PL_SQL入门指南:编写你的第一个存储过程
发布时间: 2023-12-15 17:50:30 阅读量: 18 订阅数: 17 
# 简介
## 1.1 什么是PL/SQL
PL/SQL是一种面向Oracle数据库的过程化编程语言,全称为Procedural Language/Structured Query Language。它是在标准的SQL语言基础上添加了过程控制和语句结构化的特性。PL/SQL语言是Oracle数据库的存储过程和触发器的编写语言,也是开发Oracle数据库应用程序的重要工具。
## 1.2 存储过程的概念及作用
存储过程是一组预先编译的SQL语句集合,它们以一个名称存储在数据库中,并可以在需要的时候被调用执行。存储过程可以接受参数传递,并可以返回结果集或输出参数。它们可以被其他程序或应用程序调用,从而实现复杂的业务逻辑,提高数据库的执行效率和数据的一致性。
## 1.3 为什么需要编写存储过程
编写存储过程的主要目的是提高数据库的性能和可维护性,具体原因如下:
- **提高执行效率**:存储过程由数据库管理系统进行编译和优化,可以减少网络通信开销和SQL语句的解析执行时间,从而提高数据库的查询和操作效率。
- **降低数据冗余**:通过将重复的业务逻辑封装在存储过程中,可以避免多次编写相同的SQL语句,减少编码和维护成本,并确保数据的一致性和完整性。
- **实现复杂的业务逻辑**:存储过程可以实现复杂的业务逻辑,包括事务处理、错误处理、循环和条件判断等,从而简化应用程序的开发和维护。
- **提高安全性**:通过存储过程,可以限制用户对数据库的直接访问,只允许调用存储过程执行特定的操作,从而提高数据库的安全性。
综上所述,编写存储过程是数据库开发中的重要环节,可以提高数据库的性能、可维护性和安全性,提供更好的用户体验和数据管理能力。
## 2. 准备工作
### 2.1 安装数据库及相关工具
在开始编写PL/SQL存储过程之前,首先需要安装数据库和相关工具。根据具体需求选择合适的数据库,例如Oracle、MySQL、SQL Server等。安装过程可能有所不同,可以根据官方文档或在线教程进行操作。
同时,还需要安装适用于所选数据库的客户端工具,例如Oracle SQL Developer、MySQL Workbench等。这些工具提供了图形化的界面,方便我们与数据库进行交互和管理。
### 2.2 创建数据库用户及权限设置
安装完成数据库后,需要创建一个专门用于存储过程的数据库用户,并对其进行权限设置。这样可以确保存储过程能够在所需的数据库对象上执行相应的操作。
创建数据库用户可以通过SQL命令或者图形化的客户端工具来完成。在创建用户时,需要指定用户名、密码及相关权限。
### 2.3 数据库连接配置
在开始编写和运行存储过程之前,需要进行数据库连接的配置。连接配置包括数据库地址、用户名、密码等信息。
在客户端工具中,可以通过连接面板或者配置文件的方式进行数据库连接的设置。根据具体工具的不同,配置方式也会有所差异。
在配置完成后,可以通过连接测试来确保连接信息的正确性,以便后续能够顺利地连接到数据库并执行存储过程。
以上是准备工作的相关内容。在完成这些步骤后,我们就可以着手开始编写PL/SQL存储过程了。
### 3. PL/SQL基础
在开始编写存储过程之前,我们需要先了解一下PL/SQL的基础知识。本章节将介绍PL/SQL的语法及特点、变量和数据类型、控制流语句、异常处理以及存储过程的基本语法。
#### 3.1 PL/SQL的语法及特点
PL/SQL是Oracle数据库中的一种过程化编程语言,具有以下几个特点:
- PL/SQL是块结构化语言,以块(block)为单位执行,一个块由声明部分和执行部分组成。
- PL/SQL使用在SQL中使用的数据类型,如VARCHAR2、NUMBER等。
- PL/SQL支持变量、常量、游标等概念,可以在代码中进行声明和使用。
- PL/SQL有丰富的控制流语句,如IF-THEN、FOR LOOP、WHILE LOOP等,可以实现复杂的逻辑控制。
- PL/SQL可以与SQL语句无缝集成,可以直接在PL/SQL中执行SQL语句并处理返回结果。
- PL/SQL具有异常处理机制,可以捕获和处理运行时错误。
#### 3.2 变量和数据类型
在PL/SQL中,我们使用变量来存储和操作数据。变量可以使用不同的数据类型,如VARCHAR2、NUMBER、DATE等。变量的声明可以放在PL/SQL块的声明部分。
下面是一个变量的声明和赋值的例子:
```sql
DECLARE
name VARCHAR2(20);
age NUMBER(2);
BEGIN
name := 'John';
age := 25;
END;
```
在上面的例子中,我们声明了一个VARCHAR2型的变量name和一个NUMBER型的变量age,并分别赋值为'John'和25。
#### 3.3 控制流语句
PL/SQL提供了多种控制流语句来实现条件判断和循环操作。
- IF-THEN语句:用于条件判断,根据条件的成立与否执行不同的代码块。
```sql
IF condition THEN
statement_1;
ELSE
statement_2;
END IF;
```
- FOR LOOP语句:用于循环操作,重复执行某段代码。
```sql
FOR counter IN lower_bound..upper_bound LOOP
statement;
END LOOP;
```
- WHILE LOOP语句:用于循环操作,根据条件判断是否继续执行循环块中的代码。
```sql
WHILE condition LOOP
statement;
END LOOP;
```
#### 3.4 异常处理
PL/SQL提供了异常处理机制,用于捕获和处理运行时错误。在异常处理部分,我们可以根据需要指定不同的操作,如记录日志、回滚事务等。
下面是一个异常处理的例子:
```sql
BEGIN
-- 执行一些可能引发异常的代码
EXCEPTION
WHEN exception1 THEN
-- 处理异常1的操作
WHEN exception2 THEN
-- 处理异常2的操作
...
END;
```
#### 3.5 存储过程的基本语法
存储过程是一段被命名的PL/SQL代码块,可以被多次调用。存储过程可以接收参数,执行一系列的SQL语句,然后返回结果。
```sql
CREATE [OR REPLACE] PROCEDURE procedure_name [(parameter1 [mode1] datatype1,
parameter2 [mode2] datatype2, ...)]
IS
-- 声明部分
BEGIN
-- 执行部分
EXCEPTION
-- 异常处理部分
END;
```
在上面的语法中,procedure_name是存储过程的名称,parameter是存储过程的参数,IS之后是存储过程的声明部分,BEGIN和END之间是存储过程的执行部分,EXCEPTION之后是存储过程的异常处理部分。
### 4. 编写第一个存储过程
#### 4.1 确认需求并设计存储过程的功能
在本章中,我们将演示如何编写第一个存储过程。假设我们有一个数据库表,包含员工的信息,我们需要编写一个存储过程来根据员工的工资级别,自动将他们的薪水增加10%。
#### 4.2 创建并编辑存储过程
使用SQL Developer或任意喜欢的数据库管理工具连接到数据库。在查询窗口中创建一个新的存储过程:
```sql
CREATE OR REPLACE PROCEDURE increase_salary AS
BEGIN
-- 逻辑代码将在这里编写
END;
/
```
#### 4.3 编译存储过程
将逻辑代码添加到存储过程中。以下是我们实现自动增加薪水的代码:
```sql
CREATE OR REPLACE PROCEDURE increase_salary AS
BEGIN
UPDATE employees
SET salary = salary * 1.1
WHERE salary < 2000;
COMMIT; -- 提交事务
END;
/
```
在这个例子中,我们使用了UPDATE语句来更新员工表中薪水低于2000的记录,并将薪水增加10%。注意,我们在代码的末尾使用了COMMIT语句来提交事务。
#### 4.4 测试存储过程
我们可以通过调用存储过程来测试它是否按预期工作。在查询窗口中执行以下代码:
```sql
EXECUTE increase_salary;
```
这将执行存储过程,并将薪水低于2000的员工的薪水增加10%。你可以使用SELECT语句来验证结果:
```sql
SELECT * FROM employees;
```
结果应该显示薪水低于2000的员工薪水已经被增加了10%。
通过这个例子,我们了解了如何编写一个简单的存储过程,并在具体的业务需求下使用它。在实际开发中,存储过程可以实现更复杂的逻辑,并提供更好的可维护性和性能。
### 存储过程的高级用法
存储过程是数据库中的一种重要的程序化对象,除了基本的存储过程结构和语法外,我们还可以通过参数传递、事务处理、异常处理与日志记录、动态SQL和游标的使用等高级用法来更灵活地应用存储过程。
#### 5.1 参数传递及使用
在存储过程中,我们可以通过参数来传递数值、字符和日期等数据类型,并且可以使用IN、OUT、IN OUT这三种参数传递模式。通过参数传递,我们可以使存储过程更加灵活和通用,可以根据不同的参数值产生不同的计算结果和处理逻辑。
```sql
-- 示例:使用参数传递来实现简单的计算
CREATE OR REPLACE PROCEDURE calculate_salary_bonus (emp_id IN NUMBER, bonus_rate IN NUMBER, total_bonus OUT NUMBER) AS
emp_salary NUMBER;
BEGIN
SELECT salary INTO emp_salary FROM employees WHERE employee_id = emp_id;
total_bonus := emp_salary * bonus_rate;
END;
/
```
#### 5.2 事务处理
在存储过程中,我们可以使用事务处理来确保一组SQL语句要么完全执行,要么完全不执行,以保持数据的一致性。通过使用BEGIN、COMMIT、ROLLBACK等语句,可以在存储过程中实现对数据库操作的事务性控制。
```sql
-- 示例:使用事务处理来确保转账操作的原子性
CREATE OR REPLACE PROCEDURE transfer_funds (from_account IN NUMBER, to_account IN NUMBER, amount IN NUMBER) AS
BEGIN
BEGIN
UPDATE accounts SET balance = balance - amount WHERE account_id = from_account;
UPDATE accounts SET balance = balance + amount WHERE account_id = to_account;
COMMIT;
EXCEPTION
WHEN OTHERS THEN
ROLLBACK;
RAISE;
END;
END;
/
```
#### 5.3 异常处理与日志记录
在存储过程中,我们可以使用异常处理来捕获和处理可能发生的异常情况,同时也可以通过日志记录来记录存储过程的执行情况、错误信息等,以便后续分析和排查问题。
```sql
-- 示例:使用异常处理和日志记录来处理插入操作的异常
CREATE OR REPLACE PROCEDURE insert_employee (emp_id IN NUMBER, emp_name IN VARCHAR2, emp_salary IN NUMBER) AS
BEGIN
INSERT INTO employees (employee_id, employee_name, salary) VALUES (emp_id, emp_name, emp_salary);
COMMIT;
EXCEPTION
WHEN DUP_VAL_ON_INDEX THEN
INSERT INTO error_log (error_message) VALUES ('Duplicate employee ID: ' || emp_id);
WHEN OTHERS THEN
INSERT INTO error_log (error_message) VALUES ('Error occurred while inserting employee data: ' || SQLERRM);
END;
/
```
#### 5.4 动态SQL和游标的使用
存储过程中可以动态构建SQL语句,并且可以使用游标来对结果集进行操作。通过动态SQL和游标的使用,我们可以处理动态条件查询、动态表操作等复杂的业务逻辑。
```sql
-- 示例:使用动态SQL和游标来查询员工信息
CREATE OR REPLACE PROCEDURE get_employees_by_department (department_id IN NUMBER) AS
sql_stmt VARCHAR2(200);
emp_id employees.employee_id%type;
emp_name employees.employee_name%type;
CURSOR c1 IS
SELECT employee_id, employee_name FROM employees WHERE department_id = department_id;
BEGIN
sql_stmt := 'SELECT employee_id, employee_name FROM employees WHERE department_id = ' || department_id;
OPEN c1;
LOOP
FETCH c1 INTO emp_id, emp_name;
EXIT WHEN c1%NOTFOUND;
DBMS_OUTPUT.PUT_LINE('Employee ID: ' || emp_id || ', Employee Name: ' || emp_name);
END LOOP;
CLOSE c1;
END;
/
```
## 存储过程的最佳实践
### 6.1 命名规范和注释规范
在编写存储过程时,良好的命名规范和注释规范能够使代码更加易读、易维护。以下是一些常用的规范:
#### 6.1.1 存储过程命名规范
- 使用有意义的名称:存储过程的名称应该准确地描述其功能和用途。避免使用不清晰或过于简洁的命名。
- 使用统一的命名风格:可以选择使用小驼峰式命名,或者下划线命名等。在整个代码库中保持一致性。
- 加上前缀:可以为存储过程名称加上前缀以表示其所属的模块或功能类别,例如"sp_"表示存储过程。
#### 6.1.2 注释规范
- 添加文件头注释:在每个存储过程的开头添加注释块,描述存储过程的功能、输入参数、输出结果等。
- 添加函数注释:在每个存储过程内部的关键代码块前添加注释,解释代码的作用和逻辑。
- 注释代码更改:在修改代码时,及时更新相应的注释,保持代码和注释的一致性。
- 注释要简洁明了:注释应该简洁明了,避免冗长和复杂的描述。
### 6.2 代码复用和减少重复
在编写存储过程时,代码复用是提高效率和减少代码冗余的重要技巧。
#### 6.2.1 子程序的使用
可以将一些可复用的功能封装成子程序,比如一些常见的数据处理操作、计算逻辑等。通过调用子程序,可以在多个存储过程中复用代码,避免代码的重复编写。
#### 6.2.2 公共函数的使用
数据库中通常会有一些公共函数,如日期函数、字符串处理函数等。通过调用这些公共函数,可以减少代码量,使存储过程更加简洁。
### 6.3 性能优化技巧
在编写存储过程时,性能优化是重要的考虑因素之一。以下是一些常用的性能优化技巧:
#### 6.3.1 使用合适的数据类型
选择合适的数据类型能够提高存储过程的执行效率。使用较小的数据类型能够减少存储空间的占用,并提高数据处理速度。
#### 6.3.2 减少数据库访问次数
数据库访问通常是存储过程的瓶颈之一。尽量减少不必要的数据库访问次数,可以通过合并多个操作为一个事务、使用批处理操作等方式来减少数据库访问的次数。
#### 6.3.3 使用索引
根据具体的查询需求,合理地使用索引可以大大提高存储过程的查询效率。
### 6.4 安全性考虑
在编写存储过程时,安全性是需要重点考虑的。以下是一些常用的安全性考虑:
#### 6.4.1 参数校验
对于从外部输入的参数,应该进行合法性校验,避免恶意输入或者非法操作。
#### 6.4.2 数据库权限设置
合理设置数据库用户的权限,限制其对敏感数据和敏感操作的访问。
#### 6.4.3 防止SQL注入攻击
在拼接SQL语句时,要注意避免拼接未经验证的用户输入,以防止SQL注入攻击。
 最低0.47元/天 解锁专栏
最低0.47元/天 解锁专栏 送3个月
 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
"plsql" 专栏涵盖了各种与 Oracle 数据库编程语言 PL/SQL 相关的主题。无论您是刚开始学习 PL/SQL,还是已经有一定经验的开发者,您都可以在这个专栏中找到适合您的文章。从编写您的第一个存储过程到深入了解异常处理、错误处理和日志记录,从优化查询性能到了解高级函数和过程,以及日期和时间数据的管理和文件操作等等,本专栏将帮助您更加全面地了解 PL/SQL 的使用。此外,您还将学习到如何使用 PL/SQL 实现并发控制和锁定机制,以及调试和性能调优技巧。无论您是想提升自己的编程技能还是解决具体的问题,这个专栏都能帮助您更加深入地掌握 PL/SQL 的知识。
专栏目录
最低0.47元/天 解锁专栏
送3个月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【实战演练】虚拟宠物:开发一个虚拟宠物游戏,重点在于状态管理和交互设计。

# 2.1 虚拟宠物的状态模型
### 2.1.1 宠物的基本属性
虚拟宠物的状态由一系列基本属性决定,这些属性描述了宠物的当前状态,包括:
- **生命值 (HP)**:宠物的健康状况,当 HP 为 0 时,宠物死亡。
- **饥饿值 (Hunger)**:宠物的饥饿程度,当 Hunger 为 0 时,宠物会饿死。
- **口渴
Python map函数在代码部署中的利器:自动化流程,提升运维效率

# 1. Python map 函数简介**
map 函数是一个内置的高阶函数,用于将一个函数应用于可迭代对象的每个元素,并返回一个包含转换后元素的新可迭代对象。其语法为:
```python
map(function, iterable)
```
其中,`function` 是要应用的函数,`iterable` 是要遍历的可迭代对象。map 函数通
Python脚本调用与区块链:探索脚本调用在区块链技术中的潜力,让区块链技术更强大

# 1. Python脚本与区块链简介**
**1.1 Python脚本简介**
Python是一种高级编程语言,以其简洁、易读和广泛的库而闻名。它广泛用于各种领域,包括数据科学、机器学习和Web开发。
**1.2 区块链简介**
区块链是一种分布式账本技术,用于记录交易并防止篡改。它由一系列称为区块的数据块组成,每个区块都包含一组交易和指向前一个区块的哈希值。区块链的去中心化和不可变性使其
【实战演练】综合自动化测试项目:单元测试、功能测试、集成测试、性能测试的综合应用

# 2.1 单元测试框架的选择和使用
单元测试框架是用于编写、执行和报告单元测试的软件库。在选择单元测试框架时,需要考虑以下因素:
* **语言支持:**框架必须支持你正在使用的编程语言。
* **易用性:**框架应该易于学习和使用,以便团队成员可以轻松编写和维护测试用例。
* **功能性:**框架应该提供广泛的功能,包括断言、模拟和存根。
* **报告:**框架应该生成清
Python Excel数据分析:统计建模与预测,揭示数据的未来趋势
# 1. Python Excel数据分析概述**
**1.1 Python Excel数据分析的优势**
Python是一种强大的编程语言,具有丰富的库和工具,使其成为Excel数据分析的理想选择。通过使用Python,数据分析人员可以自动化任务、处理大量数据并创建交互式可视化。
**1.2 Python Excel数据分析库**
【实战演练】构建简单的负载测试工具

# 1. 负载测试基础**
负载测试是一种性能测试,旨在模拟实际用户负载,评估系统在高并发下的表现。它通过向系统施加压力,识别瓶颈并验证系统是否能够满足预期性能需求。负载测试对于确保系统可靠性、可扩展性和用户满意度至关重要。
# 2. 构建负载测试工具
### 2.1 确定测试目标和指标
在构建负载测试工具之前,至关重要的是确定测试目标和指标。这将指导工具的设计和实现。以下是一些需要考虑的关键因素:
Python字典常见问题与解决方案:快速解决字典难题
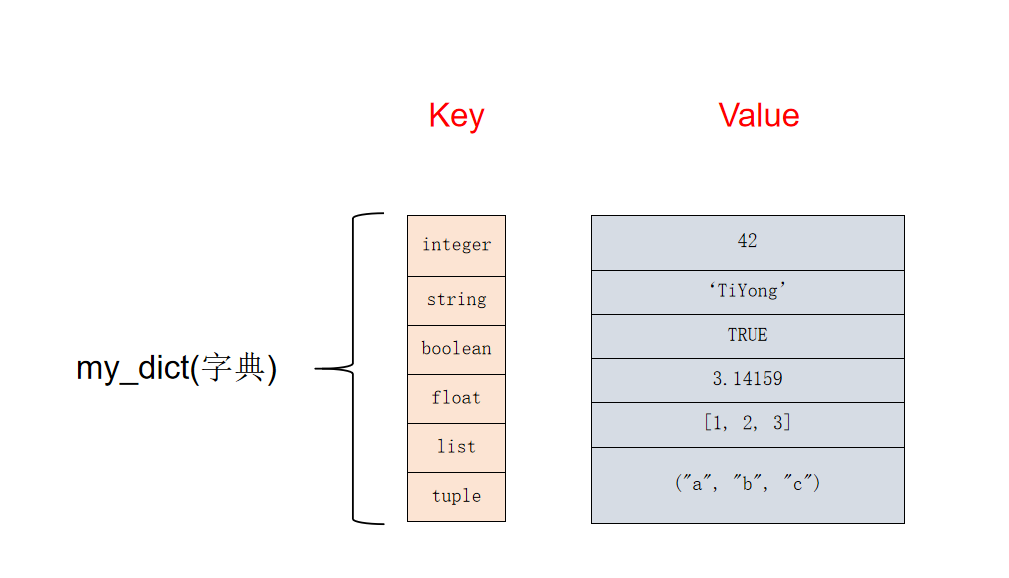
# 1. Python字典简介
Python字典是一种无序的、可变的键值对集合。它使用键来唯一标识每个值,并且键和值都可以是任何数据类型。字典在Python中广泛用于存储和组织数据,因为它们提供了快速且高效的查找和插入操作。
在Python中,字典使用大括号 `{}` 来表示。键和值由冒号 `:` 分隔,键值对由逗号 `,` 分隔。例如,以下代码创建了一个包含键值对的字典:
```py
【进阶】PyTorch简介与安装

# 2.1 PyTorch张量与运算
### 2.1.1 张量的概念和操作
张量是PyTorch中表示多维数据的核心数据结构。它类似于NumPy中的ndarray,但具有额外的功能,如自动微分和GPU加速。张量可以用`torch.Tensor()`函数创建,也可以从NumPy数组或其他张量转换而来。
张量支持各种操作,包括算术运算(如加、减、乘、除)、比较运算(如等于、大于、小于)、逻辑运算(如与、或、
OODB数据建模:设计灵活且可扩展的数据库,应对数据变化,游刃有余

# 1. OODB数据建模概述
对象-面向数据库(OODB)数据建模是一种数据建模方法,它将现实世界的实体和关系映射到数据库中。与关系数据建模不同,OODB数据建模将数据表示为对象,这些对象具有属性、方法和引用。这种方法更接近现实世界的表示,从而简化了复杂数据结构的建模。
OODB数据建模提供了几个关键优势,包括:
* **对象标识和引用完整性
【实战演练】前沿技术应用:AutoML实战与应用

# 1. AutoML概述与原理**
AutoML(Automated Machine Learning),即自动化机器学习,是一种通过自动化机器学习生命周期
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
送3个月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )