【Python量化编程的最佳实践】:编写高效量化代码的权威指南
发布时间: 2024-12-24 22:13:29 阅读量: 25 订阅数: 14 

Python单元测试完全指南:编写、运行与最佳实践

# 摘要
随着金融市场的日益复杂化,Python量化编程成为了投资者和金融工程师分析、执行交易策略的重要工具。本文首先概述了Python量化编程的基础知识及其在金融市场中的应用,然后深入讲解了量化工具与库的运用,包括数据处理与分析、统计与优化、可视化技术以及金融数据的接入与管理。在策略构建与回测章节,本文探讨了量化策略设计、风险管理、回测框架搭建以及案例分析。此外,文章还涉及了量化实战技巧,如性能优化、实时交易系统开发和大数据环境下的量化策略。最后,本文展望了Python量化编程的未来趋势,包括自动化量化分析、人工智能与深度学习的应用以及云端量化平台的发展。附录部分提供了丰富的参考文献、资源索引以及编码与调试技巧,为量化编程的学习者和实践者提供了全面的学习资料。
# 关键字
Python量化编程;数据分析;策略回测;性能优化;实时交易系统;大数据技术
参考资源链接:[极智量化Python教程:从入门到实战](https://wenku.csdn.net/doc/7qmvueq8ok?spm=1055.2635.3001.10343)
# 1. Python量化编程概述
量化投资是一种利用计算机技术、统计学原理、数学模型来指导投资决策的方法。随着金融市场的发展和计算机技术的进步,量化投资已经成为金融行业不可或缺的一部分。
Python作为一门简洁而强大的编程语言,其在量化投资领域的应用逐渐成为一种趋势。Python语言简洁易读,拥有大量的开源库,这些特性使得Python成为量化投资的首选语言。
在量化投资中,Python的主要优势在于其丰富的数据分析库,如NumPy、Pandas等,这些库能够处理大量的数据,进行高效的数据分析。此外,Python还有强大的可视化库,如Matplotlib和Seaborn,可以帮助我们更好地理解数据和分析结果。
本章将对Python量化编程进行概述,包括其在量化投资中的应用、优势以及如何入门Python量化编程等内容。后续章节将深入探讨Python量化工具与库的掌握,量化策略的构建与回测,Python量化实战技巧以及Python量化编程的未来趋势等内容。
# 2. Python量化工具与库的掌握
Python是一种广泛应用于量化领域的编程语言,它以其简洁明了的语法、强大的社区支持以及丰富的库生态系统成为量化分析者的首选。本章将详细介绍Python量化工具和库的使用,包括基础库的运用、高级量化分析工具以及金融数据接入与管理。
## 2.1 Python基础库的运用
### 2.1.1 NumPy与数据处理
NumPy是Python中最基础且强大的科学计算库之一,其核心功能是支持大规模多维数组与矩阵运算。它不仅能够提供快速的数值计算能力,还包含了许多数学函数库。
#### 核心特性与应用
- **数组对象**:NumPy核心是ndarray对象,它能够提供一个通用的同质数据多维容器。
- **广播机制**:能够对不同形状的数组进行数学运算,极大地提高了编程效率。
- **矢量化操作**:比起传统的循环,NumPy的矢量化操作可以显著提升数据处理速度。
```python
import numpy as np
# 创建一个二维数组
array = np.array([[1, 2, 3], [4, 5, 6]])
print(array)
# 使用NumPy的广播机制进行运算
array2 = np.array([10, 20, 30])
print(array + array2)
# 矢量化操作示例
vectorized_result = array * 2
print(vectorized_result)
```
通过上述代码,我们可以看到如何创建NumPy数组,并执行基本的数组运算。广播机制允许我们直接将一个标量添加到数组,以及将两个不同形状的数组进行相加。矢量化操作则让数组的每个元素都参与运算,无需额外的循环语句。
### 2.1.2 Pandas与数据分析
Pandas库是基于NumPy构建的,提供了一些高级数据结构和操作工具,使得处理结构化数据变得异常简单和直观。Pandas的主要数据结构是DataFrame,它是一个二维、大小可变、潜在异质型标签数据表。
#### 核心特性与应用
- **DataFrame**:提供了一种能够存储并操作结构化数据的方式。
- **数据读取与清洗**:可以方便地读取不同格式的数据,比如CSV、Excel等,并进行清洗。
- **数据筛选与聚合**:支持基于标签的索引、切片和高级数据筛选功能。
```python
import pandas as pd
# 创建一个DataFrame
data = {'A': [1, 2, 3], 'B': [4, 5, 6]}
df = pd.DataFrame(data)
print(df)
# 数据筛选
filtered_data = df[df.A > 1]
print(filtered_data)
# 数据聚合
aggregated_data = df.mean()
print(aggregated_data)
```
通过这段代码,我们创建了一个简单的DataFrame,并展示了如何筛选和聚合数据。Pandas的筛选功能允许我们根据条件选择数据行,而聚合功能提供了计算DataFrame中数据的统计摘要。
## 2.2 高级量化分析工具
### 2.2.1 SciPy在统计与优化中的应用
SciPy是一个开源的Python算法库和数学工具包,建立在NumPy之上。它为用户提供了一系列科学计算的功能,包括积分、优化、统计和线性代数等。
#### 核心特性与应用
- **优化模块**:提供了多种优化算法,用于解决无约束或有约束的最优化问题。
- **统计模块**:提供概率分布、统计测试以及描述性统计量的生成与计算。
- **线性代数模块**:提供了线性方程组求解、特征值计算、矩阵分解等功能。
```python
from scipy import optimize
from scipy import stats
# 一个优化问题的例子:最小化函数x^2 + 10sin(x)
result = optimize.minimize(lambda x: x**2 + 10*np.sin(x), x0=0)
print(result.x)
# 使用SciPy进行统计计算
data = stats.norm.rvs(size=1000)
print(stats.describe(data))
```
此代码段演示了如何使用SciPy解决一个简单的优化问题,并使用其内置的统计功能来描述一组数据。优化模块使用了Nelder-Mead算法,而统计模块则提供了数据集的快速统计摘要。
### 2.2.2 Matplotlib和Seaborn的可视化技术
Matplotlib和Seaborn是Python中最流行的绘图库,它们使得复杂的数据可视化变得简单。Matplotlib提供了一个非常灵活的绘图接口,而Seaborn在Matplotlib的基础上增加了更多高级图表和一个更高级别的接口。
#### 核心特性与应用
- **Matplotlib**:能够生成各种静态、动态、交互式的图表。
- **Seaborn**:提供了更丰富的图表类型,如热图、分布图、类别图,并且使得这些图表的生成更加简洁。
```python
import matplotlib.pyplot as plt
import seaborn as sns
# 使用Matplotlib绘制基本的线图
plt.plot([1, 2, 3], [4, 5, 6])
plt.title("Simple Plot")
plt.xlabel("x")
plt.ylabel("y")
plt.show()
# 使用Seaborn绘制一个散点图矩阵
tips = sns.load_dataset("tips")
sns.pairplot(tips)
plt.show()
```
上述代码展示了使用Matplotlib绘制基本线图的方式,以及使用Seaborn绘制散点图矩阵的快速方法。Seaborn的pairplot函数可以快速生成数据集各变量间的配对关系图。
## 2.3 金融数据接入与管理
### 2.3.1 Yahoo Finance数据接入
在量化分析中,获取金融数据是第一步,而Yahoo Finance提供了丰富的金融数据源。Python通过yfinance库可以方便地从Yahoo Finance中抓取数据。
#### 核心特性与应用
- **数据抓取**:能够抓取股票的实时数据、历史数据、基本面数据等。
- **时间序列处理**:支持基于时间序列的金融数据分析。
- **数据清洗与预处理**:提供了一些基本的数据清洗功能。
```python
import yfinance as yf
# 获取股票数据
stock = yf.Ticker("AAPL")
data = stock.history(period="1y")
print(data.head())
```
这段代码演示了如何使用yfinance库获取苹果公司(AAPL)的股票历史数据。数据被抓取后,可以直接用于后续的分析。
### 2.3.2 数据库存储与检索方法
将抓取的数据存储到数据库中,并能够高效地进行检索,是量化分析流程中的重要环节。SQLite是Python中一个轻量级的数据库系统,不需要独立的服务器进程,非常适合个人项目和小型应用。
#### 核心特性与应用
- **数据存储**:提供了一个简单的文件型数据库,能够存储和检索数据。
- **SQL查询**:支持标准的SQL查询语言,进行数据检索。
- **Python交互**:能够直接通过Python代码进行数据库操作。
```python
import sqlite3
# 连接到SQLite数据库
# 如果文件不存在,会自动在当前目录创建一个数据库文件
conn = sqlite3.connect('finance_data.db')
# 创建一个Cursor对象并通过它执行SQL语句
cursor = conn.cursor()
cursor.execute('CREATE TABLE IF NOT EXISTS stock_data (date text, open real, high real, low real, close real, volume integer)')
# 插入数据
stock = yf.Ticker("AAPL")
data = stock.history(period="1y")
for row in data.itertuples():
cursor.execute('INSERT INTO stock_data VALUES(?, ?, ?, ?, ?, ?)',
(row.date, row.open, row.high, row.low, row.close, row.volume))
# 提交事务
conn.commit()
# 查询数据
cursor.execute('SELECT * FROM stock_data WHERE date BETWEEN "2021-01-01" AND "2021-01-07"')
rows = cursor.fetchall()
print(rows)
# 关闭Cursor和Connection
cursor.close()
conn.close()
```
这段代码展示了如何创建一个SQLite数据库和一个表格,然后从Yahoo Finance获取数据并将其存储到数据库中。同时,我们还演示了如何通过SQL查询检索特定日期范围内的数据。
至此,我们完成了第二章的内容,即Python量化工具与库的掌握。本章介绍了基础库的运用,如NumPy和Pandas在数据处理方面的应用;高级量化分析工具,如SciPy的优化功能、Matplotlib和Seaborn的可视化技术;以及金融数据接入与管理,包括从Yahoo Finance获取数据和使用SQLite进行数据存储。通过本章的学习,读者应该能够熟练掌握Python在量化分析中的核心工具和库。
# 3. 量化策略的构建与回测
量化交易策略是量化投资的核心,它们定义了一系列规则和条件,指导着投资者何时买入或卖出资产。成功的量化策略能带来丰厚的回报,但构建一个有效策略的过程充满挑战,需要深入理解市场、统计学原理,以及对交易成本和风险的管理。在策略构建后,回测是必不可少的一步,它能验证策略在历史数据上的表现,为策略未来的盈利能力提供参考。
## 3.1 策略设计原则与实践
### 3.1.1 基于统计学的策略设计
量化交易策略通常建立在统计学原理之上,通过历史数据分析来发现可利用的市场模式或异常。设计策略时,我们首先会确定交易信号的生成方法,然后决定资金如何在不同资产间分配。
在统计学基础之上,策略设计的一个关键步骤是确定信号的统计显著性。这涉及到概率分布的理解、置信区间、假阳性(Type I error)和假阴性(Type II error)等概念。举个例子,我们可能会选择一个特定的技术指标,如移动平均线交叉策略,作为我们的信号生成机制。当短期移动平均线从下方穿过长期移动平均线时,视为买入信号;反之则视为卖出信号。
一个典型的代码块可能如下所示:
```python
import numpy as np
import pandas as pd
import talib
# 假设我们有一个DataFrame 'df' 包含价格数据
df['MA_Short'] = talib.MA(df['Close'], timeperiod=50, matype=0) # 50日移动平均线
df['MA_Long'] = talib.MA(df['Close'], timeperiod=200, matype=0) # 200日移动平均线
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
《极智量化(Python语言)帮助文档.pdf》专栏提供全面的 Python 量化分析指南,涵盖从基础知识到高级技术的各个方面。专栏文章包括:
* 掌握金融量化交易的 10 大核心技能
* Python 实战技巧,用于量化投资中的数据可视化
* 解决真实世界量化问题的 10 个关键步骤
* 参数调优和模型选择的投资策略优化艺术
* 极智量化集成工具的高级使用技巧
* 编写高效量化代码的最佳实践
* 数据结构和算法的深入解析,用于量化分析
* 利用统计学原理优化交易策略的统计模型应用
* 高效抓取互联网金融数据的技术
* Python 量化机器学习入门指南
专栏目录

文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【ADXL362应用实例解析】:掌握在各种项目中的高效部署方法
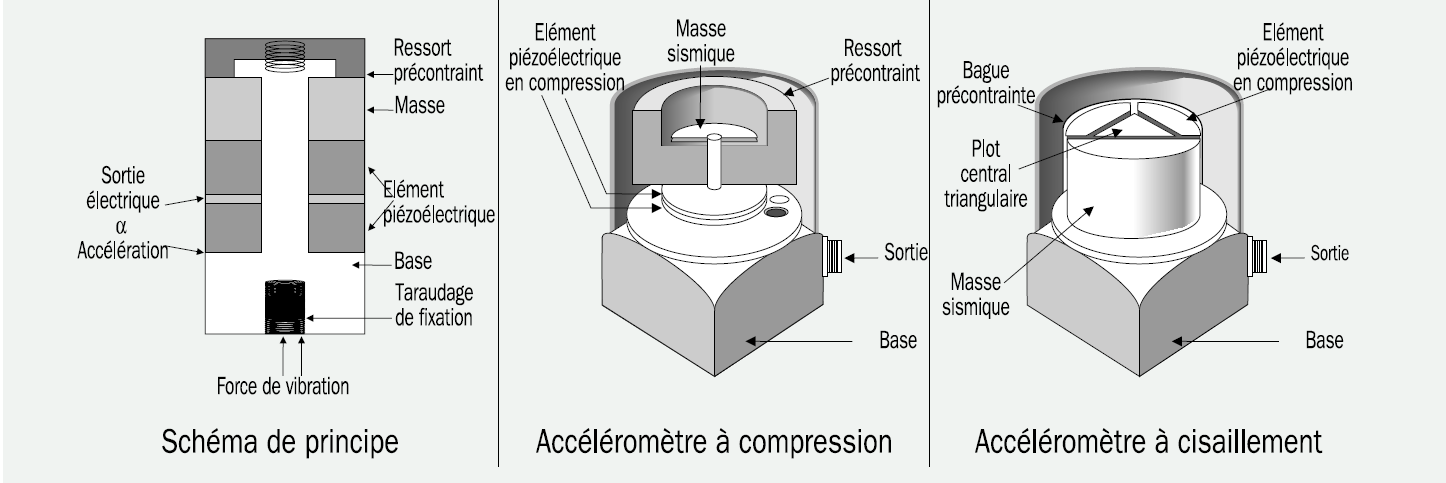
# 摘要
ADXL362是一款先进的低功耗三轴加速度计,广泛应用于多种项目中,包括穿戴设备、自动化系统和物联网设备。本文旨在详细介绍ADXL362的基本概念、硬件集成、数据采集与处理、集成应用以及软件开发和调试,并对未来的发展趋势进行展望。文章首先介绍了ADXL362的特性,并且深入探讨了其硬件集成和配置方法,如电源连接、通信接口连接和配置
【设备充电兼容性深度剖析】:能研BT-C3100如何适应各种设备(兼容性分析)

# 摘要
本文对设备充电兼容性进行了全面分析,特别是针对能研BT-C3100充电器的技术规格和实际兼容性进行了深入研究。首先概述了设备充电兼容性的基础,随后详细分析了能研BT-C3100的芯片和电路设计,充电协议兼容性以及安全保护机制。通过实际测试,本文评估了BT-C3100与多种设备的充电兼容性,包括智能手机、平板电脑、笔记本电脑及特殊设备,并对充电效率和功率管理进行了评估。此外,本文还探讨了BT-C3100的软件与固件
【SAP角色维护进阶指南】:深入权限分配与案例分析

# 摘要
本文全面阐述了SAP系统中角色维护的概念、流程、理论基础以及实践操作。首先介绍了SAP角色的基本概念和角色权限分配的理论基础,包括权限对象和字段的理解以及分配原则和方法。随后,文章详细讲解了角色创建和修改的步骤,权限集合及组合角色的创建管理。进一步,探讨了复杂场景下的权限分配策略,角色维护性能优化的方法,以及案例分析中的问题诊断和解决方案的制定
【CAPL语言深度解析】:专业开发者必备知识指南

# 摘要
本文详细介绍了一种专门用于CAN网络编程和模拟的脚本语言——CAPL(CAN Access Programming Language)。首先,文章介绍了CAPL的基
MATLAB时域分析大揭秘:波形图绘制与解读技巧
# 摘要
本文详细探讨了MATLAB在时域分析和波形图绘制中的应用,涵盖了波形图的基础理论、绘制方法、数据解读及分析、案例研究和美化导出技巧。首先介绍时域分析的基础知识及其在波形图中的作用,然后深入讲解使用MATLAB绘制波形图的技术,包括基本图形和高级特性的实现。在数据解读方面,本文阐述了波形图的时间和幅度分析、信号测量以及数学处理方法。通过案例研究部分,文章展示了如何应用波形图
汉化质量控制秘诀:OptiSystem组件库翻译后的校对与审核流程

# 摘要
随着软件国际化的需求日益增长,OptiSystem组件库汉化项目的研究显得尤为重要。本文概述了汉化项目的整体流程,包括理论基础、汉化流程优化、质量控制及审核机制。通过对汉化理论的深入分析和翻译质量评价标准的建立,本文提出了一套汉化流程的优化策略,并讨论了翻译校对的实际操作方法。此外,文章详细介绍了汉化组件库
PADS电路设计自动化进阶:logic篇中的脚本编写与信号完整性分析

# 摘要
本文综合介绍PADS电路设计自动化,从基础脚本编写到高级信号完整性分析,详细阐述了PADS Logic的设计流程、脚本编写环境搭建、基本命令以及进阶的复杂设计任务脚本化和性能优化。同时,针对信号完整性问题,本文深入讲解了影响因素、分析工具的使用以及解决策略,提供了高速接口电路设计案例和复杂电路板设计挑战的分析。此外,本文还探讨了自动化脚本与
【Java多线程编程实战】:掌握并行编程的10个秘诀
# 摘要
Java多线程编程是一种提升应用程序性能和响应能力的技术。本文首先介绍了多线程编程的基础知识,随后深入探讨了Java线程模型,包括线程的生命周期、同步机制和通信协作。接着,文章高级应用章节着重于并发工具的使用,如并发集合框架和控制组件,并分析了原子类与内存模型。进一步地,本文讨论了多线程编程模式与实践,包括设计模式的应用、常见错误分析及高性能技术。
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )