【Python中的JSON处理秘籍】:7个技巧提升你的数据处理效率
发布时间: 2024-10-08 22:52:08 阅读量: 216 订阅数: 66 

# 1. JSON数据格式基础
JSON(JavaScript Object Notation)是一种轻量级的数据交换格式,易于人阅读和编写,同时也易于机器解析和生成。它是基于文本的、语言无关的、并采用“键值对”方式存储数据。本章将介绍JSON的基本概念,包括其数据类型、结构以及如何在不同系统和编程语言之间传输。
JSON数据类型包括字符串(String)、数字(Number)、对象(Object)、数组(Array)、布尔值(Boolean)和null。这些类型可以通过递归嵌套的方式组合成复杂的数据结构。
- **字符串**:由双引号包围的文本序列,例如 `"hello world"`。
- **数字**:不包括引号的数值,例如 `42` 或 `3.14159`。
- **对象**:由零个或多个键值对组成的无序集合,例如 `{"name": "John", "age": 30}`。
- **数组**:由值的有序列表构成,例如 `["apple", "banana", "cherry"]`。
- **布尔值**:表示真或假的值,例如 `true` 或 `false`。
- **null**:表示无值或空值的特殊关键字。
在传输过程中,JSON格式数据通常以纯文本形式发送,可以方便地通过HTTP等协议在网络中传输。其轻量级特性使得它非常适合用于Web应用中前后端的数据交换。
```json
// 示例JSON对象
{
"name": "Alice",
"age": 25,
"isStudent": false,
"courses": ["Math", "Science"],
"address": {
"street": "123 Main St",
"city": "Wonderland"
}
}
```
在编码过程中,重要的是了解如何正确地序列化(将对象转换为JSON字符串)和反序列化(将JSON字符串转换回对象)。这在Web应用开发、移动应用的数据同步以及服务器与服务器之间的通信中尤为关键。下一章节将介绍如何在Python中使用内置的json模块来处理JSON数据。
# 2. Python中的JSON处理技巧
## 2.1 Python内置的json模块
### 2.1.1 json模块的基本使用方法
在Python中,处理JSON数据的核心工具是内置的`json`模块。这个模块提供了将JSON数据与Python对象互相转换的方法。Python的`json`模块广泛用于网络数据交换和本地数据持久化。以下是`json`模块的基本使用方法:
- `json.dumps()`: 将Python对象序列化为JSON字符串。
- `json.loads()`: 将JSON字符串反序列化为Python对象。
举个例子:
```python
import json
# 将Python字典转换为JSON字符串
data_dict = {"name": "John", "age": 30, "city": "New York"}
json_str = json.dumps(data_dict)
# 打印JSON字符串
print(json_str)
# 将JSON字符串转换回Python字典
data_dict_from_str = json.loads(json_str)
# 打印转换后的Python字典
print(data_dict_from_str)
```
### 2.1.2 json模块的高级特性
除了基本的序列化和反序列化之外,`json`模块还具有一些高级特性,可以提高数据处理的效率和灵活性:
- `json.dump()`: 将Python对象序列化为JSON字符串,并直接写入文件。
- `json.load()`: 直接从文件读取JSON字符串并反序列化为Python对象。
- `json.dump()`和`json.load()`支持流式处理,适合处理大文件。
```python
with open('data.json', 'w') as f:
json.dump(data_dict, f)
with open('data.json', 'r') as f:
data_dict_from_file = json.load(f)
```
- 使用`indent`参数控制`json.dumps()`或`json.dump()`输出的JSON字符串的格式化。
```python
print(json.dumps(data_dict, indent=4))
```
- 使用`sort_keys`参数对输出的字典键进行排序。
```python
print(json.dumps(data_dict, sort_keys=True))
```
## 2.2 Python处理JSON数据的最佳实践
### 2.2.1 格式化和美化JSON数据输出
在进行JSON数据的输出时,除了保证数据格式正确外,保持输出的可读性也是非常重要的。`json`模块的`indent`参数可以帮助我们格式化和美化JSON数据输出,从而使其更加易于阅读和调试。
```python
data = {
"employees": [
{"name": "John", "age": 30, "department": "Accounting"},
{"name": "Doe", "age": 25, "department": "IT"},
{"name": "Smith", "age": 40, "department": "Sales"}
]
}
# 格式化JSON数据
formatted_json = json.dumps(data, indent=4)
print(formatted_json)
# 将格式化的JSON数据写入文件
with open("formatted_data.json", "w") as ***
***
```
### 2.2.2 JSON数据的有效性和校验
确保JSON数据的有效性是数据处理的一个重要步骤。`json`模块提供了`json.JSONDecodeError`异常类,用于处理无效的JSON数据。同时,我们可以通过编写函数来校验JSON数据的有效性。
```python
import json
def is_valid_json(json_data):
try:
json.loads(json_data)
except json.JSONDecodeError as e:
return False
return True
# 示例JSON字符串
json_str = '{"name": "John", "age": 30, "city": "New York"}'
# 检查JSON字符串是否有效
print(is_valid_json(json_str)) # 输出: True
# 尝试一个无效的JSON字符串
invalid_json_str = '{"name": "John", "age": 30, "city": "New York"}' # 缺少闭合的大括号
print(is_valid_json(invalid_json_str)) # 输出: False
```
## 2.3 高效解析和生成JSON数据
### 2.3.1 使用object_pairs_hook进行数据解析
在处理大型JSON数据时,使用`object_pairs_hook`参数可以更高效地解析数据。该参数允许指定一个函数,该函数将被用来处理解析过程中的对象对。
```python
def dict_factory(ordered_pairs):
"""Convert an ordered list of pairs into a dictionary."""
return dict(ordered_pairs)
json_str = '{"name": "John", "age": 30, "city": "New York"}'
# 使用object_pairs_hook参数
data_dict = json.loads(json_str, object_pairs_hook=dict_factory)
print(data_dict)
```
### 2.3.2 利用iterparse实现流式解析
对于巨大的JSON文件,流式解析是处理的一种高效方式。`json`模块的`iterparse`方法可以逐个处理JSON数据中的对象,而无需将整个文件加载到内存中。
```python
import json
def process_item(item):
"""处理每个解析出的JSON对象"""
print(item)
json_str = '{"name": "John", "age": 30, "city": "New York"}'
# 使用iterparse方法
for obj in json.iterparse(json_str):
process_item(obj[1])
```
### 2.3.3 使用JSON编码和解码自定义类
有时我们需要自定义JSON数据的序列化和反序列化行为。例如,我们可以创建一个自定义类,并使用`json.JSONEncoder`的`default`方法来自定义其JSON编码逻辑。
```python
import json
class CustomJSONEncoder(json.JSONEncoder):
def default(self, obj):
if isinstance(obj, CustomClass):
# 对CustomClass实例进行特殊处理
return {"type": "CustomClass", "data": obj.data}
# 对于其他类型,使用默认行为
return json.JSONEncoder.default(self, obj)
class CustomClass:
def __init__(self, data):
self.data = data
# 创建一个CustomClass实例
custom_instance = CustomClass("Some data")
# 编码并打印结果
encoded = json.dumps(custom_instance, cls=CustomJSONEncoder)
print(encoded)
```
以上就是Python中处理JSON数据的一些技巧和最佳实践。掌握这些技术对于提高数据处理效率和保证数据质量至关重要。
# 3. JSON数据在应用中的实践应用
## 3.1 Web开发中的JSON数据交互
### 3.1.1 前后端的数据交换格式选择
在Web开发中,前后端进行数据交互时,选择合适的数据交换格式至关重要。JSON(JavaScript Object Notation)由于其轻量级和易于阅读的特点,成为了与XML竞争的主要格式。JSON之所以在Web开发中得到广泛应用,主要有以下几个原因:
- **轻量级**:JSON相比于XML,其结构更为紧凑,数据的开销小,减少了网络传输的负担。
- **语言无关性**:JSON格式的数据可以被JavaScript、Python、Java等多种语言原生支持,无需额外的解析器。
- **易于解析和生成**:大多数现代编程语言都提供了处理JSON的库,使得解析和生成JSON数据变得十分简单。
在进行前后端数据交互时,通常会使用HTTP请求,而在HTTP请求中,JSON经常作为请求体或响应体的一部分进行传输。前后端约定好数据格式和结构后,就可以通过解析JSON数据来实现业务逻辑。
### 3.1.2 使用Flask处理JSON数据
Flask是一个流行的轻量级Python Web框架,用于创建Web应用程序和服务。它支持RESTful API设计,并且很容易处理JSON数据。以下是如何使用Flask来接收和发送JSON数据的一个简单示例:
```python
from flask import Flask, jsonify, request
app = Flask(__name__)
@app.route('/get-data', methods=['GET'])
def get_data():
# 假设我们返回一个简单的字典数据作为JSON响应
data = {'message': 'Hello, World!'}
return jsonify(data) # jsonify帮助我们把Python字典转换为JSON格式
@app.route('/post-data', methods=['POST'])
def post_data():
# 获取JSON数据并解析
json_data = request.get_json()
print(json_data)
# 处理数据,例如将数据存入数据库
# ...
return jsonify({'status': 'success'}), 200 # 返回状态码和成功消息
if __name__ == '__main__':
app.run(debug=True)
```
以上代码展示了如何使用Flask框架创建两个API端点,一个用于返回JSON格式的数据,另一个用于接收JSON格式的POST请求数据。通过`request.get_json()`方法,Flask可以自动解析HTTP请求中的JSON数据。
在实际应用中,处理JSON数据时需要注意数据的安全性和验证,确保接收到的数据符合预期,避免诸如JSON注入等安全风险。同时,对于大型数据的处理,可能需要考虑异步处理和流式处理技术以提升性能。
## 3.2 数据分析中的JSON处理
### 3.2.1 使用Pandas处理JSON数据
Pandas是一个强大的Python数据分析工具库,它不仅支持DataFrame这种高级的数据结构,还提供了丰富的API来处理不同格式的数据,包括JSON。使用Pandas处理JSON数据非常方便,它提供了一个`read_json`函数来直接读取JSON文件或数据流。
下面是一个使用Pandas处理JSON数据的实例:
```python
import pandas as pd
import json
# 假设我们有一个JSON文件
json_file_path = 'data.json'
# 使用pandas读取JSON文件
df = pd.read_json(json_file_path)
# 输出DataFrame查看数据结构
print(df)
# 假设需要对数据进行一些处理,比如提取特定的列
processed_data = df[['column1', 'column2']]
# 可以将处理后的数据写回到新的JSON文件中
processed_data.to_json('processed_data.json', orient='records')
```
在上面的代码中,我们首先从`data.json`读取数据到DataFrame,然后对数据进行了处理,并将处理后的数据写入新的JSON文件。Pandas自动处理了JSON数据的解析和DataFrame之间的转换。
### 3.2.2 JSON数据的可视化技术
数据分析之后,通常需要将结果以图形或图表的形式展示给用户。Python提供了多种库来进行数据可视化,如Matplotlib、Seaborn和Plotly等。这些库可以处理Pandas DataFrame,并且能够轻松地将数据可视化为图表。
接下来的示例展示了如何使用Matplotlib将JSON数据可视化为一个简单的柱状图:
```python
import matplotlib.pyplot as plt
import pandas as pd
# 假设我们有一个包含销售数据的JSON文件
sales_data_file = 'sales_data.json'
# 使用Pandas读取数据
sales_df = pd.read_json(sales_data_file)
# 数据可视化:生成一个柱状图
sales_df.plot(kind='bar', x='Month', y='Sales')
plt.title('Monthly Sales Data')
plt.xlabel('Month')
plt.ylabel('Sales')
plt.show()
```
在这个例子中,我们首先读取了包含销售数据的JSON文件到Pandas DataFrame中,然后使用Matplotlib库生成了一个柱状图,直观地展示了每个月的销售情况。
## 3.3 移动应用中的JSON数据同步
### 3.3.1 移动端与服务器的数据交互
移动应用与服务器的数据同步是现代移动开发不可或缺的一部分。JSON由于其轻便的特性,在移动应用开发中常被用作数据交换格式。客户端和服务器之间的数据交互通常通过RESTful API进行,JSON数据在HTTP请求的body中传输。
在移动开发中,客户端发送数据到服务器的逻辑可以分为以下几个步骤:
1. 构造数据对象。
2. 将数据对象转换成JSON格式的字符串。
3. 发送HTTP请求,将JSON字符串作为请求体发送到服务器端点。
4. 服务器端解析JSON数据,执行相关操作,并返回响应。
5. 客户端解析服务器返回的JSON响应。
例如,在iOS开发中,使用Swift语言,可以利用`JSONSerialization`类来处理JSON数据。而在Android开发中,则可以使用`Gson`或`Moshi`库进行JSON的序列化和反序列化。
### 3.3.2 数据同步机制和效率优化
为了提高数据同步的效率,可以采取以下策略:
- **数据压缩**:在发送JSON数据之前,可以对数据进行压缩,减少网络传输时间。
- **缓存机制**:在客户端实现数据缓存,避免不必要的数据同步操作。
- **增量更新**:仅同步自上次同步以来发生变化的数据部分,而不是整个数据集。
- **异步处理**:在不影响用户界面响应的情况下,通过异步任务来处理数据同步。
此外,对于性能敏感的移动应用,还可以考虑使用二进制格式进行数据传输,例如Google的Protocol Buffers,它在数据大小和解析速度方面通常优于JSON。
在实际应用中,要根据业务需求、数据结构和网络条件选择最合适的同步机制。同时,要密切监控数据同步的性能指标,确保用户体验的流畅性。
通过上述实践应用的介绍,我们可以看到JSON数据在不同场景下的灵活性和效率。在Web开发中,JSON是前后端交互的标准格式;在数据分析中,Pandas和可视化工具使得从JSON到图表的转换变得简单;而在移动应用中,JSON数据同步机制确保了应用的及时性和一致性。
# 4. JSON数据处理性能优化
在处理大量数据时,性能成为了一个不可忽视的问题。JSON作为轻量级的数据交换格式,在各种应用场景中广泛使用。但是,如果处理不当,JSON的序列化和反序列化可能会成为系统性能的瓶颈。本章节将探讨如何优化JSON数据处理性能,涵盖内存使用优化、CPU负担降低、以及使用高级技术提升处理效率等策略。
## 4.1 优化JSON数据的序列化和反序列化
序列化(serialization)和反序列化(deserialization)是处理JSON数据的两个重要过程。优化这两个过程,能够显著提升应用程序的数据处理能力。
### 4.1.1 优化内存使用
在处理大型JSON数据结构时,内存管理变得尤为重要。Python的json模块在解析大型数据时可能会占用大量的内存,从而降低程序性能。为了减少内存使用,我们可以采取分批解析或流式解析的技术。
```python
import json
# 示例:使用streaming解析技术
with open('large_json_file.json', 'r') as ***
*** ''):
json_data = json.loads(chunk)
# 进行数据处理...
```
**代码解释:**
以上代码中,我们使用`with`语句确保文件正确关闭,并通过`iter`函数和`lambda`表达式来分批读取文件。`json.loads`被用于解析每一小部分(chunk)的数据,这样就可以避免一次性将整个大型文件加载到内存中。
### 4.1.2 减少CPU的计算负担
为了减少CPU负担,我们可以通过自定义解析函数或者利用json模块提供的高级特性来避免不必要的计算。
```python
import json
def custom_json_decoder(lst):
for item in lst:
# 自定义处理逻辑
yield item
json_string = '{"key": "value"}'
decoded_obj = json.loads(json_string, object_hook=custom_json_decoder)
# 进行数据处理...
```
**代码逻辑分析:**
在上面的代码示例中,我们定义了一个名为`custom_json_decoder`的函数,该函数被用作`object_hook`参数传递给`json.loads`方法。这种方法允许我们对每一个解析后的对象进行自定义处理,避免了额外的循环和条件判断,从而减少了CPU的计算负担。
## 4.2 提升数据处理效率的高级技巧
在提升JSON数据处理效率方面,我们还可以采取一些高级技术,如使用性能更优的第三方库,或者采用异步编程来优化IO操作。
### 4.2.1 使用第三方库如ujson和orjson
第三方库如`ujson`和`orjson`在性能上优于标准库的`json`模块。它们通过C语言实现,并针对解析和编码过程进行了优化。
```python
import ujson
# 使用ujson进行快速的JSON解析和编码
ujson_string = ujson.dumps({"key": "value"})
# 使用ujson.loads进行快速的JSON解析
ujson_obj = ujson.loads(ujson_string)
```
**参数说明和扩展性说明:**
在上述代码中,`ujson.dumps`用于将Python对象编码为JSON字符串,而`ujson.loads`用于将JSON字符串解析为Python对象。`ujson`库的这两个方法通常比标准的`json`模块快得多,特别是在处理大型数据时。
### 4.2.2 实践异步编程优化IO
异步编程是提升IO密集型应用性能的有效手段。Python 3.5及以上版本引入了`asyncio`库,允许我们使用`async`和`await`关键字来编写异步代码。
```python
import asyncio
import aiohttp
async def fetch(session, url):
async with session.get(url) as response:
return await response.text()
async def main():
async with aiohttp.ClientSession() as session:
html = await fetch(session, '***')
# 处理数据...
loop = asyncio.get_event_loop()
loop.run_until_complete(main())
```
**代码逻辑分析:**
在这个异步示例中,我们定义了一个`fetch`的异步函数,它使用`aiohttp`库发起HTTP请求。通过`async with`语句,我们可以保证即使在异步代码中,资源也会被正确释放。`main`函数使用`async with`来创建`aiohttp.ClientSession`,然后等待`fetch`函数完成。最后,我们获取事件循环并运行`main`函数,以启动异步操作。
通过使用异步编程,我们可以显著提高处理大量网络请求的性能,尤其是在微服务架构中,服务之间频繁交换JSON数据的场景。
本章节介绍了性能优化的多种方法和技巧,包括内存优化、CPU负担减轻以及使用第三方库和异步编程技术来提升效率。在接下来的章节中,我们将探讨JSON数据的安全风险与防护措施,确保数据处理的安全性与稳定运行。
# 5. 安全和异常处理
## 5.1 JSON数据的安全风险与防护
JSON数据因其轻量级和易读性在数据交换中广泛使用,但其安全性也是不容忽视的问题。JSON注入攻击是一个常见的安全风险,攻击者可能会在数据中嵌入恶意脚本代码,导致未预期的行为。
### 5.1.1 防止JSON注入攻击
为了防止JSON注入攻击,开发者需要采取一些预防措施。例如,在接收JSON数据时进行严格的验证,确保数据格式符合预期的规范,对于数据中的特殊字符进行转义处理。在Python中,可以使用内置的json模块提供的功能来安全地编码和解码JSON数据,例如:
```python
import json
# 安全地编码JSON数据
def safe_encode(data):
return json.dumps(data, separators=(',', ':'), ensure_ascii=False)
# 安全地解码JSON数据
def safe_decode(data):
return json.loads(data)
```
此外,服务端在解析JSON数据前,应确保只接受合法的输入,对非法输入进行拒绝,并给予相应的错误提示。
### 5.1.2 数据加密与安全传输
为了确保数据在传输过程中的安全性,可以采用SSL/TLS加密技术,保证传输通道的安全性。而在存储数据时,也应该对敏感信息进行加密处理,例如使用AES算法加密敏感字段,然后将加密结果存储到数据库中。加密和解密的过程可以使用像PyCrypto这样的库来实现。
## 5.2 处理JSON数据的异常情况
处理JSON数据时,经常会出现解析错误或者格式不匹配等问题,所以掌握如何处理这些异常情况是非常重要的。
### 5.2.1 常见的JSON处理错误及调试
在使用Python的json模块处理JSON数据时,常见的错误有:`JSONDecodeError`(解码错误)、`TypeError`(类型错误)、`ValueError`(值错误)等。
例如,在解析一个不正确的JSON字符串时,可能会抛出`JSONDecodeError`:
```python
import json
try:
data = '{"name": "John", "age": "thirty"}'
parsed_data = json.loads(data)
except json.JSONDecodeError as e:
print("解析错误:", e)
```
开发者应该仔细阅读异常信息,了解问题所在,并据此进行相应的代码调整和数据校验。
### 5.2.2 异常处理的最佳实践
为了提高代码的健壮性,应当合理使用异常处理机制。最佳实践包括:
- 预防性检查:在处理JSON数据前,先进行格式和内容的检查。
- 明确异常:只捕获那些你确定知道如何处理的异常类型。
- 记录日志:对于异常情况,除了在控制台打印,还应该记录到日志文件中,便于事后分析。
- 适当反馈:在用户界面中,应该给用户提供友好的错误提示信息,而不是晦涩难懂的错误堆栈。
```python
# 异常处理的最佳实践示例
try:
# 尝试解析JSON数据
data = '{"name": "John", "age": 30}'
parsed_data = json.loads(data)
except json.JSONDecodeError:
# 捕获JSON解析错误
log_error('JSON解码失败')
print('解析JSON数据时发生错误,请检查数据格式。')
except Exception as e:
# 捕获其他类型的异常
log_error('处理JSON数据时发生未知错误')
print('处理数据时发生未知错误。')
else:
# 在没有异常的情况下执行代码
process_data(parsed_data)
```
总之,合理处理JSON数据的异常和安全问题,对于开发出稳定、安全的应用至关重要。通过上述的措施,我们可以大大减少由于JSON数据处理不当而带来的风险。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
欢迎来到 Python 库文件学习之 JSON 专栏!本专栏深入探讨了 Python 中的 JSON 处理,提供了一系列技巧和最佳实践,帮助你提升数据处理效率。从 JSON 序列化和反序列化的深入解析,到内存优化策略和错误处理全解析,再到 JSON 与 XML 的互转和性能升级秘诀,本专栏涵盖了 JSON 处理的各个方面。此外,还提供了高级用法、数据结构转换、批量处理和优化、安全处理、异常处理和跨平台编码兼容性的实用指南。通过本专栏,你将掌握 JSON 处理的方方面面,并能有效利用 Python 的 JSON 库来处理复杂的数据交互场景。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
ODU flex故障排查:G.7044标准下的终极诊断技巧

# 摘要
本文综述了ODU flex技术在故障排查方面的应用,重点介绍了G.7044标准的基础知识及其在ODU flex故障检测中的重要性。通过对G.7044协议理论基础的探讨,本论文阐述了该协议在故障诊断中的核心作用。同时,本文还探讨了故障检测的基本方法和高级技术,并结合实践案例分析,展示了如何综合应用各种故障检测技术解决实际问题。最后,本论文展望了故障排查技术的未来发展,强调了终
环形菜单案例分析

# 摘要
环形菜单作为用户界面设计的一种创新形式,提供了不同于传统线性菜单的交互体验。本文从理论基础出发,详细介绍了环形菜单的类型、特性和交互逻辑。在实现技术章节,文章探讨了基于Web技术、原生移动应用以及跨平台框架的不同实现方法。设计实践章节则聚焦于设计流程、工具选择和案例分析,以及设计优化对用户体验的影响。测试与评估章节覆盖了测试方法、性能安全评估和用户反馈的分析。最后,本文展望
【性能优化关键】:掌握PID参数调整技巧,控制系统性能飞跃
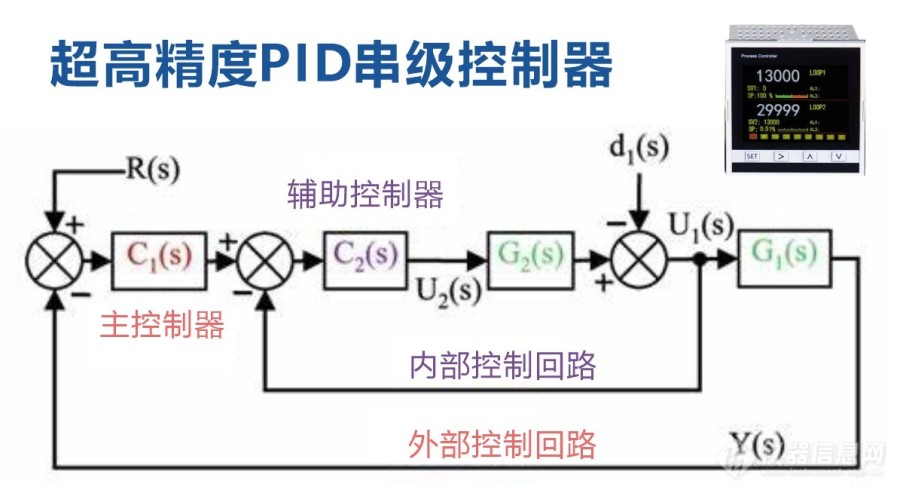
# 摘要
本文深入探讨了PID控制理论及其在工业控制系统中的应用。首先,本文回顾了PID控制的基础理论,阐明了比例(P)、积分(I)和微分(D)三个参数的作用及重要性。接着,详细分析了PID参数调整的方法,包括传统经验和计算机辅助优化算法,并探讨了自适应PID控制策略。针对PID控制系统的性能分析,本文讨论了系统稳定性、响应性能及鲁棒性,并提出相应的提升策略。在
系统稳定性提升秘籍:中控BS架构考勤系统负载均衡策略

# 摘要
本文旨在探讨中控BS架构考勤系统中负载均衡的应用与实践。首先,介绍了负载均衡的理论基础,包括定义、分类、技术以及算法原理,强调其在系统稳定性中的重要性。接着,深入分析了负载均衡策略的选取、实施与优化,并提供了基于Nginx和HAProxy的实际
【Delphi实践攻略】:百分比进度条数据绑定与同步的终极指南

# 摘要
本文针对百分比进度条的设计原理及其在Delphi环境中的数据绑定技术进行了深入研究。首先介绍了百分比进度条的基本设计原理和应用,接着详细探讨了Delphi中数据绑定的概念、实现方法及高级应用。文章还分析了进度条同步机制的理论基础,讨论了实现进度条与数据源同步的方法以及同步更新的优化策略。此外,本文提供了关于百分比进度条样式自定义与功能扩展的指导,并
【TongWeb7集群部署实战】:打造高可用性解决方案的五大关键步骤

# 摘要
本文深入探讨了高可用性解决方案的实施细节,首先对环境准备与配置进行了详细描述,涵盖硬件与网络配置、软件安装和集群节点配置。接着,重点介绍了TongWeb7集群核心组件的部署,包括集群服务配置、高可用性机制及监控与报警设置。在实际部署实践部分,本文提供了应用程序部署与测试、灾难恢复演练及持续集成与自动化部署
JY01A直流无刷IC全攻略:深入理解与高效应用

# 摘要
本文详细介绍了JY01A直流无刷IC的设计、功能和应用。文章首先概述了直流无刷电机的工作原理及其关键参数,随后探讨了JY01A IC的功能特点以及与电机集成的应用。在实践操作方面,本文讲解了JY01A IC的硬件连接、编程控制,并通过具体
先锋SC-LX59:多房间音频同步设置与优化

# 摘要
本文旨在介绍先锋SC-LX59音频系统的特点、多房间音频同步的理论基础及其在实际应用中的设置和优化。首先,文章概述了音频同步技术的重要性及工作原理,并分析了影响音频同步的网络、格式和设备性能因素。随后,针对先锋SC-LX59音频系统,详细介绍了初始配置、同步调整步骤和高级同步选项。文章进一步探讨了音频系统性能监测和质量提升策略,包括音频格式优化和环境噪音处理。最后,通过案例分析和实战演练,展示了同步技术在多品牌兼容性和创新应用
【S参数实用手册】:理论到实践的完整转换指南
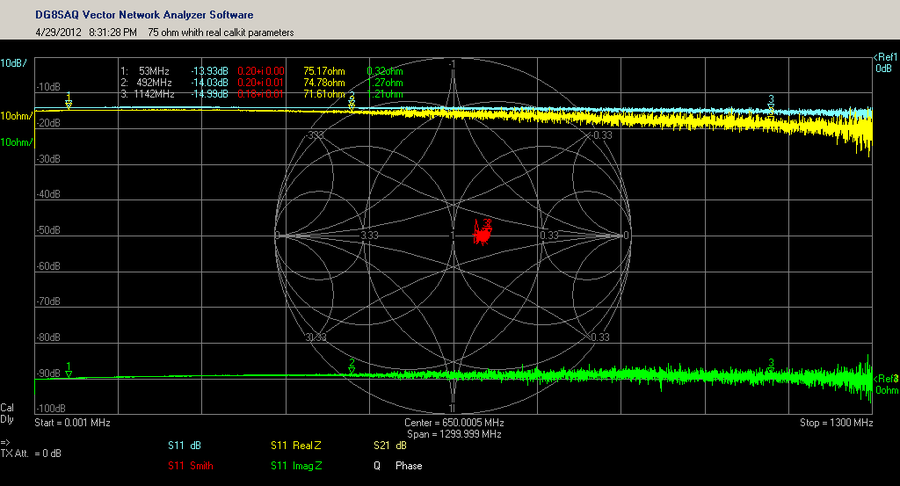
# 摘要
本文系统阐述了S参数的基础理论、测量技术、在射频电路中的应用、计算机辅助设计以及高级应用和未来发展趋势。第一章介绍了S参数的基本概念及其在射频工程中的重要性。第二章详细探讨了S参数测量的原理、实践操作以及数据处理方法。第三章分析了S参数在射频电路、滤波器和放大器设计中的具体应用。第四章进一步探讨了S参数在CAD软件中的集成应用、仿真优化以及数据管理。第五章介绍了
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )