【Sphinx实战秘籍】:为开源库编写高效文档的7大秘诀
发布时间: 2024-10-07 00:46:46 阅读量: 29 订阅数: 46 

docker-sphinx-doc:Sphinx的Docker映像,这是用Python编写的文档工具

# 1. Sphinx文档工具概览
Sphinx是一个广泛使用的开源文档生成工具,特别适用于创建Python项目的文档。它将简单的标记语言(reStructuredText)转换成结构化的HTML文档,同时支持LaTeX、EPUB等其他格式。Sphinx因其强大的扩展性、主题定制能力和易于维护的特性,赢得了广大开发者和文档工程师的青睐。不仅如此,Sphinx还能够通过自动跟踪文档和代码的变更来保持文档与软件的一致性,从而确保文档信息的准确性和时效性。接下来,我们将深入探讨如何设置和使用Sphinx,以及如何编写高质量的项目文档。
# 2. 基础设置与配置
### 2.1 安装Sphinx环境
#### 2.1.1 Sphinx的安装流程
在开始使用Sphinx之前,首先需要安装其环境。可以通过Python的包管理器pip进行安装,具体步骤如下:
1. 确保你的计算机上已经安装了Python。
2. 打开命令行工具,可以是终端、cmd或PowerShell。
3. 运行安装命令:
```bash
pip install sphinx
```
这个命令会下载并安装Sphinx包及其依赖。
在安装过程中可能会遇到权限问题,这时可以使用管理员权限或在命令前加上`sudo`(Linux/macOS)进行安装。
#### 2.1.2 常见问题与解决方案
在安装Sphinx时,用户可能会遇到如下问题:
1. **权限问题**:若无法安装包,则可以尝试在命令前加上`sudo`来获取管理员权限。
2. **版本兼容问题**:不同版本的Python可能会影响Sphinx包的安装。确保你的Python版本是受支持的,例如Python 3.6及以上版本。
3. **依赖缺失**:安装过程中可能会出现某些依赖缺失的错误。此时,需要根据提示安装缺失的依赖,如`setuptools`。
4. **网络问题**:如果由于网络原因无法从PyPI下载Sphinx,可以考虑使用镜像源,如清华大学镜像源。
```bash
pip install -i ***
```
以上是常见的Sphinx安装问题及其解决方案。按照上述步骤,绝大多数用户应该可以顺利完成安装。
### 2.2 创建项目文档结构
#### 2.2.1 目录结构的最佳实践
创建一个清晰的文档目录结构对于维护和扩展文档具有重要意义。Sphinx采用特定的目录结构,其中主要包含以下部分:
- `source`目录:存放文档源文件(.rst格式)。
- `build`目录:存放生成的静态HTML文件,以及其他格式的输出文件。
- `conf.py`:Sphinx的配置文件。
- `index.rst`:文档的入口文件,也称为根文档。
下面是一个典型的Sphinx项目目录结构示例:
```
my_project/
├── build/
├── source/
│ ├── _static/
│ ├── _templates/
│ ├── conf.py
│ ├── index.rst
│ ├── installation.rst
│ ├── usage.rst
│ └── api/
└── Makefile
```
其中`_static`目录用于存放静态资源文件(如CSS、图片),`_templates`目录用于存放自定义HTML模板,`api`目录可以存放API文档的相关文件。
#### 2.2.2 自动文档生成的设置
Sphinx支持从`.rst`(reStructuredText)文件自动文档生成。设置自动文档生成步骤如下:
1. 编辑`source/index.rst`文件,设置文档结构。
2. 使用`.. toctree::`指令来创建目录树,管理文档间的链接。
3. 配置`conf.py`文件,确保`html_theme`和`extensions`等配置项已正确设置。
一个简单的`index.rst`文件示例:
```rst
.. My Project documentation master file
Welcome to My Project's documentation!
.. toctree::
:maxdepth: 2
:caption: Contents:
introduction
installation
usage
api/index
Indices and tables
* :ref:`genindex`
* :ref:`modindex`
* :ref:`search`
```
以上设置完成之后,使用Sphinx提供的构建命令可以自动生成文档。
### 2.3 配置文档生成选项
#### 2.3.1 修改配置文件settings.py
Sphinx的`conf.py`文件是一个Python脚本,它配置了文档生成的方方面面。在这个文件中,你可以设置主题、扩展、样式以及文档的元信息等。
修改`conf.py`文件时,你可以按照以下步骤操作:
1. 设置项目名称、版本号、作者等元数据。
2. 选择主题,Sphinx提供默认主题和其他第三方主题。
3. 打开/关闭特定的扩展(例如autodoc、intersphinx等)。
4. 设置静态资源路径和模板路径。
示例配置代码:
```python
# conf.py
project = 'My Project'
author = 'Your Name'
version = '1.0.0'
release = '1.0.0'
# 主题设置
html_theme = 'alabaster'
# 扩展配置
extensions = [
'sphinx.ext.autodoc',
'sphinx.ext.napoleon',
'sphinx.ext.viewcode',
]
# 其他配置项...
```
#### 2.3.2 选择合适的主题和扩展
Sphinx允许使用多种主题来改变文档的外观,例如:
- **alabaster**:一个简单的白色主题。
- **sphinx_rtd_theme**:Read the Docs主题,适合在线阅读。
- **bootstrap**:使用Bootstrap框架的主题。
可以通过安装扩展包来启用更多主题。此外,扩展Sphinx的功能通常通过添加特定的扩展模块来实现,例如:
- **autodoc**:自动从源代码中生成API文档。
- **intersphinx**:链接到其他项目的文档。
- **napoleon**:支持Google和NumPy的文档风格。
选择扩展和主题时,需要根据项目的需求和团队的偏好来决定。
在了解了上述基础设置与配置后,我们可以进一步深入到如何编写和组织文档内容,使用Sphinx提供的丰富功能来构建高质量的文档。
# 3. 编写与组织文档内容
## 3.1 利用reStructuredText语法
reStructuredText(reST)是一种轻量级标记语言,用于编写可读性高且格式丰富的纯文本文件。Sphinx使用reST作为其默认的标记语言,因此掌握reST的语法对于编写Sphinx文档至关重要。这一小节将向读者介绍reST的基础语法,以及一些高级文本格式化技巧。
### 3.1.1 基本语法介绍
在Sphinx文档中,文本可以被标记为不同类型的元素,比如标题、列表、段落、强调文本等。
- **标题**:使用下划线标记标题,一个星号(*)表示第一级标题,两个星号表示第二级标题,依此类推。例如:
```
This is a primary heading
========================
This is a secondary heading
---------------------------
### This is a tertiary heading
```
- **列表**:Sphinx支持无序和有序列表。
无序列表使用星号、加号或减号后跟空格来开始每一项:
```
* 项目一
* 项目二
* 项目三
```
有序列表则以数字、点或圆圈后跟空格开始:
```
1. 第一项
2. 第二项
3. 第三项
```
- **强调**:使用星号或下划线来强调文本:
```
*强调* 或者 _强调_
```
- **代码**:单行代码使用双反引号:
```
`print("Hello World")`
```
- **链接**:可以使用`_`后跟链接文本和URL的格

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入探索 Python 文档构建工具 Sphinx,提供从基础到高级的全面指南。涵盖了 Sphinx 的核心概念、定制主题和布局、插件机制、CI 集成、专业文档制作、扩展开发、标记语言、混合语言文档、主题美化、API 文档生成、云端分发、交互式文档集成、大型项目应用和 SEO 优化等各个方面。通过一系列文章,本专栏旨在帮助读者掌握 Sphinx 的强大功能,创建高质量、定制化且易于维护的 Python 文档,提升项目维护效率和用户体验。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
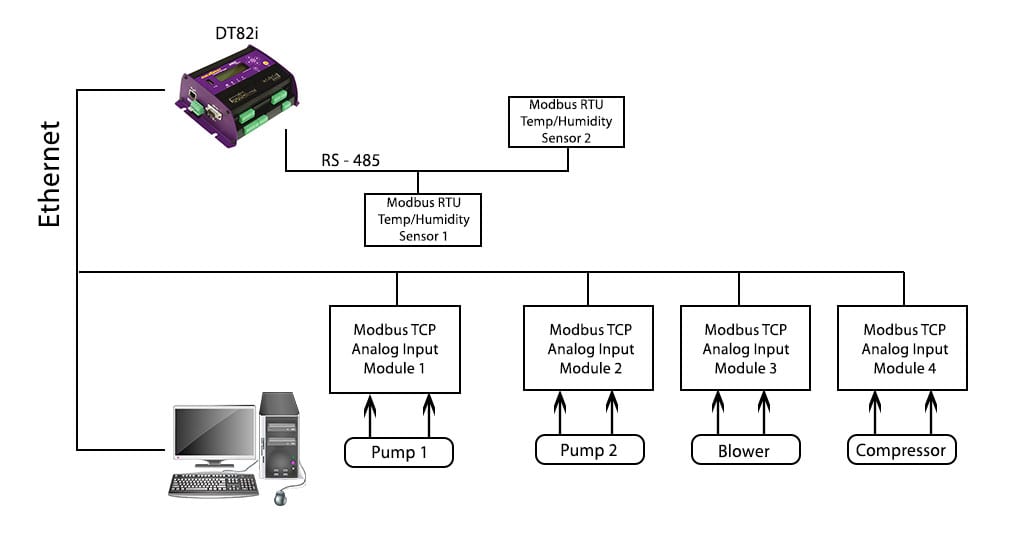
NModbus性能优化:提升Modbus通信效率的5大技巧
# 摘要
本文综述了NModbus性能优化的各个方面,包括理解Modbus通信协议的历史、发展和工作模式,以及NModbus基础应用与性能瓶颈的分析。文中探讨了性能瓶颈常见原因,如网络延迟、数据处理效率和并发连接管理,并提出了多种优化技巧,如缓存策略、批处理技术和代码层面的性能改进。文章还通过工业自动化系统的案例分析了优化实施过程和结果,包括性能对比和稳定性改进。最后,本文总结了优化经验,展望了NModbus性能优化技术的发展方向。
【Java开发者效率利器】:Eclipse插件安装与配置秘籍

# 摘要
Eclipse插件开发是扩展IDE功能的重要途径,本文对Eclipse插件开发进行了全面概述。首先介绍了插件的基本类型、架构及安装过程,随后详述了提升Java开发效率的实用插件,并探讨了高级配置技巧,如界面自定义、性能优化和安全配置。第五章讲述了开发环境搭建、最佳实践和市场推广策略。最后,文章通过案例研究,分析了成功插件的关键因素,并展望了未来发展趋势和面临的技
【性能测试:基础到实战】:上机练习题,全面提升测试技能

# 摘要
随着软件系统复杂度的增加,性能测试已成为确保软件质量不可或缺的一环。本文从理论基础出发,深入探讨了性能测试工具的使用、定制和调优,强调了实践中的测试环境构建、脚本编写、执行监控以及结果分析的重要性。文章还重点介绍了性能瓶颈分析、性能优化策略以及自动化测试集成的方法,并展望了
SECS-II调试实战:高效问题定位与日志分析技巧

# 摘要
SECS-II协议作为半导体设备通信的关键技术,其基础与应用环境对提升制造自动化与数据交换效率至关重要。本文详细解析了SECS-II消息的类型、格式及交换过程,包括标准与非标准消息的处理、通信流程、流控制和异常消息的识别。接着,文章探讨了SECS-II调试技巧与工具,从调试准备、实时监控、问题定位到日志分析
Redmine数据库升级深度解析:如何安全、高效完成数据迁移

# 摘要
随着信息技术的发展,项目管理工具如Redmine的需求日益增长,其数据库升级成为确保系统性能和安全的关键环节。本文系统地概述了Redmine数据库升级的全过程,包括升级前的准备工作,如数据库评估、选择、数据备份以及风险评估。详细介绍了安全迁移步骤,包括
YOLO8在实时视频监控中的革命性应用:案例研究与实战分析

# 摘要
YOLO8作为一种先进的实时目标检测模型,在视频监控应用中表现出色。本文概述了YOLO8的发展历程和理论基础,重点分析了其算法原理、性能评估,以及如何在实战中部署和优化。通过探讨YOLO8在实时视频监控中的应用案例,本文揭示了它在不同场景下的性能表现和实际应用,同时提出了系统集成方法和优化策略。文章最后展望了YOLO8的未来发展方向,并讨论了其面临的挑战,包括数据隐私和模型泛化能力等问题。本文旨在为研究人员和工程技术人员提供YOLO8
UL1310中文版深入解析:掌握电源设计的黄金法则

# 摘要
电源设计在确保电气设备稳定性和安全性方面发挥着关键作用,而UL1310标准作为重要的行业准则,对于电源设计的质量和安全性提出了具体要求。本文首先介绍了电源设计的基本概念和重要性,然后深入探讨了UL1310标准的理论基础、主要内容以及在电源设计中的应用。通过案例分析,本文展示了UL1310标准在实际电源设计中的实践应用,以及在设计、生产、测试和认证各阶段所面
Lego异常处理与问题解决:自动化测试中的常见问题攻略

# 摘要
本文围绕Lego异常处理与自动化测试进行深入探讨。首先概述了Lego异常处理与问题解决的基本理论和实践,随后详细介绍了自动化测试的基本概念、工具选择、环境搭建、生命周期管理。第三章深入探讨了异常处理的理论基础、捕获与记录方法以及恢复与预防策略。第四章则聚焦于Lego自动化测试中的问题诊断与解决方案,包括测试脚本错误、数据与配置管理,以及性
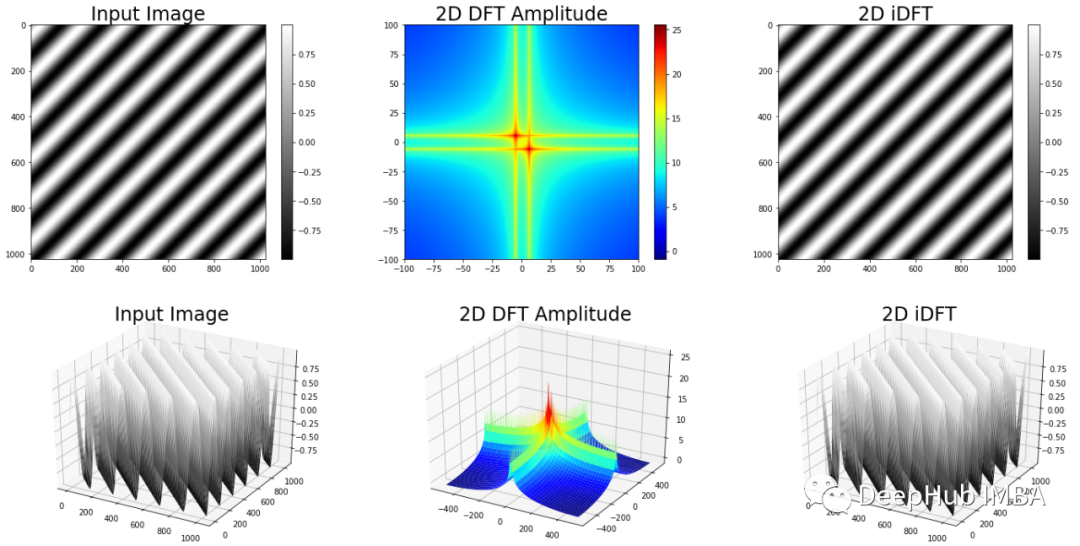
【Simulink频谱分析:立即入门】
# 摘要
本文系统地介绍了Simulink在频谱分析中的应用,涵盖了从基础原理到高级技术的全面知识体系。首先,介绍了Simulink的基本组件、建模环境以及频谱分析器模块的使用。随后,通过多个实践案例,如声音信号、通信信号和RF信号的频谱分析,展示了Simulink在不同领域的实际应用。此外,文章还深入探讨了频谱分析参数的优化,信号处理工具箱的使用,以及实时频谱分析与数据采
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )