深入理解Git的重置与回滚操作
发布时间: 2024-04-09 18:30:40 阅读量: 49 订阅数: 46 

Git重置与检出对比表
# 1. 深入理解Git的重置与回滚操作
## 第一章:Git的基础操作回顾
在本章中,我们将回顾Git的基础操作,包括Git的基本概念和创建与克隆仓库的方法。
### 2.1 Git的基本概念回顾
下面是Git的一些基本概念的回顾:
- **仓库(Repository)**:用于存储项目代码的地方。
- **提交(Commit)**:将代码变动记录到仓库中的操作。
- **分支(Branch)**:用于开发新功能或修复bug而从主代码分离出来的版本控制机制。
- **合并(Merge)**:将不同分支的代码内容合并在一起的操作。
- **远程仓库(Remote Repository)**:托管在服务器上的项目仓库。
### 2.2 创建与克隆仓库
下面是创建与克隆仓库的操作方法:
1. 创建仓库:
```bash
$ git init # 在当前目录创建一个新的仓库
$ git clone <url> # 克隆远程仓库到本地
```
2. 克隆仓库:
```bash
$ git clone <url> # 将远程仓库克隆到本地
```
通过本章的内容回顾,读者可以加深对Git基础操作的理解,为后续章节的重置与回滚操作打下坚实的基础。
# 2. Git的重置操作
### 3.1 重置的概念与作用
在Git中,重置操作可以让我们回到之前的某个提交状态,撤销一些操作,是一种十分常用的版本管理工具。
重置操作主要有两种方式:软重置和硬重置,它们分别适用于不同的场景。
### 3.2 软重置的使用方法
软重置(Soft Reset)是一种较为轻量级的重置操作,它会将 HEAD 指针移回到指定的提交版本,但是保留暂存区和工作目录的文件不变。
软重置的使用方法如下:
```bash
git reset --soft <commit-hash>
```
### 3.3 硬重置的使用方法
硬重置(Hard Reset)是一种比较彻底的重置操作,它会将 HEAD 指针移回到指定的提交版本,并且清空暂存区和工作目录的内容,慎用!
硬重置的使用方法如下:
```bash
git reset --hard <commit-hash>
```
下面是一个软重置的示例流程图:
```mermaid
graph LR
A[当前工作目录] --> B[git reset --soft <commit-hash>]
B --> C[暂存区]
C --> D[指定提交版本]
```
下表展示了软重置与硬重置的比较:
| 重置方式 | 作用 | 保留内容 | 注意事项 |
| -------- | ---- | ------- | ------- |
| 软重置 | 回到历史提交版本 | 保留暂存区和工作目录的文件 | 适合撤销最近的提交 |
| 硬重置 | 回到历史提交版本 | 清空暂存区和工作目录的内容 | 慎用,会永久删除未提交的修改 |
通过软重置和硬重置,我们可以灵活地管理版本历史记录,快速恢复到需要的状态。
# 3. Git的重置操作
### 3.1 重置的概念与作用
在Git中,重置是指将当前分支的HEAD指针移动到另一个位置的操作。它可以被用来撤销更改、修改提交历史,以及处理代码提交错误等情况。
重置操作主要有两种类型:软重置(soft reset)和硬重置(hard reset)。软重置会保留当前修改,而硬重置将丢弃所有修改,让工作目录恢复到指定状态。
### 3.2 软重置的使用方法
软重置通过移动HEAD指针来取消提交,但保留提交后的修改。
```shell
git reset --soft HEAD^
```
其中,`--soft`参数表示保留工作目录和暂存区的改动,将HEAD指向上一个提交。
使用软重置后,可以重新修改之前的代码,然后重新提交。
### 3.3 硬重置的使用方法
硬重置会将HEAD指针和工作目录都重置到指定提交的状态,丢弃之后的改动。
```shell
git reset --hard COMMIT_ID
```
其中,`--hard`参数表示重置工作区和暂存区,不保留任何修改。
**硬重置要慎用,因为会永久丢失之后的修改,谨慎操作!**
#### 硬重置操作示例
下面是一个使用硬重置的示例,其中重置到前两个提交之前:
```shell
git log --oneline
# 查看提交历史
git reset --hard HEAD~2
# 将HEAD指针指向前两个提交
git log --oneline
# 再次查看提交历史,确认重置成功
```
通过以上操作,可以清楚地看到HEAD指针的位置发生了改变,工作目录也恢复到了前两个提交的状态。
#### 硬重置操作结果说明
通过上述示例,我们成功地演示了如何使用Git进行硬重置操作。重置操作可以帮助我们在特定情况下快速纠正错误,但一定要谨慎操作,以免造成数据丢失。
###

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏全面介绍 Git 的安装、概念、优势、工作原理、文件结构和操作。它提供了详细的分步指南,指导您在 Windows、Mac 和 Linux 系统中安装 Git。专栏深入探讨了 Git 的团队协作功能,包括远程仓库管理和代码审查。它还涵盖了 Git 的高级主题,例如撤销修改、版本控制、标签、分支合并、重置、回滚、忽略规则、工作流管理和 Git Flow 工作流程。通过本专栏,您将掌握 Git 的核心概念和实用技术,从而提高代码管理和协作效率。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【ACC自适应巡航软件功能规范】:揭秘设计理念与实现路径,引领行业新标准

# 摘要
自适应巡航控制(ACC)系统作为先进的驾驶辅助系统之一,其设计理念在于提高行车安全性和驾驶舒适性。本文从ACC系统的概述出发,详细探讨了其设计理念与框架,包括系统的设计目标、原则、创新要点及系统架构。关键技术如传感器融合和算法优化也被着重解析。通过介绍ACC软件的功能模块开发、测试验证和人机交互设计,本文详述了系统的实现
敏捷开发与DevOps的融合之道:软件开发流程的高效实践

# 摘要
敏捷开发与DevOps是现代软件工程中的关键实践,它们推动了从开发到运维的快速迭代和紧密协作。本文深入解析了敏捷开发的核心实践和价值观,探讨了DevOps的实践框架及其在自动化、持续集成和监控等方面的应用。同时,文章还分析了敏捷开发与DevOps的融合策略,包括集成模式、跨功能团队构建和敏捷DevOps文化的培养。通过案例分析,本文提供了实施敏捷DevOps的实用技巧和策略
【汇川ES630P伺服驱动器终极指南】:全面覆盖安装、故障诊断与优化策略
# 摘要
汇川ES630P伺服驱动器是工业自动化领域中先进的伺服驱动产品,它拥有卓越的基本特性和广泛的应用领域。本文从概述ES630P伺服驱动器的基础特性入手,详细介绍了其主要应用行业以及与其他伺服驱动器的对比。进一步,探讨了ES630P伺服驱动
AutoCAD VBA项目实操揭秘:掌握开发流程的10个关键步骤
# 摘要
本文旨在全面介绍AutoCAD VBA的基础知识、开发环境搭建、项目实战构建、编程深入分析以及性能优化与调试。文章首先概述AutoCAD VBA的基本概念和开发环境,然后通过项目实战方式,指导读者如何从零开始构建AutoCAD VBA应用。文章深入探讨了VBA编程的高级技巧,包括对象模型、类模块的应用以及代码优化和错误处理。最后,文章提供了性能优化和调试的方法,并
NYASM最新功能大揭秘:彻底释放你的开发潜力
# 摘要
NYASM是一个功能强大的汇编语言工具,支持多种高级编程特性并具备良好的模块化编程支持。本文首先对NYASM的安装配置进行了概述,并介绍了其基础与进阶语法。接着,本文探讨了NYASM在系统编程、嵌入式开发以及安全领域的多种应用场景。文章还分享了NYASM的高级编程技巧、性能调优方法以及最佳实践,并对调试和测试进行了深入讨论。最后,本文展望了NYASM的未来发展方向,强调了其与现代技
ICCAP高级分析:挖掘IC深层特性的专家指南
# 摘要
本文全面介绍了ICCAP的理论基础、实践应用及高级分析技巧,并对其未来发展趋势进行了展望。首先,文章介绍了ICCAP的基本概念和基础知识,随后深入探讨了ICCAP软件的架构、运行机制以及IC模型的建立和分析方法。在实践应用章节,本文详细阐述了ICCAP在IC参数提取和设计优化中的具体应用,包括方法步骤和案例分析。此外,还介绍了ICCAP的脚本编程技巧和故障诊断排除方法。最后,文章预测了ICCAP在物联网和人工智能
【Minitab单因子方差分析】:零基础到专家的进阶路径
# 摘要
本文详细介绍了Minitab单因子方差分析的各个方面。第一章概览了单因子方差分析的基本概念和用途。第二章深入探讨了理论基础,包括方差分析的原理、数学模型、假设检验以及单因子方差分析的类型和特点。第三章则转向实践操作,涵盖了Minitab界面介绍、数据分析步骤、结果解读和报告输出。第四章讨论了高级应用,如多重比较、方差齐性检验及案例研究。第五章关注在应用单因子方差分析时可能
FTTR部署实战:LinkHome APP用户场景优化的终极指南
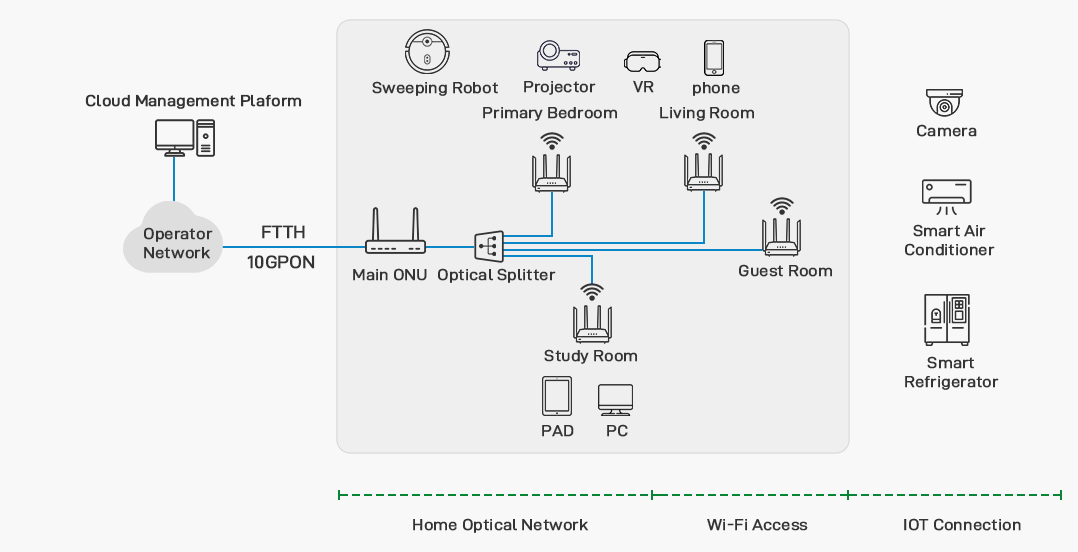
# 摘要
本论文首先介绍了FTTR(Fiber To The Room)技术的基本概念及其背景,以及LinkHome APP的概况和功能。随后详细阐述了在FTTR部署前需要进行的准备工作,包括评估网络环境与硬件需求、分析LinkHome APP的功能适配性,以及进行预部署测试与问题排查。重点介绍了FTTR与LinkHome APP集成的实践,涵盖了用户场景配置、网络环境部署实施,以及网络性能监
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )