数据结构在C++中的实现与优化
发布时间: 2024-03-29 04:05:18 阅读量: 55 订阅数: 27 
# 1. C++中常用的数据结构概述
1.1 数组
1.2 链表
1.3 栈与队列
1.4 树与图
# 2. 数据结构在C++中的基本实现
2.1 数组的实现与操作
2.2 链表的实现与操作
# 3. 常见数据结构的高级实现技巧
数据结构在实际编程中起着至关重要的作用,而对数据结构进行高级实现技巧的优化,则可以提高程序的效率和性能。本章将介绍一些常见数据结构的高级实现技巧,包括动态数组、双向链表、堆与优先队列等。
#### 3.1 动态数组的实现与优化
动态数组在C++中经常被使用,它可以根据需要动态地增加或减少元素的个数,而且支持随机访问。在实现动态数组时,需要考虑扩容策略、内存管理等方面的优化。
```cpp
#include <iostream>
#include <vector>
int main() {
std::vector<int> dynamicArray;
// 添加元素
for(int i = 1; i <= 5; i++) {
dynamicArray.push_back(i);
}
// 输出元素
for(int i = 0; i < dynamicArray.size(); i++) {
std::cout << dynamicArray[i] << " ";
}
return 0;
}
```
**代码总结**:使用`std::vector`实现动态数组,通过`push_back`方法添加元素,可以动态增加数组大小。
**结果说明**:输出结果为`1 2 3 4 5`,表示成功添加并输出动态数组的元素。
#### 3.2 双向链表的实现与优化
双向链表是一种常见的数据结构,它允许在两个方向上遍历链表中的元素。在实现双向链表时,需要考虑插入、删除、查找等操作的效率和优化。
```cpp
#include <iostream>
#include <list>
int main() {
std::list<int> doublyLinkedList;
// 添加元素
for(int i = 1; i <= 5; i++) {
doublyLinkedList.push_back(i);
}
// 输出元素
for(auto val : doublyLinkedList) {
std::cout << val << " ";
}
return 0;
}
```
**代码总结**:使用`std::list`实现双向链表,通过`push_back`方法添加元素,可以在两个方向上遍历链表。
**结果说明**:输出结果为`1 2 3 4 5`,表示成功添加并输出双向链表的元素。
#### 3.3 堆与优先队列的实现
堆是一种常见的数据结构,支持快速查找最大或最小元素。优先队列则是基于堆实现的一种数据结构,在优先队列中,元素按照优先级顺序进行排列。
```cpp
#include <iostream>
#include <queue>
int main() {
std::priority_queue<int> maxHeap;
// 添加元素
maxHeap.push(3);
maxHeap.push(5);
maxHeap.push(1);
// 输出元素
while(!maxHeap.empty()) {
std::cout << maxHeap.top() << " ";
maxHeap.pop();
}
return 0;
}
```
**代码总结**:使用`std::priority_queue`实现最大堆,通过`push`方法添加元素,`top`方法获取当前最大元素并`pop`出堆。
**结果说明**:输出结果为`5 3 1`,表示成功使用优先队列实现最大堆,并按照优先级顺序输出元素。
# 4. 数据结构的内存优化
在实际的软件开发过程中,数据结构的内存占用往往是需要特别关注的问题。合理的内存设计能够有效提高程序的性能和效率。本章将介绍如何优化数据结构的内存占用,并介绍一些内存对齐和内存池技术。
### 4.1 优化数据结构的内存占用
在C++中,数据结构的内存占用是需要特别注意的问题。一个数据结构的内存占用大小会直接影响程序的性能和资源消耗。在设计数据结构时,需要考虑以下几点来优化内存占用:
- **使用合适的数据类型**:选择合适的数据类型可以有效减少内存占用。比如使用`int`替代`long`、使用`char`替代`string`等。
- **避免内存碎片**:尽量避免频繁的内存分配和释放操作,可以采用内存池技术来管理内存块,减少内存碎片的产生。
- **结构体内存对齐**:结构体的内存对齐可以减少内存浪费,提高内存读取效率。可以通过设置编译器的对齐方式来进行优化。
- **使用位运算**:在一些特定场景下,可以使用位运算来节约内存空间,比如使用位域来表示多个开关状态。
### 4.2 内存对齐和内存池技术
- **内存对齐**:由于硬件的限制,在访问内存时,CPU往往要求数据按照一定的字节对齐方式存放。通过设置编译器的对齐方式,可以优化数据结构的内存占用。
- **内存池技术**:内存池是一种预先分配内存空间,在程序运行期间重复使用的技术。通过内存池管理动态分配和释放的内存,可以减少内存碎片的产生,并提高内存的利用率。
综上所述,合理的优化数据结构的内存占用对于软件开发至关重要。在实际项目中,需要根据具体情况选择合适的优化策略,以提高程序的性能和效率。
# 5. 数据结构在实际项目中的应用与性能优化
数据结构在实际项目中的应用十分广泛,不仅在算法设计中发挥着重要作用,也在系统设计和性能优化中扮演着关键角色。本章将重点探讨数据结构在实际项目中的应用场景以及相关的性能优化技巧。
### 5.1 数据结构在算法设计中的应用
在算法设计中,数据结构的选择直接影响着算法的效率和可维护性。例如,对于需要频繁插入和删除操作的场景,选择合适的数据结构如链表而不是数组是至关重要的。常见的算法中,比如哈希表、红黑树、并查集等都是基于不同数据结构实现的。合理地运用数据结构,可以优化算法的时间复杂度和空间复杂度,提高算法的性能。
```python
# 示例:使用哈希表解决两数之和问题
def two_sum(nums, target):
hashmap = {}
for i, num in enumerate(nums):
complement = target - num
if complement in hashmap:
return [hashmap[complement], i]
hashmap[num] = i
return []
# 测试
nums = [2, 7, 11, 15]
target = 9
print(two_sum(nums, target)) # 输出: [0, 1]
```
**总结:** 在算法设计中,合理选择和运用数据结构可以提高算法的效率和可读性,哈希表、树、链表等数据结构常常是解决算法问题的利器。
### 5.2 数据结构在系统设计中的应用
在系统设计中,数据结构不仅用于解决算法问题,还承担着存储和管理数据的重要任务。例如,在数据库系统中,B+树被广泛用于实现索引结构;在高并发系统中,队列常用于实现消息队列等。合理选择和设计数据结构,可以提高系统的性能、可扩展性和稳定性。
```java
// 示例:使用优先队列实现最大堆排序
import java.util.PriorityQueue;
public class HeapSort {
public static void heapSort(int[] nums) {
PriorityQueue<Integer> maxHeap = new PriorityQueue<>((a, b) -> b - a);
for (int num : nums) {
maxHeap.offer(num);
}
for (int i = 0; i < nums.length; i++) {
nums[i] = maxHeap.poll();
}
}
// 测试
public static void main(String[] args) {
int[] nums = {4, 10, 3, 5, 1};
heapSort(nums);
for (int num : nums) {
System.out.print(num + " "); // 输出: 10 5 4 3 1
}
}
}
```
**总结:** 在系统设计中,数据结构的选择和设计对系统的性能和可维护性至关重要,合理运用数据结构可以提高系统的效率和稳定性。
### 5.3 数据结构的性能优化技巧
数据结构的性能优化是提高系统性能的重要手段之一。常见的数据结构性能优化技巧包括:缓存、预分配、延迟加载等。在实际项目中,根据具体场景合理应用这些技巧,可以有效提升系统的性能。
```javascript
// 示例:使用缓存优化Fibonacci数列计算
let memo = {};
function fibonacci(n) {
if (n <= 1) return n;
if (!memo[n]) {
memo[n] = fibonacci(n - 1) + fibonacci(n - 2);
}
return memo[n];
}
// 测试
console.log(fibonacci(6)); // 输出: 8
```
**总结:** 在性能优化中,合理利用缓存、预分配等技巧可以减少资源消耗,提高系统性能,但也需要权衡空间复杂度和时间复杂度的关系。
通过以上内容,我们可以看到数据结构在实际项目中的重要性和应用范围,以及如何通过性能优化技巧提升系统性能。在实际项目开发中,充分理解和掌握数据结构的应用与优化技巧,将有助于提高代码质量和系统性能。
# 6. 实例分析与总结
### 6.1 分析一个实际项目中数据结构的应用
在一个实际项目中,我们经常需要处理大量数据并且需要高效地进行各种操作,这就需要合适的数据结构来支撑。举个例子,假设我们要开发一个在线购物系统,需要实现购物车功能。这个功能需要支持添加商品、移除商品、修改商品数量等操作。在这种场景下,可以使用动态数组或者哈希表来实现购物车功能,以便高效地进行商品的增删改查操作。
#### 代码示例(Python实现):
```python
class ShoppingCart:
def __init__(self):
self.cart_items = {}
def add_item(self, item_id, quantity):
if item_id in self.cart_items:
self.cart_items[item_id] += quantity
else:
self.cart_items[item_id] = quantity
def remove_item(self, item_id):
if item_id in self.cart_items:
del self.cart_items[item_id]
def update_quantity(self, item_id, quantity):
if item_id in self.cart_items:
self.cart_items[item_id] = quantity
def get_cart_items(self):
return self.cart_items
# 创建购物车实例并进行操作
cart = ShoppingCart()
cart.add_item("001", 2)
cart.add_item("002", 1)
print(cart.get_cart_items())
cart.remove_item("001")
cart.update_quantity("002", 3)
print(cart.get_cart_items())
```
#### 代码总结:
- 上述代码实现了一个简单的购物车功能,使用了哈希表来存储商品项及其数量。
- `add_item` 方法用于添加商品至购物车,如果商品已存在,则更新数量;如果不存在,则新增商品。
- `remove_item` 方法用于移除购物车中的某个商品。
- `update_quantity` 方法用于修改购物车中某个商品的数量。
- `get_cart_items` 方法用于获取购物车中所有商品及其数量的信息。
#### 结果说明:
- 第一次打印输出会显示购物车中的商品项及其数量为:`{'001': 2, '002': 1}`。
- 经过移除商品 "001" 和更新商品 "002" 数量为 3 后,第二次打印输出显示购物车中的商品项及其数量为:`{'002': 3}`。
### 6.2 总结数据结构在C++中的实现与优化经验
在实际项目中,选择合适的数据结构并结合优化技巧可以有效提升系统的性能和稳定性。以下是对数据结构在C++中的实现与优化的一些经验总结:
1. 根据实际需求选择合适的数据结构,如数组适合随机访问和删除,并且需要在固定大小的情况下;链表适合频繁的插入和删除操作等。
2. 对数据结构进行内存优化,包括减小数据结构大小、使用指针和引用等技巧,以减少内存占用。
3. 使用适当的算法和数据结构组合,如在搜索场景中使用哈希表优化查找速度等。
4. 注意数据结构的操作复杂度,避免出现性能瓶颈,及时优化代码结构和算法。
### 6.3 展望未来数据结构与C++技术发展趋势
随着技术的不断发展,数据结构在C++中的实现与优化也将随之变化。未来的发展趋势可能包括:
1. 更加智能化的数据结构设计,以适应大规模数据处理和人工智能等领域的需求。
2. 针对不同场景的定制化数据结构实现,以提高系统性能和扩展性。
3. 结合硬件优化和并行计算,进一步提升数据结构在C++中的运行速度和效率。
4. 持续关注新技术和新算法的发展,及时应用于数据结构的实现与优化中,不断提升系统的竞争力。
以上是关于数据结构在C++中的实现与优化的一些实例分析和总结,希望能为读者提供一些启发和参考。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
这个专栏旨在探讨如何运用C++的各种技术来设计一个完善的停车场系统。从C++基础知识到高级应用,涵盖了数据结构、面向对象原理、指针与引用、异常处理、模板编程、多线程编程、STL容器、算法实现、Lambda表达式、设计模式等方面的内容。专栏还深入讨论了动态内存管理、智能指针、性能调优、并发编程、数据库连接、图形用户界面设计、网络编程等关键主题,同时分享了性能测试、代码重构、优化实践等方面的经验。适合想深入学习C++技术并应用于实际项目中的开发人员阅读,为他们提供全面的技术指导和实践案例。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【变频器与电机控制优化】:匹配与策略大公开,提升工业自动化性能
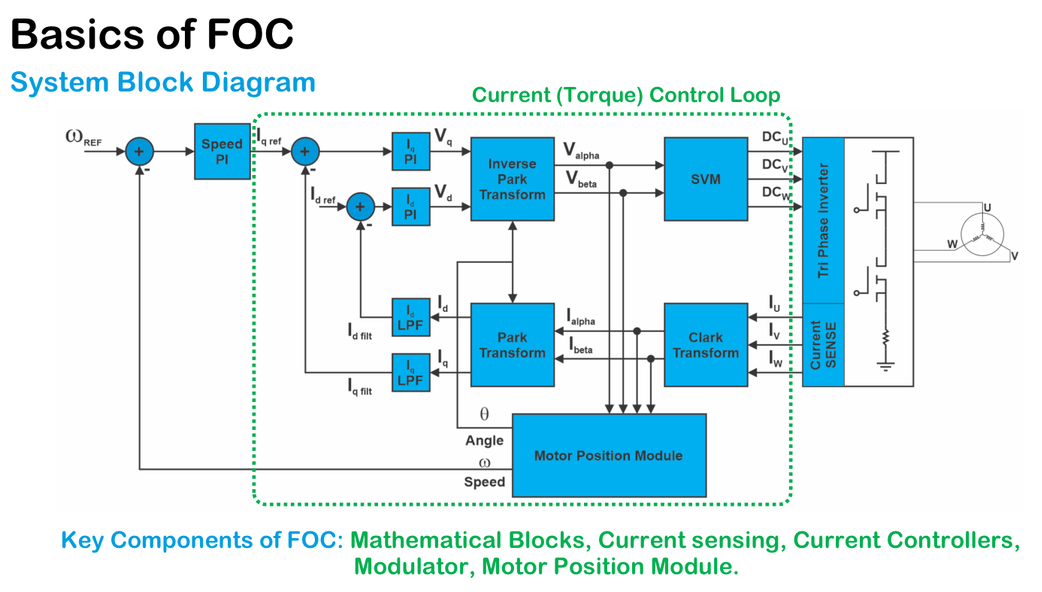
# 摘要
本文系统地探讨了变频器与电机控制的基础知识、理论与技术,及其在实践应用中的优化策略与维护方法。文中首先介绍了电机控制与变频器技术的基础理论,包括电机的工作原理和控制策略,以及变频器的工作原理和分类。然后,文章深入探讨了电机与变频器的匹配原则,并通过案例研究分析了变频器在电机控制中的安装、调试及优化。此外,
【无缝集成秘籍】:确保文档安全管理系统与IT架构100%兼容的技巧

# 摘要
本文全面探讨了文档安全管理系统与IT架构的兼容性和集成实践。首先概述了文档安全管理系统的基本概念与重要性,然后深入分析了IT架构兼容性的基础理论,包括硬件与软件架构的兼容性原则及兼容性测试方法。第三章详细讨论了文档安全管理系统与IT架构集成的准备、实施步骤和维护优化。第四章探讨了高级集成技术,例如虚拟化、容器化、微服
PowerDesigner关联映射技巧:数据模型与数据库架构同步指南

# 摘要
PowerDesigner作为一种强大的数据建模工具,为数据模型的构建和数据库架构设计提供了高效解决方案。本文首先介绍Pow
【海康威视测温客户端案例研究】:行业应用效果与成功故事分享
# 摘要
海康威视测温客户端是一款集成了先进测温技术的智能设备,被广泛应用于公共场所、企业和教育机构的体温筛查中。本文首先概述了海康威视测温客户端,随后深入探讨了其测温技术理论基础,包括工作原理、精确度分析以及核心功能。接着,本文通过实操演练详述了客户端的安装、配置、使用流程以及维护和故障排查的方法。在行业应用案例分析中,本文讨论了海康威视测温客户端在不同场景下的成功应用和防疫管理策略。最后,文章分析了测温客户端的市场现状、未来发展趋势以及海康威视的战略布局,为未来测温技术的应用提供展望。
# 关键字
海康威视;测温客户端;红外测温技术;体温筛查;数据管理;市场趋势
参考资源链接:[海康威
散列表与哈希技术:C++实现与冲突处理,性能优化全解

# 摘要
散列表与哈希技术是数据结构领域的重要组成部分,它们在提高数据检索速度和管理大数据集方面发挥着关键作用。本文首先介绍了散列表和哈希技术的基础知识,然后详细探讨了在C++语言中散列表的实现方法、性能分析和冲突处理策略。针对性能优化,本文还讨论了如
【TP.VST69T.PB763主板维修深度】:深入探讨与实践要点
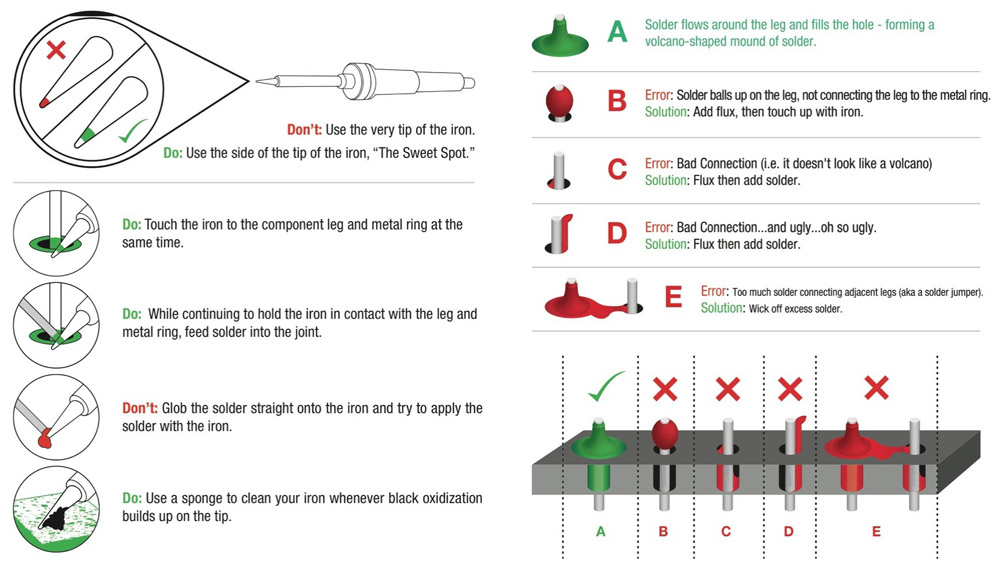
# 摘要
本文针对TP.VST69T.PB763主板维修进行了全面系统的分析和探讨。首先概述了主板维修的基本知识,接着详细介绍了主板的硬件架构、故障诊断方法,以及实际维修步骤。通过案例分析,本文深入研究了主板的常见故障类型、复杂故障的解决策略,并对维修后的测试与验证流程进行了讨论。文章还探讨了性能优化与升级的实践方法,以及BIOS设置、硬件升级对系统稳定性的影响。最后,文章展望
IT架构优化的秘密武器:深入挖掘BT1120协议的潜力

# 摘要
本文详细介绍了BT1120协议的概述、技术原理及其在IT架构中的应用。首先,文章概述了BT1120协议的历史、应用场景以及基础技术内容。接着深入探讨了协议的关键技术,包括同步机制、错误检测和纠正方法,以及多通道数据传输策略。此外,本文还分析了BT1120在数据中心和边缘计算环境中的应用,指
概预算编制规程详解:2017版信息通信工程标准的深度解读

# 摘要
本文系统地探讨了信息通信工程概预算编制的全流程,从标准的核心要素、预算编制的理论与实践流程,到编制中的难点与对策,最后通过案例分析展望了未来的发展趋势。文章重点分析了2017版标准的特点与创新,探讨了其对工程预算编制的影响。同时,本文也关注了信息技术在预算编制中的应用,并提出了有效的风险管理措施。通过对预算编制过程中的理论与实践相结合的探讨,本文旨在为信息通信工程预算编制提供全面的指导和建议。
# 关键字
信息
【Java与IC卡通信秘籍】:掌握JNI调用读卡器的5大技巧
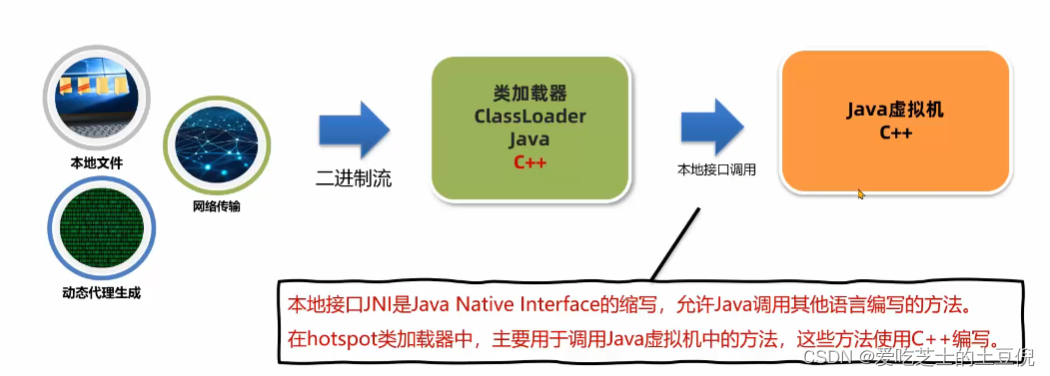
# 摘要
本论文对Java与IC卡通信进行了全面的探讨,包括JNI的基础知识、配置、数据类型映射、调用协议,以及如何使用JNI调用IC卡读卡器,实现高效通信、数据传输、异常处理,并强调了安全性和实践技巧。文章还涉及了JNI的高级特性,IC卡的高级操作技术,以及集成与测试方面的内容。通过系统地阐述这些技术和方法,本文旨在为相关领域的开发人员提供实用的指导,帮助他们更有效地实现Java
Imatest动态范围测试:应用场景与必备知识

# 摘要
本文详细介绍了Imatest动态范围测试的理论基础和实践操作。首先概述了动态范围测试的重要性及其在摄影中的应用,接着深入探讨了动态范围的基础理论,包括光学动态范围的定义和量化指标,以及数码相机动态范围原理。文章还详细解析了Imatest软件的安装、配置和动态范围测试模块,并提供了一系列实践技巧,如测试步骤详解和问题应对策略。此外,本文还探讨了动态范围测试在摄影、图像
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )