【CGo错误处理详解】:将C错误优雅传递到Go世界的指南
发布时间: 2024-10-21 09:10:26 阅读量: 42 订阅数: 24 

golang-cross:使用CGO的golang交叉编译器
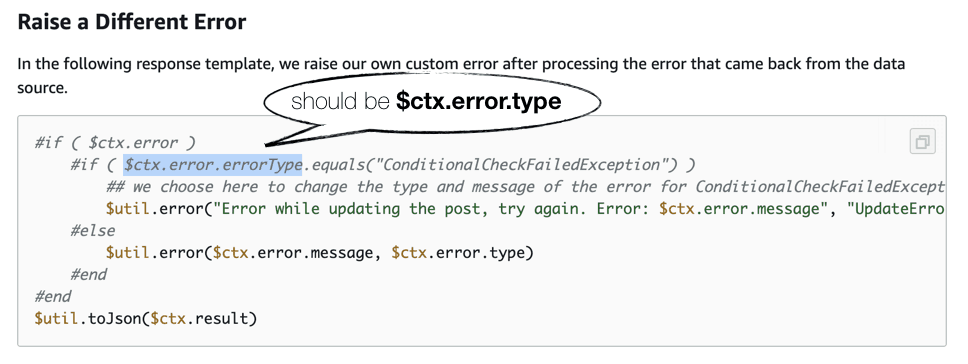
# 1. CGo错误处理基础
错误处理是编写健壮软件不可或缺的一环。在CGo中,它结合了C语言和Go语言的错误处理机制,提供了独特的挑战和机遇。本章将为您介绍CGo错误处理的基础知识,为后续章节中深入探讨C语言和Go语言的错误处理策略打下坚实的基础。我们将从CGo的基本概念开始,理解如何在CGo中识别和传递错误,并逐步深入到如何优化错误处理流程,以提升程序的稳定性和用户体验。通过本章的学习,您将掌握在CGo环境中有效管理和处理错误的关键知识和技巧。
# 2. C语言中的错误处理机制
### 2.1 C语言错误处理基本概念
#### 2.1.1 错误码与errno
在C语言中,错误处理通常是通过错误码(errno)来实现的,这是一个整数类型的变量,用于表示函数调用失败的原因。每当一个标准C库函数执行失败时,它会设置errno的值来指明错误的性质。在Linux环境中,错误码通常与`<errno.h>`头文件中定义的常量相对应。
例如,当尝试打开一个不存在的文件时,`fopen`函数将返回NULL,并设置errno为`ENOENT`(没有那个文件或目录)。以下是使用errno的一个简单示例:
```c
#include <stdio.h>
#include <errno.h>
#include <string.h>
int main() {
FILE *fp = fopen("nonexistentfile.txt", "r");
if (fp == NULL) {
printf("Error: %s\n", strerror(errno));
} else {
fclose(fp);
}
return 0;
}
```
在上述代码中,如果文件不存在,`fopen`会失败,`errno`将被设置为`ENOENT`,随后`strerror`函数根据`errno`的值返回一个描述错误的字符串。
#### 2.1.2 perror和strerror的使用
`perror`和`strerror`是两个常用于错误处理的C标准库函数,它们提供了一种打印错误信息到标准错误流的方式。
- `perror`函数接受一个字符串参数,并在该字符串后打印出当前的错误信息和一个换行符。例如:
```c
#include <stdio.h>
#include <errno.h>
int main() {
FILE *fp = fopen("nonexistentfile.txt", "r");
if (fp == NULL) {
perror("Error opening file");
} else {
fclose(fp);
}
return 0;
}
```
- `strerror`函数接受一个错误码作为参数,并返回一个描述该错误码的字符串。例如:
```c
#include <stdio.h>
#include <string.h>
#include <errno.h>
int main() {
FILE *fp = fopen("nonexistentfile.txt", "r");
if (fp == NULL) {
printf("Error: %s\n", strerror(errno));
} else {
fclose(fp);
}
return 0;
}
```
### 2.2 C语言中的异常处理
C语言本身不提供类似于Java或C++中的异常处理机制,但可以通过`setjmp.h`头文件中的`setjmp`和`longjmp`函数来实现类似的功能。
#### 2.2.1 setjmp和longjmp的机制
`setjmp`函数用于记录当前调用环境,以便将来可以通过`longjmp`恢复到该环境。`longjmp`则可以跳转回`setjmp`设置的位置,从而实现非本地跳转。
```c
#include <stdio.h>
#include <setjmp.h>
jmp_buf jump_buffer;
void second_function() {
longjmp(jump_buffer, 1); // 非本地跳转回 main 函数
}
int main() {
if (setjmp(jump_buffer)) {
printf("Back in main\n");
} else {
second_function();
}
return 0;
}
```
在上面的例子中,`setjmp`首先被调用并记录当前的环境。然后程序调用`second_function`,在该函数中,`longjmp`被用来跳转回`main`函数中`setjmp`之后的点,并且`setjmp`返回1,表示是通过`longjmp`回来的。
#### 2.2.2 抛出与捕获异常
尽管C语言没有内建异常处理机制,`setjmp`和`longjmp`在某种程度上可以模拟它。但这种机制并不推荐用于日常的错误处理,因为它可能导致程序状态不清晰,并使得代码难以维护和理解。
### 2.3 C标准库中的错误处理函数
#### 2.3.1 常见的库函数错误处理方式
C标准库中的大多数函数在遇到错误时会返回特定的值,如前面提到的`fopen`返回NULL。程序员需要检查这些返回值,以决定如何处理错误。例如,`strtol`函数将字符串转换为长整数,如果转换失败,它返回0并设置`errno`。
```c
#include <stdlib.h>
#include <errno.h>
int main() {
char *ptr;
char *str = "12345";
long int num = strtol(str, &ptr, 10);
if (ptr == str) {
// 转换失败,ptr没有前进
printf("No digits were found\n");
} else if (*ptr != '\0') {
// 转换成功,但字符串中还有未处理的字符
printf("Stopped conversion at %s\n", ptr);
} else {
// 转换成功,字符串完全被解析
printf("Number = %li\n", num);
}
return 0;
}
```
#### 2.3.2 错误处理的最佳实践
良好的错误处理实践包括:
- **检查所有可能失败的函数调用**并适当处理错误。
- 使用`assert`宏进行调试时的条件检查,确保程序在运行时满足特定条件。
- 使用`errno`进行错误分类,当多个函数可能返回相同的错误码时,通过检查`errno`来确定具体错误类型。
- 使用`perror`和`strerror`辅助输出清晰的错误信息,便于问题追踪和调试。
遵循这些实践有助于使程序健壮且易于维护。
# 3. Go语言中的错误处理机制
## 3.1 Go错误接口详解
### 3.1.1 error接口的基本用法
Go语言中错误处理的核心是error接口,它是Go语言中用于表示错误的唯一类型。它定义如下:
```go
type error interface {
Error() string
}
```
任何实现Error()方法的类型都可以作为error使用。在Go中,大多数函数和方法在遇到错误时会返回一个error类型的值。
使用error接口的基本用法通常如下:
```go
func someFunction() error {
// ... 代码逻辑
if 错误发生 {
return errors.New("错误描述")
}
// ... 更多代码逻辑
return nil
}
```
一个具体的例子是文件操作,如下所示:
```go
func openFile(filename string) (*os.File, error) {
file, err := os.Open(filename)
if err != nil {
return nil, err
}
return file, nil
}
```
在这个函数中,如果文件无法被打开,一个error类型的值将被返回。调用者需要检查这个返回值,并作出相应的错误处理。
### 3.1.2 错误处理的惯用模式
Go语言的惯用错误处理模式通常包括检查错误是否为nil,并基于错误的内容作出相应的处理。常见的处理模式包括:
- 立即返回错误,不执行后续操作:
```go
if err != nil {
return err // 或者返回自定义错误
}
```
- 记录错误信息并继续执行:
```go
if err != nil {
log.Println("警告:", err)
// 继续执行,但可能处于不完全预期的状态
}
```
- 在错误发生时,提供一些额外的上下文信息:
```go
if err != nil {
return fmt.Errorf("在处理X时出错:%w", err)
}
```
在上面的惯用模式中,`fmt.Errorf`函数使用`%w`动词将原始错误包装起来,这样可以在后续的错误处理中保持错误链的连贯性。
## 3.2 Go中的

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入探讨了 Go 语言中 CGo 的方方面面,为开发者提供了与 C 语言交互的全面指南。从性能优化到内存管理,再到依赖管理和操作系统 API 交互,专栏涵盖了所有关键主题。此外,还提供了 CGo 编码规范,以帮助开发者编写清晰且可维护的代码。通过遵循本专栏中概述的最佳实践,开发者可以充分利用 CGo 的强大功能,在 Go 应用程序中无缝集成 C 代码,从而提升性能、扩展功能并与底层系统交互。
专栏目录

文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
揭秘STM32:如何用PWM精确控制WS2812LED亮度(专业速成课)

# 摘要
本文系统介绍了STM32微控制器基础,PWM信号与WS2812LED通信机制,以及实现PWM精确控制的技术细节。首先,探讨了PWM信号的理论基础和在微控制器中的实现方法,随后深入分析了WS2812LED的工作原理和与PWM信号的对接技术。文章进一步阐述了实现PWM精确控制的技术要点,包括STM32定时器配置、软件PWM的实现与优化以及硬件PWM的配置和
深入解构MULTIPROG软件架构:掌握软件设计五大核心原则的终极指南
# 摘要
本文旨在探讨MULTIPROG软件架构的设计原则和模式应用,并通过实践案例分析,评估其在实际开发中的表现和优化策略。文章首先介绍了软件设计的五大核心原则——单一职责原则(SRP)、开闭原则(OCP)、里氏替换原则(LSP)、接口隔离原则(ISP)、依赖倒置原则(DIP)——以及它们在MULTIPROG架构中的具体应用。随后,本文深入分析了创建型、结构型和行为型设计模式在
【天清IPS问题快速诊断手册】:一步到位解决配置难题
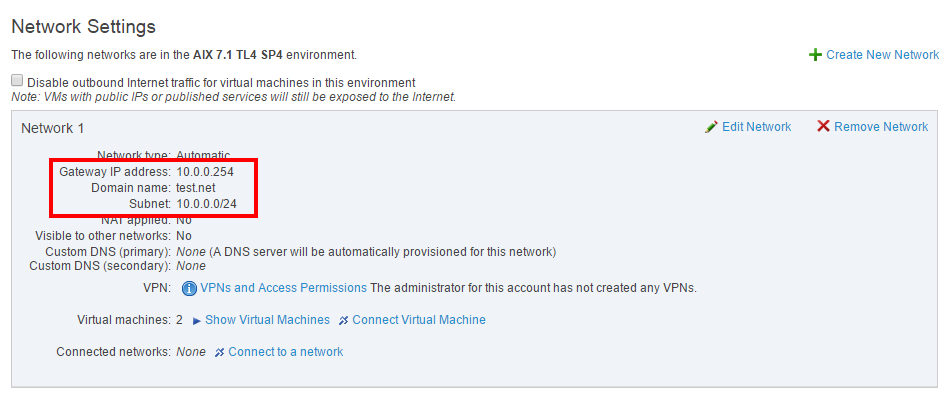
# 摘要
本文全面介绍了天清IPS系统,从基础配置到高级技巧,再到故障排除与维护。首先概述了IPS系统的基本概念和配置基础,重点解析了用户界面布局、网络参数配置、安全策略设置及审计日志配置。之后,深入探讨了高级配置技巧,包括网络环境设置、安全策略定制、性能调优与优化等。此外,本文还提供了详细的故障诊断流程、定期维护措施以及安全性强化方法。最后,通过实际部署案例分析、模拟攻击场景演练及系统升级与迁移实
薪酬增长趋势预测:2024-2025年度人力资源市场深度分析

# 摘要
本论文旨在探讨薪酬增长的市场趋势,通过分析人力资源市场理论、经济因素、劳动力供需关系,并结合传统和现代数据分析方法对薪酬进行预
【Linux文件格式转换秘籍】:只需5步,轻松实现xlsx到txt的高效转换

# 摘要
本文全面探讨了Linux环境下文件格式转换的技术与实践,从理论基础到具体操作,再到高级技巧和最佳维护实践进行了详尽的论述。首先介绍了文件格式转换的概念、分类以及转换工具。随后,重点介绍了xlsx到txt格式转换的具体步骤,包括命令行、脚本语言和图形界面工具的使用。文章还涉及了转换过程中的高级技
QEMU-Q35芯片组存储管理:如何优化虚拟磁盘性能以支撑大规模应用
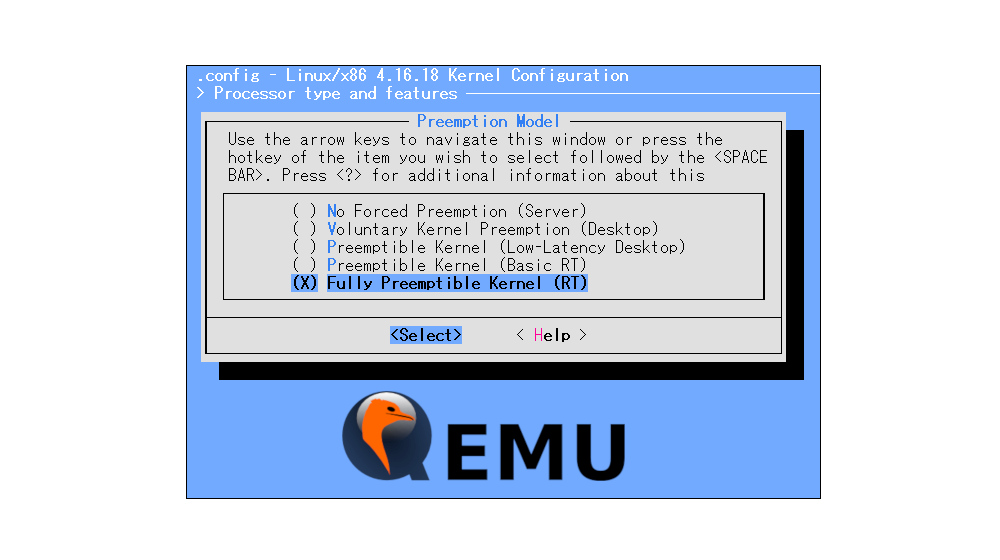
# 摘要
本文详细探讨了QEMU-Q35芯片组在虚拟化环境中的存储管理及性能优化。首先,介绍了QEMU-Q35芯片组的存储架构和虚拟磁盘性能影响因素,深入解析了存储管理机制和性能优化理论。接着,通过实践技巧部分,具体阐述了虚拟磁盘性能优化方法,并提供了配置优化、存储后端优化和QEMU-Q35特性应用的实际案例。案例研究章节分析了大规模应用环境下的虚拟磁盘性能支撑,并展
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )