版本控制实战:Fork与Clone在多环境部署的应用技巧
发布时间: 2024-12-07 08:35:37 阅读量: 7 订阅数: 18 

Java多线程编程详解:核心概念与高级技术应用
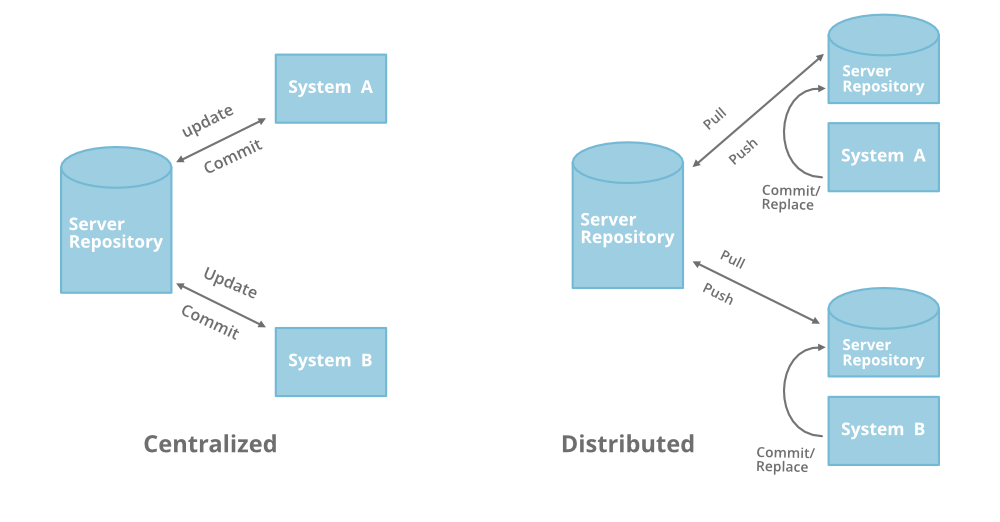
# 1. 版本控制基础与分布式概念
在现代软件开发的复杂环境中,版本控制系统是维护和管理代码变更的关键工具。本章将介绍版本控制的基础知识以及分布式版本控制系统的概念,为理解后续章节中的Fork和Clone操作打下坚实的基础。
## 1.1 版本控制系统的演变
版本控制系统的演进从最初的本地版本控制发展到集中式版本控制,再到现在的分布式版本控制。这些系统帮助开发者在项目中协同工作,追踪和管理代码的历史变化。
### 本地版本控制
在本地版本控制时代,开发者依赖于文件系统的备份和手动管理,这种方式简单但效率低下且容易出错。
### 集中式版本控制
集中式版本控制如SVN引入了中央服务器的概念,所有团队成员都将代码提交到服务器上,解决了协同工作的难题,但仍有单点故障的风险。
### 分布式版本控制
分布式版本控制如Git,每个开发者都拥有代码库的完整副本,这大大提高了协作的灵活性。即使在没有网络连接的情况下,开发者仍可以提交更改,并与远程仓库同步。
## 1.2 分布式版本控制的核心优势
分布式版本控制系统,特别是Git,提供了许多优势,包括但不限于:
- **分支与合并**:允许开发者自由地创建分支,并进行独立的更改,然后再将这些更改合并回主分支。
- **离线操作**:每个开发者都可以在没有网络的情况下工作,并且仍然能够提交更改。
- **高效的版本历史管理**:Git使用独特的数据结构存储提交历史,保证了操作的高效性。
通过本章的学习,你将对版本控制系统的基本概念有一个全面的理解,并为探索更高级的操作,如Fork和Clone,打下坚实的基础。接下来,我们将深入探讨Fork操作的理论与实践,以进一步理解分布式版本控制的强大功能。
# 2. Fork操作的理论与实践
## 2.1 Fork的版本控制理论
### 2.1.1 Fork在Git中的作用
在Git版本控制系统中,Fork是一个重要的功能,它允许用户在不直接接触原始仓库(通常称为“上游仓库”)的情况下复制一份代码。这种操作让开发者能够自由地在自己的代码分支上进行实验、开发新功能或者修正bug,而不会影响原始仓库的内容。Fork允许开源项目在社区中广泛传播,因为任何个人或组织都可以创建他们自己的版本,并且可以随意地对其进行改进。
在Git中,Fork创建的仓库称为“fork仓库”,它与原始仓库在功能上是完全独立的。这意味着你可以自由地推送和拉取提交(commits),但这些更改不会影响到原始仓库,除非你发起了一个合并请求(Pull Request),让原始仓库的维护者审查你的更改。如果这些更改被接受,它们可以被合并回上游仓库。
### 2.1.2 Fork与分支管理的关系
尽管Fork和分支管理在Git中都是处理代码变更的机制,但它们在作用范围和使用场景上有所不同。Fork通常用于跨团队或跨组织的合作中,分支管理则更多地用于同一团队内部的协作。
一个分支(branch)是源仓库中的一条独立发展线,开发者可以在分支上进行更改而不影响主分支(通常是“master”或“main”分支)。分支是本地工作的一部分,更改可以随时合并到主分支或者被删除。在分支上的开发工作完成后,可以通过Pull Request被合并到上游分支中。
而Fork则涉及到远程仓库的复制,它允许开发者在一个独立的环境中工作,然后将变更同步回原始仓库。Fork通常用于开源项目,因为它允许开发者为一个公共项目贡献代码,而不需要获得原始仓库的写权限。
## 2.2 Fork的实际应用场景
### 2.2.1 开源项目中的Fork使用
在开源项目中,Fork是一种常见的实践。一个开源项目的贡献者可以fork原始仓库到自己的GitHub或其他Git托管平台账户下,然后在这个fork仓库中自由地进行更改。这些更改包括但不限于bug修复、功能实现和性能优化。
一旦贡献者在fork仓库中完成更改并通过内部测试,他们可以发起一个Pull Request给原始项目的所有者或维护者。如果维护者同意这些更改,他们可以将这些更改合并到上游仓库中,从而使得其他用户也能受益于这些贡献。
### 2.2.2 企业内部Fork的管理和流程
在企业环境中,Fork也可以作为一种有效的协作机制,尤其是在有多个团队需要同时在同一个项目上工作时。Fork可以被用于隔离不同阶段的开发工作,或者让不同的团队在同一个代码基础上进行独立开发。
企业内部的Fork管理流程通常包括以下步骤:
1. 创建fork仓库:当项目开始时,主仓库被fork到每个需要参与该项目的开发者或团队中。
2. 本地开发:开发者在自己的fork仓库上进行更改,通过分支管理来组织开发流程。
3. 同步上游变更:定期将上游仓库的变更合并到自己的fork仓库中,以保持与主项目的同步。
4. Pull Request:当开发工作完成时,开发者可以向主仓库发起Pull Request。
5. 审核与合并:主仓库的维护者会审核Pull Request中的更改,如果满意,则将其合并回主仓库。
## 2.3 Fork操作的高级技巧
### 2.3.1 如何有效同步上游变更
同步上游变更是在Fork的工作流中保持代码库更新的关键步骤。这可以通过`git remote`和`git fetch`命令来完成。首先,需要添加原始仓库为远程仓库(通常称为`upstream`),然后定期从`upstream`抓取(fetch)最新的变更,并根据需要将这些变更合并到自己的工作分支中。
这是一个典型的同步上游变更的步骤示例:
```bash
# 添加上游远程仓库
git remote add upstream https://example.com/original-repo.git
# 抓取上游分支的最新更改
git fetch upstream
# 切换到自己的工作分支
git checkout my-feature-branch
# 将上游分支的更改合并到自己的工作分支中
git merge upstream/main
# 如果存在冲突,解决冲突后继续合并
# ...
```
### 2.3.2 解决Fork过程中的冲突和问题
在Fork的工作流中,因为有多个仓库在并行发展,所以冲突是不可避免的。解决这些冲突是维护健康工作流的一部分。通常,冲突发生在当你尝试合并上游的变更到自己的分支时。
解决冲突的步骤通常如下:
1. 检查冲突:当`git merge`命令提示有冲突时,Git会标记出冲突的文件。
2. 编辑文件:打开这些文件,找到标记为冲突的部分,这些部分会以特定的格式显示。你需要决定如何合并这些更改。
3. 添加文件:一旦解决了冲突,使用`git add`命令标记这些文件已解决。
4. 继续合并:使用`git merge --continue`命令来完成合并过程。
这是一个处理合并冲突的代码示例:
```bash
# 检查状态,查看冲突文件
git status
# 编辑冲突文件,解决冲突
nano conflicting-file.txt
# 添加解决冲突后的文件到暂存区
git add conflicting-file.txt
# 完成合并过程
git merge --continue
# 继续其他工作或提交更改
```
通过上述步骤,你可以有效地解决Fork过程中遇到的冲突和问题,保持自己的代码库与上游仓库同步,同时也确保自己的更改能够被妥善整合

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入探讨了 GitHub 中 Fork 和 Clone 的区别,重点关注其在团队协作中的核心作用。它提供了实用指南,帮助读者解决代码冲突、维护项目完整性,并利用 Fork 和 Clone 的高级用法。专栏还介绍了在大型团队协作和复杂项目中实施 Fork 和 Clone 的策略,并提供了代码审查艺术的应用策略。通过深入分析 Fork 和 Clone 的细微差别,本专栏旨在帮助读者掌握版本控制的艺术,从而提升团队协作效率和代码质量。
专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
Ubuntu文件系统选择:专家推荐,匹配最佳安装场景

参考资源链接:[Ubuntu手动分区详解:步骤与文件系统概念](https://wenku.csdn.net/doc/6483e7805753293249e57041?spm=1055.2635.3001.10343)
# 1. Ubuntu文件系统概述
Linux操作系统中,文件系统扮演着存储和管理数据的核心角色。Ubuntu作为广泛使用的Linux发行版,支持多
飞腾 U-Boot 初始化流程详解:启动前的准备步骤(内含专家技巧)
参考资源链接:[飞腾FT-2000/4 U-BOOT开发与使用手册](https://wenku.csdn.net/doc/3suobc0nr0?spm=1055.2635.3001.10343)
# 1. 飞腾U-Boot及其初始化流程概述
飞腾U-Boot作为一款开源的引导加载器,是许多嵌入式系统的首选启动程序,尤其在飞腾处理器的硬件平台上占据重要地位
【Ubuntu上安装QuestaSim 2021终极指南】:全面优化性能与兼容性

参考资源链接:[Ubuntu 20.04 安装QuestaSim2021全步骤指南](https://wenku.csdn.net/doc/3siv24jij8?spm=1055.2635.3001.10343)
# 1. QuestaSim与数字仿真基础
## 数字仿真简述
数字仿真是一种技术手段,通过计算机模拟电子系统的操作过程,以预测系统对各种输入信号的响应。它在电子设计
HyperMesh材料属性设置:确保正确赋值与验证的秘诀
参考资源链接:[HyperMesh入门:网格划分与模型优化教程](https://wenku.csdn.net/doc/7zoc70ux11?spm=1055.2635.
MODBUS故障排查实战:使用MODSCAN32迅速诊断和解决问题

参考资源链接:[基于MODSCAN32的MODBUS通讯数据解析](https://wenku.csdn.net/doc/6412b5adbe7fbd1778d44019?spm=1055.2635.3001.10343)
# 1. MODBUS协议基础知识
MODBUS协议是工业领域广泛使用的一种简单、开放、可靠的通信协议。最初由Modicon公司开发,现已成为工业电子通信
MATPOWER潮流计算可视化解读:结果展示与深度分析

参考资源链接:[MATPOWER潮流计算详解:参数设置与案例示范](https://wenku.csdn.net/doc/6412b4a1be7fbd1778d40417?spm=1055.2635.3001.10343)
# 1. 潮流计算基础与MATPOWER简介
潮流计算是电力系统分析的基石,它涉及计算在不同
电源管理芯片应用详解:为单片机USB供电电路选型与配置指南
参考资源链接:[单片机使用USB接口供电电路制作](https://wenku.csdn.net/doc/6412b7abbe7fbd1778d4b20d?spm=1055.2635.3001.10343)
# 1. 电源管理芯片基础与重要性
电源管理芯片是电子系统中不可或缺的组件,它负责调节供电电压和电流,以确保各部分电子设备能够稳定、高效地工作。随着技术的进步,电源
10GBASE-R技术深度剖析:如何确保数据中心的网络性能与稳定性
参考资源链接:[10GBASE-R协议详解:从Arria10 Transceiver到PCS架构](https://wenku.csdn.net/doc/10ayqu73ib?spm=1055.2635.3001.10343)
# 1. 10GBASE-R技术概述
## 1.1 技术背景与定义
10GBASE-R技术是IEEE 802
【兼容性保证】:LAN8720A与IEEE标准的最佳实践

参考资源链接:[Microchip LAN8720A/LAN8720Ai: 低功耗10/100BASE-TX PHY芯片,全面RMII接口与HP Auto-MDIX支持](https://wenku.csdn.net/doc/6470614a543f844488
B-6系统集成挑战:与第三方服务无缝对接的7个策略
参考资源链接:[墨韵读书会:软件学院书籍共享平台详细使用指南](https://wenku.csdn.net/doc/74royby0s6?spm=1055.2635.3001.10343)
# 1. 系统集成与第三方服务对接概述
在当今高度数字化的商业环境中,企业运作越来越依赖于技术系统来优化流程、增强用户体验和提高竞争力。系统集成(
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )