【R语言数据处理新手必备】:mlr包基础使用与案例分析的全面解读
发布时间: 2024-11-02 15:22:48 阅读量: 61 订阅数: 22 

R语言数据分析的概要介绍与分析

# 1. R语言与mlr包概述
R语言作为数据分析领域的翘楚,它强大的统计分析功能和灵活的图形表现力,赢得了广泛的数据科学家的青睐。mlr包(Machine Learning in R),作为R语言中非常流行的机器学习框架,为用户提供了统一的操作接口,简化了复杂机器学习算法的实现过程。
mlr包不仅涵盖了大多数经典机器学习算法,还支持多种学习任务,如分类、回归和聚类等。它具备高度的可扩展性,用户可以通过简单的配置,即可实现各种高级的机器学习功能。不仅如此,mlr还提供了自动化模型选择与参数调优的工具,极大地提高了机器学习工作的效率。
在本章中,我们将从R语言与mlr包的基础知识入手,逐步引导读者进入机器学习的世界,并为后续章节深入探讨mlr包的功能与应用打下坚实的基础。
# 2. mlr包基础操作
## 2.1 mlr包的安装与加载
### 2.1.1 安装mlr包的方法
在R语言的生态系统中,`mlr`(Machine Learning in R)包是一个功能强大的机器学习框架,它允许用户方便地应用、比较和组合多种机器学习算法。为了使用`mlr`包,首先需要将其安装到R环境中。安装过程非常直接:
```r
install.packages("mlr")
```
该命令会从CRAN(Comprehensive R Archive Network)下载最新版本的`mlr`包,并安装到当前的R环境中。如果你需要安装开发版本的`mlr`,可以访问其GitHub仓库,并使用`devtools`包进行安装。
```r
if (!requireNamespace("devtools", quietly = TRUE))
install.packages("devtools")
devtools::install_github("mlr-org/mlr")
```
安装`mlr`包时,请确保网络连接正常,并耐心等待下载和安装过程完成。安装完毕后,`mlr`包就可以在R会话中使用了。
### 2.1.2 加载mlr包的步骤
安装`mlr`包之后,需要将其加载到R会话中,以便开始使用其功能。加载`mlr`包的命令如下:
```r
library(mlr)
```
该命令会将`mlr`包中的函数和方法加载到当前的R环境中。如果包已经安装,但你遇到了加载错误,那可能是因为包未正确安装或与其他包冲突。可以通过`require`函数检查包是否安装成功:
```r
require(mlr)
```
如果返回的是`TRUE`,表示包已成功加载。此时,你可以开始使用`mlr`包提供的各种机器学习功能了。
## 2.2 mlr包中的学习任务和任务类型
### 2.2.1 学习任务的创建
在`mlr`包中,所有机器学习任务都是以“学习任务”(Task)的形式定义的。学习任务定义了数据集及其相关特征,以及所要解决的问题类型(例如分类、回归或聚类)。创建一个学习任务的基本语法如下:
```r
task = makeTask(id = "example", backend = data, target = "class")
```
在这个例子中,`makeTask`函数用于创建一个新的学习任务。参数`id`用于指定任务的名称,`backend`是指向数据集的指针,`target`则是指定了因变量列名,即我们想要预测的目标变量。
### 2.2.2 任务类型详解
`mlr`包支持多种类型的学习任务,每种类型对应着不同的机器学习问题:
- **分类任务(Classification)**:目标变量是离散的,用于处理如垃圾邮件识别或疾病诊断这样的问题。
- **回归任务(Regression)**:目标变量是连续的,例如房价预测或股票价格预测。
- **聚类任务(Cluster Analysis)**:没有目标变量,用于发现数据中的自然分组。
- **生存分析任务(Survival Analysis)**:目标变量包含时间至事件发生的持续时间和事件是否发生的信息。
- **多标记分类任务(Multilabel Classification)**:单个实例可能被分配多个类别标签。
创建任务时,需要选择合适的任务类型函数。例如,对于分类任务,你会使用`makeClassifTask`,对于回归任务,则使用`makeRegrTask`等。
## 2.3 mlr包中的学习方法
### 2.3.1 支持的算法概览
`mlr`包提供了多种学习算法,覆盖了从简单的线性模型到复杂集成方法的广泛范围。算法可以分为以下几类:
- **基础算法**:包括线性回归、逻辑回归、k-最近邻等。
- **集成方法**:如随机森林、梯度提升机(GBM)和极端随机树(ExtraTrees)。
- **支持向量机(SVM)**:包括线性和非线性SVM。
- **神经网络**:通过`nnet`包提供的神经网络。
- **贝叶斯方法**:如贝叶斯线性回归等。
要查看`mlr`支持的所有算法,可以使用以下命令:
```r
listLearners()
```
### 2.3.2 方法的选择与使用
选择合适的学习方法取决于任务的性质和数据的特性。例如,对于小规模数据集,简单的线性模型可能是一个好的起点。然而,对于复杂的模式识别问题,集成方法可能更有效。
在`mlr`中,算法以“学习器”(Learner)的形式呈现,可以这样创建一个学习器实例:
```r
learner = makeLearner("classif.rpart")
```
这里,`makeLearner`函数用于创建一个新的学习器对象,`"classif.rpart"`指定了使用`rpart`包中的分类树算法。
接下来,可以使用`train`函数来训练模型:
```r
model = train(learner, task)
```
`model`对象现在包含了训练好的模型,可以用于进行预测或评估模型性能。
## 2.4 mlr包中的模型评估
### 2.4.1 评估指标的选择
模型评估是机器学习中的重要环节,它允许我们量化模型在训练数据集外的预测能力。`mlr`提供了多种评估指标,如:
- **分类任务**:准确率(Accuracy)、精确率(Precision)、召回率(Recall)、F1分数等。
- **回归任务**:均方误差(MSE)、均方根误差(RMSE)、决定系数(R²)等。
- **聚类任务**:轮廓系数(Silhouette Coefficient)、Davies-Bouldin指数等。
- **生存分析任务**:Harrell's C指数、Brier分数等。
选择适合的评估指标需要考虑任务类型以及业务目标。例如,在不平衡数据集中,准确率可能不是最佳指标,此时应选择能够考虑类别分布不均的指标。
### 2.4.2 模型性能的评估方法
`mlr`提供了`resample`函数,用于对模型进行交叉验证评估,这是评估模型性能的常用方法。`resample`函数将数据集划分为训练集和测试集,并重复这个过程多次,计算平均评估指标:
```r
rdesc = makeResampleDesc(method = "CV", iters = 10)
r = resample(learner, task, rdesc, measures = list(acc))
```
在这个例子中,我们使用10折交叉验证(`"CV"`),并指定了准确率(`acc`)作为评估指标。
输出的`r`对象包含了所有迭代的性能结果,可以通过汇总这些结果来分析模型的整体性能。
在接下来的章节中,我们将进一步探索`mlr`包的实践应用,并通过实际案例加深对这些概念的理解。
# 3. mlr包的实践应用
## 3.1 数据预处理
### 3.1.1 数据集的加载与查看
在机器学习项目中,数据的加载和初步查看是至关重要的第一步。在mlr包中,可以使用`read.csv`、`data.table`或`readr`等R语言流行的包来加载数据集,然后利用mlr包的功能对数据进行查看和了解。
```r
# 使用read.csv加载数据
data <- read.csv("data.csv")
# 使用mlr包中的makeTask来创建学习任务
library(mlr)
task <- makeClassifTask(data = data, target = "class_column")
```
在上述代码中,首先加载了一个名为`data.csv`的数据集。之后,使用`makeClassifTask`函数,以数据集和目标列名称创建了一个分类学习任务。mlr包中的学习任务是一个包含了数据和相关元数据的复杂结构,有助于算法更有效地处理数据。
### 3.1.2 数据清洗与转换
数据清洗和转换是机器学习预处理的重要组成部分。mlr包提供了多种数据操作工具,如数据类型转换、缺失值处理、异常值检测和特征提取等。
```r
# 查找并处理缺失值
task <- addMissings(task)
# 将因子变量转换为数值变量
task <- convertFeatures(task, method = "class2num")
# 查看处理后的数据
getTaskData(task)
```
在数据清洗的代码示例中,`addMissings`函数用于向任务中添加缺失值信息,然后使用`convertFeatures`函数将因子变量转换为数值型,最后使用`getTaskData`函数查看处理后的数据。这些步骤对于确保数据质量,进而提高模型性能至关重要。
## 3.2 特征工程
### 3.2.1 特征选择方法
特征选择对于提高机器学习模型的性能至关重要,因为多余的特征可能导致过拟合,而遗漏重要特征则可能降低模型准确性。mlr包提供了多种特征选择方法,包括过滤法、封装法和嵌入法。
```r
# 使用相关系数作为过滤方法进行特征选择
ctrl <- makeFilterControl(method = "quadratic")
filter <- filterFeatures(task, method = "correlation", control = ctrl)
selected_features <- getFilteredFeatures(filter)
# 查看选择后的特征
print(selected_features)
```
上述代码使用了过滤法中的相关系数方法,通过`filterFeatures`函数选择相关性高的特征,并通过`getFilteredFeatures`函数查看选择的特征。
### 3.2.2 特征构造技术
特征构造是通过已有特征生成新的特征,这可以提高模型的表达能力。mlr包支持包括主成分分析(PCA)在内的多种构造技术。
```r
# 使用PCA构造新特征
pca <- prcomp(getTaskData(task), scale. = TRUE)
new_features <- predict(pca, getTaskData(task))[, 1:2] # 选择前两个主成分
# 将新构造的特征添加到任务中
task <- updateTask(task, new_features)
```
在这个例子中,`prcomp`函数用于执行PCA分析,然后选择前两个主成分作为新特征,最后使用`updateTask`函数将新特征添加到原有任务中。通过这种方式,可以扩展原有的特征空间,提升模型性能。
## 3.3 模型训练与调优
### 3.3.1 训练过程的基本步骤
在mlr包中,模型训练主要通过创建学习器(Learner),然后使用该学习器对任务进行训练来完成。
```r
# 创建学习器
learner <- makeLearner("classif.rpart", predict.type = "prob")
# 训练模型
model <- train(learner, task)
# 查看训练得到的模型
print(model)
```
上述代码首先通过`makeLearner`函数创建了一个决策树分类器,设置预测类型为概率形式。然后,使用`train`函数进行模型训练。最后,使用`print`函数查看训练得到的模型对象。
### 3.3.2 参数调优的策略
参数调优是提高模型性能的关键步骤之一。mlr包提供了网格搜索、随机搜索和模型选择等策略。
```r
# 使用网格搜索进行参数优化
ps <- makeParamSet(
makeNumericParam("cp", lower = 0.001, upper = 0.1)
)
ctrl <- makeTuneControlGrid()
res <- tuneParams(learner, task, par.set = ps, control = ctrl, measures = acc)
# 查看最优参数
print(res$x)
```
在这个例子中,首先通过`makeParamSet`函数定义了需要优化的参数`cp`(复杂度参数),接着通过`makeTuneControlGrid`函数设置了网格搜索的优化策略。使用`tuneParams`函数进行模型参数的网格搜索,并通过`measures`参数指定了优化的指标为准确率(accuracy)。最后,使用`print`函数输出最优参数。
## 3.4 模型的解释与可视化
### 3.4.1 模型结果的解释
模型结果的解释是确保模型可解释性和公正性的重要环节。在mlr包中,可以通过各种方法来解释模型的行为和预测结果。
```r
# 预测并获取模型结果
predictions <- predict(model, task)
# 解释模型结果
explain <- getLearnerModel(model)
print(explain)
```
上述代码通过`predict`函数对任务进行预测,得到预测结果。然后,使用`getLearnerModel`函数获取模型内部结构,可以帮助我们理解模型是如何做出预测的。
### 3.4.2 结果可视化的方法
可视化可以帮助我们直观地理解模型的性能和决策边界。
```r
# 绘制ROC曲线
plotROCCurve(predictions)
# 绘制学习曲线
plotLearningCurve(learner, task)
```
在上述示例中,`plotROCCurve`函数用于绘制接收者操作特征(ROC)曲线,这有助于评估模型在不同分类阈值下的性能。`plotLearningCurve`函数绘制学习曲线,可以观察模型随着训练数据量增加的性能变化。
以上是本章节关于mlr包实践应用的详细介绍,涵盖了数据预处理、特征工程、模型训练与调优以及模型解释与可视化的重要环节。在下一章节中,我们将深入探讨mlr包的具体案例分析,以实例化的方式进一步理解mlr包在不同机器学习任务中的应用和效果。
# 4. mlr包案例分析
## 4.1 分类问题案例
### 4.1.1 数据准备与预处理
在分类问题案例的介绍中,数据的准备与预处理是至关重要的步骤。在这个阶段,我们将对数据集进行详细的探索,以及进行必要的数据清洗与转换操作,确保数据质量。
首先,我们需要从各种数据源加载数据集。比如,如果数据存储在CSV文件中,我们可以使用`read.csv`函数来加载数据:
```R
data <- read.csv("path_to_dataset.csv")
```
加载数据后,我们进行初步的检查,查看数据集的基本信息,包括每列的数据类型、缺失值情况等:
```R
str(data)
summary(data)
```
在数据预处理阶段,我们可能会进行以下几个步骤:
- 处理缺失值:对于分类问题,缺失值处理尤其重要。常用的方法包括删除含有缺失值的行,或用均值、中位数、众数等填充。
- 数据标准化:通过将数据缩放到特定的范围,比如0到1,或标准化到均值为0,标准差为1的分布,从而消除不同量纲的影响。
- 转换类别变量:如果数据集中有类别变量,我们可能需要将其转换为虚拟变量(dummy variables)以便于后续处理。
### 4.1.2 分类器的选择与训练
在数据准备和预处理之后,下一步是选择合适的分类器进行训练。mlr包支持多种分类算法,包括逻辑回归、支持向量机(SVM)、决策树、随机森林等。
在选择分类器时,我们需要考虑问题的特点以及数据集的特性。例如,在不平衡数据集上,某些算法可能表现得更好,或者在高度相关的特征集中,我们可能倾向于使用具有正则化特征的模型。
选择分类器之后,使用`makeLearner`函数创建学习器对象,然后使用`train`函数训练模型。这里以逻辑回归为例:
```R
# 创建学习器对象
lr_learner <- makeLearner("classif.logreg", predict.type = "prob")
# 训练模型
lr_model <- train(learner = lr_learner, task = data_task)
```
### 4.1.3 模型评估与优化
模型训练完成后,我们需评估模型的性能,进而进行优化。mlr包提供了多种评估指标,比如准确率(accuracy)、精确率(precision)、召回率(recall)等。
评估模型时,我们可以直接使用`performance`函数来获取指标值:
```R
# 计算性能
perf <- performance(lr_model, measures = list(acc, prec, rec))
```
模型优化通常涉及参数调优。在mlr包中,我们可以使用交叉验证和网格搜索等技术来找到最佳的参数组合。通过`train`函数可以实现这一点:
```R
# 设置参数网格
param_grid <- makeParamSet(
makeIntegerParam("maxit", lower = 100, upper = 500),
makeNumericParam("alpha", lower = 0.001, upper = 0.1)
)
# 交叉验证与网格搜索
ctrl <- makeTuneControlGrid()
tuned_model <- tuneParams(learner = lr_learner, task = data_task,
resampling = makeResampleDesc("CV", iters = 10),
par.set = param_grid, control = ctrl)
```
在以上代码中,我们通过指定`makeParamSet`来定义参数网格,并用`makeTuneControlGrid`来设置网格搜索策略。最后通过`tuneParams`来执行参数调优过程。
通过本章节的介绍,我们展示了如何使用mlr包来解决一个分类问题,从数据准备、预处理,到分类器的选择和训练,以及最终的模型评估和优化。在接下来的小节中,我们将探索如何利用mlr包处理回归问题和多标签学习案例。
# 5. mlr包进阶技巧与扩展应用
## 5.1 mlr包的高级参数设置
在机器学习和数据分析中,高级参数设置是提升模型性能的关键。mlr包提供了许多可调节的参数,可以更细致地控制学习过程和模型训练。
### 5.1.1 参数优化空间的理解
理解参数优化空间包括识别哪些参数是影响模型性能的关键因素。例如,在训练一个随机森林模型时,可能需要调整`num.trees`(树的数量)、`mtry`(每次分裂时考虑的特征数量)等参数。
### 5.1.2 进阶参数设置示例
下面是一个使用`makeLearner`函数设置随机森林学习器参数的代码示例:
```r
# 加载mlr包
library(mlr)
# 创建一个随机森林学习器
rf.learner <- makeLearner(
cl = "classif.randomForest",
predict.type = "prob",
par.vals = list(num.trees = 500, mtry = 3)
)
# 列印学习器参数,确认设置
print(rf.learner)
```
在上面的代码中,我们设置了`num.trees=500`以增加树的数量来提高模型的稳定性,`mtry=3`表示在每次分裂时考虑3个特征。通过适当调整这些参数,我们可以获得更好的预测性能。
## 5.2 mlr包的集成学习
集成学习是一种强大的技术,它结合了多个模型来解决同一问题,以期获得比单个模型更优的预测性能。
### 5.2.1 集成学习方法的介绍
集成学习方法如Bagging、Boosting、Stacking等,在mlr中都可以通过简单的设置实现。mlr支持像随机森林、AdaBoost等著名的集成学习算法。
### 5.2.2 集成模型的构建与评估
下面是一个构建随机森林集成模型并评估其性能的例子:
```r
# 设置随机森林学习器
rf.learner <- makeLearner(
cl = "classif.randomForest",
predict.type = "prob"
)
# 创建一个集成学习器,使用5个随机森林作为基学习器
set.seed(123)
rf.ens.learner <- makeEnsemble(
learners = replicate(5, rf.learner, simplify = FALSE)
)
# 训练集成模型
rf.ens.task <- makeClassifTask(data = iris, target = "Species")
rf.ens.model <- train(rf.ens.learner, task = rf.ens.task)
# 评估模型性能
rf.ens.pred <- predict(rf.ens.model, task = rf.ens.task)
performance(rf.ens.pred)
```
在上述代码中,我们首先创建了一个随机森林学习器,然后使用`makeEnsemble`函数创建了一个集成学习器,其中包含了5个随机森林基学习器。通过`train`函数训练模型,并用`predict`函数来评估性能。
## 5.3 mlr包的扩展包与自定义任务
mlr包提供了易于扩展和自定义的功能,这使得用户可以根据自己的需求来创建新的学习任务或算法。
### 5.3.1 mlr的扩展包介绍
mlr有许多扩展包,如`mlrCPO`用于特征转换和预处理操作,`mlrMBO`用于贝叶斯优化等。
### 5.3.2 自定义学习任务与算法实现
通过继承`Learner`类,可以实现自定义的学习任务。下面是一个如何扩展mlr以添加一个自定义学习器的简单例子:
```r
# 自定义学习器类
CustomLearner <- makeLearnerClass(
id = "classif.myCustom",
par.set = makeParamSet(
makeNumericParam("myParam", lower = 0, upper = 1)
),
properties = c("classif", "numerics"),
short.name = "MyCustomLearner"
)
# 实现自定义学习器
CustomLearner$train = function(task, row.id = NULL, ...) {
# 这里编写训练逻辑
}
# 使用自定义学习器
custom.learner <- makeLearner("classif.myCustom")
custom.task <- makeClassifTask(data = iris, target = "Species")
custom.model <- train(custom.learner, task = custom.task)
```
在上面的例子中,我们首先创建了一个名为`CustomLearner`的自定义学习器类。接着,我们定义了它的训练逻辑,以及如何使用它来训练一个模型。
## 5.4 mlr包在大数据处理中的应用
处理大数据集是数据科学中的常见任务,mlr为这类问题提供了一些解决方案。
### 5.4.1 大数据处理的挑战
处理大数据集时,我们面临的挑战包括内存限制、计算时间长、分布式计算需求等。
### 5.4.2 mlr包在大数据处理中的应用实例
mlr通过提供对外部工具的接口,比如`paradox`包进行参数搜索,以及`batchtools`包用于分布式计算,解决了大数据处理中的一些问题。
```r
# 加载paradox和batchtools包
library(paradox)
library(batchtools)
# 创建一个大规模的任务
batch.task <- makeRegrTask(data = largeDataFrame, target = "targetColumn")
# 使用batchtools进行并行化训练
regressor <- makeLearner(cl = "regr.rpart")
cl <- makeClusterFunctionsMulticore(parallel::detectCores()) # 用多核处理
# 设置超参数搜索范围
ps <- makeParamSet(
makeDiscreteParam("cp", values = c(0.01, 0.005, 0.001))
)
# 执行参数优化
ctrl <- makeTuneControlGrid()
res <- tuneParams(learner = regressor,
task = batch.task,
resampling = makeResampleDesc("Holdout"),
par.set = ps,
control = ctrl,
measures = acc,
*** = FALSE,
cl = cl)
```
在上述示例中,我们使用了`batchtools`包来进行分布式计算,通过`paradox`包定义了参数搜索空间,并使用了`makeTuneControlGrid`来执行网格搜索。
这些章节展示了mlr包在高级参数设置、集成学习、扩展应用以及大数据处理方面的能力和应用方法,为数据科学家和机器学习从业者提供了深入理解和实践的途径。通过这些进阶技巧和扩展应用,用户可以更有效地解决复杂的数据问题,并将mlr包的功能发挥到极致。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入探讨了 R 语言中功能强大的 mlr 数据包,为数据科学家和机器学习从业者提供了全面的指南。从基础使用到高级应用,该专栏涵盖了广泛的主题,包括数据预处理、模型构建、特征选择、模型调优、可视化、文本挖掘、生存分析、贝叶斯学习和深度学习。通过深入的教程和案例分析,该专栏旨在帮助读者掌握 mlr 包的各个方面,从而提高他们的数据分析和机器学习技能。无论您是初学者还是经验丰富的从业者,本专栏都能提供有价值的见解和实用技巧,帮助您充分利用 mlr 包的强大功能。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
VisionPro故障诊断手册:网络问题的系统诊断与调试

# 摘要
网络问题诊断与调试是确保网络高效、稳定运行的关键环节。本文从网络基础理论与故障模型出发,详细阐述了网络通信协议、网络故障的类型及原因,并介绍网络故障诊断的理论框架和管理工具。随后,本文深入探讨了网络故障诊断的实践技巧,包括诊断工具与命令、故障定位方法以及
【Nginx负载均衡终极指南】:打造属于你的高效访问入口
.webp)
# 摘要
Nginx作为一款高性能的HTTP和反向代理服务器,已成为实现负载均衡的首选工具之一。本文首先介绍了Nginx负载均衡的概念及其理论基础,阐述了负载均衡的定义、作用以及常见算法,进而探讨了Nginx的架构和关键组件。文章深入到配置实践,解析了Nginx配置文件的关键指令,并通过具体配置案例展示了如何在不同场景下设置Nginx以实现高效的负载分配。
云计算助力餐饮业:系统部署与管理的最佳实践
# 摘要
云计算作为一种先进的信息技术,在餐饮业中的应用正日益普及。本文详细探讨了云计算与餐饮业务的结合方式,包括不同类型和部署模型的云服务,并分析了其在成本效益、扩展性、资源分配和高可用性等方面的优势。文中还提供餐饮业务系统云部署的实践案例,包括云服务选择、迁移策略以及安全合规性方面的考量。进一步地,文章深入讨论了餐饮业务云管理与优化的方法,并通过案例研究展示了云计算在餐饮业中的成功应用。最后,本文对云计算在餐饮业中
【Nginx安全与性能】:根目录迁移,如何在保障安全的同时优化性能
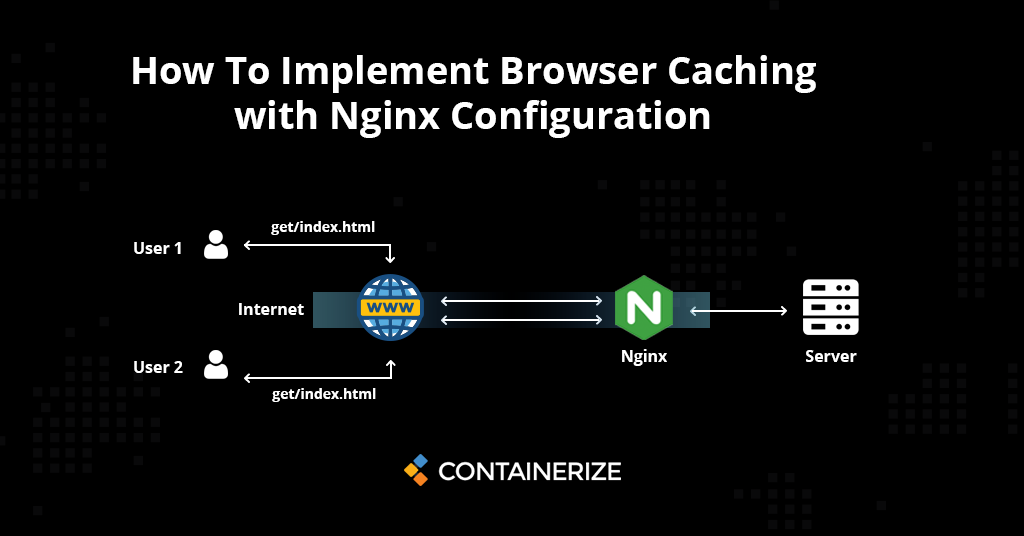
# 摘要
本文对Nginx根目录迁移过程、安全性加固策略、性能优化技巧及实践指南进行了全面的探讨。首先概述了根目录迁移的必要性与准备步骤,随后深入分析了如何加固Nginx的安全性,包括访问控制、证书加密、
RJ-CMS主题模板定制:个性化内容展示的终极指南

# 摘要
本文详细介绍了RJ-CMS主题模板定制的各个方面,涵盖基础架构、语言教程、最佳实践、理论与实践、高级技巧以及未来发展趋势。通过解析RJ-CMS模板的文件结构和继承机制,介绍基本语法和标签使用,本文旨在提供一套系统的方法论,以指导用户进行高效和安全的主题定制。同时,本文也探讨了如何优化定制化模板的性能,并分析了模板定制过程中的高级技术应用和安全性问题。最后,本文展望了RJ-CMS模板定制的
【板坯连铸热传导进阶】:专家教你如何精确预测和控制温度场

# 摘要
本文系统地探讨了板坯连铸过程中热传导的基础理论及其优化方法。首先,介绍了热传导的基本理论和建立热传导模型的方法,包括导热微分方程及其边界和初始条件的设定。接着,详细阐述了热传导模型的数值解法,并分析了影响模型准确性的多种因素,如材料热物性、几何尺寸和环境条件。本文还讨论了温度场预测的计算方法,包括有限差分法、有限元法和边界元法,并对温度场控制技术进行了深入分析。最后,文章探讨了温度场优化策略、
【性能优化大揭秘】:3个方法显著提升Android自定义View公交轨迹图响应速度

# 摘要
本文旨在探讨Android自定义View在实现公交轨迹图时的性能优化。首先介绍了自定义View的基础知识及其在公交轨迹图中应用的基本要求。随后,文章深入分析了性能瓶颈,包括常见性能问题如界面卡顿、内存泄漏,以及绘制过程中的性能考量。接着,提出了提升响应速度的三大方法论,包括减少视图层次、视图更新优化以及异步处理和多线程技术应用。第四章通过实践应用展示了性能优化的实战过程和
Python环境管理:一次性解决Scripts文件夹不出现的根本原因

# 摘要
本文系统地探讨了Python环境的管理,从Python安装与配置的基础知识,到Scripts文件夹生成和管理的机制,再到解决环境问题的实践案例。文章首先介绍了Python环境管理的基本概念,详细阐述了安装Python解释器、配置环境变量以及使用虚拟环境的重要性。随
通讯录备份系统高可用性设计:MySQL集群与负载均衡实战技巧

# 摘要
本文探讨了通讯录备份系统的高可用性架构设计及其实际应用。首先对MySQL集群基础进行了详细的分析,包括集群的原理、搭建与配置以及数据同步与管理。随后,文章深入探讨了负载均衡技术的原理与实践,及其与MySQL集群的整合方法。在此基础上,详细阐述了通讯录备份系统的高可用性架构设计,包括架构的需求与目标、双活或多活数据库架构的构建,以及监
【20分钟精通MPU-9250】:九轴传感器全攻略,从入门到精通(必备手册)

# 摘要
本文对MPU-9250传感器进行了全面的概述,涵盖了其市场定位、理论基础、硬件连接、实践应用、高级应用技巧以及故障排除与调试等方面。首先,介绍了MPU-9250作为一种九轴传感器的工作原理及其在数据融合中的应用。随后,详细阐述了传感器的硬件连
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )