MySQL缓存与NoSQL:混合使用提升数据库性能,应对多样化数据场景
发布时间: 2024-08-01 01:19:46 阅读量: 15 订阅数: 36 
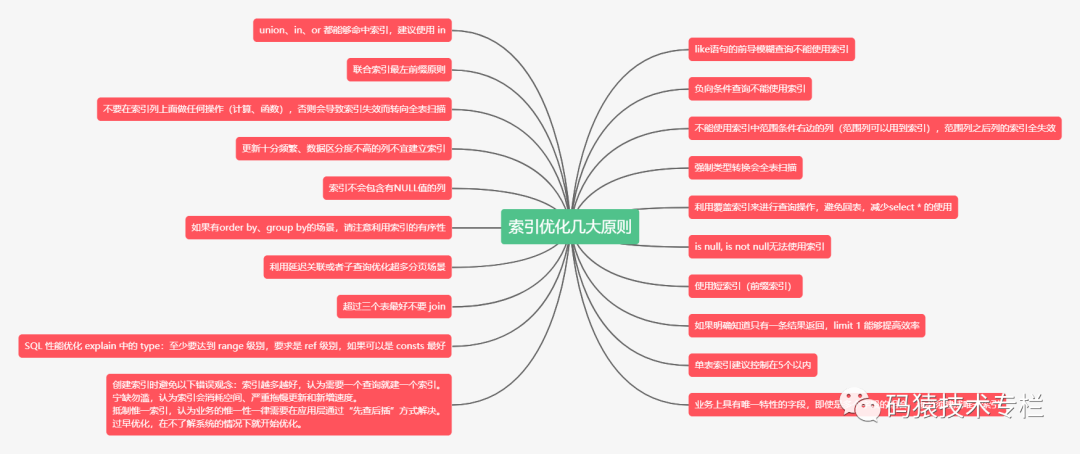
# 1. 数据库性能优化概述
数据库性能优化是提升数据库系统效率和响应速度的关键技术。它涉及一系列措施,包括:
- **识别性能瓶颈:**确定导致数据库性能低下的因素,例如慢查询、高负载或资源不足。
- **优化查询:**通过调整查询语句、使用索引和优化连接来提高查询效率。
- **缓存机制:**利用缓存机制,例如查询缓存和缓冲池,来减少数据库访问的开销。
- **NoSQL数据库:**考虑使用NoSQL数据库,例如键值存储或文档存储,来处理非结构化数据或高并发读写场景。
# 2. MySQL缓存机制
MySQL数据库提供了一系列缓存机制来提高查询性能,这些缓存机制在内存中存储了经常访问的数据,从而减少了对磁盘的访问。
### 2.1 MySQL缓存的类型和工作原理
MySQL主要有三种类型的缓存:
#### 2.1.1 查询缓存
查询缓存存储了最近执行过的查询及其结果。当一个查询再次执行时,MySQL会首先检查查询缓存,如果找到匹配的查询,则直接返回缓存中的结果,而无需再次执行查询。
#### 2.1.2 缓冲池
缓冲池是MySQL中最重要的缓存,它存储了从磁盘读取的数据页。当MySQL需要访问数据时,它会首先检查缓冲池,如果找到所需的数据页,则直接从缓冲池中读取数据,而无需再次访问磁盘。
#### 2.1.3 重做日志缓冲
重做日志缓冲存储了对数据库所做的更改。当一个事务提交时,MySQL会将事务中的更改写入重做日志缓冲。如果数据库发生故障,MySQL可以从重做日志缓冲中恢复更改,确保数据的完整性。
### 2.2 MySQL缓存的优化策略
为了优化MySQL缓存的使用,可以采取以下策略:
#### 2.2.1 调整缓存大小
调整缓存大小可以根据系统的负载和内存使用情况进行优化。如果缓存太小,可能会导致频繁的磁盘访问,降低性能。如果缓存太大,可能会浪费内存,影响其他应用程序的性能。
#### 2.2.2 禁用不必要的缓存
如果某些缓存对系统性能没有明显影响,可以考虑禁用它们以释放内存。例如,如果应用程序很少使用查询缓存,可以禁用查询缓存以释放内存。
#### 2.2.3 监控和分析缓存使用情况
通过监控和分析缓存使用情况,可以了解缓存的命中率和使用模式。根据分析结果,可以进一步优化缓存大小和配置。
**代码块:**
```sql
SHOW VARIABLES LIKE 'query_cache%';
```
**逻辑分析:**
该SQL语句用于显示与查询缓存相关的配置参数,包括查询缓存大小、命中率等信息。
**参数说明:**
* query_cache_size:查询缓存大小
* query_cache_type:查询缓存类型
* query_cache_limit:查询缓存大小限制
* query_cache_min_res_unit:查询缓存最小资源单位
# 3. NoSQL数据库简介
### 3.1 NoSQL数据库的类型和特点
NoSQL(Not Only SQL)数据库是一种非关系型数据库,它突破了传统关系型数据库的局限性,提供了更灵活、可扩展和高性能的数据存储解决方案。NoSQL数据库主要分为以下几種類型:
**3.1.1 键值存储**
键值存储是最简单的NoSQL数据库类型,它将数据存储在键值对中。键是唯一标识符,而值可以是任何类型的数据。键值存储通常用于存储小而简单的对象,例如用户偏好、计数器或缓存数据。
**3.1.2 文档存储**
文档存储将数据存储在文档中,文档是一个包含键值对和其他结构化数据的JSON或XML对象。文档存储允许灵活的数据模型,可以轻松存储和检索复杂的数据结构。
**3.1.3 列存储**
列存储将数据存储在列中,而不是行中。这使得列存储非常适合处理大数据集,因为可以快速访问特定列中的数据。列存储通常用于分析和数据挖掘应用程序。
### 3.2 NoSQL数据库的应用场景
NoSQL数据库在以下场景中具有优势:
**3.2.1 海量数

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
欢迎阅读我们的 MySQL 数据库缓存专栏!本专栏深入探讨了 MySQL 缓存的方方面面,旨在帮助您优化数据库性能,提升效率。从缓存机制的原理到实践应用,从缓存失效分析到解决策略,我们为您提供了全面的指南。此外,我们还提供了提升缓存命中率的技巧、详细的缓存配置详解、实战调优案例和最佳实践。通过了解缓存与索引、锁机制、复制、慢查询、云计算、NoSQL、大数据、人工智能、容器化、DevOps 和安全之间的协同作用,您可以全面掌握 MySQL 缓存的优化之道,释放数据库性能潜力,打造高速、稳定、安全的数据库系统。
专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
比例谐振控制算法深度解析:理论基石与实践指南(从基础到进阶)
参考资源链接:[比例谐振PR控制器详解:从理论到实践](https://wenku.csdn.net/doc/5ijacv41jb?spm=1055.2635.3001.10343)
# 1. 比例谐振控制算法概述
比例谐振控制算法是一种广泛应用于现代控制系统的先进控制技术,它结合了比例控制(P控制)和谐振控制(R控制),通过精确地调整控制参数,以达到对特定频率下的振荡过程进行稳定和抑制的效果
FANUC机器人通讯案例分析:工业自动化中的成功应用实例

参考资源链接:[FANUC机器人TCP/IP通信设置手册](https://wenku.csdn.net/doc/6401acf8cce7214c316edd05?spm=1055.2635.3001.10343)
# 1. 工业自动化与机器人通讯概述
工业自动化系统是现代制造业的核心组成部分,而机器人通讯则是这一系统
STM32F103VET6原理图设计软件:Altium与KiCad精通之道
参考资源链接:[STM32F103VET6 PCB原理详解:最小系统板与电路布局](https://wenku.csdn.net/doc/6412b795be7fbd1778d4ad36?spm=1055.2635.3001.10343)
# 1. STM32F103VET6与原理图设计软件概述
## 1.1 STM32F103VET6简介
STM32F103VET6是STMicroelectronics公司推出的一款高性能ARM Cortex-M3微控制器,具有丰富的外设接口和高速处理能力。作为嵌入式系统领域广泛采用的芯片,它常用于工业控制、医疗设备、消费电子等应用。在进行原理图设计时,对
硬盘SMART信息解读:高级用户必备知识
参考资源链接:[硬盘SMART错误警告解决办法与诊断技巧](https://wenku.csdn.net/doc/7cskgjiy20?spm=1055.2635.3001.10343)
# 1. 硬盘与SMART技术概述
硬盘是计算机中存储数据的关键部件,它的稳定性直接关系到整个系统的运行。随着技术的发展,硬盘存储容量和速度不断提升,随之而来的是更高的故障风险。因此,硬盘的健康监测变得至关重要。SMART(Self-Monitoring, Analysis, and Reporting Technology)技术应运而生,它是一种硬盘自我监测、分析和报告技术,目的是通过持续监控硬盘运行状态
【ASP.NET Core Web API设计】:构建RESTful服务的最佳实践

参考资源链接:[ASP.NET实用开发:课后习题详解与答案](https://wenku.csdn.net/doc/649e3a1550e8173efdb59dbe?spm=1055.2635.3001.10343)
# 1. ASP.NET
【PFC5.0高可用性架构设计】:保障业务连续性的策略与技巧

参考资源链接:[PFC5.0用户手册:入门与教程](https://wenku.csdn.net/doc/557hjg39sn?spm=1055.2635.3001.10343)
# 1. PFC5.0高可用性架构概述
PFC5.0高可用性架构作为企业级解决方案的最新突破,旨在为企业提供不间断的业务运行和数据
电动汽车充电效率提升:SAE J1772标准实施难点的解决方案

参考资源链接:[SAE J1772-2017.pdf](https://wenku.csdn.net/doc/6412b74abe7fbd1778d
【IDEA性能调优】:自动编译设置,让性能飞跃

参考资源链接:[IDEA 开启自动编译设置步骤](https://wenku.csdn.net/doc/646ec8d7d12cbe7ec3f0b643?spm=1055.2635.3001.10343)
# 1. IDEA性能调优概述
随着现代软件开发项目的复杂性不断增加,集成开发环境(IDE)的性能对开发效率的影响愈发显著。在本章中,我们将介绍IntelliJ IDEA这
iSecure Center审计功能:合规性监控与审计报告完全解析

参考资源链接:[iSecure Center 安装指南:综合安防管理平台部署步骤](https://wenku.csdn.net/doc/2f6bn25sjv?spm=1055.2635.3001.10343)
# 1. iSecure Center审计功能概述
## 1.1 了解iSecure Center
iSecure Center是一个高效的审计和合规性
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )