AQWA参数调优专家课
发布时间: 2024-12-16 21:02:20 阅读量: 1 订阅数: 2 

Aqwa Theory Manual.pdf

参考资源链接:[ANSYS AQWA教程:三维海洋工程浮体波浪载荷计算](https://wenku.csdn.net/doc/3txgv2ra18?spm=1055.2635.3001.10343)
# 1. AQWA参数调优概述
在现代工程和科学研究中,AQWA作为一种强大的分析工具,其参数调优对于确保模拟和分析的精确性至关重要。本章将为读者提供一个关于AQWA参数调优的概览,包括调优的目的、重要性及其在相关领域中的应用。
## 参数调优的目的
参数调优,又称参数优化,其目的是为了在给定的模型或系统中找到一组最佳的参数设置,以使模型输出或系统性能达到最优。在AQWA的上下文中,参数调优可以提高模型预测的准确性,优化设计参数,以及改善工程结构的性能。
## 参数调优的重要性
对于任何工程设计和分析,正确的参数设置是确保可靠性和效率的关键。AQWA参数调优可以显著减少设计周期,优化资源配置,并最终为工程项目的成功实施提供保障。
## AQWA在工程中的应用
AQWA广泛应用于海洋工程领域,它能够帮助工程师分析波浪对海洋结构的影响。通过精确的参数调优,工程师可以更准确地预测波浪动力效应,设计更为可靠和经济的海上平台、船舶以及其他海洋结构。
在接下来的章节中,我们将深入了解AQWA软件的细节、参数调优的理论基础、实际操作步骤以及高级技巧和方法,并探讨这一领域的未来趋势和挑战。
# 2. AQWA参数调优基础
## 2.1 AQWA软件介绍
AQWA是一款强大的海洋工程软件,广泛应用于船舶设计、海洋结构物分析等领域。了解AQWA的基础知识是进行参数调优的前提。
### 2.1.1 AQWA的历史和发展
AQWA的历史可以追溯到20世纪70年代,最初由澳大利亚的海洋工程研究所开发,主要用于海洋结构物的设计和分析。随着时间的推移,AQWA逐步发展壮大,功能不断完善,成为海洋工程领域的标志性软件。
### 2.1.2 AQWA的主要功能和应用领域
AQWA的主要功能包括波浪载荷计算、结构动态响应分析等。它在船舶设计、海洋平台建设、海洋能源开发等领域都有广泛的应用。
## 2.2 AQWA参数调优的理论基础
参数调优是提高AQWA软件分析精度和效率的重要手段,其理论基础包括参数调优的理论模型和关键技术。
### 2.2.1 参数调优的理论模型
参数调优的理论模型主要包括线性模型和非线性模型。线性模型适用于参数之间相互独立的情况,而非线性模型则更适用于参数之间存在相互影响的情况。
### 2.2.2 参数调优的关键技术和方法
参数调优的关键技术主要包括梯度下降法、遗传算法等。梯度下降法适用于参数空间较小的情况,而遗传算法则适用于参数空间较大的情况。
## 2.2.2.1 梯度下降法
梯度下降法是通过计算函数在参数空间的梯度,然后沿着梯度的反方向进行迭代,以达到最小化目标函数的目的。它的基本步骤如下:
1. 初始化参数:选择一个合适的初始参数值。
2. 计算梯度:计算目标函数在当前参数下的梯度。
3. 更新参数:根据梯度计算结果更新参数。
4. 检查终止条件:如果满足终止条件,则停止迭代;否则,返回步骤2继续迭代。
梯度下降法的Python代码示例如下:
```python
def gradient_descent(x_start, df, n_iter=1000):
x = x_start
for i in range(n_iter):
grad = df(x)
x = x - 0.01 * grad
return x
```
在这段代码中,`x_start`是初始参数值,`df`是目标函数关于参数的梯度函数,`n_iter`是迭代次数。每次迭代都会根据梯度反方向更新参数,直到达到预定的迭代次数。
## 2.2.2.2 遗传算法
遗传算法是模拟自然选择和遗传机制的优化算法,适用于解决参数空间较大的优化问题。它的基本步骤如下:
1. 初始化种群:随机生成一组参数值作为初始种群。
2. 评估适应度:计算每个参数值的目标函数值,作为适应度。
3. 选择操作:根据适应度进行选择,适应度高的参数值被选中的概率更高。
4. 交叉和变异操作:对选中的参数值进行交叉和变异操作,生成新的参数值。
5. 检查终止条件:如果满足终止条件,则停止迭代;否则,返回步骤2继续迭代。
遗传算法的Python代码示例如下:
```python
import numpy as np
def genetic_algorithm(pop_size, gene_length, n_generations):
population = np.random.randint(0, 2, (pop_size, gene_length))
for i in range(n_generations):
fitness = np.array([df(individual) for individual in population])
selected = np.array([population[np.argmax(fitness)]])
population = np.concatenate((population, selected))
population = crossover(population)
population = mutate(population)
return population[np.argmax(fitness)]
def crossover(population):
# 实现交叉操作
pass
def mutate(population):
# 实现变异操作
pass
```
在这段代码中,`pop_size`是种群大小,`gene_length`是基因长度,`n_generations`是迭代次数。每次迭代都会根据适应度进行选择、交叉和变异操作,生成新的种群,直到达到预定的迭代次数。
以上就是AQWA参数调优的基础知识和基本步骤,掌握这些知识和技能,是进行AQWA参数调优的关键。
# 3. AQWA参数调优实践
在前文我们已经讨论了AQWA参数调优的基础理论和软件介绍。本章节将深入探讨如何实践AQWA参数调优,包括基本步骤和实例分析。通过这一章节的阅读,读者将能够掌握如何在实际项目中运用AQWA软件进行参数调优,并对调优结果进行解读与优化。
## 3.1 参数调优的基本步骤
### 3.1.1 参数调优的准备和设置
在开始进行AQWA参数调优之前,必须对模型进行适当的准备和设置。这包括定义好优化目标、确定优化参数的范围以及准备必要的输入文件。
**优化目标**:
优化目标可以是减少计算时间、提高结果的精确性、达到特定的性能指标等。在AQWA中,通常需要明确是进行波浪载荷的计算、结构响应分析还是稳定性分析。
**参数范围的确定**:
确定参数的调整范围是参数调优过程中的关键步骤之一。参数的选择将直接影响模型的输出。例如,如果优化目标是减少波浪载荷,那么可以调整与波浪相互作用的相关参数,如船舶吃水深度、航速等。
**输入文件的准备**:
AQWA使用特定格式的输入文件,需要按照软件的要求编写或修改。输入文件中包含了模型的几何信息、物理属性、边界条件等关键信息。在进行参数调优前,这些文件需准备完善。
### 3.1.2 参数调优的执行和评估
在准备好所有必要的准备工作后,接下来就是执行参数调优。这一过程包括选择合适的优化算法、启动调优流程,并对结果进行评估。
**选择优化算法**:
AQWA提供多种优化算法,包括梯度法、遗传算法等。选择合适的算法对于获得有效结果至关重要。算法的选择依赖于问题的性质、参数的特性以及优化目标。
**启动调优流程**:
调优流程的启动可以通过AQWA软件界面或脚本文件实现。执行调优流程时,软件会根据设定的参数范围和优化算法自动进行多次迭代计算,直到满足优化目标或达到迭代次数上限。
**结果评估**:
完成调优流程后,需要对结果进行评估,以确定是否满足优化目标。评估过程中需要查看输出文件中的关键性能指标,并将它们与目标值进行比较。
## 3.2 参数调优的实例分析
### 3.2.1 案例研究:参数调优的实际应用
为了更深入地理解参数调优的过程,我们来分析一个案例研究。
**案例背景**:
假定一个海洋工程公司需要使用AQWA来分析一艘新设计的海洋平台在特定海况下的波浪载荷。为确保结构的安全性,公司希望优化平台的形状设计以减少载荷。
**调优流程**:
首先,确定优化目标为最小化平台在特定波浪条件下的最大受力。接着,选择影响载荷的关键参数,如平台的浮筒高度、间距等,作为优化变量。然后,设置这些参数的调整范围,比如浮筒高度在10m到15m之间变化。最后,使用AQWA内置的遗传算法进行参数调优,并对结果进行分析。
**结果分析**:
通过多轮迭代计算后,优化结果表明浮筒的高度设置为13.5m,间距为12m时,平台受到的波浪载荷达到最小。此时的载荷比初始设计减少了20%,从而验证了参数调优的有效性。
### 3.2.2 参数调优结果的解读和优化建议
在完成参数调优后,解读结果并提出优化建议是至关重要的。以下是解读过程的几个关键点和建议:
**结果解读**:
对于上述案例,结果解读主要关注于各参数对目标的影响程度,以及如何通过调整这些参数来达到优化目标。在案例中,浮筒的高度和间距对波浪载荷的影响最大,因此这两个参数被选作优化变量。
**优化建议**:
根据结果,建议在设计新的海洋平台时,重点关注结构的浮筒高度和间距。此外,还建议在实际应用中考虑多参数组合优化,以进一步改善结构性能。对于进一步的优化,可以考虑引入更复杂的参数设置,或者使用更高级的优化算法,比如基于代理模型的优化方法,来进一步提高优化效果。
在下一章节中,我们将深入探讨AQWA参数调优技巧和方法,包括多参数组合优化和自动化参数调优工具的使用,以及如何选择和应用不同的参数调优方法。
# 4. AQWA参数调优技巧和方法
## 4.1 参数调优的高级技巧
### 4.1.1 多参数组合优化
在进行复杂的模型调优时,单个参数的调整往往难以达到最优的效果。多参数组合优化是一种更为高效的方法,它涉及到同时调整多个参数以观察整体性能的变化。这种方法可以显著提高模型的性能,但它也引入了更高的计算复杂度。
为了实现多参数组合优化,常用的策略是使用拉丁超立方抽样(Latin Hypercube Sampling, LHS)或者全因子设计(Full Factorial Design)。这些方法能够确保在参数空间中均匀地抽取样本点,从而使调优过程更为高效和全面。
**表格展示多参数组合优化方法对比:**
| 参数优化方法 | 特点 | 适用场景 |
| ------------ | ---- | -------- |
| LHS | 均匀分布的样本点,减少计算量 | 参数空间较大时 |
| 全因子设计 | 精确探索参数的所有可能组合 | 参数数量较少时 |
| 随机搜索 | 快速,简单,适用于高维问题 | 初步筛选参数组合 |
| 网格搜索 | 结果精确,适用于参数数量较少 | 需要验证参数影响 |
```python
import numpy as np
from sklearn.model_selection import train_test_split
# 示例代码:使用拉丁超立方抽样进行多参数组合优化
def latin_hypercube_sampling(n_params, samples):
# 生成等概率的累积分布值
cdf = np.linspace(0, 1, samples)
# 生成均匀分布值,并进行随机打乱
random_array = np.random.permutation(cdf)
# 通过差分获取间隔一致的样本点
lhs_samples = np.linspace(0, 1, samples)
lhs_samples[1:-1] = np.diff(random_array)
lhs_samples = np.sort(lhs_samples)
return lhs_samples
# 假设我们有两个参数进行优化
samples = 10
lhs_params = latin_hypercube_sampling(2, samples)
X_train, X_test, y_train, y_test = train_test_split(lhs_params.T, labels, test_size=0.2)
# 在此处继续模型训练和评估过程
```
在上述代码中,我们定义了一个简单的函数来执行拉丁超立方抽样,然后使用这个抽样方法生成用于模型训练的参数组合。通过这种方式,可以在保持样本均匀性的同时,探索参数组合对模型性能的影响。
### 4.1.2 自动化参数调优工具的使用
自动化参数调优工具可以极大地提高参数调优的效率和可靠性。这些工具通常包括了预设的算法来自动调整参数,用户只需要定义搜索空间和评价标准即可。
一些流行的自动化参数调优工具有:Hyperopt、Optuna、Optunity等。这些工具支持多种搜索策略,如贝叶斯优化、遗传算法、粒子群优化等,并能够与多个机器学习框架集成。
以Hyperopt为例,其核心是基于贝叶斯优化的算法,通过建立一个概率模型来指导参数搜索,从而在搜索空间中智能地寻找最优参数。
```python
from hyperopt import fmin, tpe, hp, STATUS_OK, Trials
from sklearn.ensemble import RandomForestClassifier
from sklearn.datasets import make_classification
from sklearn.model_selection import cross_val_score
# 构建一个随机森林分类器
clf = RandomForestClassifier()
# 定义一个优化的目标函数
def objective(params):
clf.set_params(**params)
cross_val_scores = cross_val_score(clf, X, y, cv=5, scoring='accuracy')
return {'loss': -np.mean(cross_val_scores), 'status': STATUS_OK}
# 定义参数空间
space = {
'n_estimators': hp.choice('n_estimators', [100, 200, 300]),
'max_depth': hp.choice('max_depth', [5, 10, 15, 20]),
}
# 使用tpe算法寻找最优参数
trials = Trials()
best = fmin(fn=objective, space=space, algo=tpe.suggest, max_evals=100, trials=trials)
print(best)
```
在上面的代码示例中,我们定义了一个目标函数,该函数使用了随机森林分类器,并通过交叉验证来评估参数。我们设置了一个参数空间,包括决策树的数量和深度。然后使用Hyperopt库中的 `fmin` 函数和tpe算法来搜索最优参数。
## 4.2 参数调优方法的选择和应用
### 4.2.1 不同优化方法的比较和选择
在参数调优中,面对多种多样的优化方法,选择合适的方法对于提高模型性能至关重要。不同的优化方法各有优劣,如遗传算法适合解决复杂的非线性问题,贝叶斯优化在求解连续空间的全局最优解方面表现突出,网格搜索和随机搜索则适用于参数空间较小或计算资源有限的情况。
在选择优化方法时,需要综合考虑问题的特性、参数的类型(离散或连续)、模型的复杂度、计算资源以及优化的效率等因素。
**不同参数优化方法的特点对比:**
| 优化方法 | 优点 | 缺点 | 适用范围 |
| -------- | ---- | ---- | -------- |
| 网格搜索 | 实现简单,易于理解 | 计算代价高,不适用于高维参数空间 | 参数空间较小 |
| 随机搜索 | 计算效率高于网格搜索 | 随机性较强,可能遗漏最优解 | 参数空间适中 |
| 贝叶斯优化 | 高效率,适用于高维空间 | 需要预设概率模型,对先验知识要求较高 | 高维参数空间,计算资源受限 |
| 遗传算法 | 强大的全局搜索能力,适用于复杂问题 | 收敛速度可能较慢,参数调整较为复杂 | 复杂非线性问题 |
### 4.2.2 参数调优方法在特定领域的应用
参数调优的方法并不是万能的,不同的应用领域对参数调优的技巧和方法有着不同的需求。例如,在金融预测模型中,可能会更倾向于使用具有强大全局搜索能力的优化算法,因为这类模型往往需要处理高度非线性和动态变化的数据。
在机器学习领域,参数调优通常关注于最大化模型的准确率、精确度、召回率等指标。在深度学习中,参数调优尤其关键,因为神经网络的训练高度依赖于参数的初始化和超参数的选择。
**表格展示参数调优方法在不同领域的应用情况:**
| 领域 | 优化方法选择 | 特定考量 |
| ---- | ------------ | -------- |
| 金融预测 | 遗传算法、贝叶斯优化 | 处理非线性和动态数据 |
| 机器学习 | 随机搜索、贝叶斯优化 | 确保模型的泛化能力 |
| 深度学习 | 自适应学习率算法、贝叶斯优化 | 超参数空间巨大,需要高效搜索算法 |
在深度学习中,使用贝叶斯优化对学习率、批次大小等超参数进行优化是一个非常有效的策略,它可以帮助我们避免陷入局部最优,同时快速地找到较为优秀的参数设置。
在实践中,选择合适的参数调优方法,需要对所面临的问题有深入的了解。研究者和从业者应根据问题的具体情况,选择最合适的参数调优方法,以达到最优的模型性能。
通过本章节的介绍,我们可以了解到参数调优中使用的高级技巧和方法的选择策略。下一章节将继续探索AQWA参数调优的未来趋势和面临的挑战。
# 5. AQWA参数调优的未来趋势和挑战
## 5.1 参数调优技术的发展趋势
### 5.1.1 人工智能在参数调优中的应用
随着人工智能技术的不断进步,其在AQWA参数调优中的应用愈发广泛。机器学习和深度学习的算法能够处理复杂的数据,并能根据历史优化经验自动调整参数,这为AQWA的参数调优提供了新的可能性。例如,使用遗传算法和神经网络进行自适应优化,可以提高参数调优的效率和精度。
```python
# 示例代码:使用遗传算法优化AQWA参数
import DEAP
# 假设已有AQWA参数的遗传算法框架
creator.create("FitnessMax", Fitness, weights=(1.0,))
creator.create("Individual", list, fitness=creator.FitnessMax)
toolbox = base.Toolbox()
toolbox.register("attr_float", random.uniform, 0, 1)
toolbox.register("individual", tools.initRepeat, creator.Individual, toolbox.attr_float, n=10)
toolbox.register("population", tools.initRepeat, list, toolbox.individual)
def evalFunc(individual):
# AQWA参数优化评估函数
# 此处用伪代码表示,实际应调用AQWA进行分析
score = -1 * sum(individual) # 例子中的评估函数
return score,
toolbox.register("evaluate", evalFunc)
toolbox.register("mate", tools.cxBlend, alpha=0.1)
toolbox.register("mutate", tools.mutGaussian, mu=0, sigma=1, indpb=0.2)
toolbox.register("select", tools.selNSGA2)
# 遗传算法参数
NGEN = 100
MU = 100
LAMBDA = 200
# 创建初始种群
population = toolbox.population(n=MU)
# 开始进化
NGEN = 100
for gen in range(NGEN):
offspring = algorithms.varAnd(population, toolbox, lambda_=1, mu=MU, lambda_=LAMBDA)
fits = toolbox.map(toolbox.evaluate, offspring)
for fit, ind in zip(fits, offspring):
ind.fitness.values = fit
population = toolbox.select(offspring, k=mu)
```
### 5.1.2 参数调优的未来发展方向
未来参数调优的发展方向将更加趋向于智能化、自动化。研究者们将致力于开发更为高效的算法,同时也会更注重于参数调优的解释性和透明度。这将有助于用户更好地理解参数调优的过程和结果,提升信任度和接受度。
## 5.2 面对的挑战和解决策略
### 5.2.1 参数调优过程中的常见问题
在AQWA参数调优的过程中,可能会遇到多种问题,比如局部最优问题、计算资源限制、参数间相互依赖导致的复杂性增加等。这些问题的存在会降低调优效率,甚至导致调优失败。
### 5.2.2 解决这些问题的策略和方法
为了解决这些问题,可以采取一些策略,例如采用多目标优化算法来避免局部最优,利用云计算资源提高计算能力,或者采用参数空间划分技术来降低复杂性。另外,建立参数间关系的可视化工具,有助于分析和调整参数间的依赖关系。
| 挑战类型 | 解决策略 |
|----------------|----------------------------------------|
| 局部最优 | 多目标优化算法,如Pareto优化 |
| 计算资源限制 | 云计算,分布式计算 |
| 参数依赖复杂性 | 参数空间划分技术,如贝叶斯优化方法 |
| 参数不透明性 | 可视化分析工具,如参数敏感性分析图表 |
通过上述策略和方法的应用,可以有效提升AQWA参数调优的效率和准确性,为工程设计和优化提供更为坚实的理论与实践基础。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【编程更亲切】:GoLand设置中文全攻略
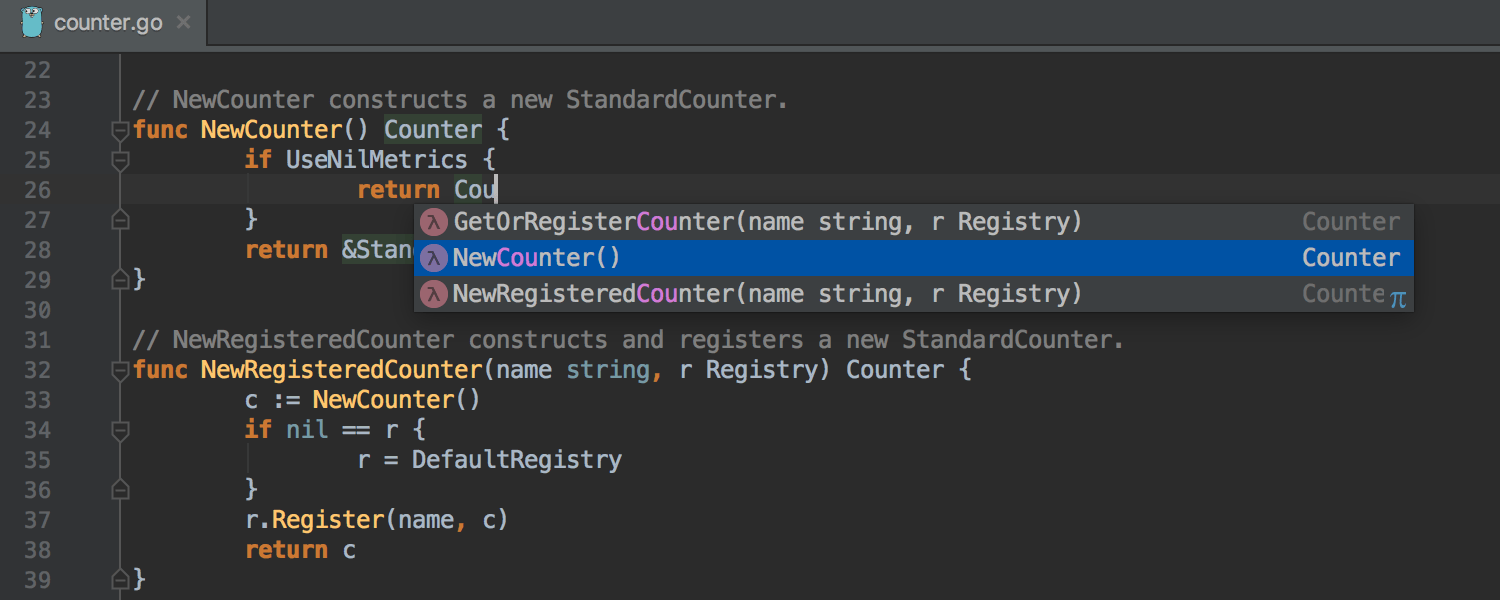
参考资源链接:[GoLand中文设置教程:在线与离线安装步骤](https://wenku.csdn.net/doc/645105aefcc5391368ff158e?spm=1055.2635.3001.10343)
# 1. Goland介绍与安装
## 1.1 Goland概述
GoLand是由JetBrains公司开发的专为Go语言编写的集成开发环境(IDE)。它提供了智能代码补全、代码分析
【电力系统故障模拟】:PowerWorld Simulator中电网故障与恢复的实战案例
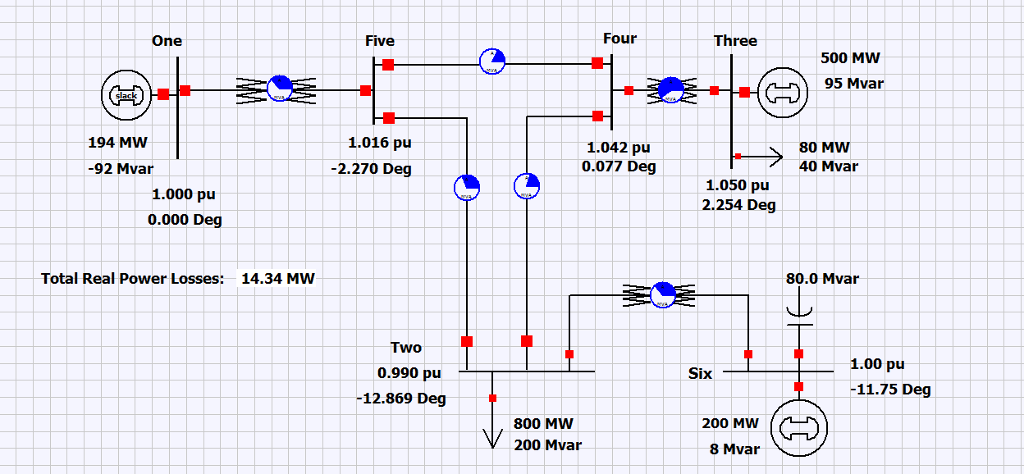
参考资源链接:[PowerWorld Simulator中文手册:电力系统建模与分析教程](https://wenku.csdn.net/doc/6401abe7cce7214c316e9ec1?spm=1055.2635.3001.10343)
# 1. 电力系统故障模拟概述
电力系统故障模拟是电力工程领域一项重要的技术,它能够帮
【立即掌握】:12个实用技巧,精通ISO 22900-2-2017与D-PDU-API的完美融合

参考资源链接:[ISO 22900-2 D-PDU API详解:MVCI协议与车辆诊断数据传输](https://wenku.csdn.net/doc/4svgegqzsz?spm=1055.2635.3001.10343)
# 1. ISO 22900-2-2017
技术革新者速成:掌握Ambarella H22芯片的编程与功耗控制秘诀

参考资源链接:[Ambarella H22芯片规格与特性:低功耗4K视频处理与无人机应用](https://wenku.csdn.net/doc/6401abf8cce7214c316ea27b?spm=1055.2635.3001.10343)
# 1. Ambarella H22芯片概述及架构解析
## 1.1
【ADS差分滤波器原理与实践】:实现理论到实际的无缝转换
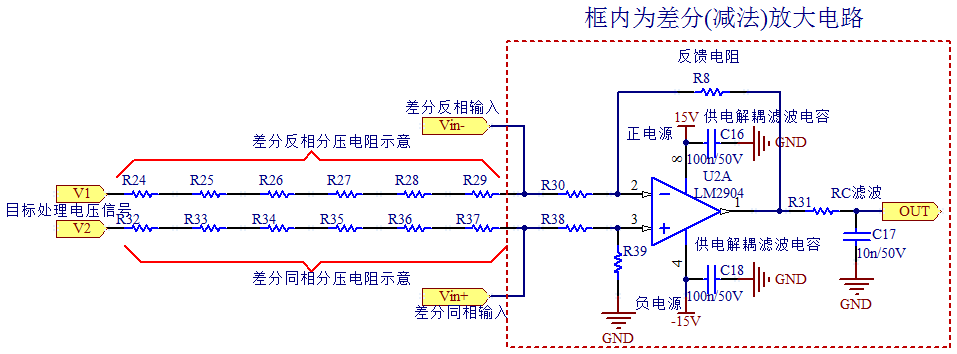
参考资源链接:[ads 差分滤波器设计及阻抗匹配](https://wenku.csdn.net/doc/6412b59abe7fbd1778d43bd8?spm=1055.2635.3001.10343)
# 1. ADS差分滤波器的基础理论
在通信系统中,差分滤波器扮演着至关重要的角色。差分滤波器能够有效地处理差分信号,保证信号在传输过程中的稳定性和抗干扰能力。本章将重点介绍ADS差分滤波器的基础理论,为后续的设计、
【CDO进阶应用】:CDO高级命令解析与实战演练

参考资源链接:[CDO气候数据操作命令详解:文件信息、合并、裁剪与插值](https://wenku.csdn.net/doc/1dcuhj0aue?spm=1055.2635.3001.10343)
# 1. CDO的基本概念和功能介绍
CDO(Climate Data Operators)是一个集合了多种命令行工具的集合,这些工具被设计用于处理气候数据。虽然它最初是为
【高性能计算中的GPGPU应用】:实战案例深度解析

参考资源链接:[GPGPU编程模型与架构解析:CUDA、OpenCL及应用](https://wenku.csdn.net/doc/5pe6wpvw55?spm=1055.2635.3001.10343)
# 1. GPGPU技术概述
## 1.1 GPGPU的定义和重要性
GPGPU,即通用计算图形处理器,是一种利用图形处理单
从LibreOffice 6到7.1.8升级全解析:技术细节与实用指南
参考资源链接:[ARM架构下libreoffice 7.1.8预编译安装包](https://wenku.csdn.net/doc/2fg8nrvwtt?spm=1055.2635.3001.10343)
# 1. LibreOffice升级概览
LibreOffice作为一款流行的开源办公套件,持续不断地进行版本迭代以提升用户体验和性能。在本章节,我们将概述LibreOffice的升级流程,
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录

文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )