【VDA-360推荐系统速成秘籍】:新手必读的10大入门技巧
发布时间: 2024-12-15 12:21:43 阅读量: 8 订阅数: 18 

参考资源链接:[VDA-360 recommendation_360_Interface_ESC_eBooster_V1](https://wenku.csdn.net/doc/6412b4bebe7fbd1778d40a9c?spm=1055.2635.3001.10343)
# 1. VDA-360推荐系统概述
随着信息技术的飞速发展,推荐系统已经渗透到我们生活的方方面面,从在线购物到社交媒体,再到新闻推荐和在线教育,推荐系统在提高用户体验、增加用户粘性方面发挥了不可替代的作用。VDA-360推荐系统是一个全面、多层次的推荐解决方案,旨在解决信息过载问题,为用户呈现个性化内容,提高服务质量与效率。在本章中,我们将探讨VDA-360推荐系统的基本概念、设计目标以及它在大数据环境下的重要性。
## 1.1 推荐系统简介
推荐系统是一种信息过滤系统,通过分析用户的历史行为、偏好和上下文信息,为用户提供个性化的内容推荐。VDA-360推荐系统采用先进的算法和丰富的数据处理技术,为不同领域的用户提供定制化的推荐服务。它的核心在于通过学习用户的行为和反馈,动态调整推荐策略,以达到最佳的用户体验。
## 1.2 推荐系统的作用与价值
推荐系统不仅改善了用户的信息消费方式,还为企业提供了新的商业模式和增收渠道。通过精准的用户画像和行为分析,VDA-360推荐系统能够提高用户的满意度和参与度,从而提升企业的转化率和用户留存率。此外,推荐系统还在一定程度上推动了大数据和人工智能技术的发展,促进了相关学科的交叉融合。
## 1.3 推荐系统的挑战与发展
尽管推荐系统带来了诸多便利,但同时也面临着众多挑战,如数据隐私保护、推荐结果的多样性和新颖性等。VDA-360推荐系统通过不断的技术迭代和优化,试图克服这些难题,并为用户带来更加安全、高效、满意的推荐体验。随着技术的不断进步,未来推荐系统将更好地融入我们的日常生活,为社会创造更大的价值。
在接下来的章节中,我们将深入探讨VDA-360推荐系统的理论基础、实践应用以及未来趋势,全面解读其在技术演进和行业发展中的重要作用。
# 2. VDA-360推荐系统理论基础
在当今信息化飞速发展的社会中,推荐系统已经成为了网站和应用程序中不可或缺的部分,它能够根据用户的兴趣和行为,为用户推荐他们可能感兴趣的产品或服务。VDA-360推荐系统,作为一种先进的推荐技术,通过结合不同的算法和技术来提供个性化的推荐。本章节将深入探讨VDA-360推荐系统的分类、核心算法以及数据处理方法,为理解该系统的运作机制奠定理论基础。
## 2.1 推荐系统的分类
推荐系统可以根据不同的标准和应用场景被划分为多种类型,但最常见的分类方法是基于推荐系统的工作原理。主要可以分为以下几类:
### 2.1.1 基于内容的推荐
基于内容的推荐系统主要关注于内容本身,它通过分析项目(如文章、视频、音乐等)的特征和属性,然后推荐与用户历史喜好相似的内容。此类型推荐系统的核心在于建立准确的项目描述,并将用户的偏好与这些描述匹配。
```python
# 示例代码:基于内容的推荐系统伪代码
def content_based_recommendation(user_profile, content_data):
# 假设 user_profile 是用户的历史偏好特征向量
# content_data 是项目的内容特征数据集
similarity_scores = {} # 存储相似度分数
for content_id, content_features in content_data.items():
# 计算内容特征与用户偏好特征之间的相似度
similarity = calculate_similarity(user_profile, content_features)
similarity_scores[content_id] = similarity
# 按相似度排序,推荐得分最高的项目
recommended_items = sorted(similarity_scores, key=similarity_scores.get, reverse=True)
return recommended_items[:N] # 返回前N个推荐项
```
### 2.1.2 协同过滤推荐
协同过滤是推荐系统中另一种常见的方法,它通过分析用户之间的行为和偏好,基于用户的群体行为进行推荐。协同过滤分为两种:用户-用户协同过滤和项目-项目协同过滤。
```python
# 示例代码:基于协同过滤的推荐系统伪代码
def collaborative_filtering_recommendation(user_ratings, target_user_id):
# 假设 user_ratings 是所有用户的评分矩阵
# target_user_id 是目标用户ID
similar_users = find_similar_users(user_ratings, target_user_id)
# 根据相似用户的历史评分预测目标用户的评分
predictions = predict_ratings(user_ratings, similar_users, target_user_id)
recommended_items = sort_by_predictions(predictions)
return recommended_items[:N] # 返回前N个推荐项
```
### 2.1.3 混合推荐系统
混合推荐系统结合了基于内容的推荐和协同过滤的方法。它的目的是利用不同方法的优势,同时减少各自方法的不足。通过合理融合不同类型的推荐算法,混合推荐系统能够为用户提供更准确、更全面的推荐。
```python
# 示例代码:混合推荐系统伪代码
def hybrid_recommendation(user_profile, content_data, user_ratings):
content_based_recs = content_based_recommendation(user_profile, content_data)
collaborative_recs = collaborative_filtering_recommendation(user_ratings, user_id)
# 将两种推荐方法的结果按一定规则融合
final_recs = combine_recommendations(content_based_recs, collaborative_recs)
return final_recs[:N] # 返回前N个推荐项
```
## 2.2 推荐系统的核心算法
### 2.2.1 算法的基本原理
推荐系统的核心算法涵盖了从简单的启发式方法到复杂的机器学习算法。算法的基本原理通常围绕着如何提取用户行为数据、如何度量用户之间的相似性以及如何预测用户可能感兴趣的新项目。
### 2.2.2 算法的性能评估
推荐系统的性能评估对于算法的优化至关重要。常见的评估指标包括准确度、召回率、F1分数、平均绝对误差(MAE)和均方根误差(RMSE)等。这些指标帮助我们理解推荐系统在真实环境下的表现。
### 2.2.3 算法的选择和应用
在选择适合的推荐系统算法时,需要考虑系统的应用场景、数据特性、可扩展性、实时性要求等多个因素。算法的选择应当根据实际的业务需求和目标来确定。
## 2.3 推荐系统的数据处理
### 2.3.1 数据收集和预处理
数据收集和预处理是推荐系统实施的首要步骤。原始数据往往包含噪声和不一致性,需要通过清洗、标准化、去重等手段进行预处理,以提高数据质量。
```markdown
表2.1 数据预处理步骤
| 步骤 | 描述 | 目的 |
| --- | --- | --- |
| 数据清洗 | 移除重复项、处理缺失值 | 提高数据准确性 |
| 数据标准化 | 对不同量级的特征进行缩放 | 保证数据可比性 |
| 数据离散化 | 将连续数据分割成离散区间 | 简化模型处理 |
| 特征选择 | 筛选出影响模型预测的重要特征 | 提升模型效率 |
```
### 2.3.2 特征工程和模型构建
在推荐系统中,特征工程的主要目的是从原始数据中提取出对预测用户行为最有帮助的特征。模型构建则依赖于这些特征来训练预测模型,常用的模型包括矩阵分解、梯度提升决策树等。
### 2.3.3 数据的更新和维护策略
随着时间的推移,用户的兴趣会变化,新项目也会不断出现,因此推荐系统需要定期更新其数据集。数据更新和维护策略包括增量学习、冷启动处理以及数据老化机制等。
通过以上章节的深入分析,我们可以看出,VDA-360推荐系统的理论基础是多方面的,不仅包含推荐系统本身的技术实现,还涉及了对算法性能评估的重视,以及对数据处理流程的严谨要求。在实际应用中,理解这些理论基础有助于我们更好地设计和优化推荐系统,使其在不同场景下发挥出最佳性能。
# 3. ```
# 第三章:VDA-360推荐系统的实践应用
在介绍VDA-360推荐系统的实践应用时,首先需要理解推荐系统在实际业务场景中的搭建过程。这一过程通常涉及需求分析、系统设计、技术选型、系统实现、测试评估和持续优化等多个环节。本章将围绕这些关键步骤展开,详细解析推荐系统在真实世界中的运作和优化策略。
## 3.1 实际场景下的推荐系统搭建
### 3.1.1 系统需求分析和设计
在推荐系统搭建的第一阶段,需求分析和系统设计是至关重要的。该阶段的主要任务是明确业务目标、用户需求和系统功能。
**需求分析**
需求分析首先需要从业务角度出发,明确推荐系统需要达成的目标。例如,是否需要提高用户粘性、增加销售额或是提升用户满意度等。之后,收集目标用户群体的反馈,了解他们的需求和偏好。
**系统设计**
在需求分析的基础上,进入系统设计阶段,这包括:
- **推荐策略的设定**:确定是使用基于内容的推荐、协同过滤还是混合推荐系统。
- **系统架构的选择**:选择合适的后端技术栈和推荐算法框架。
- **接口和数据流的定义**:确定系统与用户界面、数据存储和其他服务间的交互方式。
### 3.1.2 关键技术选型和实现
推荐系统的技术选型直接影响到系统的性能和扩展性。关键技术包括数据处理技术、推荐算法以及前后端技术栈。
**数据处理技术**
数据是推荐系统的核心,因此需要使用高效的数据处理技术。例如,使用Hadoop或Spark进行大规模数据的存储和处理。
**推荐算法**
算法是推荐系统的灵魂。常见的推荐算法有矩阵分解、深度学习模型等。例如,使用Apache Mahout或TensorFlow实现推荐算法。
**前后端技术栈**
前端技术栈应具备良好的用户体验设计,如React或Vue.js。后端则负责逻辑处理和数据交互,如Node.js或Python Flask。
### 3.1.3 系统测试和优化
系统的测试和优化是保证推荐系统质量的重要环节。测试包括单元测试、集成测试和性能测试等。
**单元测试**
确保每个模块按预期工作。可以使用Jest或Mocha等测试框架。
**集成测试**
确保各个模块间交互正确。通常使用Selenium或Puppeteer进行自动化测试。
**性能测试**
优化系统性能以提高响应速度。可采用LoadRunner或JMeter等工具。
## 3.2 用户行为分析与特征提取
### 3.2.1 用户画像构建
用户画像的构建是推荐系统个性化推荐的基础。它包括收集用户的基本信息、行为数据、偏好设置等。
**基本信息**
如性别、年龄、地域等,可从用户注册信息中获取。
**行为数据**
包括用户在平台上的浏览、购买、评价等行为。可以使用Python进行数据抓取和处理。
**偏好设置**
用户在设置中手动指定的兴趣偏好,这对推荐系统的准确性至关重要。
### 3.2.2 用户行为数据挖掘
通过数据挖掘技术分析用户行为数据,发现用户行为模式和兴趣趋势。
**聚类分析**
使用K-means、DBSCAN等算法,发现用户群体特征。
**关联规则**
通过Apriori或FP-Growth算法,找出用户购买行为间的关联性。
### 3.2.3 特征向量的应用
将用户行为和偏好转化为特征向量,为推荐算法提供输入。
**向量化**
如将文本数据转化为TF-IDF向量或Word2Vec向量。
**归一化**
对特征向量进行归一化处理,保证不同特征在同一量级。
## 3.3 推荐系统效果评估和优化
### 3.3.1 用户满意度调查
通过问卷或访谈的方式收集用户对推荐结果的满意度反馈。
### 3.3.2 系统A/B测试
对推荐算法进行A/B测试,比较不同版本的推荐效果。
### 3.3.3 模型的迭代优化
根据反馈和测试结果不断迭代优化推荐模型。
**模型调整**
根据用户反馈调整推荐策略和算法参数。
**系统升级**
持续更新系统以引入新技术和方法。
通过上述三个子章节的详细介绍,我们可以看到VDA-360推荐系统的搭建过程涉及到了复杂的步骤和广泛的技术应用。在实际场景下,推荐系统并非一成不变,而是需要根据用户行为、反馈和业务需求不断调整和优化。这种动态的调整机制是实现个性化推荐、提升用户体验和业务效率的关键。
```
# 4. VDA-360推荐系统的进阶技巧
## 4.1 推荐系统的个性化定制
### 4.1.1 个性化推荐策略
在现代推荐系统的发展中,个性化推荐是提升用户体验和增加用户粘性的核心要素。个性化推荐策略通常依赖于用户的特征数据,包括但不限于用户的历史行为、偏好设置以及当前上下文信息。为了实现个性化推荐,系统需要动态地学习用户的兴趣模式,并实时更新用户画像。
举例来说,如果一个用户在一段时间内频繁查看技术类的书籍,推荐系统会倾向于推荐相关的技术文章或图书。当这个用户在特定的时间段内,比如晚上的休闲时间,系统则可能推荐一些轻松的科技博客或视频内容。这些推荐都是基于用户过去的行为和时间上下文进行优化的。
### 4.1.2 用户兴趣追踪与预测
追踪用户兴趣的动态变化,并预测其未来可能感兴趣的内容,是推荐系统个性化的重要方面。这可以通过机器学习模型来实现,比如使用时间序列分析来预测用户的未来行为,或者采用协同过滤来发现用户的潜在兴趣。
一种常用的方法是隐语义模型(Latent Factor Models),它们通过分析用户对不同项的评分,推断出用户和物品的隐特征。隐特征可以理解为用户兴趣和物品属性在低维空间的表示。通过这种模型,推荐系统能根据用户当前的兴趣状态预测其对未交互物品的潜在偏好。
### 4.1.3 多样性与新颖性平衡
在个性化推荐中,除了精准度之外,推荐结果的多样性和新颖性也是衡量推荐系统质量的重要指标。多样性保证用户不会总是接收到相似的推荐结果,而新颖性则意味着推荐系统可以引入用户未见过但可能感兴趣的新内容。
为了平衡这两者,可以采用多臂老虎机(Multi-Arm Bandit)算法来调节探索(exploration)与利用(exploitation)之间的关系。探索是为了发现用户的未知偏好,而利用则是基于当前已知偏好提供推荐。通过动态调整这个平衡,推荐系统能够更加灵活地适应用户的变化,同时持续提供新鲜感。
### 代码块实例:使用Python实现隐语义模型(Latent Factor Models)
```python
import numpy as np
from scipy.sparse.linalg import svds
# 假设 ratings 是一个用户-物品评分矩阵
# 以下是矩阵的简化示例数据
ratings = np.array([
[5, 3, 0, 1],
[4, 0, 4, 1],
[1, 1, 0, 5],
[1, 0, 0, 4],
[0, 1, 5, 4],
])
# 利用奇异值分解(SVD)来降低维度并发现隐特征
U, singular_values, Vt = svds(ratings, k=2)
# 构建用户和物品的隐特征矩阵
user隱特征 = U
item隱特征 = Vt.T
# 根据用户的隐特征和物品的隐特征来预测评分
def predict(ratings, user隱特征, item隱特征):
# 这里只是简单地计算用户隐特征和物品隐特征的点积
# 实际应用中可能需要更复杂的模型和更精细的调参
predictions = np.dot(user隱特征, item隱特征.T)
return predictions
predictions = predict(ratings, user隱特征, item隱特征)
print(predictions)
```
通过上述代码,我们可以使用SVD对用户和物品的隐特征进行学习,并利用这些隐特征进行评分预测。这种方法能够帮助我们在个性化推荐中达到多样性和新颖性的平衡。
## 4.2 大数据下的推荐系统技术
### 4.2.1 分布式计算框架
大数据环境下,推荐系统需要处理的数据量庞大,单机架构往往无法满足实时性和可扩展性的需求。分布式计算框架成为了推荐系统的必然选择。Apache Spark和Apache Flink是当前流行的分布式计算框架,它们提供了一套完整的大数据处理解决方案。
Spark通过其弹性分布式数据集(RDD)和DataFrame等抽象,使得大数据的处理变得简单高效。而Flink则侧重于流处理,能够实现低延迟的实时数据处理,这在需要即时推荐的场景下非常有用。
### 4.2.2 流式处理与实时推荐
流式处理技术为实时推荐提供了可能。推荐系统能够根据用户当前的行为模式,即时调整推荐策略。这不仅提升了用户体验,也有助于提高系统的响应性和业务的转化率。
使用Flink进行流处理时,推荐系统可以订阅用户的实时行为数据流,并利用复杂事件处理(Complex Event Processing, CEP)技术分析这些数据流,以发现符合用户当前兴趣的推荐机会。
### 4.2.3 大数据存储和管理
推荐系统必须拥有强大的数据存储和管理能力,以支撑复杂的数据查询和高效的数据更新。Hadoop的HDFS和Apache Cassandra是大数据存储的两个例子,它们能够提供高吞吐量和容错性,适合存储大规模的非关系型数据。
在数据管理方面,NoSQL数据库如MongoDB提供了灵活的数据模型和高效的存储,能够应对非结构化数据和半结构化数据的挑战。而图数据库如Neo4j则适合处理推荐系统中复杂的关联关系,比如用户和用户之间的社交关系。
### 表格:比较不同大数据存储方案
| 存储方案 | 适用场景 | 优势 | 劣势 |
|---------|--------|-----|-----|
| HDFS | 大规模批处理数据存储 | 高吞吐量、容错性好、扩展性强 | 不适合小数据量实时处理 |
| Cassandra | 高性能大规模分布式数据库 | 无单点故障、高可用、可水平扩展 | 一致性保证较弱 |
| MongoDB | 存储半结构化数据 | 灵活的数据模型、高性能读写 | 对事务处理支持较弱 |
| Neo4j | 存储复杂的图关系数据 | 处理复杂查询高效、事务支持好 | 可能遇到扩展性问题 |
## 4.3 推荐系统在各行业的应用案例
### 4.3.1 电子商务推荐系统实例
电子商务推荐系统是推荐技术应用最为广泛的领域之一。基于用户历史浏览、购买记录以及搜索关键词,推荐系统可以为用户提供个性化商品推荐。例如,亚马逊利用基于内容的推荐和协同过滤算法为用户提供个性化的商品页面,并通过A/B测试持续优化推荐模型。
### 4.3.2 媒体内容推荐的策略
在媒体内容领域,推荐系统通过分析用户的观看历史、观看时长、评论和评分等数据,了解用户的偏好。Netflix就是一个典型的例子,它不仅提供个性化的内容推荐,还通过推荐引擎预测用户的喜好,以提高用户满意度和观看时长。
### 4.3.3 社交网络中的推荐技术
社交网络中的推荐技术不仅包括为用户推荐好友,还包括推荐内容、群组和事件。Facebook利用用户的社交图谱来推荐可能认识的新朋友,同时通过分析用户在网站上的互动行为,为用户推荐感兴趣的内容和活动。LinkedIn则更多地关注于职业发展和招聘领域的推荐,比如职位推荐、人脉推荐等。
### 代码块实例:基于用户行为的简单推荐算法
```python
from scipy.spatial.distance import cosine
def recommend_items(user_behavior, all_items, top_n=10):
"""
一个简单的推荐系统函数,基于用户行为推荐物品。
:param user_behavior: 用户行为数据
:param all_items: 所有物品的集合
:param top_n: 推荐数量
:return: 推荐列表
"""
# 计算用户行为与所有物品之间的余弦相似度
similarities = []
for item in all_items:
if item not in user_behavior:
continue
similarity = 1 - cosine(user_behavior[item], user_behavior['target_item'])
similarities.append((item, similarity))
# 根据相似度排序,并返回前top_n个推荐
similarities.sort(key=lambda x: x[1], reverse=True)
return [item[0] for item in similarities[:top_n]]
# 示例用户行为数据
user_behavior = {
'item1': np.array([0.1, 0.2, 0.3]),
'item2': np.array([0.2, 0.3, 0.4]),
'target_item': np.array([0.3, 0.4, 0.5]),
}
# 推荐结果
recommended_items = recommend_items(user_behavior, ['item3', 'item4', 'item5'])
print(recommended_items)
```
通过此代码示例,我们可以实现一个基于用户行为的简单推荐系统。这种方法能够快速地为用户推荐与目标物品相似的物品列表。
以上是VDA-360推荐系统进阶技巧中的一些关键概念和实现方式。通过对个性化定制、大数据技术的应用和在不同行业的案例研究,我们可以看到推荐系统在现代互联网应用中的多样性和重要性。
# 5. VDA-360推荐系统未来趋势与发展
随着技术的不断进步和数据量的爆炸式增长,推荐系统在个性化、实时性和准确性方面的要求越来越高。本章将探讨推荐系统未来的趋势,包括伦理法规的挑战、新兴技术的应用,以及行业展望与创新方向。
## 5.1 推荐系统的伦理与法规
推荐系统的伦理和法规问题是任何技术发展都无法忽视的重要方面。在快速发展的IT行业中,保护用户隐私、数据安全和合规性成为企业必须面对的挑战。
### 5.1.1 用户隐私保护
用户隐私保护是推荐系统设计和实施过程中的核心问题。企业需要确保用户的个人信息在收集、存储、处理和传输过程中不被泄露或滥用。一种有效的做法是采用匿名化处理和数据加密技术,以此来保证用户信息的安全。
```python
# Python示例代码:使用Pandas处理用户数据并进行匿名化处理
import pandas as pd
from sklearn.preprocessing import LabelEncoder
# 假设df是包含用户数据的DataFrame
df = pd.DataFrame({
'User ID': [101, 102, 103],
'Name': ['Alice', 'Bob', 'Charlie'],
'Email': ['alice@email.com', 'bob@email.com', 'charlie@email.com']
})
# 对用户姓名和电子邮件进行匿名化处理
le = LabelEncoder()
df['Name'] = le.fit_transform(df['Name'])
df['Email'] = le.fit_transform(df['Email'])
print(df)
```
### 5.1.2 数据安全与合规性
数据安全不仅仅是技术问题,还涉及到合规性问题。推荐系统必须遵守相关的法律法规,例如欧洲的一般数据保护条例(GDPR)。合规性要求企业在处理个人数据时要有明确的合法依据,并赋予用户对自己数据的控制权。
### 5.1.3 推荐系统的伦理问题
推荐系统的设计和实施还面临着伦理问题,比如算法偏见和信息泡沫。为了避免这些问题,推荐系统需要透明化,让用户了解推荐的原因,并提供多样化的推荐结果以防止信息偏食。
## 5.2 新兴技术在推荐系统中的应用
未来推荐系统的发展将越来越多地依赖于新兴技术的融合应用。
### 5.2.1 人工智能与深度学习
深度学习技术能够从复杂的用户行为数据中提取深层次的特征,为推荐系统提供了更精准的预测。通过构建复杂的神经网络模型,系统可以更好地理解用户偏好,并提供高度个性化的推荐。
### 5.2.2 增强学习与智能决策
增强学习允许推荐系统在与用户的互动中不断学习和改进。通过对推荐策略进行实时调整,推荐系统可以在不断变化的环境中保持高效和准确。
### 5.2.3 量子计算与推荐系统
量子计算作为一种革命性的计算范式,拥有解决复杂计算问题的巨大潜力。在推荐系统领域,量子计算可以用来加速大数据集上的模式识别和优化计算过程。
## 5.3 行业展望与创新方向
随着推荐技术的不断演进,我们可以预见未来的推荐系统将会在多个领域带来创新和变革。
### 5.3.1 未来的推荐技术趋势
未来的推荐技术将更加注重用户交互体验,利用增强现实和虚拟现实技术为用户提供沉浸式推荐。同时,实时推荐和情境感知推荐将成为常态。
### 5.3.2 行业应用的创新点
推荐系统将深入到各个行业,为用户提供更加专业化和个性化的服务。例如,在医疗行业,推荐系统可以根据患者的病历和健康数据提供定制化治疗方案。
### 5.3.3 推荐系统对社会的影响
推荐系统在提高社会效率和改善用户体验方面具有重要作用,但同时也可能造成信息分化和社会分化。因此,未来的发展需要更加注重平衡推荐系统的利弊,并采取措施来减少其可能带来的负面影响。
通过本章的探讨,我们可以看到,尽管VDA-360推荐系统面临着诸多挑战,但其在技术创新和行业应用上具有巨大的发展潜力。未来,随着技术的不断进步和法规的完善,推荐系统将会为社会带来更加积极的影响。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
《VDA-360 Recommendation 360 Interface ESC eBooster V1》专栏深入探讨了 VDA-360 的实施、集成、故障排除、云服务优化、大数据处理和动态内容推荐等方面的关键主题。通过案例分析、挑战解决方案、故障排查指南、部署策略、处理秘籍和推荐策略,该专栏为读者提供了全面的知识和实践技巧,帮助他们充分利用 VDA-360 的功能,解决实际问题,并优化其性能和效率。专栏旨在为企业和 IT 专业人士提供宝贵的见解,使他们能够有效地实施和管理 VDA-360,从而提高业务效率和用户体验。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【USB 3.0接口的电源管理】:确保设备安全稳定供电

# 摘要
USB 3.0接口已成为现代计算机和消费电子设备中广泛应用的高速数据传输标准。本文详细探讨了USB 3.0接口的电源管理理论,包括电源管理规范、工作原理以及面临的挑战。进一步,本文通过实际案例分析了USB 3.0接口电源管理在不同设备中的实现、测试与优化,并讨论了提高电源效率的技术手段以及电源管理策略的设计。文章最后总结了USB
【西门子PID调试流程】:理论与实践完美结合的步骤指南

# 摘要
本文全面介绍了西门子PID控制器的功能、理论基础及应用。首先概述了PID控制器的重要性和基本控制原理,随后详细阐述了比例、积分、微分三种控制参数的物理意义及调整策略,并提供了性能评估指标的定义和计算方法。接着,文章探讨了西门子PLC与PID调试软件的介绍,以及PID参数的自动调整技术和调试经验分享。通过实操演示,说明了PID参数的初始化、设置步骤
数字电路性能深度分析:跨导gm的影响与案例研究

# 摘要
本文全面探讨了数字电路性能中跨导gm的作用及其优化策略。首先介绍了跨导gm的基础理论,包括其定义、作用机制和计算方法。随后分析了跨导gm对数字电路性能的影响,特别是其在放大器设计和开关速度中的应用。为了实现跨导gm的优化,本文详细探讨了相关的测量技术及实践案例,提出了针对性的
【Kepware高级配置教程】:定制通信方案以适配复杂DL645场景

# 摘要
本文旨在全面介绍Kepware通信方案,并深入探讨DL645协议的基础知识、高级配置技巧,以及与PLC集成的实践案例。首先,文章概述了Kepware
【KepServerEX V6性能提升术】:揭秘数据交换效率翻倍策略
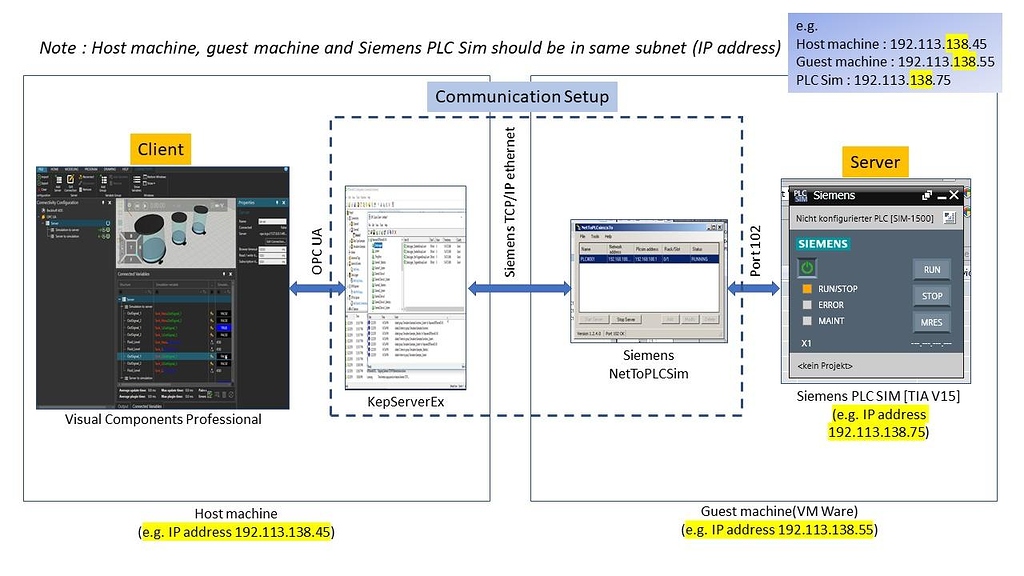
# 摘要
KepServerEX V6作为一款广泛使用的工业自动化数据集成平台,正面临性能调优和优化的严峻挑战。本文首先概述了KepServerEX V6及其面临的性能问题,随后深入解析其数据交换机制,探讨了通信协议、关键性能指标以及性能优化的理论基础。在实践章节中,我们详
STM32F103RCT6开发板同步间隔段调试:提升性能的黄金法则
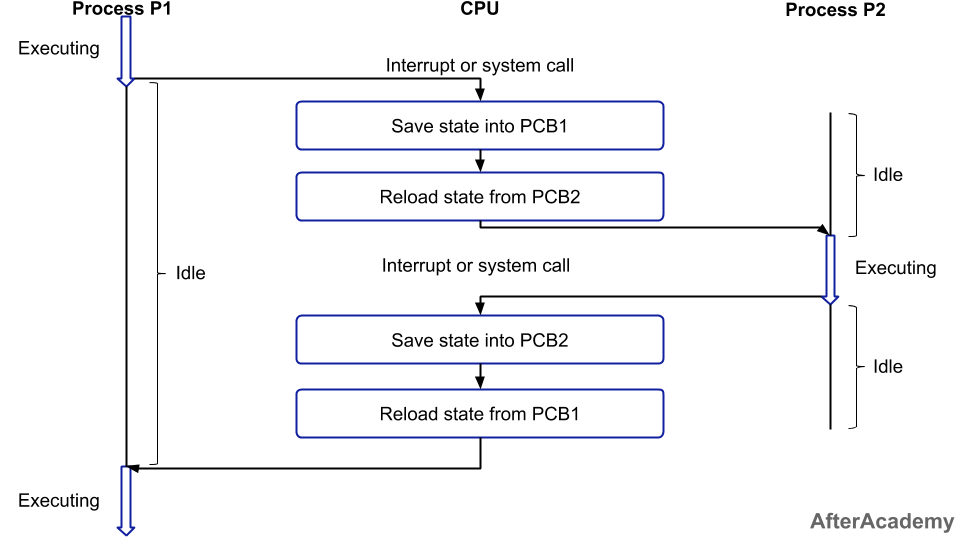
# 摘要
本文以STM32F103RCT6开发板为核心,详细介绍了同步间隔段(TIM)的基本概念、初始化、配置及高级功能,展示了如何通过调试实践优化性能。文中不仅阐述了定时器的基础理论和工作原理,还探讨了PWM和输入捕获模式的应用。通过案例研究,分析了实际应用中性能提升的实例,并提出了内存管理、代码优化和系统稳
Visual C++问题快速修复:Vivado安装手册速成版
# 摘要
本文档提供了一份全面的指南,旨在帮助读者成功安装并配置Visual C++与Vivado,这两种工具在软件开发和硬件设计领域中扮演着重要角色。从概述到高级配置,本指南涵盖了从软件安装、环境配置、项目创建、集成调试到性能优化的全过程。通过详尽的步骤和技巧,本文旨在使开发者能够高效地利用这两种工具进行软件开发和FPGA编程,从而优化工作流程并提高生产力。本指南适合初学者和有经验的工
【三菱ST段SSI编码器全攻略】:20年专家深度解析及其在工业自动化中的应用
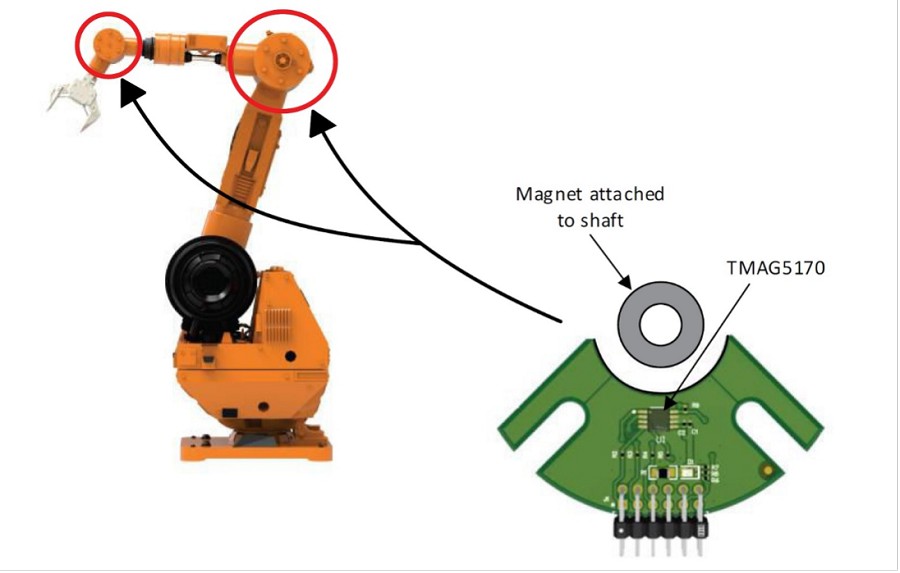
# 摘要
本文详细介绍了三菱ST段SSI编码器的基本原理、技术参数、以及在工业自动化领域的应用。通过对SSI编码器的深入分析,包括其工作原理、技术参数的精确性、速度响应、环境适应性和电气特性,本文揭示了编码器在运动控制、机器人技术及工业4.0中的关键作用。通过实战案例分析,探讨了SSI编码器在不同工业场景中的应用效果和优化经验。最后,本文探讨了SSI编码器的维护与故障排除技巧,并展望了技术发展
【Vue.js日历组件的扩展功能】:集成第三方API和外部库的解决方案

# 摘要
随着Web应用的复杂性增加,Vue.js日历组件在构
EMC VNX存储高级故障排查

# 摘要
本文对EMC VNX存储系统进行了全面的概述,从理论到实践,深入分析了其架构、故障排查的理论基础,并结合实际案例详细介绍了硬件和软件故障的诊断方法。文章进一步探讨了性能瓶颈的诊断技术,并提出了数据丢失恢复、系统级故障处理以及在复杂环境下故障排除的高级案例分析。最后,本文提出了EMC VNX存储的最佳实
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )