Logstash插件开发详解与常用插件介绍
发布时间: 2024-01-11 10:03:40 阅读量: 35 订阅数: 43 
# 1.
## 第一章:Logstash插件开发介绍
Logstash是一个开源的数据处理引擎,用于收集、分析和转发数据。它通过插件来扩展功能,使得用户可以根据自己的需求定制化Logstash的行为。
### 1.1 Logstash插件的概念
插件是Logstash的组成部分,用于实现特定的功能。Logstash插件可以分为输入插件、过滤插件和输出插件三种类型。输入插件用于从不同来源收集数据,过滤插件用于对数据进行处理和转换,输出插件用于将处理后的数据发送到目标位置。
### 1.2 Logstash插件类型
Logstash插件分为官方插件和自定义插件两种类型。官方插件是由Logstash团队维护和提供支持的插件,包括常用的输入、过滤和输出插件。自定义插件是用户根据自己的需求开发的插件,可以满足特定场景下的需求。
### 1.3 Logstash插件开发环境搭建
要进行Logstash插件开发,需要先搭建开发环境。首先,确保已安装好以下软件和工具:
- Java JDK
- Ruby环境
- Logstash
接下来,通过安装Logstash依赖的插件管理工具`gem`,来安装`logstash-devutils`插件,以便进行插件开发:
```bash
gem install logstash-devutils
```
### 1.4 开发第一个Logstash插件示例
我们来开发一个简单的Logstash插件示例,该插件用于对输入的文本进行大写转换。首先,在Logstash安装目录下创建一个新的插件项目:
```bash
bin/logstash-plugin generate --type plugin --name my_uppercase_filter
```
此命令将生成一个名为`my_uppercase_filter`的插件项目,包含了示例插件的基本结构。
然后,进入插件项目目录,编辑`lib/logstash/filters/my_uppercase_filter.rb`文件,实现大写转换逻辑:
```ruby
require "logstash/filters/base"
require "logstash/namespace"
class LogStash::Filters::MyUppercaseFilter < LogStash::Filters::Base
config_name "my_uppercase_filter"
def filter(event)
return unless filter?(event)
event.set("message", event.get("message").upcase)
filter_matched(event)
end
end
```
接下来,将该插件打包为gem文件:
```bash
gem build my_uppercase_filter.gemspec
```
最后,使用以下命令安装插件:
```bash
bin/logstash-plugin install /path/to/my_uppercase_filter.gem
```
现在,我们已经成功开发并安装了一个自定义的Logstash插件。可以在Logstash配置文件中使用该插件:
```conf
input {
stdin {}
}
filter {
my_uppercase_filter {}
}
output {
stdout {}
}
```
运行Logstash,输入文本后,将会看到输入的文本被转换为大写输出。
这是第一章的内容,我们介绍了Logstash插件的概念、类型,以及开发环境的搭建和第一个插件示例的开发过程。在接下来的章节中,我们将深入探讨Logstash插件的开发细节和常用插件的使用方法。
# 2. Logstash输入插件开发详解
Logstash的输入插件用于从各种来源获取数据并将其发送到管道中进行处理。在本章中,我们将详细介绍Logstash输入插件的开发方法和注意事项,并通过一个实例来演示如何开发一个自定义的Logstash输入插件。
### 2.1 输入插件的作用与使用场景
输入插件用于从不同的来源获取数据,例如文件、数据库、网络等,然后将数据发送到Logstash管道中,以便进行后续的处理和分析。常见的使用场景包括日志采集、监控数据收集等。
### 2.2 输入插件开发步骤与注意事项
要开发自定义的Logstash输入插件,您需要按照以下步骤进行操作:
1. 编写插件代码
2. 定义配置选项
3. 实现注册逻辑
4. 实现数据采集逻辑
5. 编译插件并测试
在开发过程中,需要注意配置选项的定义、线程安全性、异常处理等方面的细节。
### 2.3 实例:开发一个自定义的Logstash输入插件
我们将以Java语言为例,演示如何开发一个简单的Logstash输入插件,该插件从网络接收数据,并将其发送到Logstash管道中。
```java
// 示例代码,仅用于演示插件框架,具体实现可能有所不同
public class CustomInputPlugin implements Input {
private String host;
private int port;
private Queue<Event> events;
public CustomInputPlugin(String host, int port) {
this.host = host;
this.port = port;
this.events = new ConcurrentLinkedQueue<>();
}
@Override
public void register(PluginContext pluginContext) {
// 注册插件逻辑,可以进行一些初始化操作
}
@Override
public void start(Consumer<Event> consumer) {
// 启动插件逻辑,连接网络并接收数据
while (true) {
// 接收数据逻辑,将数据封装为Event对象,并发送给consumer
Event event = new Event();
consumer.accept(event);
}
}
@Override
public void stop() {
// 停止插件逻辑,关闭网络连接等清理操作
}
// Other methods and implementation details
}
```
以上是一个简化的输入插件示例,实际开发中还需要考虑异常处理、配置选项解析等细节。
### 2.3.1 代码总结
以上示例中,我们演示了一个简单的Logstash输入插件的基本框架,包括注册、启动和停止逻辑。实际开发中,还需要考虑配置选项的解析、线程安全性等细节。
### 2.3.2 结果说明
通过该实例,我们可以了解到如何以Java语言开发一个基本的Logstash输入插件,并将其集成到Logstash的数据处理流程中。
希望这个例子可以帮助您理解Logstash输入插件的开发方法和注意事项。
# 3. Logstash过滤插件开发详解
Logstash过滤插件用于对输入的数据进行处理、转换和过滤,以满足特定的需求和要求。本章将详细介绍Logstash过滤插件的开发过程和注意事项,并提供一个实例来演示如何开发一个自定义的Logstash过滤插件。
### 3.1 过滤插件的作用与使用场景
过滤插件主要用于对输入的事件数据进行格式化、解析、转换和过滤,常用的使用场景包括:
- 日志数据字段提取:从原始日志数据中提取特定字段,如提取日志中的时间戳、IP地址、用户信息等。
- 数据格式转换:将原始数据格式转换为特定的格式,如将JSON数据转换为CSV格式等。
- 数据清洗:对原始数据进行清洗和预处理,如删除无用字段、去除重复数据等。
- 数据过滤:根据特定的规则或条件过滤掉不符合要求的数据,如过滤掉错误日志、恶意请求等。
### 3.2 过滤插件开发步骤与注意事项
开发Logstash过滤插件的基本步骤如下:
步骤一:创建一个新的插件目录
首先,在Logstash的插件目录下创建一个新的文件夹,作为新插件的目录。
步骤二:创建插件配置文件
在新插件目录下创建一个名为`plugin-name.yml`的配置文件,用于配置插件的输入、输出等参数。
步骤三:实现过滤插件
在新插件目录下创建一个名为`filter_name.rb`的Ruby脚本文件,用于实现过滤逻辑和规则。在脚本中,可以使用Ruby语言提供的各种方法和函数对数据进行处理和转换。
步骤四:编辑插件说明文件
在新插件目录下创建一个名为`README.md`的Markdown文件,用于描述插件的功能、用法和使用示例。
步骤五:打包插件
使用Logstash提供的`gem`命令将插件目录打包成一个`.gem`文件,方便在Logstash中安装和使用。
注意事项:
- Logstash插件使用Ruby语言开发,熟悉Ruby语法和相关技术栈是开发过滤插件的基本要求。
- 插件目录结构和配置文件格式需要严格按照Logstash的要求进行,否则插件可能无法正常加载和使用。
- 在开发过程中,建议使用Logstash提供的调试工具和日志输出来验证插件的正确性和性能。
### 3.3 实例:开发一个自定义的Logstash过滤插件
下面以一个简单的示例来演示如何开发一个自定义的Logstash过滤插件,该插件用于将输入的日志中的时间戳字段转换为指定格式:
1. 在Logstash的插件目录下创建一个新的文件夹`logstash-filter-customtimestamp`,作为新插件的目录。
2. 在`logstash-filter-customtimestamp`目录下创建一个名为`logstash-filter-customtimestamp.yml`的配置文件,内容如下:
```yaml
name: logstash-filter-customtimestamp
version: 1.0.0
description: A custom Logstash filter plugin for customizing timestamp field
```
3. 创建一个名为`customtimestamp.rb`的Ruby脚本文件,内容如下:
```ruby
# encoding: utf-8
require "logstash/filters/base"
require "logstash/namespace"
# Logstash Custom Timestamp Filter Plugin
class LogStash::Filters::CustomTimestamp < LogStash::Filters::Base
config_name "customtimestamp"
config :field, :validate => :string, :required => true
config :format, :validate => :string, :required => true
public
def register
# Add instance variables
end
public
def filter(event)
# Modify the event
if event.get(@field)
timestamp = event.get(@field)
custom_timestamp = Time.parse(timestamp)
.strftime(@format)
event.set("custom_timestamp", custom_timestamp)
end
# filter_matched should go in the last line of our successful code
filter_matched(event)
end
end
```
4. 在`logstash-filter-customtimestamp`目录下创建一个名为`README.md`的Markdown文件,用于描述插件的功能和使用示例。
5. 使用Logstash提供的命令行工具将插件目录打包成一个`.gem`文件:
```shell
gem build logstash-filter-customtimestamp.gemspec
```
6. 安装插件:
```shell
bin/logstash-plugin install logstash-filter-customtimestamp-1.0.0.gem
```
以上是Logstash过滤插件的开发过程和一个简单示例。开发者可以根据实际需求和业务场景,编写自定义的过滤插件,以满足数据处理和转换的需求。
希望这个章节的内容对您有所帮助!
# 4. Logstash输出插件开发详解
在本章中,将深入探讨Logstash输出插件的开发细节,包括输出插件的作用与使用场景、开发步骤与注意事项,以及通过一个实例来演示如何开发一个自定义的Logstash输出插件。
#### 4.1 输出插件的作用与使用场景
Logstash输出插件用于将经过处理的数据发送到指定的目的地,比如数据库、消息队列、文件等。它们可以用于数据的持久化存储、数据的传输和数据的交换等场景。
#### 4.2 输出插件开发步骤与注意事项
开发Logstash输出插件的步骤与输入插件类似,需要创建一个新的Ruby gem项目,并实现特定的接口方法。在开发过程中需要注意插件的可靠性、性能和扩展性,确保插件能够稳定地运行并与Logstash系统完美集成。
#### 4.3 实例:开发一个自定义的Logstash输出插件
下面以一个简单的示例来演示如何开发一个自定义的Logstash输出插件。假设我们需要将Logstash处理后的数据发送到一个HTTP API接口,我们可以通过开发一个HTTP输出插件来实现这个需求。
```ruby
# encoding: utf-8
require "logstash/outputs/base"
require "logstash/namespace"
class LogStash::Outputs::Http < LogStash::Outputs::Base
config_name "http"
# 设置API接口的URL和其他参数
config :url, :validate => :string, :required => true
config :headers, :validate => :hash, :default => {}
public
def register
# 在这里进行插件的初始化操作,比如建立HTTP连接等
end
public
def multi_receive_encoded(events_and_encoded)
# 处理接收到的事件数据,并将数据发送到API接口
events_and_encoded.each { |event, encoded|
# 发送数据到API接口的具体逻辑
# 这里可以使用第三方HTTP客户端库,比如Net::HTTP
# 例如:
# uri = URI(@url)
# request = Net::HTTP::Post.new(uri)
# request["Content-Type"] = "application/json"
# request.body = encoded
# response = Net::HTTP.start(uri.hostname, uri.port) {|http|
# http.request(request)
# }
}
end
public
def close
# 在插件关闭时执行清理操作,比如关闭HTTP连接等
end
end
```
上面是一个简化的HTTP输出插件示例,其中定义了一个`http`插件,并实现了注册、数据处理和关闭等方法。在实际开发中,还需要考虑异常处理、日志记录、配置参数的验证等更多细节。
### 结语
在本章中,我们深入了解了Logstash输出插件的开发细节,包括其作用与使用场景、开发步骤与注意事项,以及通过一个实例演示了如何开发一个自定义的Logstash输出插件。希望本章的内容能够帮助读者更加深入地理解Logstash插件开发的过程和技巧。
# 5. 常用Logstash插件介绍
Logstash是一个功能强大的日志收集、处理和传输工具,其插件系统为用户提供了丰富的扩展功能。本章将介绍一些常用的Logstash插件,并提供相应的示例。
### 5.1 Grok插件
Grok插件是Logstash中常用的解析工具,它可以根据用户定义的模式将日志中的结构化数据进行解析提取。下面是一个使用Grok插件的示例:
```ruby
input {
file {
path => "/var/log/nginx/access.log"
start_position => "beginning"
}
}
filter {
grok {
match => { "message" => "%{COMBINEDAPACHELOG}" }
}
}
output {
elasticsearch {
hosts => ["localhost:9200"]
index => "nginx-access-log"
}
}
```
在上述示例中,我们通过Grok插件解析了Nginx访问日志中的结构化数据,并将结果输出到Elasticsearch中的"nginx-access-log"索引。
### 5.2 Date插件
Date插件用于将日志中的时间字段进行解析与格式化。它支持各种常见的时间格式,并能将其转换为统一的时间格式。下面是一个使用Date插件的示例:
```ruby
input {
file {
path => "/var/log/app.log"
start_position => "beginning"
}
}
filter {
date {
match => ["timestamp", "yyyy-MM-dd HH:mm:ss", "ISO8601"]
}
}
output {
elasticsearch {
hosts => ["localhost:9200"]
index => "app-log"
}
}
```
在上述示例中,我们通过Date插件将日志中的"timestamp"字段按照"yyyy-MM-dd HH:mm:ss"或"ISO8601"格式解析,并将结果输出到Elasticsearch中的"app-log"索引。
### 5.3 Mutate插件
Mutate插件用于对日志事件的字段进行修改、拆分、合并等操作。它提供了一系列的处理方法,例如添加字段、删除字段、替换字段值等。下面是一个使用Mutate插件的示例:
```ruby
input {
file {
path => "/var/log/syslog"
start_position => "beginning"
}
}
filter {
mutate {
add_field => { "new_field" => "new_value" }
remove_field => ["old_field"]
rename => { "old_field" => "new_field" }
}
}
output {
elasticsearch {
hosts => ["localhost:9200"]
index => "syslog"
}
}
```
在上述示例中,我们通过Mutate插件添加了一个名为"new_field"的新字段,并且将"old_field"字段删除并重命名为"new_field",最后将结果输出到Elasticsearch中的"syslog"索引。
### 5.4 GeoIP插件
GeoIP插件用于根据IP地址获取地理位置信息。它基于MaxMind的地理位置数据库,可以识别IP地址对应的国家、地区、城市等信息。下面是一个使用GeoIP插件的示例:
```ruby
input {
beats {
port => 5044
}
}
filter {
geoip {
source => "client_ip"
target => "geoip"
database => "/usr/share/logstash/GeoLite2-City.mmdb"
}
}
output {
elasticsearch {
hosts => ["localhost:9200"]
index => "access-log"
}
}
```
在上述示例中,我们通过GeoIP插件将日志中的"client_ip"字段解析为地理位置信息,并将结果输出到Elasticsearch中的"access-log"索引。
### 5.5 Json插件
Json插件用于解析日志中的JSON格式数据,并将其转换为字段。它支持解析多层嵌套的JSON数据,并将其展开为扁平的字段结构。下面是一个使用Json插件的示例:
```ruby
input {
file {
path => "/var/log/app.log"
start_position => "beginning"
}
}
filter {
json {
source => "message"
remove_field => ["message"]
}
}
output {
elasticsearch {
hosts => ["localhost:9200"]
index => "app-log"
}
}
```
在上述示例中,我们通过Json插件解析了日志中的JSON格式数据,并将结果输出到Elasticsearch中的"app-log"索引。
### 5.6 其他常用插件介绍与示例
除了上述介绍的插件,Logstash还有许多其他常用插件,如Kafka插件、Jdbc插件、Http插件等。可以根据具体业务需求选择合适的插件进行配置和使用。
本章节介绍了一些常用的Logstash插件及其用法示例。通过合理使用这些插件,可以极大地增强Logstash的功能,实现更加灵活、高效的日志处理流程。
# 6. Logstash插件开发最佳实践与调优技巧
Logstash插件开发是一个复杂而又具有挑战性的工作,为了更好地满足用户需求并提高插件的性能,开发者需要遵循一些最佳实践和调优技巧。本章将介绍一些Logstash插件开发的最佳实践和调优技巧,帮助开发者更好地应用和优化他们的自定义插件。
#### 6.1 最佳实践指南
在进行Logstash插件开发时,遵循下面的最佳实践指南将有助于提高插件的可用性和可维护性:
- **遵循插件开发规范**: Logstash提供了插件开发规范和模板,开发者应当严格遵循这些规范来确保插件的正确性和兼容性。
- **详细的文档和注释**: 编写清晰、详细的文档和注释,包括插件的作用、配置参数、示例等,有助于用户更快地理解和使用插件。
- **单一职责原则**: 每个插件应当遵循单一职责原则,即一个插件只做一件事情,并且做好这件事情。
- **错误处理和日志记录**: 插件应当具备良好的错误处理机制,能够记录和报告错误信息,方便故障排查和调试。
#### 6.2 插件性能调优技巧
Logstash插件的性能直接影响着整个数据处理流程的效率,因此开发者需要重点关注插件的性能调优:
- **批量处理**: 尽量对事件进行批量处理,减少单个事件的处理开销,可以通过设置`batch_size`参数来实现。
- **避免资源泄露**: 注意资源的释放,避免内存泄露和资源泄露问题,利用RAII(资源获取即初始化)等技术来管理资源。
- **并发处理**: 对于耗时的操作,可以考虑使用多线程或者异步IO来提高并发处理能力,但需要注意线程安全和资源竞争问题。
#### 6.3 插件发布与维护建议
在插件开发完成后,要考虑到插件的发布和维护工作:
- **及时更新**: 随着Logstash的版本更新和用户反馈,及时更新和维护插件,修复bug和兼容性问题。
- **发布到官方仓库**: 将插件发布到Logstash官方的插件仓库,方便用户安装和更新。
以上是关于Logstash插件开发最佳实践与调优技巧的一些指导,开发者可以根据实际需求和场景进行调整和应用。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
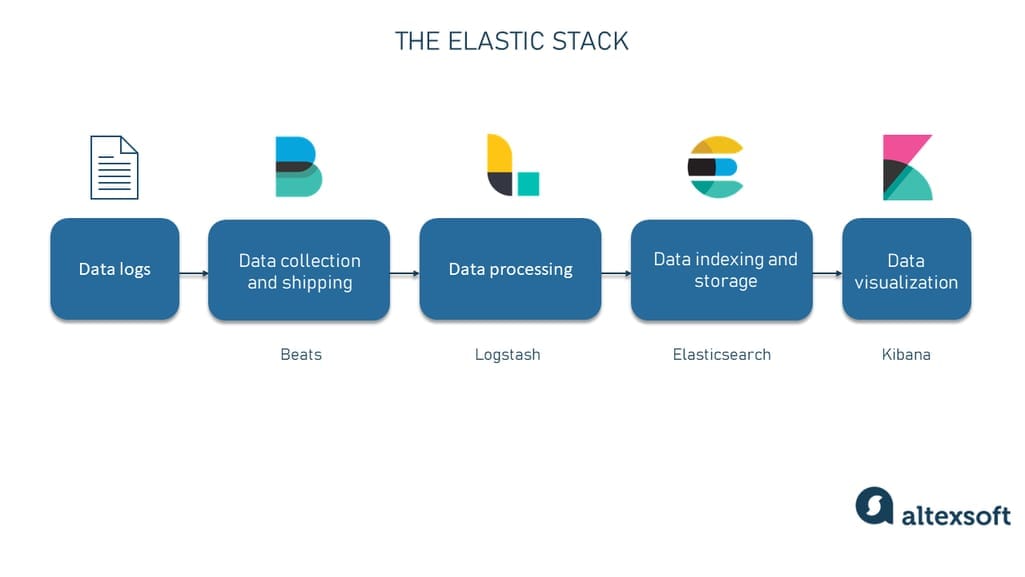
这个专栏名为"ELK7.x通用教程(elasticsearch集群 logstash kibana beats)",旨在提供关于ELK技术栈的全面指导。在专栏中,我们将介绍ELK技术栈的基本概念和原理,帮助读者熟悉日志管理的基本知识。我们还会详细说明如何搭建ELK7.x环境,包括Elasticsearch集群的简介和搭建方法。此外,我们会介绍Elasticsearch索引的管理,包括映射、分片和副本等关键概念。我们将深入探讨Logstash的基本用法和日志收集配置,并介绍Logstash插件的开发和常用插件的用法。此外,我们还会介绍Kibana的基础功能和高级功能,包括可视化和仪表盘的创建,以及搜索、过滤和聚合的方法。另外,我们会详细介绍Beats的使用,包括Filebeat的配置和日志收集。我们还会介绍Beats的进阶用法,如Metricbeat、Packetbeat、Heartbeat等的应用。此外,我们还会探讨ELK7.x下的数据管道概念和实践,以及Logstash与Elasticsearch的深度集成并实践;我们将介绍Elasticsearch集群的监控和性能调优,以及Logstash插件的开发实战。此外,我们还会分享Kibana Dashboard面板设计的最佳实践,并介绍Kibana高级可视化的方法,如Time Series、Metric、Tag Cloud等。我们还会讲解Beats模块的定制开发和扩展,以及ELK7.x下的安全策略实施和权限管理。最后,我们会介绍Elasticsearch的数据备份和恢复,以及Logstash的高级应用,例如复杂日志处理和转换。这个专栏将帮助读者全面了解ELK技术栈的各个组件,并实践其在日志管理中的应用。
专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【Python讯飞星火LLM问题解决】:1小时快速排查与解决常见问题
# 1. Python讯飞星火LLM简介
Python讯飞星火LLM是基于讯飞AI平台的开源自然语言处理工具库,它将复杂的语言模型抽象化,通过简单易用的API向开发者提供强大的语言理解能力。本章将从基础概览开始,帮助读者了解Python讯飞星火LLM的核心特性和使用场景。
## 星火LLM的核心特性
讯飞星火LLM利用深度学习技术,尤其是大规模预训练语言模型(LLM),提供包括但不限于文本分类、命名实体识别、情感分析等自然语言处理功能。开发者可以通过简单的函数调用,无需复杂的算法知识,即可集成高级的语言理解功能至应用中。
## 使用场景
该工具库广泛适用于各种场景,如智能客服、内容审
【数据集不平衡处理法】:解决YOLO抽烟数据集类别不均衡问题的有效方法

# 1. 数据集不平衡现象及其影响
在机器学习中,数据集的平衡性是影响模型性能的关键因素之一。不平衡数据集指的是在分类问题中,不同类别的样本数量差异显著,这会导致分类器对多数类的偏好,从而忽视少数类。
## 数据集不平衡的影响
不平衡现象会使得模型在评估指标上产生偏差,如准确率可能很高,但实际上模型并未有效识别少数类样本。这种偏差对许多应
【大数据处理利器】:MySQL分区表使用技巧与实践
# 1. MySQL分区表概述与优势
## 1.1 MySQL分区表简介
MySQL分区表是一种优化存储和管理大型数据集的技术,它允许将表的不同行存储在不同的物理分区中。这不仅可以提高查询性能,还能更有效地管理数据和提升数据库维护的便捷性。
## 1.2 分区表的主要优势
分区表的优势主要体现在以下几个方面:
- **查询性能提升**:通过分区,可以减少查询时需要扫描的数据量
【MATLAB在Pixhawk定位系统中的应用】:从GPS数据到精确定位的高级分析

# 1. Pixhawk定位系统概览
Pixhawk作为一款广泛应用于无人机及无人车辆的开源飞控系统,它在提供稳定飞行控制的同时,也支持一系列高精度的定位服务。本章节首先简要介绍Pixhawk的基本架构和功能,然后着重讲解其定位系统的组成,包括GPS模块、惯性测量单元(IMU)、磁力计、以及_barometer_等传感器如何协同工作,实现对飞行器位置的精确测量。
我们还将概述定位技术的发展历程,包括
【用户体验设计】:创建易于理解的Java API文档指南
# 1. Java API文档的重要性与作用
## 1.1 API文档的定义及其在开发中的角色
Java API文档是软件开发生命周期中的核心部分,它详细记录了类库、接口、方法、属性等元素的用途、行为和使用方式。文档作为开发者之间的“沟通桥梁”,确保了代码的可维护性和可重用性。
## 1.2 文档对于提高代码质量的重要性
良好的文档
面向对象编程与函数式编程:探索编程范式的融合之道

# 1. 面向对象编程与函数式编程概念解析
## 1.1 面向对象编程(OOP)基础
面向对象编程是一种编程范式,它使用对象(对象是类的实例)来设计软件应用。
Spring核心特性深度剖析:最佳实践与代码示例
# 1. Spring框架介绍和核心概念
## 简介
Spring框架是Java开发者耳熟能详的开源框架,它为开发Java应用提供了全面的基础结构支持。从企业应用开发到复杂的集成解决方案,Spring都扮演着重要的角色。Spring的核心是基于轻量级的控制反转(IoC)和面向切面编程(AOP)原理。
## 核心概念
- **控制反转(IoC)**:也称为依赖注入(DI),它是一种设计模式,用于减少代码的耦合性。通过控
绿色计算与节能技术:计算机组成原理中的能耗管理
# 1. 绿色计算与节能技术概述
随着全球气候变化和能源危机的日益严峻,绿色计算作为一种旨在减少计算设备和系统对环境影响的技术,已经成为IT行业的研究热点。绿色计算关注的是优化计算系统的能源使用效率,降低碳足迹,同时也涉及减少资源消耗和有害物质的排放。它不仅仅关注硬件的能耗管理,也包括软件优化、系统设计等多个方面。本章将对绿色计算与节能技术的基本概念、目标及重要性进行概述
Java中JsonPath与Jackson的混合使用技巧:无缝数据转换与处理

# 1. JSON数据处理概述
JSON(JavaScript Object Notation)数据格式因其轻量级、易于阅读和编写、跨平台特性等优点,成为了现代网络通信中数据交换的首选格式。作为开发者,理解和掌握JSON数
微信小程序登录后端日志分析与监控:Python管理指南
# 1. 微信小程序后端日志管理基础
## 1.1 日志管理的重要性
日志记录是软件开发和系统维护不可或缺的部分,它能帮助开发者了解软件运行状态,快速定位问题,优化性能,同时对于安全问题的追踪也至关重要。微信小程序后端的日志管理,虽然在功能和规模上可能不如大型企业应用复杂,但它在保障小程序稳定运行和用户体验方面发挥着基石作用。
## 1.2 微
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )