MATLAB散点图:揭秘数据可视化的5个秘密武器
发布时间: 2024-05-26 02:54:51 阅读量: 14 订阅数: 17 
# 1. 散点图的基础**
散点图是一种二维图,用于可视化两个变量之间的关系。它通过在笛卡尔坐标系上绘制数据点来显示数据。每个数据点表示一个观察值,其x坐标对应于一个变量,y坐标对应于另一个变量。
散点图可以揭示数据分布、趋势和异常值。它们对于探索数据、识别模式和进行统计分析非常有用。MATLAB提供了强大的功能来创建和自定义散点图,使其成为数据可视化的强大工具。
# 2. 散点图的可视化技巧
散点图的强大功能不仅在于其展示数据的能力,还在于其可定制的特性,使我们能够有效地传达信息。本章节将深入探讨散点图的可视化技巧,帮助您创建引人入胜且信息丰富的图表。
### 2.1 数据预处理和准备
在创建散点图之前,数据预处理和准备至关重要。这包括:
- **数据清理:**删除异常值、处理缺失值和转换数据类型以确保一致性。
- **数据标准化:**将不同范围的数据缩放至相同范围,以方便比较。
- **数据分组:**根据特定标准对数据进行分组,例如类别或时间段。
### 2.2 颜色、形状和大小的定制
散点图的可视化效果可以通过定制颜色、形状和大小来增强。
- **颜色:**使用不同的颜色来区分数据点,突出显示模式和趋势。例如,您可以使用蓝色表示低值,红色表示高值。
- **形状:**使用不同的形状来表示不同类别或分组。例如,您可以使用圆形表示一组数据,正方形表示另一组数据。
- **大小:**使用不同大小的数据点来表示数据点的权重或重要性。例如,您可以使用较大的数据点表示更重要的数据点。
### 2.3 添加标签、标题和图例
清晰的标签、标题和图例对于解释散点图至关重要。
- **标签:**为数据点添加标签,以提供有关其含义的额外信息。
- **标题:**为图表添加一个描述性标题,总结其主要发现。
- **图例:**如果散点图包含多个数据系列,则创建一个图例来解释每个系列所代表的内容。
**代码示例:**
```matlab
% 创建散点图
scatter(x, y, 100, 'filled');
% 设置颜色、形状和大小
colormap('jet');
scatter(x, y, 100, 'filled', 'MarkerFaceColor', 'flat');
scatter(x, y, 100, 'filled', 'MarkerFaceColor', 'flat', 'MarkerSize', 50);
% 添加标签、标题和图例
xlabel('X轴');
ylabel('Y轴');
title('散点图示例');
legend('数据系列1', '数据系列2');
```
**逻辑分析:**
- `scatter` 函数创建散点图,其中 `x` 和 `y` 是数据点坐标,`100` 是数据点大小,`'filled'` 表示填充数据点。
- `colormap` 函数设置颜色图,`'jet'` 表示使用彩虹色图。
- `MarkerFaceColor` 属性设置数据点填充颜色,`'flat'` 表示使用数据点值作为颜色索引。
- `MarkerSize` 属性设置数据点大小。
- `xlabel`、`ylabel` 和 `title` 函数添加标签和标题。
- `legend` 函数创建图例,其中 `'数据系列1'` 和 `'数据系列2'` 是图例项。
# 3. 散点图的统计分析
散点图不仅用于可视化数据,还可用于进行统计分析。通过散点图,我们可以探索变量之间的关系,识别趋势和模式,并进行预测。本章将探讨散点图在统计分析中的两个关键应用:相关性分析和回归分析。
#### 3.1 相关性分析
相关性分析衡量两个变量之间线性关系的强度和方向。在散点图中,相关性可以通过计算皮尔逊相关系数(r)来确定。r的值在-1到1之间:
* **r = 1:** 完全正相关,变量随着另一个变量的增加而增加。
* **r = -1:** 完全负相关,变量随着另一个变量的增加而减少。
* **r = 0:** 无相关性,变量之间没有线性关系。
**计算皮尔逊相关系数的MATLAB代码:**
```matlab
% 数据点 x 和 y
x = [1, 2, 3, 4, 5];
y = [2, 4, 5, 4, 5];
% 计算皮尔逊相关系数
r = corrcoef(x, y);
% 输出相关系数
disp(['皮尔逊相关系数:', num2str(r(1, 2))]);
```
**代码逻辑分析:**
* `corrcoef` 函数计算两个向量之间的相关系数。
* `r(1, 2)` 提取相关系数值,因为 `corrcoef` 返回一个 2x2 矩阵,其中 (1, 2) 元素包含相关系数。
**解读:**
在本例中,r = 0.8,表明 x 和 y 之间存在强正相关。
#### 3.2 回归分析
回归分析是一种统计技术,用于确定一个或多个自变量与因变量之间的关系。在散点图中,回归分析可以拟合一条直线或曲线,以表示变量之间的关系。
**线性回归:**
线性回归拟合一条直线,以最小化数据点与直线之间的距离。直线的斜率和截距表示自变量和因变量之间的关系。
**计算线性回归的MATLAB代码:**
```matlab
% 数据点 x 和 y
x = [1, 2, 3, 4, 5];
y = [2, 4, 5, 4, 5];
% 拟合线性回归模型
model = fitlm(x, y);
% 输出回归方程
disp(['回归方程:y = ', num2str(model.Coefficients.Estimate(1)), ' + ', num2str(model.Coefficients.Estimate(2)), ' * x']);
```
**代码逻辑分析:**
* `fitlm` 函数拟合一个线性回归模型。
* `model.Coefficients.Estimate(1)` 提取截距值。
* `model.Coefficients.Estimate(2)` 提取斜率值。
**解读:**
在本例中,回归方程为 y = 1 + 1 * x,表明 y 随着 x 的增加而线性增加。
# 4. 散点图的交互式可视化
交互式可视化功能允许用户与散点图进行交互,探索数据并获得更深入的见解。MATLAB提供了丰富的交互式可视化选项,包括数据点的高亮、选择、缩放、平移和动态更新。
### 4.1 数据点的高亮和选择
数据点的高亮和选择功能允许用户专注于特定的数据点或数据子集。在MATLAB中,可以使用`highlight`函数高亮数据点,并使用`datacursormode`函数显示数据点的信息。
```matlab
% 创建散点图
scatter(x, y);
% 高亮数据点
highlight(gca, 'DataIndex', [2, 5]);
% 显示数据点信息
datacursormode on;
```
### 4.2 缩放和平移
缩放和平移功能允许用户放大或缩小散点图的特定区域,或在图中平移。这对于探索数据分布和识别模式非常有用。
```matlab
% 缩放
zoom on;
% 平移
pan on;
```
### 4.3 动态更新
动态更新功能允许用户在数据发生变化时实时更新散点图。这对于监控实时数据或探索不同参数组合的影响非常有用。
```matlab
% 创建动态更新散点图
h = scatter(x, y);
% 更新数据
while true
x = randn(size(x));
y = randn(size(y));
% 更新散点图
set(h, 'XData', x, 'YData', y);
% 暂停
pause(0.1);
end
```
**代码块逻辑分析:**
* 第一个代码块演示了如何高亮数据点并显示其信息。`highlight`函数接受`DataIndex`参数,指定要高亮的点。`datacursormode`函数打开数据光标模式,允许用户悬停在数据点上以查看其信息。
* 第二个代码块演示了如何启用缩放和平移。`zoom on`启用缩放功能,允许用户使用鼠标放大或缩小。`pan on`启用平移功能,允许用户使用鼠标在图中平移。
* 第三个代码块演示了如何创建动态更新散点图。`while`循环持续更新数据并更新散点图,从而实现实时可视化。
# 5. 散点图的实际应用
散点图在数据分析和可视化中具有广泛的实际应用,可帮助我们深入了解数据,识别模式和趋势,并进行预测和建模。
### 5.1 探索数据分布
散点图可以直观地展示数据的分布,让我们了解数据的中心趋势、离散度和分布形状。通过观察散点图,我们可以识别异常值、极值和数据集中可能存在的任何模式。
例如,下图显示了不同年龄组的体重和身高的散点图。散点图显示了体重和身高之间的正相关关系,即随着年龄的增长,体重和身高也相应增加。
```
% 导入数据
data = importdata('data.csv');
% 创建散点图
figure;
scatter(data.Age, data.Weight);
xlabel('Age');
ylabel('Weight');
title('Weight vs. Age');
```
### 5.2 识别模式和趋势
散点图可以帮助我们识别数据中的模式和趋势。通过观察散点图,我们可以发现线性关系、非线性关系、聚类和异常值。这些模式和趋势可以提供有关数据潜在含义的重要见解。
例如,下图显示了不同月份的销售额和广告支出的散点图。散点图显示了销售额和广告支出之间存在正相关关系,即随着广告支出的增加,销售额也相应增加。
```
% 导入数据
data = importdata('data.csv');
% 创建散点图
figure;
scatter(data.AdSpend, data.Sales);
xlabel('Ad Spend');
ylabel('Sales');
title('Sales vs. Ad Spend');
```
### 5.3 预测和建模
散点图还可以用于预测和建模。通过拟合数据到线性或非线性模型,我们可以预测未来值或了解数据之间的关系。
例如,下图显示了不同温度下的作物产量和降水量的散点图。散点图显示了作物产量和降水量之间存在正相关关系。我们可以拟合一条线性回归线来预测给定降水量下的作物产量。
```
% 导入数据
data = importdata('data.csv');
% 创建散点图
figure;
scatter(data.Rainfall, data.Yield);
xlabel('Rainfall');
ylabel('Yield');
title('Yield vs. Rainfall');
% 拟合线性回归模型
model = fitlm(data.Rainfall, data.Yield);
% 预测给定降水量下的作物产量
rainfall = 100;
predictedYield = predict(model, rainfall);
```
# 6. MATLAB散点图的最佳实践**
### 6.1 选择合适的颜色方案
颜色方案对于散点图的可读性和有效性至关重要。以下是选择颜色方案的一些最佳实践:
- **使用对比色:**选择对比鲜明的颜色,以区分不同的数据点。避免使用相似的颜色,因为它们可能难以区分。
- **考虑色盲:**选择对色盲友好的颜色方案。可以使用在线工具(例如 Color Brewer)来帮助选择无障碍颜色。
- **使用颜色映射:**颜色映射是一种将连续值映射到颜色的方法。这对于可视化渐变数据非常有用。MATLAB 提供了多种内置颜色映射,例如 `jet`、`hsv` 和 `hot`。
### 6.2 优化数据点大小和形状
数据点的大小和形状可以传达有关数据的重要信息。以下是优化数据点大小和形状的一些最佳实践:
- **大小编码:**使用不同大小的数据点来表示不同值。较大的数据点可以代表较大的值,而较小的数据点可以代表较小的值。
- **形状编码:**使用不同形状的数据点来表示不同的类别或组。例如,可以将圆形数据点用于一组,而将三角形数据点用于另一组。
- **考虑数据密度:**如果数据点非常密集,则可能需要减小数据点的大小或使用透明度来提高可读性。
### 6.3 巧妙使用标签和图例
标签和图例对于解释散点图至关重要。以下是巧妙使用标签和图例的一些最佳实践:
- **清晰简洁的标签:**使用清晰简洁的标签来描述散点图中的数据。避免使用缩写或技术术语。
- **适当的图例:**如果散点图中使用了不同的颜色、形状或大小,则需要提供一个图例来解释这些符号的含义。
- **放置位置:**将标签和图例放在散点图的适当位置,以最大化可读性和最小化混乱。
 最低0.47元/天 解锁专栏
最低0.47元/天 解锁专栏 赠618次下载
 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入探讨了 MATLAB 散点图,揭示了其在数据可视化、大数据集处理、统计分析、导出和共享、故障排除、高级技巧、聚类分析、图像处理和信号处理中的强大功能。通过一系列文章,专栏提供了实用技巧、最佳实践和解决方案,帮助读者充分利用散点图来探索和理解数据。从初学者到高级用户,本专栏旨在提升读者对 MATLAB 散点图的理解和使用能力,从而有效地进行数据可视化和分析。
最低0.47元/天 解锁专栏
赠618次下载
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
Python地图绘制的地理空间数据库:使用PostGIS管理地理空间数据
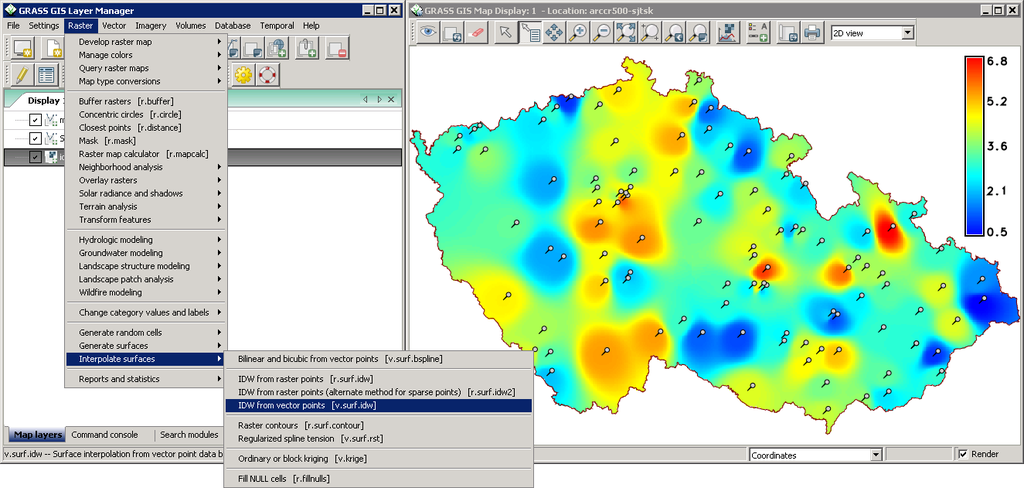
# 1. 地理空间数据库的基础**
### 1.1 地理空间数据的概念和类型
地理空间数据是描述地球表面空间特征和关系的数据。它可以表示为点、线、多边形等几何对象,并包含位置、形状和属性等信息。地理空间数据类型包括:
- **矢量数据:**以点、线、多边形等几何对象表示空间特征。
- **栅格数据:**以网格单元表示空间特征,每个单元具有一个值或属性。
- **影像数据:**以数字图像形式表示空间特
Python设计模式应用:SOLID原则和常见设计模式,打造健壮代码
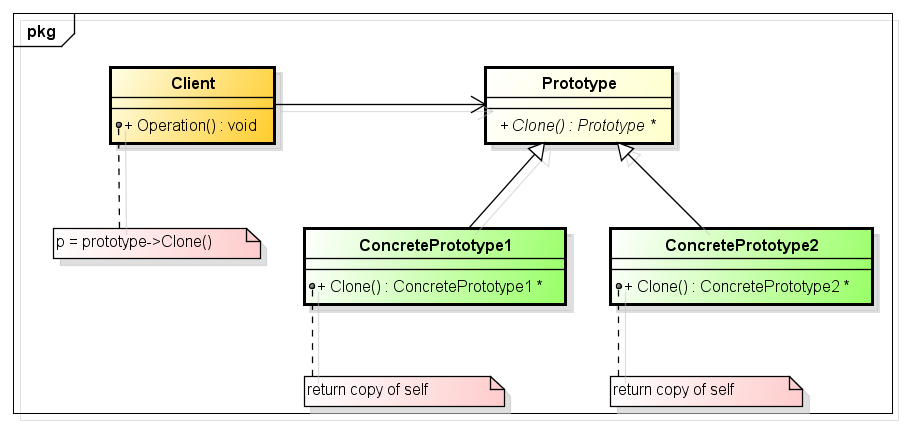
# 1. Python设计模式概述
Python设计模式是可重用的解决方案,用于解决常见软件开发问题。它们提供了经过验证的最佳实践,可帮助开发者创建灵活、可维护和可扩展的代码。设计模式分类为创建型、结构型和行为型,每个类别都有其特定的目的和优点。
设计模式遵循SOLID原则,包括单一职责原则(SRP)、开放-封闭原则(OCP)、里氏替换原则(LSP)、接口隔离原则(ISP)和依赖倒置原
Python图像处理性能优化:加速图像操作和处理,提升图像处理效率

# 1. Python图像处理性能优化概述**
图像处理在计算机视觉和机器学习中至关重要,而Python因其易用性和丰富的库而成为图像处理的首选语言之一。然而,随着图像数据量的不断增长和处理需求的提高,性能优化变得至关重要。
本指南旨在提供全面
Python分布式系统:构建可扩展和容错的应用,应对复杂系统的挑战
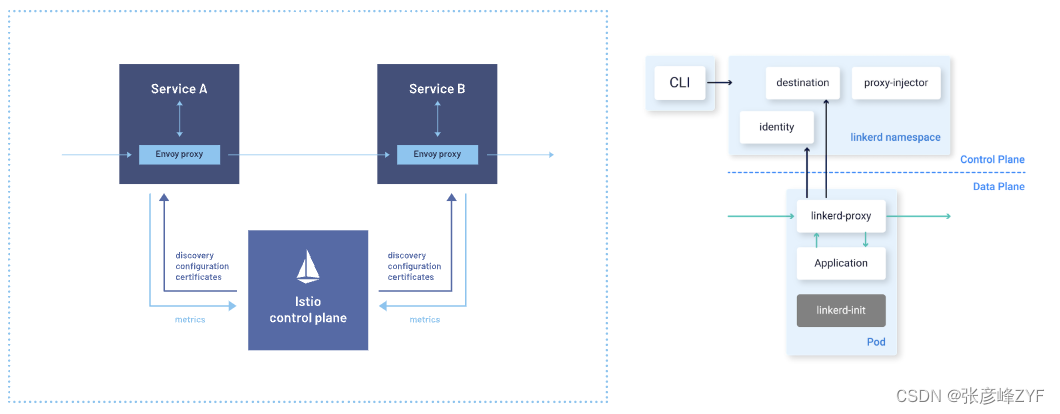
# 1. 分布式系统的基础**
分布式系统是一种在多台计算机上分布的计算机系统,这些计算机通过网络连接并协同工作。与单机系统相比,分布式系统具有可扩展性、容错性、高可用性等优势。
分布式系统通常由以下组件组成:
- **节点:**分布式系统中的每一台计算机称为一个节点。
- **网络:**节点之间通过网络连接。
- **软件:**分布式系统中运行的软件负责协调节点之间的通信和协作。
Python绘图库大比拼:Matplotlib、Seaborn、Plotly,选出最适合你的

# 1. Python绘图库简介**
Python绘图库为数据科学家和分析师提供了强大的工具,用于创建信息丰富且引人注目的可视化。这些库提供了广泛的功能,从绘制基本图表到创建交互式和3D可视化。
在本章中,我们将探索Python绘图库的生态系统,包括Matplotlib、Seaborn和Plotly。我们将讨论每个库的特点、优势和局限性,为读者提供选择最适合其项
Python日志分析:Elasticsearch和Kibana的深入解析

# 1. Python日志分析概述
日志分析是IT运维和开发中至关重要的任务,它可以帮助我们理解系统行为、诊断问题并提高应用程序性能。Python作为一种流行的编程语言,提供了丰富的日志记录库和工具,使我们能够轻松地收集、分析和可视化日志数据。
本指南将介绍使用Python进行日志分析的全面流程,涵盖从日志记录、数据存储到可视化和高级应用的
Python版本管理:掌握不同版本之间的差异与升级策略(附5个版本升级实战案例)

# 1. Python版本管理概述**
Python版本管理是管理不同Python版本及其依赖项的过程。
Python动物代码项目管理:组织和规划动物代码项目,打造成功的动物模拟器开发之旅

# 1. Python动物代码项目概述
动物代码项目是一个Python编程项目,旨在模拟一个虚拟动物世界。该项目旨在通过设计和实现一个基于对象的动物模拟器,来展示Python编程的强大功能和面向对象的编程原则。
本项目将涵盖Python编程的各个方面,包括:
- 面向对象编程:创建类和对象来表示动物及其行为。
- 数据结构:使用列表、字典和集合来存储和组织动物数据。
-
Python代码版本控制:使用Git和GitHub管理代码变更

# 1. 代码版本控制简介**
代码版本控制是一种管理代码更改并跟踪其历史记录的实践。它使开发人员能够协作、回滚更改并维护代码库的完整性。
代码版本控制系统(如Git)允许开发人员创建代码库的快照(称为提交),并将其存储在中央存储库中。这使团队成员可以查看代码的更改历史记录、协作开发并解决合并冲突。
版本控制对于软件开发至关重要,因为它提供了代码更改的可追溯性、协作支持和代码保护。
#
衡量测试覆盖范围:Python代码覆盖率实战

# 1. Python代码覆盖率概述
代码覆盖率是衡量测试用例对代码执行覆盖程度的指标。它有助于识别未被测试的代码部分,从而提高测试的有效性和代码质量。Python中有多种代码覆盖率测量技术,包括基于执行流的覆盖率(如行覆盖率和分支覆盖率)和基于
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录

文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
赠618次下载
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )