分布式任务调度平台xxl-job简介与安装配置
发布时间: 2024-01-03 11:58:48 阅读量: 60 订阅数: 58 

分布式任务调度平台xxl-job
# 一、 简介
## 1.1 任务调度平台的概念及作用
任务调度平台是一种用于管理和调度系统中各种任务的工具或平台。在现代应用开发中,我们常常会遇到定时执行某个任务或者周期性执行某个任务的需求,比如定时发送邮件、定时生成报表、定时清理数据等。而任务调度平台的作用就是帮助我们管理这些任务,并按照预定的时间和规则进行自动调度和执行。
任务调度平台的主要作用有:
- **任务管理**:提供任务的创建、修改、删除等管理功能,支持配置任务的执行时间、执行规则等。
- **任务调度**:按照预定的时间和规则自动触发任务的执行,确保任务按时顺序执行。
- **任务监控**:实时监控任务的执行情况,包括任务是否成功执行、执行日志等。
- **报警管理**:对任务执行中出现的异常情况进行报警处理,及时发现并解决问题。
- **集群监控**:对任务调度平台的集群状态进行监控和管理,确保平台的稳定运行。
## 1.2 xxl-job的特点和优势
xxl-job是一款开源的分布式任务调度平台,具有以下特点和优势:
- **轻量级**:xxl-job采用轻量级设计,部署和使用都非常简单,适用于各种规模的应用项目。
- **易扩展**:xxl-job提供了丰富的API和扩展点,可以方便地进行功能扩展和定制化开发。
- **高可靠性**:xxl-job支持任务的高可靠性执行,提供了任务失败重试、失败跳过等机制,确保任务的稳定运行。
- **分布式调度**:xxl-job支持分布式任务调度,可以实现集群环境下的任务的统一管理和调度。
- **实时监控**:xxl-job提供了实时的任务监控和日志查看功能,方便用户进行任务的管理和调试。
- **报警通知**:xxl-job支持任务执行中的报警通知功能,可以及时发现和解决任务执行异常的情况。
以上是xxl-job的简介和特点,接下来我们将详细介绍xxl-job的功能和使用。
## 功能介绍
2.1 任务管理
2.2 日志查看
2.3 报警管理
2.4 集群监控
### 三、系统架构与原理
#### 3.1 xxl-job的整体架构设计
在xxl-job中,整体架构设计包括三个核心组件:调度中心、执行器和调度中心数据库。
- **调度中心(Job Admin)**:负责任务调度的管理和监控。用户可以通过调度中心进行任务的创建、暂停、恢复、删除等操作,同时可以查看任务的执行日志和监控任务运行情况。
- **执行器(Job Executor)**:运行在任务执行端,负责接收调度中心下发的任务,执行任务逻辑并将执行结果反馈给调度中心。
- **调度中心数据库**:用于存储任务的配置信息、执行日志、调度策略等数据。
整体架构如下图所示:
```
+-----------+ +-----------+ +-------------------+
| 调度中心 | <---- | 执行器 | <---- | 调度中心数据库 |
+-----------+ +-----------+ +-------------------+
```
#### 3.2 任务执行原理解析
任务的执行原理主要分为以下几个步骤:
1. **任务注册**:调度中心将任务信息注册到调度中心数据库中,包括任务的名称、触发方式、调度策略等。
2. **任务调度**:根据任务的调度策略,调度中心选择合适的执行器,并将任务信息发送给执行器。
3. **任务执行**:执行器接收到任务信息后,开始执行任务逻辑。执行器会不断向调度中心汇报任务的执行情况,包括任务开始、任务执行进度、任务执行结果等。
4. **任务完成**:执行器将任务执行结果反馈给调度中心,并将执行日志保存到调度中心数据库中。
该执行原理保证了任务的可靠执行和监控,并且具备较好的扩展性和灵活性。
以上是xxl-job的系统架构与原理的详细介绍,通过对整体架构和任务执行原理的理解,可以更好地使用和集成xxl-job。
## 安装准备
在安装xxl-job之前,需要进行一些准备工作。
### 4.1 系统环境要求
- Java版本:xxl-job要求使用Java 8及以上版本。
- 操作系统:支持Linux、Windows等主流操作系统。
### 4.2 软件依赖
在安装xxl-job之前,需要确保以下软件的安装和配置正确:
- MySQL数据库:用于存储任务、执行日志等信息。
- ZooKeeper:用于实现分布式任务调度平台的集群管理和协调。
### 4.3 数据库准备
在安装xxl-job之前,需要先创建一个MySQL数据库,并初始化表结构。
以下是创建数据库和表的SQL语句示例:
```sql
-- 创建数据库
CREATE DATABASE xxl_job;
-- 使用数据库
USE xxl_job;
-- 创建任务表
CREATE TABLE `xxl_job_info` (
`id` int(11) NOT NULL AUTO_INCREMENT COMMENT '主键ID',
`job_group` int(11) NOT NULL COMMENT '执行器主键ID',
`job_desc` varchar(255) NOT NULL COMMENT '任务描述',
`job_cron` varchar(255) NOT NULL COMMENT 'Cron表达式',
`glue_type` varchar(64) NOT NULL COMMENT '任务执行模式',
`executor_handler` text NOT NULL COMMENT '任务执行器',
`add_time` datetime NOT NULL COMMENT '创建时间',
`update_time` datetime NOT NULL COMMENT '修改时间',
`author` varchar(64) NOT NULL COMMENT '任务创建者',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='任务信息表';
```
请根据实际情况修改以上SQL语句,并使用MySQL客户端工具执行。
在数据库导入完成后,xxl-job将会自动根据表结构进行数据的增删改查操作。接下来可以进行xxl-job的安装步骤了。
## 五、 安装步骤
### 5.1 下载xxl-job安装包
首先,我们需要从xxl-job官方网站下载最新版本的安装包。进入官方网站,找到下载页面,选择适合你的操作系统平台的安装包,比如我们选择下载Linux版本的安装包。
下载完成后,将安装包解压至指定位置,例如我们将解压后的文件夹放置在/opt/xxl-job目录下。
### 5.2 配置文件修改
在安装包解压后的目录下,你会看到一个名为application.properties的配置文件。我们需要对该文件进行修改,以适应我们的环境需求。
首先,打开该配置文件,并修改以下配置项:
```properties
# 调度中心配置
xxl.job.admin.address=http://localhost:8080/xxl-job-admin # 调度中心地址
xxl.job.admin.username=admin # 调度中心登录用户名
xxl.job.admin.password=admin # 调度中心登录密码
# 执行器配置
xxl.job.executor.appname=my-job-executor # 执行器名称
xxl.job.executor.address=localhost:9999 # 执行器绑定的IP和端口
xxl.job.executor.logpath=/opt/xxl-job/log # 执行器日志文件存储路径
xxl.job.executor.logretentiondays=7 # 执行器日志保留天数
```
根据实际情况修改以上配置项,将调度中心地址、用户名和密码设置为正确的值。同时,设置执行器名称、绑定的IP和端口以及日志文件存储路径等。
### 5.3 安装启动
完成配置文件的修改后,我们即可进行安装启动操作。首先,进入xxl-job安装包解压后的目录,然后执行以下命令启动调度中心:
```shell
cd /opt/xxl-job/bin
./xxl-job-admin.sh start
```
接着,切换到执行器目录,执行以下命令启动执行器:
```shell
cd /opt/xxl-job/bin
./xxl-job-executor.sh start
```
通过以上步骤,我们成功启动了xxl-job的调度中心和执行器。
至此,安装步骤完成,我们可以进行接下来的配置和使用。如果有任何问题,请查看官方文档或咨询xxl-job官方支持。
# 六、 高级配置与集成
## 6.1 配置集群环境
在xxl-job中,可以通过配置集群环境来实现任务的分布式调度和执行。集群环境的配置需要以下几个步骤:
### 步骤一:配置注册中心地址
在xxl-job-admin的配置文件application.properties中,配置注册中心的地址。例如:
```properties
xxl.job.admin.addresses=http://localhost:8080/xxl-job-admin
```
### 步骤二:配置执行器地址
在xxl-job-executor开发的执行器中,配置执行器的自身地址和端口号。例如:
```properties
# 执行器名称
xxl.job.executor.appname=job-executor
# 执行器日志路径
xxl.job.executor.logpath=/data/applogs/xxl-job/job-executor
# 执行器日志保存天数
xxl.job.executor.logretentiondays=30
# 执行器地址
xxl.job.executor.ip=127.0.0.1
# 执行器端口号
xxl.job.executor.port=9999
```
### 步骤三:启动执行器
在启动执行器时,需要指定执行器的注册中心地址和执行器的自身地址。例如,使用Java代码启动执行器:
```java
public class XxlJobExecutorSample {
public static void main(String[] args) {
XxlJobExecutor executor = new XxlJobExecutor();
executor.setAdminAddresses("http://localhost:8080/xxl-job-admin");
executor.setIp("127.0.0.1");
executor.setPort(9999);
executor.start();
}
}
```
配置完成后,就可以启动多个执行器实例,并将它们注册到xxl-job-admin的任务执行器列表中。
## 6.2 与Spring Boot项目集成
如果要将xxl-job与Spring Boot项目集成,可以按照以下步骤进行配置:
### 步骤一:添加依赖
在Spring Boot项目的pom.xml文件中,添加xxl-job的依赖:
```xml
<dependency>
<groupId>com.xuxueli</groupId>
<artifactId>xxl-job-core</artifactId>
<version>2.3.0</version>
</dependency>
```
### 步骤二:配置属性
在Spring Boot项目的配置文件application.properties中,配置xxl-job的相关属性:
```properties
# xxl-job admin 地址
xxl.job.admin.addresses=http://localhost:8080/xxl-job-admin
# 执行器名称
xxl.job.executor.appname=my-job-executor
# 执行器日志路径
xxl.job.executor.logpath=/data/applogs/xxl-job/job-executor
# 执行器日志保存天数
xxl.job.executor.logretentiondays=30
```
### 步骤三:配置执行器
在Spring Boot项目中,创建一个执行器的配置类,并使用@XxlJobSpringExecutor注解标注。例如:
```java
@Configuration
public class XxlJobConfig {
@Value("${xxl.job.admin.addresses}")
private String adminAddresses;
@Value("${xxl.job.executor.appname}")
private String appName;
@Value("${xxl.job.executor.logpath}")
private String logPath;
@Value("${xxl.job.executor.logretentiondays}")
private int logRetentionDays;
@Bean
public XxlJobSpringExecutor xxlJobExecutor() {
XxlJobSpringExecutor xxlJobExecutor = new XxlJobSpringExecutor();
xxlJobExecutor.setAdminAddresses(adminAddresses);
xxlJobExecutor.setAppname(appName);
xxlJobExecutor.setLogPath(logPath);
xxlJobExecutor.setLogRetentionDays(logRetentionDays);
return xxlJobExecutor;
}
}
```
配置完成后,就可以在Spring Boot项目中定义任务,并通过xxl-job的调度触发器触发任务的执行。
## 6.3 定制化扩展插件介绍
xxl-job提供了一些扩展插件,可以根据业务需求定制化扩展任务的执行逻辑。以下是一些常用的扩展插件介绍:
### 1. 任务过滤器
xxl-job的任务过滤器可以在任务触发前和调度前进行任务过滤,可以过滤掉不符合条件的任务,从而实现任务执行的动态调度。可以通过实现XxlJobFilter接口来定义任务过滤器。
### 2. 任务路由策略
xxl-job的任务路由策略可以根据任务的参数或条件,将任务路由到不同的执行器上执行。可以通过实现XxlJobRouter接口来定义任务路由策略。
### 3. 任务监听器
xxl-job的任务监听器可以在任务执行前后进行一些操作,如记录任务执行日志、记录任务执行时间等。可以通过实现XxlJobListener接口来定义任务监听器。
### 4. 分片广播任务
xxl-job的分片广播任务可以将一个任务分片执行在多个执行器上,并行执行任务。可以通过实现XxlJobExecutor接口来定义分片广播任务。
以上是一些常用的扩展插件,可以根据需要选择合适的插件进行定制化扩展。
本章介绍了xxl-job的高级配置与集成方式,包括配置集群环境、与Spring Boot项目集成以及定制化扩展插件的介绍。通过这些配置和扩展,可以更好地适应不同的业务需求和场景。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
分布式任务调度平台xxl-job是一款功能强大且易于使用的任务调度系统。该专栏详细介绍了xxl-job的安装配置、任务调度原理与执行流程、定时任务实现方法、复杂任务依赖处理、失败重试与报警机制、任务执行器设计与实现原理、动态任务注册与反注册、并发控制与线程池配置优化、分片任务的分配与处理、异常情况与错误处理、任务调度策略与动态调度算法、负载均衡与节点选举机制、分布式锁的应用与优化、任务监控与性能调优、故障处理与恢复策略、任务流水线与工作流设计、任务执行日志的存储与检索优化、任务调度权限控制与安全性设计等内容。无论是对于任务调度平台的初学者还是有一定经验的开发者,本专栏都能提供全面且实用的指导,帮助读者深入了解xxl-job的各个方面,提升任务调度的效率和可靠性。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【深入理解Python3的串口通信】:掌握Serial模块核心特性的全面解析

# 摘要
本文详细介绍了在Python3环境下进行串口通信的各个方面。首先,概述了串口通信的基础知识,以及Serial模块的安装、配置和基本使用。接着,深入探讨了Serial模块的高级特性,包括数据读写、事件和中断处理以及错误处理和日志记录。文章还通过实践案例,展示了如何与单片机进行串口通信、数据解析以及在多线程环境下实现串口通信。最后,提供了性能优化策略和故障
单片机选择秘籍:2023年按摩机微控制器挑选指南

# 摘要
单片机作为智能设备的核心,其选型对于产品的性能和市场竞争力至关重要。本文首先概述了单片机的基础知识及市场需求,然后深入探讨了单片机选型的理论
【Unreal Engine 4打包与版本控制深度探索】:掌握.pak文件的打包和版本管理(版本控制新技术)
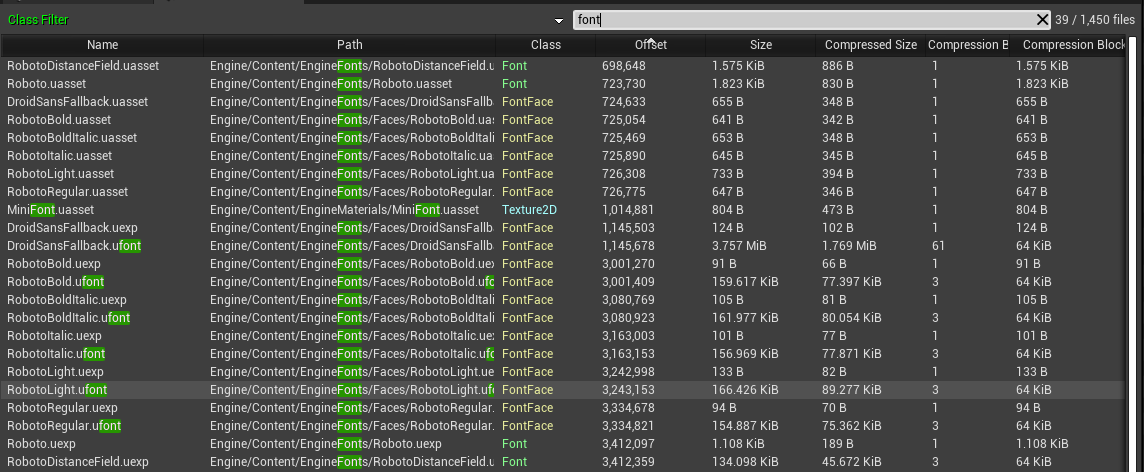
# 摘要
本文系统地介绍了Unreal Engine 4(UE4)项目打包的基础知识,并详细探讨了.pak文件的结构和打包流程,包括逻辑结构、打包技术细节以及常见问题的解决方法。同时,本文深入分析了版本控制技术在UE4中的应用,涵盖了版本控制概念、工具选择与配置以及协作工作流程。文章还提出了.pak文件与版本控制的整合策略,以及在持续集成中自动化打包的实践案例。
【无线电信号传播特性全解析】:基站数据概览与信号覆盖预测
# 摘要
无线电信号传播是移动通信技术中的基础性问题,其质量直接影响通信效率和用户体验。本文首先介绍了无线电信号传播的基础概念,随后深入分析了影响信号传播的环境因素,包括自然环境和人为因素,以及信号干扰的类型和识别方法。在第三章中,探讨了不同信号传播模型及其算法,并讨论了预测算法和工具的应用。第四章详细说明了基站数据采集与处理的流程,包括数据采集技术和数据处理方法。第五章通过实际案例分析了信号覆盖预测的应用,并提出优化策略。最后,第六章展望了无线电信号传播特性研究的前景,包括新兴技术的影响和未来研究方向。本文旨在为无线通信领域的研究者和工程师提供全面的参考和指导。
# 关键字
无线电信号传播
【MDB接口协议创新应用】:探索新场景与注意事项

# 摘要
本文旨在介绍MDB接口协议的基础知识,并探讨其在新场景中的应用和创新实践。首先,文章提供了MDB接口协议的基础介绍,阐述了其理论框架和模型。随后,文章深入分析了MDB接口协议在三个不同场景中的具体应用,展示了在实践中的优势、挑战以及优化改进措施。通过案例分析,本文揭示了MDB接口协议在实际操作中的应用效果、解决的问题和创新优化方案。最后,文章展望了MDB接口协议的发展趋势和
系统架构师必备速记指南:掌握5500个架构组件的关键
# 摘要
系统架构师在设计和维护复杂IT系统时起着至关重要的作用。本文首先概述了系统架构师的核心角色与职责,随后深入探讨了构成现代系统的关键架构组件,包括负载均衡器、高可用性设计、缓存机制等。通过分析它们的理论基础和实际应用,文章揭示了各个组件如何在实践中优化性能并解决挑战。文章还探讨了如何选择和集成架构组件,包括中间件、消息队列、安全组件等,并讨论了性能监控、调优以及故障恢复的重要性。最后,本文展望了
Cadence 17.2 SIP高级技巧深度剖析:打造个性化设计的终极指南
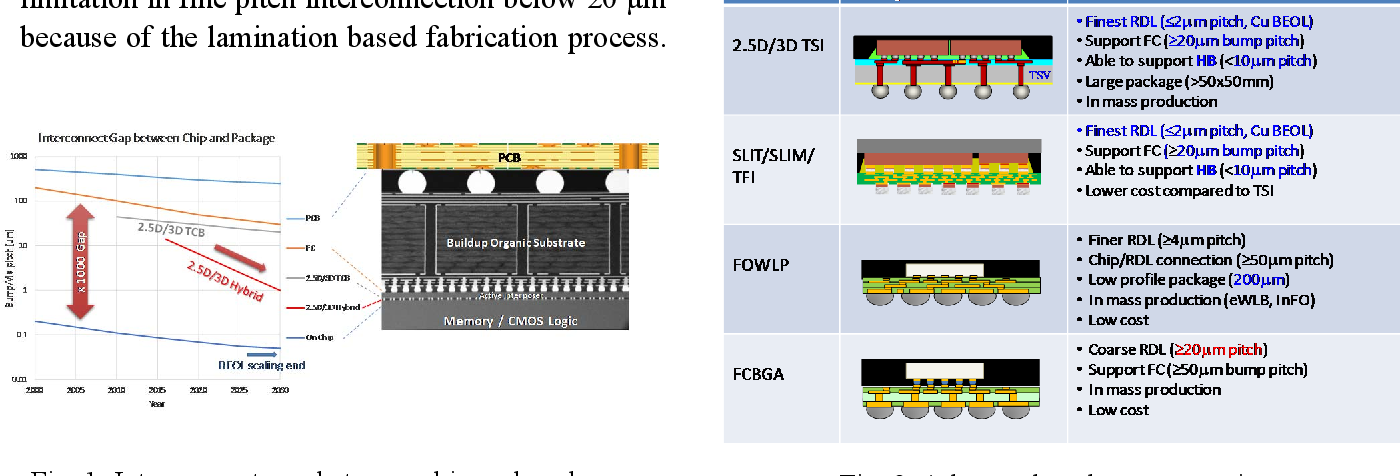
# 摘要
Cadence SIP(系统级封装)技术是集成多核处理器和高速接口的先进封装解决方案,广泛应用于移动设备、嵌入式系统以及特殊环境下,提供高性能、高集成度的电子设计。本文首先介绍Cadence SIP的基本概念和工作原理,接着深入探讨了SIP的高级定制技巧,包括硬件抽象层定制、信号完整性和电源管理优化,以及如何在不同应用领域中充分发挥SIP的潜
故障排除术:5步骤教你系统诊断问题
# 摘要
故障排除是确保系统稳定运行的关键环节。本文首先介绍了故障排除的基本理论和原则,然后详细阐述了系统诊断的准备工作,包括理解系统架构、确定问题范围及收集初始故障信息。接下来,文章深入探讨了故障分析和诊断流程,提出了系统的诊断方法论,并强调了从一般到特殊、从特殊到一般的诊断策略。在问题解决和修复方面,本文指导读者如何制定解决方案、实施修复、测试及验证修复效果。最后,本文讨论了系统优化和故障预防的策略,包括性能优化、监控告警机制建立和持续改进措施。本文旨在为IT专业人员提供一套系统的故障排除指南,帮助他们提高故障诊断和解决的效率。
# 关键字
故障排除;系统诊断;故障分析;解决方案;系统优
权威指南:DevExpress饼状图与数据源绑定全解析
/i.s3.glbimg.com/v1/AUTH_08fbf48bc0524877943fe86e43087e7a/internal_photos/bs/2021/f/c/GVBAiNRfietAiJ2TACoQ/2016-01-18-excel-02.jpg)
# 摘要
本文详细介绍了DevExpress控件库中饼状图的使用和
物联网传感数据处理:采集、处理到云端的全链路优化指南
# 摘要
随着物联网技术的发展,传感数据处理变得日益重要。本文全面概述了物联网传感数据处理的各个环节,从数据采集、本地处理、传输至云端、存储管理,到数据可视化与决策支持。介绍了传感数据采集技术的选择、配置和优化,本地数据处理方法如预处理、实时分析、缓存与存储策略。同时,针对传感数据向云端的传输,探讨了通信协议选择、传输效率优化以及云端数据处理架构。云端数据存储与管理部分涉及数据库优化、大数据处理技术的应用,以及数据安全和隐私保护。最终,数据可视化与决策支持系统章节讨论了可视化工具和技术,以及如何利用AI与机器学习辅助业务决策,并通过案例研究展示了全链路优化的实例。
# 关键字
物联网;传感数
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )