iptables规则配置详解
发布时间: 2024-03-08 22:18:51 阅读量: 14 订阅数: 13 
# 1. iptables简介
## 1.1 什么是iptables?
iptables是一个在Linux内核中实现的用于IPv4数据包过滤和网络地址转换的工具。它可以通过配置规则集来控制数据包的流动,从而实现网络安全和性能优化。
## 1.2 iptables的作用和意义
iptables的主要作用是在Linux系统中提供网络层的安全防护和流量控制,可以防止非法访问、网络攻击和提供网络服务的合理使用。通过合理配置iptables规则,可以增强系统的安全性和稳定性。
## 1.3 iptables和其他防火墙的区别
与传统的基于用户空间的防火墙工具相比,iptables是一个在内核空间操作的防火墙工具,因此在性能上具有明显的优势。此外,iptables具有丰富的匹配条件和动作选项,能够更精细地控制数据包的处理流程。
# 2. iptables基础配置
### 2.1 iptables的基本结构和语法
iptables是Linux上常用的防火墙工具,它通过在内核中设置规则来过滤、转发和修改数据包。其基本结构和语法如下:
```bash
# 添加规则
iptables -A INPUT -s 192.168.1.0/24 -p tcp --dport 22 -j ACCEPT
# 删除规则
iptables -D INPUT -s 192.168.1.0/24 -p tcp --dport 22 -j ACCEPT
# 查看规则
iptables -L
```
### 2.2 iptables链的概念和使用
iptables包含多个预定义的链,用于确定数据包处理的流程,主要包括INPUT、OUTPUT和FORWARD三条主要链。
```bash
# 查看链的规则
iptables -L INPUT
iptables -L OUTPUT
iptables -L FORWARD
```
### 2.3 常见的iptables命令及其参数介绍
常见的iptables命令包括:
- `-A`:添加规则
- `-D`:删除规则
- `-L`:列出规则
- `-P`:设置默认策略
- `-F`:清除规则
以上是iptables基础配置的相关内容,接下来我们将深入讨论iptables规则配置。
# 3. iptables规则配置
在iptables中,规则配置是非常重要的,通过合理的规则设置可以实现对网络流量的控制和管理。本章将详细介绍iptables规则配置的相关内容,包括如何创建和管理规则,规则的匹配条件和动作,以及针对源地址、目标地址和端口的规则配置。
#### 3.1 创建和管理iptables规则
要创建和管理iptables规则,首先需要了解iptables规则的结构和语法。iptables规则由若干部分组成,包括表(table)、链(chain)、匹配条件(matches)和动作(targets)。具体的规则语法为:
```shell
iptables -A <chain> -s <source> -d <destination> -p <protocol> --sport <source-port> --dport <destination-port> -j <target>
```
- `-A`:表示添加规则。
- `<chain>`:规则所属的链,如INPUT、OUTPUT、FORWARD等。
- `-s`:源地址。
- `-d`:目标地址。
- `-p`:协议,如TCP、UDP等。
- `--sport`:源端口。
- `--dport`:目标端口。
- `-j`:指定动作,如ACCEPT、DROP等。
要管理iptables规则,可以使用`iptables`命令配合不同的选项,如`-L`(列出规则)、`-D`(删除规则)、`-I`(插入规则)等。通过这些选项,可以对规则进行查看、修改和删除等操作。
#### 3.2 规则的匹配条件和动作
iptables规则的匹配条件可以非常灵活,可以根据源地址、目标地址、协议、端口等多种条件来匹配流量。当规则中的条件与数据包匹配时,就会执行设置的动作。
常见的匹配条件包括:
- `-s <source>`:指定源地址。
- `-d <destination>`:指定目标地址。
- `-p <protocol>`:指定协议。
- `--sport <source-port>`:指定源端口。
- `--dport <destination-port>`:指定目标端口。
常见的动作包括:
- `ACCEPT`:允许数据包通过。
- `DROP`:丢弃数据包。
- `REJECT`:拒绝数据包,并发送拒绝通知。
#### 3.3 源地址、目标地址和端口的规则配置
针对源地址、目标地址和端口的规则配置,在实际应用中非常常见。可以根据具体需求,设置不同的规则来实现网络流量的控制和过滤。
例如,要允许来自特定源地址的数据包通过防火墙,可以设置规则如下:
```shell
iptables -A INPUT -s 192.168.1.10 -j ACCEPT
```
这条规则允许源地址为192.168.1.10的数据包通过INPUT链。类似地,可以根据需要设置其他规则,实现更精细的网络控制。
通过合理的规则配置,可以有效管理网络流量,提高网络安全性和性能。
在接下来的章节中,我们将继续深入探讨iptables的高级配置和安全策略,希望本章内容对您理解iptables规则配置有所帮助。
# 4. iptables高级配置
在这一章中,我们将深入探讨iptables的高级配置,包括网络地址转换(NAT)的实现、高级匹配条件和匹配模块的使用,以及日志和统计信息记录。
#### 4.1 使用iptables实现网络地址转换(NAT)
网络地址转换(Network Address Translation,NAT)是一种常见的网络技术,用于将私有网络内部的IP地址转换为公共IP地址,从而实现内部网络对外部网络的访问。在iptables中,可以通过MASQUERADE和DNAT等机制实现NAT功能。
以下是一个使用iptables实现NAT的示例,假设有一个内部私有网络(192.168.1.0/24),需要将其访问外部网络时的IP地址进行转换:
```bash
# 开启IP转发
echo 1 > /proc/sys/net/ipv4/ip_forward
# 添加NAT转发规则
iptables -t nat -A POSTROUTING -s 192.168.1.0/24 -j MASQUERADE
```
上述示例中,通过修改内核参数开启IP转发,然后使用iptables添加了一个NAT转发规则,将内部网络数据包的源IP地址转换为对应的外部网络IP地址。这样,内部网络就可以顺利访问外部网络了。
#### 4.2 高级匹配条件和匹配模块的使用
除了基本的匹配条件外,iptables还提供了丰富的匹配模块,可以根据协议、数据包状态、时间等更加灵活地匹配和过滤数据包。常见的匹配模块包括`-m state`、`-m multiport`、`-m limit`等,通过这些模块可以对数据包进行更精细的过滤和处理。
以下是一个使用匹配模块的示例,假设需要限制SSH连接速率:
```bash
# 限制SSH连接速率
iptables -A INPUT -p tcp --dport 22 -m limit --limit 3/min -j ACCEPT
iptables -A INPUT -p tcp --dport 22 -j DROP
```
上述示例中,使用了`-m limit`匹配模块,限制了SSH连接的速率为每分钟3次,超过限制的连接将被丢弃。
#### 4.3 日志和统计信息记录
iptables还提供了日志功能,可以记录匹配规则的数据包信息,便于排查网络问题和分析流量情况。可以通过`-j LOG`目标和`--log-prefix`参数来实现日志记录。
以下是一个使用日志记录功能的示例,记录所有经过防火墙的HTTP流量:
```bash
# 记录HTTP流量日志
iptables -A INPUT -p tcp --dport 80 -j LOG --log-prefix "HTTP Traffic: "
```
上述示例中,当有数据包经过防火墙并匹配了HTTP流量规则时,将打印相应的日志信息,包括源IP、目标IP等,便于后续的分析和排查。
在本章中,我们介绍了iptables的高级配置,包括NAT的实现、匹配模块的使用和日志记录功能。这些高级配置可以满足更复杂的网络安全需求,提升了iptables的灵活性和功能性。
# 5. 安全策略和最佳实践
在本章中,我们将讨论iptables防火墙的安全策略和最佳实践。我们将介绍如何使用iptables配置来防止DDoS攻击,并提供一些iptables规则优化与性能调优的最佳实践。
#### 5.1 iptables防火墙安全策略
iptables可以通过配置不同的规则来实现多样化的安全策略。下面是一些常见的iptables安全策略:
- **拒绝所有流量**:配置默认策略为拒绝所有流量,只允许特定的流量通过。
- **限制特定IP的访问**:可以根据源IP地址来限制特定主机或网络的访问。
- **限制特定端口的访问**:只允许特定端口的流量通过,拒绝其他端口的访问。
- **限制特定协议的使用**:可以根据协议类型,如TCP、UDP等,来限制流量的通过。
#### 5.2 防止DDoS攻击的iptables配置
针对DDoS(分布式拒绝服务)攻击,可以使用iptables来进行防护。下面是一些针对DDoS攻击的iptables配置建议:
- **限制连接速率**:通过iptables的限速模块来限制连接速率,防止大量的连接请求导致系统资源耗尽。
- **使用连接状态追踪**:通过iptables的连接追踪功能,可以限制每个IP地址的并发连接数,防止单个IP发起过多连接请求。
- **使用ipset进行黑名单和白名单管理**:可以使用ipset模块来管理黑名单和白名单,对恶意IP进行阻止,对合法流量进行放行。
#### 5.3 iptables规则优化与性能调优
对于iptables的规则配置,优化和性能调优也是非常重要的。以下是一些iptables规则优化与性能调优的建议:
- **合并规则**:可以将多个通用的规则合并为一个,减少规则数量,提高效率。
- **使用规则模块**:选择合适的规则模块,如recent、limit等,可以提高规则匹配的效率。
- **定期清理过期规则**:定期清理不再使用的规则,避免规则数量过多导致性能下降。
以上是关于iptables防火墙安全策略和最佳实践的介绍,希望对你的网络安全配置提供一些帮助和指导。
# 6. 实例分析和案例应用
在本章中,我们将通过具体的实例场景来展示iptables规则配置的应用。每个示例都包含详细的代码、注释、代码总结以及结果说明,希望能够帮助读者更好地理解iptables的实际应用。
#### 6.1 常见网络场景下的iptables规则配置实例
##### 场景一:允许本地主机访问外部网络,但禁止外部网络访问本地主机
```python
# 允许本地主机访问外部网络
iptables -A OUTPUT -d 0.0.0.0/0 -j ACCEPT
# 禁止外部网络访问本地主机
iptables -A INPUT -s 0.0.0.0/0 -j DROP
```
**代码总结:** 在此场景下,我们通过添加OUTPUT链的规则允许本地主机访问外部网络,同时通过添加INPUT链的规则禁止外部网络访问本地主机。
**结果说明:** 本地主机可以正常访问外部网络,但外部网络无法直接访问本地主机。
##### 场景二:限制SSH访问次数
```python
# 限制每个IP地址在60秒内只能尝试连接SSH 3次
iptables -A INPUT -p tcp --dport 22 -m conntrack --ctstate NEW -m recent --update --seconds 60 --hitcount 3 -j DROP
iptables -A INPUT -p tcp --dport 22 -m conntrack --ctstate NEW -m recent --set
```
**代码总结:** 在该场景中,我们设置规则限制每个IP地址在60秒内只能尝试连接SSH 3次,超过次数则拒绝连接。
**结果说明:** 对SSH访问进行了次数限制,增强了系统的安全性。
#### 6.2 基于应用场景的iptables配置案例
##### 场景一:基于HTTP请求进行流量控制
```python
# 限制每个IP地址在60秒内只能建立10个HTTP连接
iptables -A INPUT -p tcp --dport 80 -m conntrack --ctstate NEW -m recent --update --seconds 60 --hitcount 10 -j DROP
iptables -A INPUT -p tcp --dport 80 -m conntrack --ctstate NEW -m recent --set
```
**代码总结:** 通过设置规则限制每个IP地址在60秒内只能建立10个HTTP连接,以控制HTTP流量。
**结果说明:** 实现了对HTTP请求流量的控制,避免了过多的连接导致服务器负载过高。
#### 6.3 iptables与其他安全解决方案的整合与应用
在这个案例中,我们将介绍如何将iptables与Fail2ban(一个基于日志文件实现自动封禁恶意IP的工具)相结合,提高系统的安全性。
```python
# 配置iptables规则以允许Fail2ban访问日志文件
iptables -A INPUT -p tcp --dport 12345 -s 192.168.1.100 -j ACCEPT
# 设置规则允许Fail2ban封禁IP访问
iptables -A INPUT -p tcp --dport 22 -s 0.0.0.0/0 -j DROP
```
**代码总结:** 通过配置iptables规则,将与Fail2ban集成,实现对恶意IP的自动封禁。
**结果说明:** 增强了系统安全性,有效防止了恶意IP对系统的攻击。
通过以上实例分析和案例应用,我们可以看到iptables在网络安全中的重要作用,以及如何根据不同场景的需求进行灵活配置和应用。
 最低0.47元/天 解锁专栏
最低0.47元/天 解锁专栏 送3个月
 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏目录

文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
送3个月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【实战演练】前沿技术应用:AutoML实战与应用

# 1. AutoML概述与原理**
AutoML(Automated Machine Learning),即自动化机器学习,是一种通过自动化机器学习生命周期
【实战演练】综合案例:数据科学项目中的高等数学应用

# 1. 数据科学项目中的高等数学基础**
高等数学在数据科学中扮演着至关重要的角色,为数据分析、建模和优化提供了坚实的理论基础。本节将概述数据科学
【实战演练】通过强化学习优化能源管理系统实战
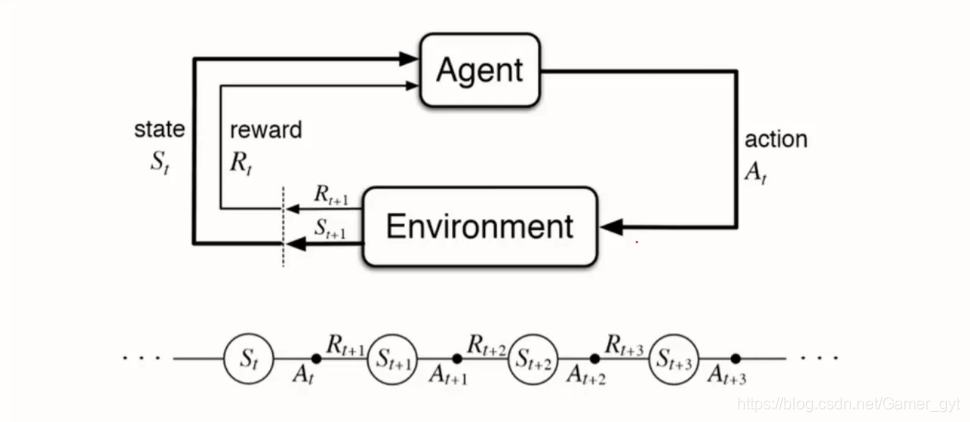
# 2.1 强化学习的基本原理
强化学习是一种机器学习方法,它允许智能体通过与环境的交互来学习最佳行为。在强化学习中,智能体通过执行动作与环境交互,并根据其行为的
【实战演练】虚拟宠物:开发一个虚拟宠物游戏,重点在于状态管理和交互设计。

# 2.1 虚拟宠物的状态模型
### 2.1.1 宠物的基本属性
虚拟宠物的状态由一系列基本属性决定,这些属性描述了宠物的当前状态,包括:
- **生命值 (HP)**:宠物的健康状况,当 HP 为 0 时,宠物死亡。
- **饥饿值 (Hunger)**:宠物的饥饿程度,当 Hunger 为 0 时,宠物会饿死。
- **口渴
【实战演练】python云数据库部署:从选择到实施
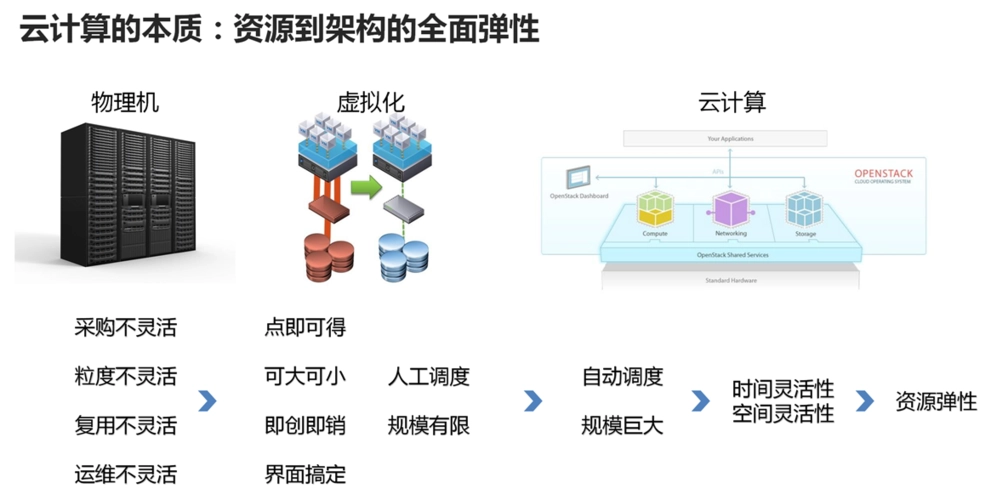
# 2.1 云数据库类型及优劣对比
**关系型数据库(RDBMS)**
* **优点:**
* 结构化数据存储,支持复杂查询和事务
* 广泛使用,成熟且稳定
* **缺点:**
* 扩展性受限,垂直扩展成本高
* 不适合处理非结构化或半结构化数据
**非关系型数据库(NoSQL)**
* **优点:**
* 可扩展性强,水平扩展成本低
【实战演练】使用Docker与Kubernetes进行容器化管理
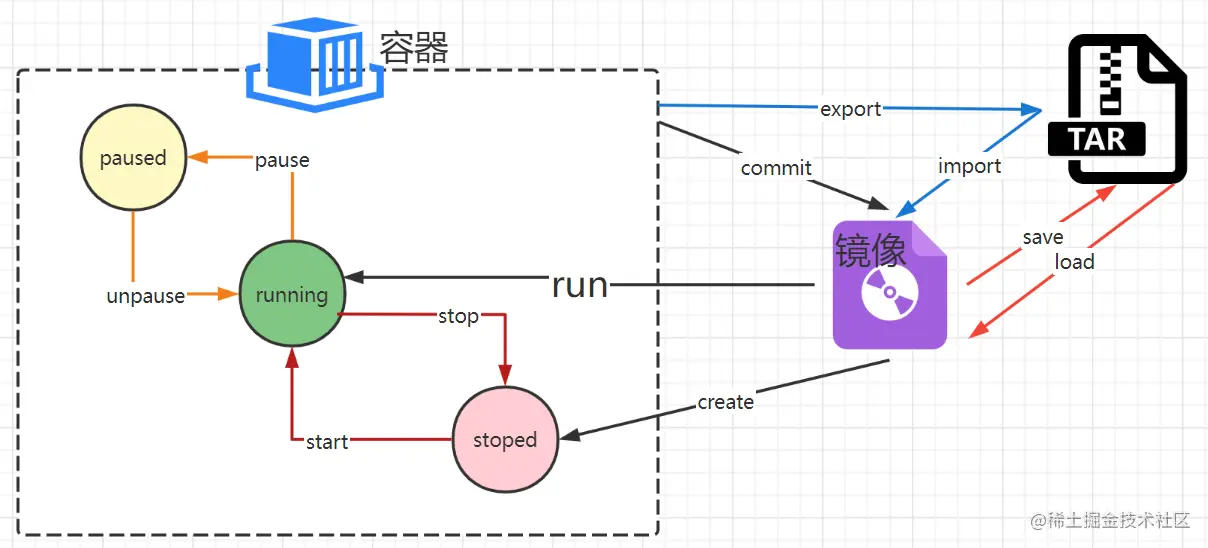
# 2.1 Docker容器的基本概念和架构
Docker容器是一种轻量级的虚拟化技术,它允许在隔离的环境中运行应用程序。与传统虚拟机不同,Docker容器共享主机内核,从而减少了资源开销并提高了性能。
Docker容器基于镜像构建。镜像是包含应用程序及
【实战演练】使用Python和Tweepy开发Twitter自动化机器人

# 1. Twitter自动化机器人概述**
Twitter自动化机器人是一种软件程序,可自动执行在Twitter平台上的任务,例如发布推文、回复提及和关注用户。它们被广泛用于营销、客户服务和研究等各种目的。
自动化机器人可以帮助企业和个人节省时间和精力,同时提高其Twitter活动的效率。它们还可以用于执行复杂的任务,例如分析推文情绪或
【实战演练】python远程工具包paramiko使用
# 1. Python远程工具包Paramiko简介**
Paramiko是一个用于Python的SSH2协议的库,它提供了对远程服务器的连接、命令执行和文件传输等功能。Paramiko可以广泛应用于自动化任务、系统管理和网络安全等领域。
# 2. Paramiko基础
### 2.1 Paramiko的安装和配置
**安装 Paramiko**
```python
pip install
【实战演练】深度学习在计算机视觉中的综合应用项目

# 1. 计算机视觉概述**
计算机视觉(CV)是人工智能(AI)的一个分支,它使计算机能够“看到”和理解图像和视频。CV 旨在赋予计算机人类视觉系统的能力,包括图像识别、对象检测、场景理解和视频分析。
CV 在广泛的应用中发挥着至关重要的作用,包括医疗诊断、自动驾驶、安防监控和工业自动化。它通过从视觉数据中提取有意义的信息,为计算机提供环境感知能力,从而实现这些应用。
# 2.1 卷积
【实战演练】时间序列预测项目:天气预测-数据预处理、LSTM构建、模型训练与评估

# 1. 时间序列预测概述**
时间序列预测是指根据历史数据预测未来值。它广泛应用于金融、天气、交通等领域,具有重要的实际意义。时间序列数据通常具有时序性、趋势性和季节性等特点,对其进行预测需要考虑这些特性。
# 2. 数据预处理
### 2.1 数据收集和清洗
#### 2.1.1 数据源介绍
时间序列预测模型的构建需要可靠且高质量的数据作为基础。数据源的选择至关重要,它将影响模型的准确性和可靠性。常见的时序数据源包括:
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
送3个月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )