tkinter中文本框的应用与高级技巧
发布时间: 2023-12-14 14:26:51 阅读量: 41 订阅数: 25 

Tkinter GUI 应用开发秘籍【已排版和加书签】
# 第一章:介绍tkinter中的文本框
## 1.1 什么是tkinter?
Tkinter是Python的标准GUI(图形用户界面)工具包,它提供了创建GUI应用所需的基本组件和功能。其中包含了文本框等常用的GUI元素,可以用于用户输入和显示文本内容。
## 1.2 文本框的基本概念和用法
文本框是GUI应用中常用的输入和输出控件,用于允许用户输入文本或在界面上显示文本。在Tkinter中,文本框有着丰富的属性和方法,可以实现丰富的文本处理功能。在本章节中,我们将介绍如何在Tkinter中创建和使用文本框,并了解其基本概念和用法。
第二章:创建和布局文本框
========================
2.1 创建文本框
----------------
在tkinter中,可以使用`Text`组件创建一个文本框。以下是创建文本框的代码示例:
```python
import tkinter as tk
root = tk.Tk()
text_box = tk.Text(root, height=10, width=30)
text_box.pack()
root.mainloop()
```
上述代码创建了一个高度为10行,宽度为30个字符的文本框,并将其添加到了窗口中。
2.2 布局文本框
----------------
在tkinter中,可以使用`pack()`、`grid()`或`place()`等方法来布局文本框。以下是使用`grid()`方法布局文本框的代码示例:
```python
import tkinter as tk
root = tk.Tk()
text_box = tk.Text(root, height=10, width=30)
text_box.grid(row=0, column=0)
root.mainloop()
```
上述代码将文本框添加到了网格布局的第一行第一列的位置。
2.3 设置文本框的样式
---------------------
在tkinter中,可以通过设置文本框的属性,如`font`、`foreground`和`background`等来改变文本框的样式。以下是设置文本框样式的代码示例:
```python
import tkinter as tk
root = tk.Tk()
text_box = tk.Text(root, height=10, width=30)
text_box.config(font=("Arial", 12), fg="red", bg="white")
text_box.pack()
root.mainloop()
```
上述代码将文本框的字体设置为Arial、字体大小设置为12、字体颜色设置为红色、背景颜色设置为白色。
### 第三章:文本框的基本功能和应用
#### 3.1 输入和输出文本内容
文本框是一种常见的用户输入和展示文本内容的界面控件。在tkinter中,我们可以使用Text类来创建和操作文本框。
首先,我们需要导入tkinter库:
```python
import tkinter as tk
```
然后,我们可以创建一个文本框并设置其大小和位置:
```python
root = tk.Tk()
text_box = tk.Text(root, width=30, height=10)
text_box.pack()
```
接下来,我们可以使用`insert()`方法插入文本:
```python
text_box.insert(1.0, "Hello, World!")
```
`insert()`方法的第一个参数是行号和列号组成的索引,其中1.0表示第一行第一列的位置。我们可以通过`get()`方法获取文本框中的内容:
```python
text = text_box.get(1.0, tk.END)
print(text)
```
上述代码会输出文本框中的内容。
#### 3.2 添加滚动条
当文本框内容超过显示范围时,我们可以添加滚动条来浏览文本。可以使用Scrollbar类来创建滚动条,并将其与文本框关联。
下面是一个例子:
```python
root = tk.Tk()
scrollbar = tk.Scrollbar(root)
text_box = tk.Text(root, width=30, height=10)
scrollbar.pack(side=tk.RIGHT, fill=tk.Y)
text_box.pack(side=tk.LEFT, fill=tk.Y)
scrollbar.config(command=text_box.yview)
text_box.config(yscrollcommand=scrollbar.set)
```
上述代码中,我们创建了一个垂直滚动条`scrollbar`,并将其放置在文本框的右侧。然后,我们使用`config()`方法将滚动条与文本框关联起来,从而实现滚动的功能。
#### 3.3 文本框的自动调整大小
有时,我们需要根据文本内容的多少来动态调整文本框的大小。我们可以使用`config()`方法设置文本框的高度和宽度,并使用`update_idletasks()`方法实时更新文本框的大小。
下面是一个例子:
```python
def resize_textbox(event):
text_box.config(height=int(text_box.index('end-1c').split('.')[0])+1)
root = tk.Tk()
text_box = tk.Text(root, width=30, hei
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏主要以深入浅出的方式介绍tkinter库的应用技巧和实用知识,包括从入门到高级应用的全面指南。通过“初识tkinter:入门指南”帮助读者快速上手,深入探讨“tkinter布局管理器的使用技巧”、“tkinter中常见的窗口控件详解”、“tkinter中的事件绑定与处理”等多个方面,涵盖了丰富的实例和技巧。同时,还介绍了“tkinter中的数据绑定与双向绑定”、“tkinter中的菜单设计与实现”等高级话题,包括实现拖放功能、数据库操作、网络编程与socket等实际应用技巧。此外,不仅涵盖了基础知识和常用控件的详细讲解,还介绍了如何实现登录认证与权限管理、多线程应用等高级技术。通过本专栏的学习,读者将能够轻松掌握tkinter库的各项功能,为日常应用提供强大的支持。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【从理论到实践:TRL校准件设计的10大步骤详解】:掌握实用技能,提升设计效率

# 摘要
本文详细介绍了TRL校准件的设计流程与实践应用。首先概述了TRL校准件的设计概念,并从理论基础、设计参数规格、材料选择等方面进行了深入探讨。接着,本文阐述了设计软件与仿真
CDP技术揭秘:从机制到实践,详解持续数据保护的7个步骤

# 摘要
连续数据保护(CDP)技术是一种高效的数据备份与恢复解决方案,其基本概念涉及实时捕捉数据变更并记录到一个连续的数据流中,为用户提供对数据的即
【俄罗斯方块游戏开发宝典】:一步到位实现自定义功能

# 摘要
本文全面探讨了俄罗斯方块游戏的开发过程,从基础理论、编程准备到游戏逻辑的实现,再到高级特性和用户体验优化,最后涵盖游戏发布与维护。详细介绍了游戏循环、图形渲染、编程语言选择、方块和游戏板设计、分数与等级系统,以及自定义功能、音效集成和游戏进度管理等关键内容。此外,文章还讨论了交
【物联网中的ADXL362应用深度剖析】:案例研究与实践指南
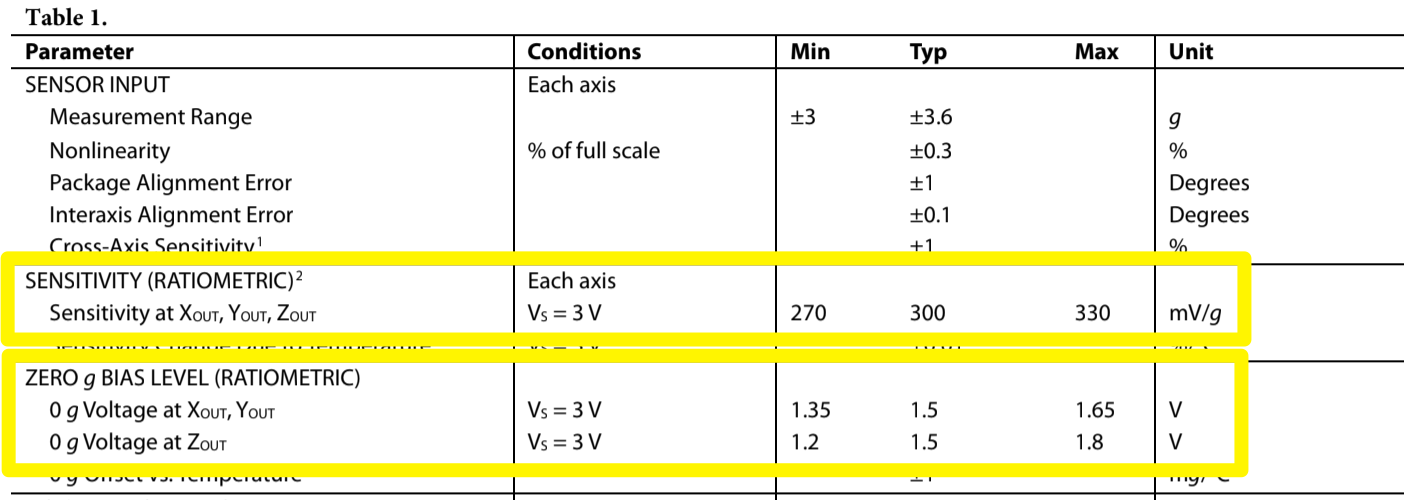
# 摘要
本文针对ADXL362传感器的技术特点及其在物联网领域中的应用进行了全面的探讨。首先概述了ADXL362的基本技术特性,随后详细介绍了其在物联网设备中的集成方式、初始化配置、数据采集与处理流程。通过多个应用案例,包括健康监测、智能农业和智能家居控制,文章展示了ADXL362传感器在实际项目中的应用情况和价值。此外,还探讨了高级数据分析技术和机器学习的应用,以及在物联网应用中面临的挑战和未来发展。本
HR2046技术手册深度剖析:4线触摸屏电路设计与优化

# 摘要
本文综述了4线触摸屏技术的基础知识、电路设计理论与实践、优化策略以及未来发展趋势。首先,介绍了4线触摸屏的工作原理和电路设计中影响性能的关键参数,接着探讨了电路设计软件和仿真工具在实际设计中的应用。然后,详细分析了核心电路设计步骤、硬件调试与测试
CISCO项目实战:构建响应速度极快的数据监控系统

# 摘要
随着信息技术的快速发展,数据监控系统已成为保证企业网络稳定运行的关键工具。本文首先对数据监控系统的需求进行了详细分析,并探讨了其设计基础。随后,深入研究了网络协议和数据采集技术,包括TCP/IP协议族及其应用,以及数据采集的方法和实践案例。第三章分析了数据处理和存储机制,涉及预处理技术、不同数据库的选择及分布式存储技术。第四章详细介绍了高效数据监控系统的架
【CAPL自动化测试艺术】:详解测试脚本编写与优化流程

# 摘要
本文全面介绍了CAPL自动化测试,从基础概念到高级应用再到最佳实践。首先,概述了CAPL自动化测试的基本原理和应用范围。随后,深入探讨了CAPL脚本语言的结构、数据类型、高级特性和调试技巧,为测试脚本编写提供了坚实的理论基础。第三章着重于实战技巧,包括如何设计和编写测试用例,管理测试数
【LDO设计必修课】:如何通过PSRR测试优化电源系统稳定性

# 摘要
线性稳压器(LDO)设计中,电源抑制比(PSRR)是衡量其抑制电源噪声性能的关键指标。本文首先介绍LDO设计基础与PSRR的概念,阐述P
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )