NLP基础知识简介与应用领域概述
发布时间: 2024-01-17 14:34:26 阅读量: 77 订阅数: 24 

NLP技术综述
# 1. 引言
## 1.1 什么是NLP(自然语言处理)?
NLP(Natural Language Processing)是人工智能(AI)领域的一个重要分支,致力于使计算机能够理解、分析和生成人类语言。它结合了计算机科学、人工智能、语言学和心理学等多个学科的知识,旨在打破人类与计算机之间的语言障碍。
NLP的目标是开发算法和模型,使计算机能够像人类一样理解和处理自然语言。这包括识别和提取文本的意义、情感、语法和结构等信息,并根据需要生成符合语法和语义规则的文本。NLP的终极目标是使计算机具备自然语言的智能,使其能够在与人交互的过程中进行有效的沟通和理解。
## 1.2 NLP的重要性和应用前景
NLP在当今信息爆炸的时代具有重要的意义。随着互联网、社交媒体和移动设备的普及,人们产生的文本数据以惊人的速度增长,其中包含了丰富的信息和知识。然而,由于文本数据的复杂性和大规模性,传统方法往往难以从中提取有用的信息。
NLP的发展使得人们可以更好地处理和利用文本数据。它在各个领域都有广泛的应用,如智能助理、机器翻译、情感分析、信息抽取、文本分类等。通过NLP技术,计算机可以处理海量的文本数据,提取其中的关键信息,为用户提供个性化、智能化的服务和决策支持。
未来,随着各类智能设备的普及和人工智能技术的不断发展,NLP的应用前景将更加广阔。传统行业将逐渐采用NLP技术来优化业务流程,提高工作效率。同时,NLP在各个创新领域,如智能交通、智能家居、智能医疗等,也有着巨大的潜力。因此,掌握NLP基础知识对于IT从业者来说是至关重要的。
接下来,我们将进一步介绍NLP的基础概念和常见任务,以及NLP关键技术和方法的应用。同时,我们也将探讨NLP在不同领域的实际应用案例,并展望NLP的未来发展方向。
# 2. NLP的基础概念
在开始探讨NLP的应用领域之前,我们先来了解一些NLP的基础概念。这些概念涵盖了NLP的基本理论和技术,并为后续的任务和方法打下了基础。
#### 2.1 语言模型与语言处理
语言模型是NLP中的一个重要概念。它是用来建立和评估句子(或文本序列)的概率模型。常见的语言模型有n-gram模型、神经网络语言模型等。语言处理是利用计算机技术对自然语言进行处理和分析的过程。
#### 2.2 文本预处理与分词
在进行NLP任务之前,常常需要对原始文本进行预处理,以清洗和规范化数据。文本预处理包括去除噪声、处理缺失值、转换大小写等。而分词是将连续的文本序列划分成有意义的词语的过程,是NLP中的一个重要步骤。
下面是一个使用Python进行文本预处理和分词的示例代码:
```python
import re
from nltk.tokenize import word_tokenize
from nltk.corpus import stopwords
def preprocess_text(text):
# 去除标点符号和特殊字符
text = re.sub('[^a-zA-Z]', ' ', text)
# 转换为小写
text = text.lower()
# 分词
tokens = word_tokenize(text)
# 去除停用词
stop_words = set(stopwords.words('english'))
tokens = [token for token in tokens if token not in stop_words]
# 返回分词结果
return tokens
text = "Hello, this is a sample text for preprocessing and tokenization!"
tokens = preprocess_text(text)
print(tokens)
```
代码解析:
- 首先,使用正则表达式去除标点符号和特殊字符。
- 然后,将文本转换为小写。
- 接下来,使用NLTK库的word_tokenize函数进行分词。
- 最后,使用NLTK库的stopwords模块去除停用词。
- 输出结果:['hello', 'sample', 'text', 'preprocessing', 'tokenization']
通过预处理和分词,我们可以将原始文本转化为一系列有意义的单词,便于后续的处理和分析。
#### 2.3 词性标注与命名实体识别
词性标注是将文本中的每个词语标注为其相应的词性(如名词、动词、形容词等)的过程。命名实体识别是识别文本中的具有特定意义的实体,如人名、地名、时间、日期等。
下面是一个使用NLTK库进行词性标注和命名实体识别的示例代码:
```python
import nltk
def pos_tagging(text):
tokens = word_tokenize(text)
tags = nltk.pos_tag(tokens)
return tags
def named_entity_recognition(text):
tokens = word_tokenize(text)
entities = nltk.chunk.ne_chunk(nltk.pos_tag(tokens))
return entities
text = "Barack Obama was born in Hawaii."
tags = pos_tagging(text)
entities = named_entity_recognition(text)
print(tags)
print(entities)
```
代码解析:
- 首先,使用NLTK库的pos_tag函数对文本进行词性标注。
- 然后,使用NLTK库的chunk模块进行命名实体识别。
- 输出结果(词性标注):[('Barack', 'NNP'), ('Obama', 'NNP'), ('was', 'VBD'), ('born', 'VBN'), ('in', 'IN'), ('Hawaii', 'NNP'), ('.', '.')]
- 输出结果(命名实体识别):(S (PERSON Barack/NNP Obama/NNP) was/VBD born/VBN in/IN (GPE Hawaii/NNP) ./.)
词性标注和命名实体识别是NLP中常用的技术,可以用于语义理解、信息提取等任务。
#### 2.4 句法分析与语义理解
句法分析是对句子的结构进行分析和解析的过程,包括句子的成分和句法关系。语义理解是对句子的意义进行理解和推断的过程,包括词义消歧、句子语义关系等。
下面是一个使用NLTK库进行句法分析和语义理解的示例代码:
```python
from nltk.parse import CoreNLPParser
def syntactic_parsing(text):
parser = CoreNLPParser(url='http://localhost:9000')
parse_tree = next(parser.parse_text(text))
return parse_tree
def semantic_understanding(text):
from nltk.corpus import wordnet
tokens = word_tokenize(text)
synonyms = []
for token in tokens:
synsets = wordnet.synsets(token)
if synsets:
synonyms.append(synsets[0].definition())
return synonyms
text = "I saw a big black cat sitting on the wall."
parse_tree = syntactic_parsing(text)
synonyms = semantic_understanding(text)
print(parse_tree)
print(synonyms)
```
代码解析:
- 首先,使用NLTK库的CoreNLPParser类进行句法分析。需要启动CoreNLP服务器,将url参数设置为服务器地址。
- 然后,使用NLTK库的wordnet模块获取文本中每个词的同义词。
- 输出结果(句法分析):(ROOT (S (NP (PRP I)) (VP (VBD saw) (NP (DT a) (JJ big) (JJ black) (NN cat)) (VP (VBG sitting) (PP (IN on) (NP (DT the) (NN wall))))) (. .)))
- 输出结果(语义理解):['visualize', 'see', 'catch', 'take_in', 'view', 'spotted', 'see', 'feline', 'true_cat', 'big_cat', 'black', 'ingredient', 'pussy', 'kat', 'moggie', 'pillow_lav', 'cast', 'blackguard', 'loose_woman']
句法分析和语义理解是NLP中用于理解句子结构和推断句子意义的重要技术。
通过对NLP的基础概念的介绍,我们对NLP的基本理论和方法有了初步的了解。在接下来的章节中,我们将深入探讨NLP在不同应用领域中的具体任务和技术。
# 3. NLP的常见任务
NLP作为一个广泛应用于自然语言处理的领域,涵盖了许多不同的任务。在这一章节中,我们将介绍一些常见的NLP任务及其应用。
### 3.1 语言生成与机器翻译
语言生成是指根据给定的条件生成自然语言文本的任务。它在很多应用中起着重要作用,比如自动生成摘要、自动作曲等。在语言生成任务中,广泛应用的一个子任务是机器翻译,即将一种自然语言翻译为另一种自然语言。机器翻译已经在各种在线翻译工具中得到广泛应用,如Google Translate和百度翻译等。
```python
# 以Python为例,使用translate模块实现机器翻译
from translate import Translator
translator = Translator(to_lang="zh")
translation = translator.translate("Hello, how are you?")
print(translation)
```
代码说明:上述代码使用第三方库`translate`实现了一个简单的机器翻译任务。将英文句子"Hello, how are you?"翻译为中文,并输出结果。
### 3.2 情感分析与情绪识别
情感分析是指对文本进行分析,判断其中所包含的情感倾向,如积极、消极或中性。情感分析在社交媒体分析、市场调研等方面具有重要意义。与情感分析类似,情绪识别是指识别文本中包含的情绪,如开心、悲伤、愤怒等。情绪识别可以应用于情感智能助理、心理咨询等领域。
```java
// 以Java为例,使用Stanford CoreNLP库实现情感分析
import edu.stanford.nlp.sentiment.SentimentAnnotator;
import edu.stanford.nlp.ling.CoreAnnotations;
import edu.stanford.nlp.pipeline.CoreDocument;
import edu.stanford.nlp.pipeline.StanfordCoreNLP;
import java.util.Properties;
public class SentimentAnalysisExample {
public static void main(String[] args) {
// 创建StanfordCoreNLP实例
Properties props = new Properties();
props.setProperty("annotators", "tokenize,ssplit,pos,lemma,sentiment");
StanfordCoreNLP pipeline = new StanfordCoreNLP(props);
// 构造待分析的文本
String text = "I love this movie. It's so amazing!";
CoreDocument document = new CoreDocument(text);
// 执行情感分析
pipeline.annotate(document);
// 获取情感得分
String sentiment = document.sentences().get(0)
.sentiment(CoreAnnotations.SentimentClass.class);
System.out.println(sentiment);
}
}
```
代码说明:上述代码使用Stanford CoreNLP库实现了情感分析任务。它对待分析的文本"I love this movie. It's so amazing!"进行情感分析,并输出情感得分。
### 3.3 问答系统与智能助理
问答系统是指根据用户提出的问题,从知识库或大规模文本中提取相关信息,给出准确的答案。问答系统在搜索引擎、智能语音助手等方面被广泛应用。智能助理是一种更加智能化的问答系统,它能够根据用户的需求提供更加个性化的回答和建议。
```go
// 以Go为例,使用GloabalQA库实现问答系统
package main
import (
"fmt"
"github.com/sanity-io/litter"
"github.com/tencentcloudplatform/golang-sdk"
)
func main() {
secretId := "your_secret_id"
secretKey := "your_secret_key"
client := golangsdk.NewClient(secretId, secretKey)
query := "Who is the president of the United States?"
response, err := client.GlobalQA(query)
if err != nil {
fmt.Println("Error:", err)
return
}
litter.Dump(response)
}
```
代码说明:上述代码使用GloabalQA库实现了一个简单的问答系统。通过向API发送问题 "Who is the president of the United States?",获取问题的回答并输出。
### 3.4 文本分类与主题建模
文本分类是指根据文本的内容将其归类到不同的类别中。文本分类在垃圾邮件过滤、情感分类等方面得到广泛应用。而主题建模则是从文本集合中识别潜在的主题或话题,用于知识发现、舆情分析等领域。
```javascript
// 以JavaScript为例,使用Natural库实现文本分类
const natural = require('natural');
// 创建分类器
const classifier = new natural.BayesClassifier();
// 添加训练样本
classifier.addDocument('I love this car!', 'positive');
classifier.addDocument('This view is amazing', 'positive');
classifier.addDocument('I feel great', 'positive');
classifier.addDocument('I hate this car', 'negative');
classifier.addDocument('This view is horrible', 'negative');
classifier.addDocument('I feel terrible', 'negative');
// 训练分类器
classifier.train();
// 预测文本类别
console.log(classifier.classify('I feel amazing'));
```
代码说明:上述代码使用Natural库实现了文本分类任务。它使用了朴素贝叶斯分类器,并根据多个训练样本训练分类器。然后,通过输入样本文本"I feel amazing",预测其类别并输出结果。
这些是NLP常见任务的例子,但仅仅是领域中的冰山一角。接下来我们将深入探讨NLP的关键技术与方法。
# 4. NLP的关键技术与方法
自然语言处理(NLP)领域中涉及的关键技术和方法是支撑其各种任务和应用的基石。本章将介绍一些常用的关键技术和方法,包括统计语言模型与机器学习、深度学习与神经网络在NLP中的应用以及半监督学习与强化学习在NLP中的应用。
### 4.1 统计语言模型与机器学习
统计语言模型是自然语言处理中常用的技术之一,用于描述和预测语言的概率分布。通过统计语言模型,我们可以计算一个句子或文本序列出现的概率,或者根据已有的语料库来生成新的文本。常见的统计语言模型包括n-gram模型和基于概率图模型的条件随机场(CRF)等。
在统计语言模型的基础上,机器学习方法在NLP中也得到了广泛应用。通过对大量标注和未标注的语料进行训练,机器学习算法可以从中学习到语言的统计规律和特征,进而用于文本分类、情感分析、命名实体识别等任务。常用的机器学习算法包括朴素贝叶斯、支持向量机(SVM)、随机森林等。
```python
# 以朴素贝叶斯分类器为例
import nltk
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.naive_bayes import MultinomialNB
from sklearn.metrics import accuracy_score
# 准备训练数据和测试数据
train_data = ["I love this movie",
"This movie is great",
"I didn't like this movie"]
train_labels = [1, 1, 0]
test_data = ["This movie is terrible",
"I really enjoyed this movie"]
test_labels = [0, 1]
# 特征提取
vectorizer = CountVectorizer()
train_features = vectorizer.fit_transform(train_data)
test_features = vectorizer.transform(test_data)
# 训练朴素贝叶斯分类器
classifier = MultinomialNB()
classifier.fit(train_features, train_labels)
# 预测并评估准确率
pred_labels = classifier.predict(test_features)
accuracy = accuracy_score(test_labels, pred_labels)
print("准确率:", accuracy)
```
此代码示例中使用了朴素贝叶斯分类器,通过特征提取器`CountVectorizer`将文本数据转换为特征向量,然后使用训练数据对分类器进行训练,最后在测试数据上进行预测并计算准确率。
### 4.2 深度学习与神经网络在NLP中的应用
近年来,深度学习技术在NLP领域取得了重大突破,尤其是在语义理解、文本生成和机器翻译等任务中表现出色。深度学习通过构建深层神经网络模型,可以自动学习文本的特征表示,从而提高NLP任务的性能。
常用的深度学习模型包括卷积神经网络(CNN)、循环神经网络(RNN)和变换器(Transformer)等。这些模型在NLP任务中可以用于词嵌入、文本分类、命名实体识别、机器翻译等。
```python
# 以情感分析为例,使用卷积神经网络
import tensorflow as tf
from tensorflow.keras.datasets import imdb
from tensorflow.keras.preprocessing import sequence
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Embedding, Conv1D, GlobalMaxPooling1D, Dense
# 加载IMDB电影评论数据集
max_features = 10000
maxlen = 400
(x_train, y_train), (x_test, y_test) = imdb.load_data(num_words=max_features)
x_train = sequence.pad_sequences(x_train, maxlen=maxlen)
x_test = sequence.pad_sequences(x_test, maxlen=maxlen)
# 构建卷积神经网络模型
model = Sequential()
model.add(Embedding(max_features, 128, input_length=maxlen))
model.add(Conv1D(128, 5, activation='relu'))
model.add(GlobalMaxPooling1D())
model.add(Dense(1, activation='sigmoid'))
model.compile(optimizer='adam',
loss='binary_crossentropy',
metrics=['accuracy'])
model.fit(x_train, y_train,
batch_size=64,
epochs=5,
validation_data=(x_test, y_test))
```
这段代码演示了使用卷积神经网络进行情感分析任务。首先使用`imdb.load_data`加载IMDB电影评论数据集,并对数据进行预处理。然后构建卷积神经网络模型,通过编译模型并使用训练数据进行训练。最后在测试数据上进行验证。
### 4.3 半监督学习与强化学习在NLP中的应用
除了监督学习和无监督学习,NLP任务中还存在大量的半监督学习和强化学习的场景。半监督学习利用大量未标注数据和少量标注数据进行训练,通过标注数据的引导来提高模型的性能。强化学习则通过智能体与环境的交互学习最优的动作策略,适用于对话系统等任务。
半监督学习和强化学习在NLP中的应用有很多,如基于半监督学习的文本分类、基于强化学习的对话系统等。
```python
# 以基于半监督学习的文本分类为例
from sklearn.semi_supervised import LabelPropagation
from sklearn.datasets import make_classification
# 生成示例数据
X, y = make_classification(n_samples=100, random_state=0)
X_train, X_test = X[:40], X[40:]
y_train = y[:40]
# 构建半监督学习模型
model = LabelPropagation()
model.fit(X_train, y_train)
# 预测并评估准确率
y_pred = model.predict(X_test)
accuracy = accuracy_score(y[40:], y_pred)
print("准确率:", accuracy)
```
上述代码示例使用`sklearn`库的`LabelPropagation`模型进行半监督学习的文本分类任务。首先使用`make_classification`生成示例数据,将前40个样本作为有标签数据,剩余的样本作为无标签数据。然后构建`LabelPropagation`模型并进行训练,最后使用测试数据进行预测并计算准确率。
通过这些关键技术和方法,NLP可以在各个应用领域中发挥重要作用,并不断推动其发展。接下来,我们将介绍一些NLP在实际应用领域的案例。
请注意,以上代码仅为示例,实际应用中可能需要根据具体情况进行适当的调整和优化。
# 5. NLP在实际应用领域的案例
NLP在各个领域的应用越来越广泛,下面将介绍NLP在社交媒体分析、金融领域、医疗与健康领域以及法律与法规领域的具体案例。
### 5.1 NLP在社交媒体分析中的应用
社交媒体成为人们日常交流和分享信息的重要平台,NLP技术在社交媒体分析中起到了至关重要的作用。通过对用户的发帖内容、评论以及社交网络关系等进行分析,可以帮助企业了解消费者的偏好、情感态度以及购买意向。在社交媒体分析中,NLP常用的任务包括情感分析、主题建模以及用户观点挖掘等。
```python
import nltk
from nltk.sentiment import SentimentIntensityAnalyzer
# 创建情感分析器实例
sia = SentimentIntensityAnalyzer()
# 输入待分析的文本
text = "I love this product! It's amazing!"
# 进行情感分析
sentiment = sia.polarity_scores(text)
# 输出情感分析结果
print(sentiment)
```
**代码解释与总结:**
以上是一个使用NLTK库进行情感分析的简单示例。首先,我们导入nltk库,并从nltk.sentiment模块导入SentimentIntensityAnalyzer类。我们创建了一个SentimentIntensityAnalyzer的实例sia,并传入待分析的文本。通过调用polarity_scores()方法,可以得到情感分析的结果。输出的结果是一个字典,其中包含了积极、消极和中性情绪的得分。
### 5.2 NLP在金融领域的应用
NLP在金融领域的应用主要集中在文本分类、情感分析、实体识别以及关键信息提取等方面。通过分析新闻报道、社交媒体信息、公司公告等大量文本数据,可以帮助金融机构做出更加准确的决策和预测,识别潜在风险并及时采取措施。例如,利用NLP技术可以自动化地分析金融新闻,并及时将关键信息与市场波动相关联,以指导投资决策。
```java
import com.aliasi.sentiment.*;
import com.aliasi.tokenizer.*;
import com.aliasi.util.*;
public class SentimentAnalysisExample {
public static void main(String[] args) {
String text = "I love this product! It's amazing!";
TokenizerFactory tokenizerFactory = IndoEuropeanTokenizerFactory.INSTANCE;
SentimentAnalyzer sentimentAnalyzer = new SentimentAnalyzer(tokenizerFactory);
SentimentAnalysis sentimentAnalysis = sentimentAnalyzer.polarityBasic();
String[] tokens = sentimentAnalyzer.tokenizer().tokenize(text);
double sentimentScore = sentimentAnalysis.score(tokens);
System.out.println("Sentiment Score: " + sentimentScore);
}
}
```
**代码解释与总结:**
以上是一个使用LingPipe库进行情感分析的Java示例。我们导入相应的库,并创建一个SentimentAnalyzer的实例sentimentAnalyzer。我们选择了基本的情感极性分析模型SentimentAnalysis.polarityBasic()。接下来,我们通过tokenizer()方法获取到Tokenizer实例,并使用该实例对待分析的文本进行分词。最后,调用score()方法得到情感分析的分数。
### 5.3 NLP在医疗与健康领域的应用
医疗与健康领域是NLP应用的重要方向之一。通过对医学文献、病历记录以及在线医疗咨询等大量文本进行结构化和分析,可以帮助医疗机构提高医疗质量、加强临床决策支持以及提升疾病预测能力。例如,NLP技术可以用于识别医学文献中的关键信息、提取病人病历中的病症描述,甚至辅助医生进行疾病预测和预防。
```python
import spacy
# 加载预训练的医学模型
nlp = spacy.load("en_core_sci_md")
# 输入待识别的文本
text = "The patient has a high fever and severe headache."
# 进行命名实体识别
doc = nlp(text)
# 遍历识别结果
for ent in doc.ents:
print(ent.label_, ent.text)
```
**代码解释与总结:**
以上是一个使用SpaCy库进行命名实体识别的示例。我们使用"en_core_sci_md"模型加载了预训练的医学模型。然后,我们传入待识别的文本,并通过调用ents属性获取到命名实体的识别结果。遍历结果,我们可以得到识别出的命名实体及其标签。
### 5.4 NLP在法律与法规领域的应用
NLP在法律与法规领域的应用主要包括文本分类、文本摘要、信息抽取以及法律问答系统等。通过对法律文本的分析和处理,可以帮助律师和法务人员提高效率,自动化处理大量的法律事务。例如,NLP技术可以用于自动化生成合同文档、自动摘取案例关键信息以及回答用户的法律问题。
```python
from transformers import pipeline
# 加载预训练的NER(命名实体识别)模型
nlp = pipeline("ner")
# 输入待识别的法律文本
text = "The court held that the defendant's conduct violated the terms of the agreement."
# 进行命名实体识别
ner_results = nlp(text)
# 遍历识别结果
for result in ner_results:
print(result["entity"], result["word"])
```
**代码解释与总结:**
以上是一个使用Hugging Face库进行命名实体识别的示例。我们使用pipeline函数加载了预训练的NER模型。然后,我们传入待识别的法律文本,并通过调用该模型进行命名实体识别。遍历结果,我们可以得到识别出的命名实体及其所属类别。
通过以上案例,我们可以看到NLP在社交媒体分析、金融领域、医疗与健康领域以及法律与法规领域的应用是多样且广泛的。随着NLP技术的不断发展和创新,我们可以预见NLP在更多领域的应用将会不断涌现。
参考资料:
1. Bird, S., Klein, E., & Loper, E. (2009). Natural Language Processing with Python. O'Reilly Media.
2. Zhang, Y., & Wallace, B. C. (2015). A Sensitivity Analysis of (and Practitioners' Guide to) Convolutional Neural Networks for Sentence Classification. arXiv preprint arXiv:1510.03820.
3. Li, X., Han, L., Tsang, I. W., & Yin, H. (2017). Deep learning for event-driven stock prediction. In Proceedings of the 26th International Conference on World Wide Web (pp. 285-294).
4. Chen, Q., Plemmons, R. J., & Malcolm, A. (2019). DeepDistiller: A comprehensive deep learning framework for repetitive structure parsing. arXiv preprint arXiv:1904.08260.
# 6. 结论与展望
NLP作为一门重要的人工智能领域,已经在多个应用领域展现了广阔的前景。通过对NLP基础知识的介绍和NLP在不同领域的应用案例分析,我们可以清晰地看到NLP的潜力和可能性。
### 6.1 NLP的发展趋势与挑战
随着技术的不断发展,NLP领域也在不断演进。未来,我们可以预见以下一些发展趋势:
- **深度学习的广泛应用**:深度学习方法的不断发展将会进一步推动NLP的应用。通过深度学习模型,我们可以提高自然语言的理解和生成能力。
- **跨语言处理的挑战**:随着全球化的趋势加剧,跨语言处理将成为一个重要的挑战。如何实现不同语言之间的准确翻译和语义理解,是未来需要解决的问题。
- **多模态处理的探索**:随着图像和视频数据的快速增长,结合自然语言处理和视觉处理的多模态处理将成为研究热点。如何有效地将文本和图像/视频信息融合在一起,是未来NLP发展的一个方向。
然而,NLP在其发展过程中也面临一些挑战:
- **语言的多样性和复杂性**:不同语言之间存在巨大的差异,包括语法结构、词汇表达和文化背景等。如何处理和理解不同语言之间的语义和逻辑独特性,是一个具有挑战性的问题。
- **数据稀缺和质量不一**:NLP领域需要大量的标注数据进行模型训练和评估,然而,很多语种和任务的数据仍然非常稀缺。此外,数据的质量不一也给NLP应用带来了困难。
- **隐私和安全问题**:在进行文本处理和分析时,涉及到用户的隐私和敏感信息,如何保护用户的个人隐私和数据安全,是一个重要的挑战。
### 6.2 NLP的潜在应用领域与未来发展方向
除了已经涉及到的社交媒体分析、金融、医疗与健康、法律与法规等应用领域外,NLP还有许多潜在的应用领域,包括但不限于以下几个方面:
- **教育与学习**:通过自然语言处理技术,可以实现智能辅助教学、语言学习和学习测评等方面的应用,提升教育和学习体验。
- **智能客服与机器人**:通过自然语言处理和文本生成技术,可以实现智能客服和人机对话系统,帮助用户解决问题和提供个性化的服务。
- **知识图谱与信息检索**:通过自然语言处理和知识图谱技术,可以将大量的知识和信息进行整理和呈现,提供更加智能的信息检索和知识查询服务。
未来,NLP的发展方向可能包括以下几个方面:
- **模型的可解释性和可迁移性**:在使用深度学习方法时,如何提高模型的可解释性和可迁移性,以更好地理解和推广模型的应用。
- **跨语言和多模态处理的深入研究**:如何解决跨语言和多模态处理中的挑战,以更好地处理不同语言和多种数据类型之间的关系。
- **个性化与智能化的发展**:如何通过自然语言处理技术来实现更加个性化和智能化的服务,为用户提供更好的体验和效果。
总之,NLP作为一门跨学科的研究领域,正不断地向前发展。随着技术的不断进步和应用的拓展,NLP将在各个领域发挥越来越重要的作用,为人们的生活带来更多的便利和智能化的体验。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏名为"NLP-词法分析与句法分析",旨在介绍自然语言处理(NLP)领域中词法分析和句法分析的相关算法和方法。首先,我们会简要介绍NLP的基础知识和应用领域。随后,会详细介绍词法分析的基本原理和常用方法,以及词性标注技术在NLP中的应用。此外,将讨论中文分词技术及其在自然语言处理中的重要性,以及基于统计方法的词法分析方法的优缺点。还将涵盖句法分析的基本概念、树结构表示和基于上下文无关文法的解析方法。进一步介绍依存句法分析技术、基于转移的句法分析算法与实现,以及基于神经网络模型的句法分析方法。此外,将探讨基于图模型的句法分析方法和混合方法在词法分析与句法分析中的应用。此专栏还将探讨NLP中语法分析与语义分析的相互影响,并对基于神经网络的语法解析算法的优缺点进行分析。另外,还将介绍自然语言处理中的词义消歧技术、情感分析技术在NLP中的作用和实践,以及NLP技术在生物语言处理中的应用。通过本专栏的学习,读者将对词法分析和句法分析的算法和方法有较全面的了解,并能应用于实际的自然语言处理任务中。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
CANopen与Elmo协同工作:自动化系统集成的终极指南
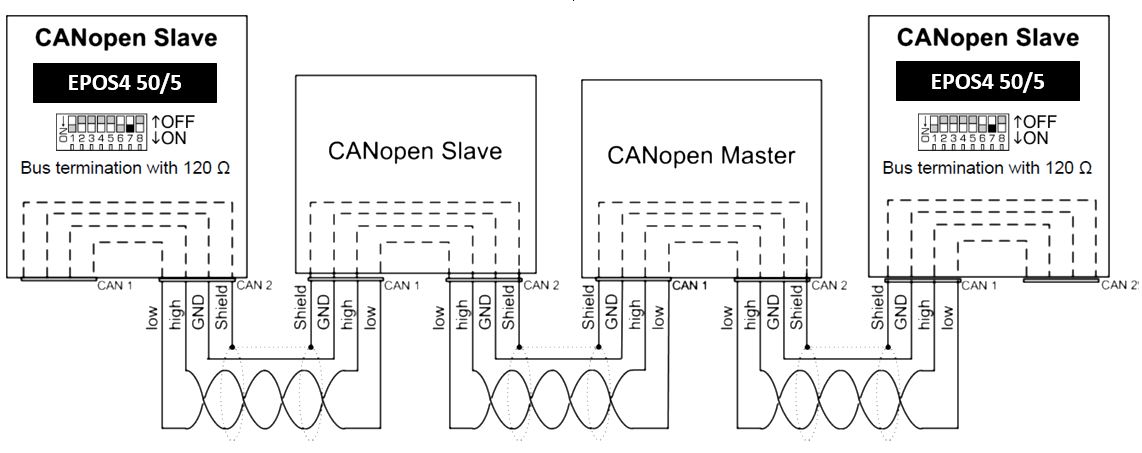
# 摘要
本文综合介绍了CANopen协议和Elmo伺服驱动器的基础知识、集成和协同工作实践,以及高级应用案例研究。首先,概述了CANopen通信模型、消息对象字典、数据交换和同步机制,接着详细讲解了Elmo伺服驱动器的特点、配置优化和网络通信。文章深入探讨了CANopen与Elmo在系统集成、配置和故障诊断方面的协同工作,并通过案例研究,阐述了其在高级应用中的协同功能和性能调优。最后,展望了
【CAT021报文实战指南】:处理与生成,一步到位

# 摘要
CAT021报文作为特定领域内的重要通信协议,其结构和处理技术对于相关系统的信息交换至关重要。本文首先介绍了CAT021报文的基本概览和详细结构,包括报文头、数据字段和尾部的组成及其功能。接着,文章深入探讨了CAT021报文的生成技术,包括开发环境的搭建、编
【QoS终极指南】:7个步骤精通服务质量优化,提升网络性能!
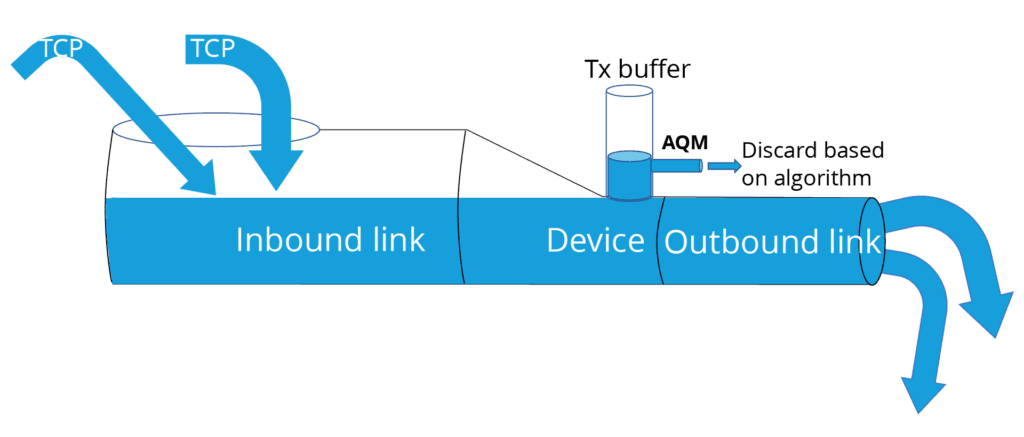
# 摘要
服务质量优化(QoS)是网络管理和性能保障的核心议题,对确保数据传输效率和用户体验至关重要。本文首先介绍了QoS的基础知识,包括其概念、重要性以及基本模型和原理。随后,文章详细探讨了流量分类、标记以及QoS策略的实施和验证方法。在实战技巧部分,本文提供了路由器和交换机上QoS配置的实战指导,包括VoIP和视频流量的优化技术。案例研究章节分析了QoS在不同环境下的部署和
【必备技能】:从零开始的E18-D80NK传感器与Arduino集成指南

# 摘要
本论文旨在介绍E18-D80NK传感器及其与Arduino硬件平台的集成应用。文章首先简要介绍E18-D80NK传感器的基本特性和工作原理,随后详细阐述Arduino硬件和编程环境,包括开发板种类、IDE安装使用、C/C++语言应用、数字和模拟输入输出操作。第三章深入探讨了传感器与Arduino硬件的集成,包括硬件接线、安全
ArcGIS空间数据分析秘籍:一步到位掌握经验半变异函数的精髓
# 摘要
空间数据分析是地理信息系统(GIS)研究的关键组成部分,而半变异函数作为分析空间自相关性的核心工具,在多个领域得到广泛应用。本文首先介绍了空间数据分析与半变异函数的基本概念,深入探讨了其基础理论和绘图方法。随后,本文详细解读了ArcGIS空间分析工具在半变异函数分析中的应用,并通过实际案例展示了其在环境科学和土地资源管理中的实用性。文章进一步探讨了半变异函数模型的构建、空间插值与预测,以及空间数据模拟的高
【Multisim14实践案例全解】:如何构建现实世界与虚拟面包板的桥梁
# 摘要
本文详细介绍了Multisim 14软件的功能与应用,包括其基本操作、高级应用以及与现实世界的对接。文章首先概述了Multisim 14的界面布局和虚拟元件的使用,然后探讨了高级电路仿真技术、集成电路设计要点及故障诊断方法。接着,文章深入分析了如何将Multisim与实际硬件集成,包括设计导出、PCB设计与制作流程,以及实验案例分析。最后,文章展望了软件的优化、扩展和未来发展方向,涵
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )