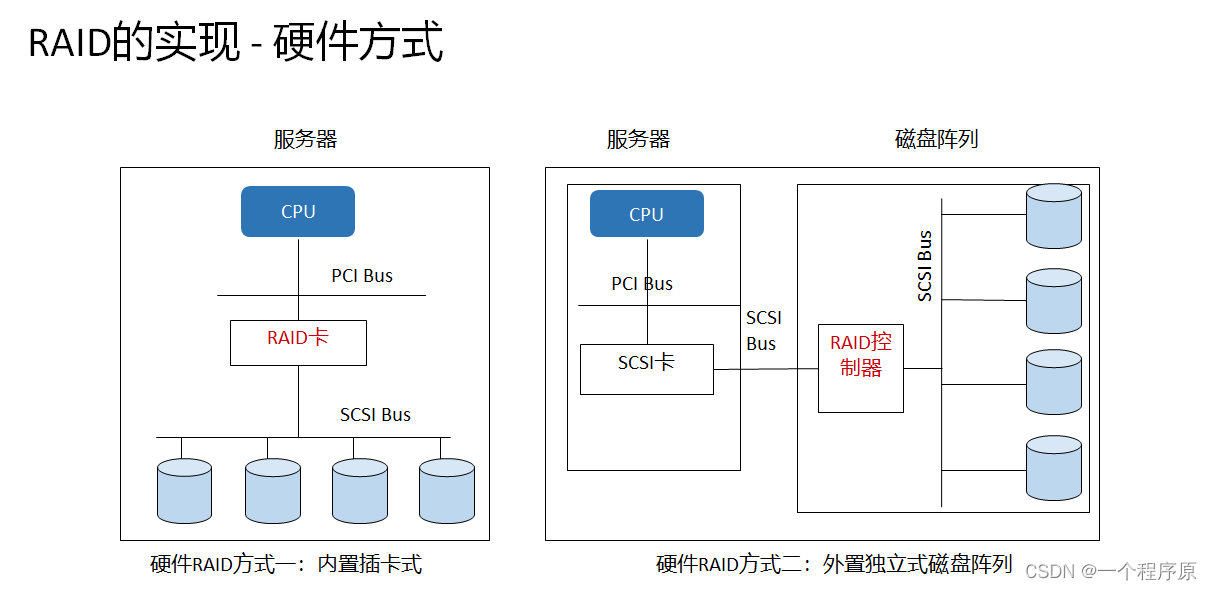
# 摘要
本文全面探讨了RAID(冗余阵列独立磁盘)技术,从基础概念到实施步骤,详细阐述了RAID的重要性、历史发展及其在现代存储中的应用。文章介绍了RAID配置的基础知识,包括硬盘与控制器的理解、基本设置以及配置界面和选项的解释。同时,深入讲解了硬件与软件RAID的实现方法,包括常见RAID控制器类型、安装设置、以及在Linux和Windows环境下的软RAID配置。对于不同RAID级别的
【VCS系统稳定性】:通过返回值分析揭示系统瓶颈与优化方向

# 摘要
本文旨在探讨VCS系统稳定性的关键要素,重点分析返回值的重要性及其在系统监控与优化中的应用。通过阐述返回值的概念、分析方法论以及在实践中的应用策略,文章揭示了返回值对于系统性能优化、故障诊断和系统架构改进的重要性。此外,本文也探讨了系统瓶颈的分析技术和基于返回值的系统
【S7-200 SMART数据采集秘籍】:Kepware配置全面解读
# 摘要
本篇论文全面介绍了Kepware在工业自动化领域中数据采集的重要性及配置技术。文章首先概述了Kepware的基本架构和功能,随后深入探讨了与S7-200 SMART PLC的连接配置、项目管理以及高级配置技巧。通过分析实践应用案例,展示了Kepware在构建实时监控系统、数据整合以及故障诊断与性能优化方面的应用。论文还讨论了Kepware在物联网和边缘计算中的潜力,并提出项目管理与维护的最佳实践。本文旨在为读者提供深入理解Kepware配置与应用的全面指南,并对提升工业自动化系统的数据管理能力具有实际指导意义。
# 关键字
Kepware;数据采集;项目管理;实时监控;故障诊断;物
hwpt530.pdf:评估并解决文档中的遗留技术问题(遗留问题深度分析)
# 摘要
遗留技术问题普遍存在于现代软件系统中,识别和分类这些问题对于维护和更新系统至关重要。本文首先探讨了遗留技术问题的理论基础与评估方法,包括定义、类型、评估流程、影响分析和评估工具。随后,文章详细讨论了多种解决策略,如重构与现代化、兼容性与整合性、迁移与替换,并提供了案例研究以及行业最佳实践。最后,文章展望了未来趋势,强调了技术债务管理和新技术应用在解决遗留问题中的重要性。本文旨在为读者提供全面理解遗留问题的框架,并提供实用的解决策略和
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )