基于Socket的网络编程中的安全通信技术
发布时间: 2024-01-09 00:21:40 阅读量: 55 订阅数: 50 

基于socket的网络编程
# 1. Socket网络编程基础
## 1.1 Socket概述
Socket是一种网络通信的工具,它可以在不同的计算机之间建立起连接,实现数据的传输和交换。在网络编程中,Socket被用于实现客户端和服务器之间的通信。
## 1.2 TCP和UDP协议
TCP(传输控制协议)和UDP(用户数据报协议)是两种常用的网络传输协议。TCP提供可靠的数据传输,保证数据的顺序和完整性;而UDP则提供了一种无连接的传输方式,适用于实时性要求较高的应用。
## 1.3 Socket编程基本流程
Socket编程的基本流程如下:
1. 创建Socket对象:客户端和服务器端都需要创建一个Socket对象来进行通信。
2. 建立连接:客户端通过指定服务器的IP地址和端口号来连接服务器。
3. 发送和接收数据:客户端和服务器端通过Socket对象发送和接收数据。
4. 关闭连接:通信结束后,客户端和服务器端都需要关闭Socket连接。
下面是使用Python实现的简单Socket通信示例代码:
```python
import socket
# 创建客户端Socket对象
client_socket = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
# 连接服务器
server_address = ('localhost', 8888)
client_socket.connect(server_address)
# 发送数据
message = "Hello, Server!"
client_socket.send(message.encode())
# 接收数据
data = client_socket.recv(1024)
print("Received from server:", data.decode())
# 关闭连接
client_socket.close()
```
这段代码是一个简单的客户端程序,它首先创建一个Socket对象,然后通过`connect`方法连接到服务器。接着,客户端发送一条消息给服务器,并接收服务器返回的数据。最后,客户端关闭Socket连接。
以上就是Socket网络编程基础的内容。在接下来的章节中,我们将深入探讨网络通信中的安全问题,并介绍安全通信技术在Socket编程中的应用。
# 2. 网络通信中的安全问题
网络通信在互联网时代起到了至关重要的作用,然而,随之而来的安全问题也日益凸显。在网络通信过程中,存在着数据窃听、数据篡改以及身份认证与授权问题。本章将重点探讨这些安全问题,并围绕这些问题提供相应的解决方案。
### 2.1 网络通信的安全隐患
网络通信中存在着各种潜在的安全隐患,例如:
- 窃听:黑客可以通过截获数据包或监听网络流量的方式,获取传输的敏感信息,比如账号密码、个人隐私等。
- 篡改:黑客在数据传输过程中可以修改数据包的内容,例如篡改支付金额、篡改网页内容等,从而实施诈骗行为。
- 拒绝服务攻击(DDoS):黑客可以通过向目标服务器发送大量请求,使其无法正常提供服务,造成服务不可用。
- 伪造身份:黑客可以使用伪造的身份信息进行网络通信,冒充合法用户进行非法操作。
### 2.2 数据窃听和篡改
为了避免数据被窃听和篡改,我们可以采取以下措施:
- 使用加密算法对数据进行加密,确保只有授权的接收方能够解密。
- 使用数字签名对数据进行签名认证,确保数据的完整性和真实性。
- 建立安全通道进行数据传输,例如使用SSL/TLS协议。
### 2.3 身份认证与授权
网络通信中的身份认证与授权也是一项重要的安全问题。在确保某个通信实体的真实身份后,才能对其进行授权,使其能够访问相应的资源。
常见的身份认证和授权方式有:
- 密码认证:用户提供正确的用户名和密码进行登录验证。
- 令牌认证:用户使用令牌(Token)进行身份认证,令牌由服务器颁发并具有一定的时效性。
- 双因素认证:用户除了提供密码外,还需提供另外一种身份认证因素,如短信验证码、指纹识别等。
- 基于数字证书的身份认证:使用数字证书对用户进行身份验证,提供更高级别的安全性。
通过合理的身份认证和授权机制,可以有效防止未授权用户的非法访问和攻击行为。
在下一章中,我们将详细介绍加密技术在网络通信中的应用,以及安全Socket编程中数据加密的实现方式。
# 3. 加密技术在网络通信中的应用
网络通信中的安全问题对于当今互联网的发展至关重要。加密技术在保护通信数据的安全性方面起着至关重要的作用。本章将介绍加密技术在网络通信中的应用,包括对称加密与非对称加密算法、SSL/TLS协议以及数字证书的作用。
#### 3.1 对称加密与非对称加密算法
在网络通信中,常用的加密算法包括对称加密算法和非对称加密算法。
对称加密算法采用相同的密钥用于加密和解密数据。发送方使用密钥对数据进行加密后,接收方使用相同的密钥进行解密。常见的对称加密算法有DES、AES等。对称加密算法的特点是加密解密速度快,但密钥传输存在安全隐患。
非对称加密算法采用一对密钥,公钥和私钥。公钥用于加密数据,私钥用于解密数据。发送方使用接收方的公钥对数据进行加密,接收方使用自己的私钥进行解密。常见的非对称加密算法有RSA、ECC等。非对称加密算法的优点是密钥传输更加安全,但加密解密速度相对较慢。
#### 3.2 SSL/TLS协议
SSL (Secure Socket Layer)和TLS (Transport Laye

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
《Linux高级网络程序设计》是针对Linux系统下的高级网络编程而设计的专栏,旨在帮助读者深入理解和掌握Linux网络编程的各个方面。专栏内容涵盖了从基础入门到高级应用的全面讲解,包括Socket编程、TCP和UDP协议详解、IPv6协议应用、异步IO模型、流控制技术、数据包处理技术、多播和广播技术等多个方面的内容。此外,专栏还介绍了使用poll()实现高效的IO多路复用、Zero-Copy技术、负载均衡技术以及安全通信技术等高性能网络编程技术。通过本专栏,读者将全面掌握Linux下网络编程的核心知识和技术,为开发高性能、安全可靠的网络应用打下坚实的基础。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
NVIDIA ORIN NX性能基准测试:超越前代的关键技术突破
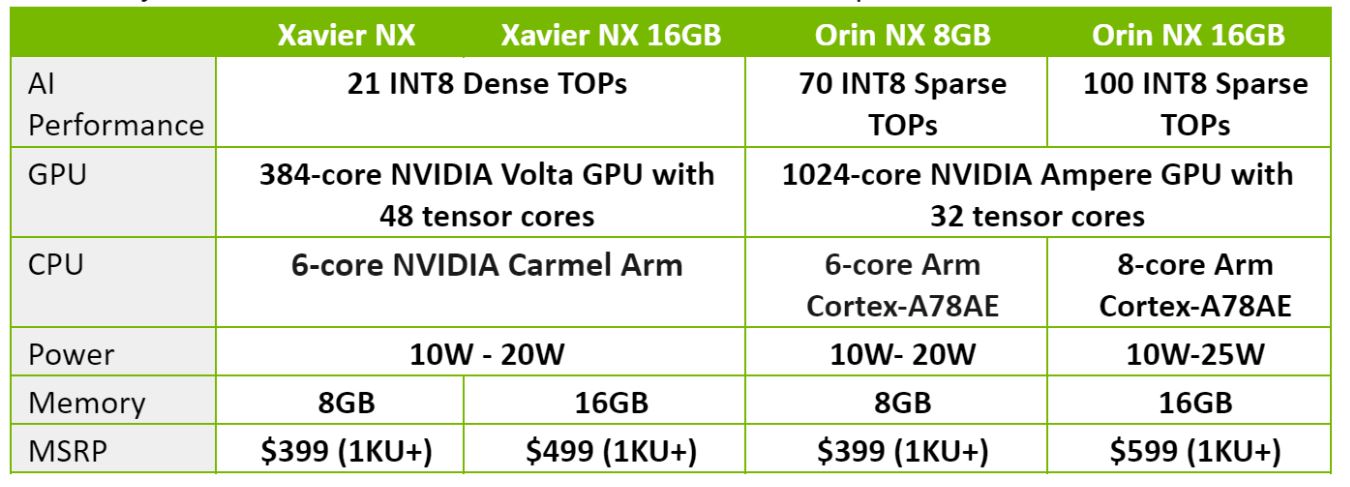
# 摘要
本文全面介绍了NVIDIA ORIN NX处理器的性能基准测试理论基础,包括性能测试的重要性、测试类型与指标,并对其硬件架构进行了深入分析,探讨了处理器核心、计算单元、内存及存储的性能特点。此外,文章还对深度学习加速器及软件栈优化如何影响AI计算性能进行了重点阐述。在实践方面,本文设计了多个实验,测试了NVI
图论期末考试必备:掌握核心概念与问题解答的6个步骤

# 摘要
图论作为数学的一个分支,广泛应用于计算机科学、网络分析、电路设计等领域。本文系统地介绍图论的基础概念、图的表示方法以及基本算法,为图论的进一步学习与研究打下坚实基础。在图论的定理与证明部分,重点阐述了最短路径、树与森林、网络流问题的经典定理和算法原理,包括Dijkstra和Floyd-Warshall算法的详细证明过程。通过分析图论在社交网络、电路网络和交通网络中的实际应用,本文探讨了图论问题解决策略和技巧,包括策略规划、数学建模与软件
【无线电波传播影响因素详解】:信号质量分析与优化指南
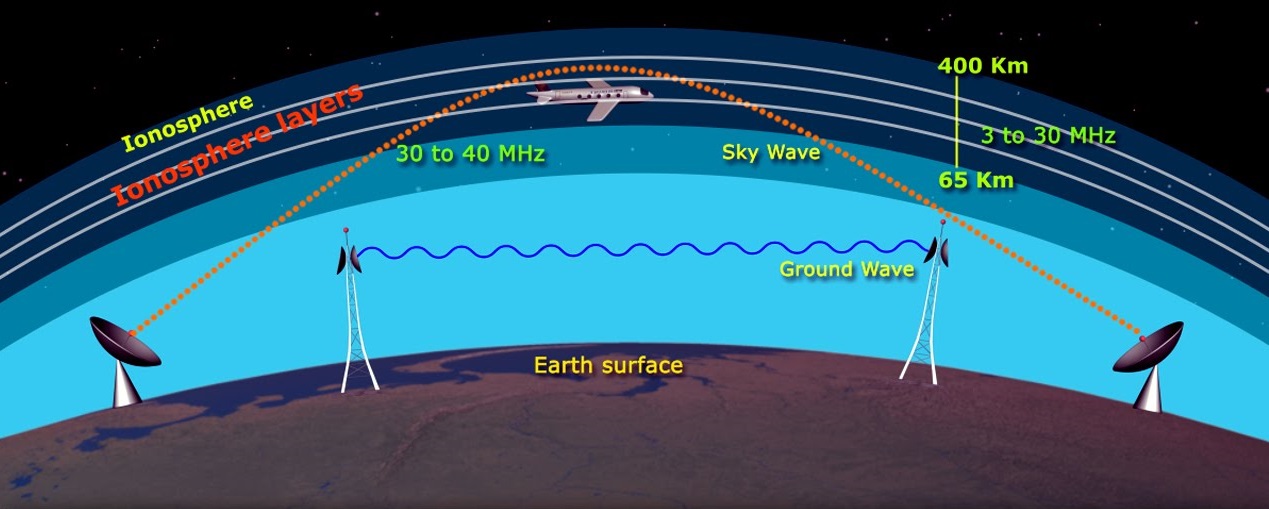
# 摘要
本文综合探讨了无线电波传播的基础理论、环境影响因素以及信号质量的评估和优化策略。首先,阐述了大气层、地形、建筑物、植被和天气条件对无线电波传播的影响。随后,分析了信号衰减、干扰识别和信号质量测量技术。进一步,提出了包括天线技术选择、传输系统调整和网络规划在内的优化策略。最后,通过城市、农村与偏远地区以及特殊环境下无线电波传播的实践案例分析,为实际应用提供了理论指导和解决方案。
# 关键字
无线电波传播;信号衰减;信号干扰;信号
FANUC SRVO-062报警:揭秘故障诊断的5大实战技巧

# 摘要
FANUC SRVO-062报警是工业自动化领域中伺服系统故障的常见表现,本文对该报警进行了全面的综述,分析了其成因和故障排除技巧。通过深入了解FANUC伺服系统架构和SRVO-062报警的理论基础,本文提供了详细的故障诊断流程,并通过伺服驱动器和电机的检测方法,以及参数设定和调整的具体操作
【单片微机接口技术速成】:快速掌握数据总线、地址总线与控制总线
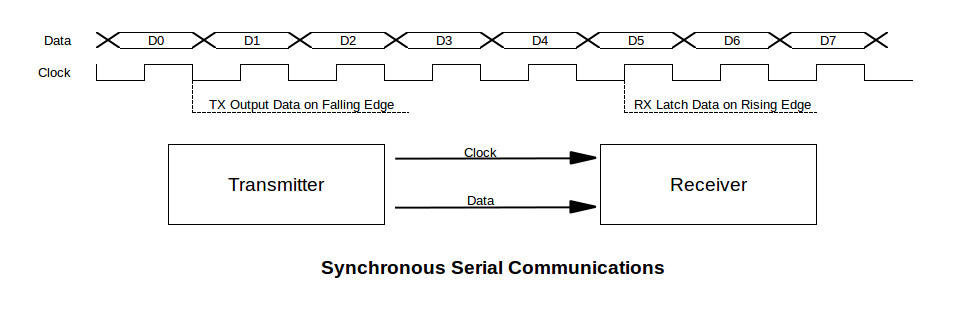
# 摘要
本文深入探讨了单片微机接口技术,重点分析了数据总线、地址总线和控制总线的基本概念、工作原理及其在单片机系统中的应用和优化策略。数据总线的同步与异步机制,以及其宽度对传输效率和系统性能的影响是本文研究的核心之一。地址总线的作用、原理及其高级应用,如地址映射和总线扩展,对提升寻址能力和系统扩展性具有重要意义。同时,控制总线的时序控制和故障处理也是确保系统稳定运行的关键技术。最后
【Java基础精进指南】:掌握这7个核心概念,让你成为Java开发高手

# 摘要
本文全面介绍了Java语言的开发环境搭建、核心概念、高级特性、并发编程、网络编程及数据库交互以及企业级应用框架。从基础的数据类型和面向对象编程,到集合框架和异常处理,再到并发编程和内存管理,本文详细阐述了Java语言的多方面知识。特别地,对于Java的高级特性如泛型和I/O流的使用,以及网络编程和数据库连接技
电能表ESAM芯片安全升级:掌握最新安全标准的必读指南
# 摘要
ESAM芯片作为电能表中重要的安全组件,对于确保电能计量的准确性和数据的安全性发挥着关键作用。本文首先概述了ESAM芯片及其在电能表中的应用,随后探讨了电能表安全标准的演变历史及其对ESAM芯片的影响。在此基础上,深入分析了ESAM芯片的工作原理和安全功能,包括硬件架构、软件特性以及加密技术的应用。接着,本文提供了一份关于ESAM芯片安全升级的实践指南,涵盖了从前期准备到升级实施以及后
快速傅里叶变换(FFT)实用指南:精通理论与MATLAB实现的10大技巧
# 摘要
快速傅里叶变换(FFT)是信号处理和数据分析的核心技术,它能够将时域信号高效地转换为频域信号,以进行频谱分析和滤波器设计等。本文首先回顾FFT的基础理论,并详细介绍了MATLAB环境下FFT的使用,包括参数解析及IFFT的应用。其次,深入探讨了多维FFT、离散余弦变换(DCT)以及窗函数在FFT中的高级应用和优化技巧。此外,本文通过不同领域的应用案例
【高速ADC设计必知】:噪声分析与解决方案的全面解读

# 摘要
高速模拟-数字转换器(ADC)是现代电子系统中的关键组件,其性能受到噪声的显著影响。本文系统地探讨了高速ADC中的噪声基础、噪声对性能的影响、噪声评估与测量技术以及降低噪声的实际解决方案。通过对噪声的分类、特性、传播机制以及噪声分析方法的研究,我们能
【Python3 Serial数据完整性保障】:实施高效校验和验证机制
# 摘要
本论文首先介绍了Serial数据通信的基础知识,随后详细探讨了Python3在Serial通信中的应用,包括Serial库的安装、配置和数据流的处理。本文进一步深入分析了数据完整性的理论基础、校验和验证机制以及常见问题。第四章重点介绍了使用Python3实现Serial数据校验的方法,涵盖了基本的校验和算法和高级校验技
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )